

 万卡时代不打群架,中国智算正过三关
万卡时代不打群架,中国智算正过三关
描述
我前两天看到了一个挺震撼的视频,科学家们在NASA戈达德空间飞行中心的天体物理学家指导下,使用Discover超级计算机模拟了跳入黑洞的过程。
画面视觉效果摄人心魄,而一组数据同样让我感到震撼:该视频生成10TB的数据,只用了5天,耗费了0.3%总算力。如果我们想用自己的笔记本电脑模拟这个场景,需要花费的时间是10年。
“时间就是金钱,效率就是生命”,这句改开时代的口号,在大模型驱动的智算时代,仍旧不过时。
算力作为生产力,所节约的不只是金钱,更重要的是时间。
目前算力集群已经从千卡,迈入了万卡、五万卡集群。甚至有媒体预测,GPT6未来部署的时候,需要70万-80万张卡才能支撑。
那问题来了,万卡集群在执行大规模训练任务时负载重,发生软硬件错误的概率,当然也就更高。万卡时代,一张卡、一台机器或一个链路的故障,都可能导致中断,拖慢进程。那么十万卡、百万卡等更大数量级的提升,未来如何应对?
最近几个月,我们团队跟不少ICT厂商做了交流,简单总结一下行业动向,那就是:迈入万卡时代,必须“过三关”。
万卡时代,做AI=“中彩票”?
有必要首先说明一下,为什么智能计算仍在“堆卡”?从千卡、万卡到十万卡、百万卡,这个趋势是可持续的吗?
伴随着模型规模与数据参数愈发庞大,在可以预见的未来,基础设施层面的“堆卡”竞赛仍将继续。
目前,国际科技巨头如谷歌、微软、苹果等,在算力集群建设上持续投入,其中AI算力占总算力支出的比例持续增长,预计到2025年将达到25%。放眼国内,万卡及以上的组网也成为下一代智算中心的建设重点。
然而,算力集群卡的数量非线性增加,会带来更大的不稳定性和协作难度。正如新华三在前不久的媒体与分析师大会上所说,单卡单打独斗我们(与N卡)有差距,多卡集群服务不能打群架。

(拍摄自新华三集团2024媒体与分析师沟通会)
我们知道,分布式并行训练能够加速训练过程,是大模型常用的训练方式,相当于将任务分配给多个AI硬件,组成协作节点和集群,主打一个“人多力量大”。但是,人多还得心齐啊,让多卡用高效一致的步伐进行协作,却是一件难事,容易出现“打群架”的情况。
多卡“打架”,集群就会因故障而中断。
一位清华大学计算机教授曾分享过一个数据,其团队写一次容错检查点checkpoint需要三小时,这还是世界先进水平(未经优化前)。
工作三小时就得被迫停下,活(训练过程)又一点不能少,只能加班加点。普通打工人听了都得“抓狂”,更别说要跟技术创新抢速度、作业生产要效率的产学界了。
多卡集群“不打群架”,将算力最大化地有效使用起来,发挥每一张GPU的价值,提升训练效率,对开发人员来说,堪比中“彩票”,价值很大,但概率却不定。
显然,千行百业智能化,当然不能靠“中彩”和运气。
当算力集群即将从万卡,迈入五万、十万乃至百万卡的清晰未来,我们不能只以单一的规模和FLOPS浮点运算次数,来衡量智算中心的综合水平。其他因素也同样重要,比如集群扩展性、兼容性、算效比、能耗比等。
如何提供一个稳定可靠高性能的智算基础设施,万卡时代要“过三关”。
第一关:闯过资源墙
超大规模集群的不稳定性,一方面要对抗硬件数量非线性增长带来的“增熵”。
随着集群增大,AI芯片也会出现算力衰减的情况。支撑稳定高效的训练,就需要优化分布式计算系统的并行加速比。
更高的加速比,可以让集群在执行同一任务时,获得更高的速度和效率。也就是说,算力集群能够最大限度地一直运转,那么有效训练时间的比例更高,是开发人员衡量集群性能的一个关键。
比如国产大模型文心4.0,就通过百度智能云的万卡集群进行训练,支持模型的稳定高效迭代进化。目前,百度智能云上万卡训练集群的加速比和有效训练时间,达到 95% 以上。
(拍摄自IPF2024浪潮信息生态伙伴大会)
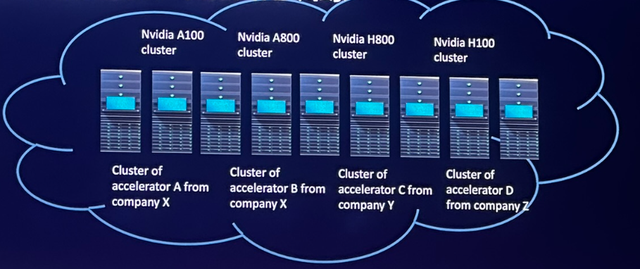
另一方面,中国智算还有一个特殊的要求,那就是闯过多元异构算力的“资源墙(resource wall)”。
不少智算中心,使用不一样的AI芯片服务器组成异构集群合池训练,共同完成一个大模型训练。尤其是此前GPU紧缺的情况下,一些数据中心、智算中心在不同时期,购买了不同的GPU,形成了不同类型、不同版本的异构集群。
多元异构的国产算力,既能以用促建,促进国产AI芯片的发展,减少对海外单一供应链的依赖,也能发挥不同类型芯片的特性,提高计算资源的利用率和训练效率。
但要将多元异构算力进行合池训练,会带来精度误差、同步问题,以及更复杂的资源管理和调度策略,更高的开发运维难度等。
未来,每个行业、每家公司都可能训练自己的大模型,带来充沛、高效、稳定的AI算力需求。让十万百万级集群、多元异构的算卡,以高效一致的步伐进行协作,将成为中国智算行业的关键挑战。
第二关:踏宽通信路
如果网络通信的联接能力不畅,大量算力资源折损在传输过程中,给智算中心与AI模型开发者带来的损失都是难以估量的。
如何将大量算卡有效地连接起来,形成一个高效稳定的计算网络,是支撑超大规模集群的关键。
需要说明的是,网络作为算力运输的道路,并不能无止境地拓宽。集群网络,尤其是万卡、十万卡集群网络的拓展,会受到几方面的制约。
首先是成本上,万卡乃至五万卡集群,所需要的网络设备数、端口数、光模块数量,可能会达到百万级别。而一个普通的400G光模块功耗就在10瓦到12瓦,当一个网络需要一万多个光模块,仅仅是电费成本都非常庞大。

此外,有业内人士向我们表示,万卡集群还容易搭建起来,未来如果要有百万卡集群来训练的大模型,可能整个城市的电都不够用。解决这个问题,那就需要分区、跨城域的算网,比如将多个万卡集群连起来,组成五万卡、十万卡集群。这就需要超高带宽的400G甚至800G网络,低时延、无损地支撑算力资源调度。
而一张运力强大、辐射范围广的算力网络,意味着管理运维的难度,也前所未有地增大了,依靠传统人力运维是不现实、不高效的。通过智能化、平台化、自动化,来实现更有效的网络纳管,是华为、新华三等ICT厂商正在探索的方向。
第三关:走出软件生态丛林
郑纬民院士曾提到一个观点:目前国内已经有30多家公司推出了国产AI芯片,“但用户不太喜欢用,核心问题就是生态不好”。
这里的生态,指的是国产软件生态。
目前,编程框架、并行加速、通信库、算子库、AI编译器、编程语言、调度器、内存分配系统、容错系统、存储系统等关键软件,虽然都有国产的,但仍有不足之处,比如功能不够齐全、性能不够好、生态贡献者不够繁荣等。
在郑院士看来,如果能把软件问题解决好,那么国产AI芯片硬件性能达到国外芯片的60%,大多数用户也可以是满意的,国产AI卡也会大受欢迎。软件做不好,国产硬件再好,也没有市场。
而万卡时代,意味着AI硬件的种类更多,既有不同架构,还有不同品类、不同版本。企业或开发者想要着手AI模型和应用开发,会在复杂的软件生态中晕头转向,很难快速找到路径。
比如说,每个芯片厂商都有自己的底层软件栈,且彼此不兼容,这就给AI开发者带来了大量移植工作,适配迁移的操作繁琐,时间、人力、金钱成本都很高。
我们注意到,2024年以来,帮助企业和AI开发者加快走出软件丛林,不少智算厂商都在强化AI软件赋能。比如宁畅在3月提出了“全局智算”战略,以“AI软动力”支持“精、准、稳”的AI集群设计,帮助客户实现大规模AI集群方案架构设计;中科曙光首次提出了“立体计算”体系,在“建、用、生态”三维发力的全新计算体系中,加大对软件生态的投入和支持;4月浪潮信息发布的企业大模型开发平台“元脑企智(EPAI)”,通过端到端的解决方案,为企业提供AI应用开发全流程的系列工具。
可以看到,“软硬兼施”的均衡能力,正在成为智算市场的兵家必争之地。

(拍摄自宁畅全局智算发布会)
大模型正在重塑产品、企业和社会,AI将无处不在,也让万卡时代成为一个确定性的未来。五万卡、十万卡乃至百万卡的算力集群,将是第四次工业革命的蒸汽机、发动机。
量子力学的创始人海森堡说过,提出正确的问题,往往等于解决了问题的大半。
从这个角度来说,正在闯关的中国智算行业,一定能在万卡时代,将算力的“心脏”握在自己手中。
-
大模型时代的算力需求2024-08-20 1023
-
做毕设,需要用2812控制由舵机组成的三关节机械臂,求助2017-04-10 4554
-
无人机战国时代中国须破解三大挑战2020-05-15 2334
-
今年中国5G用户突破1亿大关,中国的5G时代将正式开启2020-09-14 2677
-
宁畅赋能吉利星睿智算中心,引领中国汽车“智算时代”2024-01-30 1595
-
中国移动将商用三个自主可控万卡集群2024-05-06 1116
-
中国移动年内将投产多个超万卡智算中心2024-05-28 1138
-
近6万张加速卡!中国移动新建3个超大规模智算中心2024-05-29 1695
-
壁仞科技为中国移动呼和浩特智算中心提供强大算力2024-07-05 1997
-
中国电信上海、北京两个万卡集群已经投产2024-08-09 1578
-
首个国产万卡算力集群!赛思时间同步服务器助力“东数西算”甘肃庆阳枢纽节点打造「中国算谷」!2024-12-27 867
-
中国信通院栗蔚:云计算与AI加速融合,如何开启智算时代新纪元?2025-01-17 1459
-
燧原科技国产万卡集群通过中国信通院权威认证2025-07-04 1049
全部0条评论

快来发表一下你的评论吧 !
