

华为云 FunctionGraph 构建高可用系统的实践
电子说
描述
每年,网上都会报道 XXX 系统异常不可用,给客户带来巨大的经济损失。云服务的客户基数更大,一旦出现问题,都将给客户和服务自身带来极大影响。本文将基于华为云 FunctionGraph 自身的实践,详细介绍如何构建高可用的 Serverless 计算平台,实现客户和平台双赢。
高可用介绍
高可用性[1](英语:high availability,缩写为 HA),IT 术语,指系统无中断地执行其功能的能力,代表系统的可用性程度。是进行系统设计时的准则之一。
业界一般使用 SLA 指标来衡量系统的可用性。
服务级别协议[2](英语:service-level agreement,缩写 SLA)也称服务等级协议、服务水平协议,是服务提供商与客户之间定义的正式承诺。服务提供商与受服务客户之间具体达成了承诺的服务指标——质量、可用性,责任。例如,服务提供商对外承诺 99.999%的 SLA,则全年服务失效时间最大为 5.26 分钟(365*24*60*0.001%)。
FunctionGraph 直观度量系统可用性的两个黄金指标,SLI 和时延,SLI 是系统的请求成功率指标,时延是系统处理的性能。
高可用挑战
FunctionGraph 作为华为云中的子服务,在构建自身能力的同时,不仅要考虑系统本身的健壮性,也要考虑周边依赖服务的健壮性(例如依赖的身份认证服务不可用了,进行流量转发的网关服务服务宕机了,存储对象的服务访问失败了等等)。除此之外,系统依赖的硬件资源故障或者系统突然遭到流量攻击等,面临这些不可控的异常场景,系统如何构建自己的能力来保持业务高可用是一个很大的挑战。图一展示了 FunctionGraph 的周边交互。
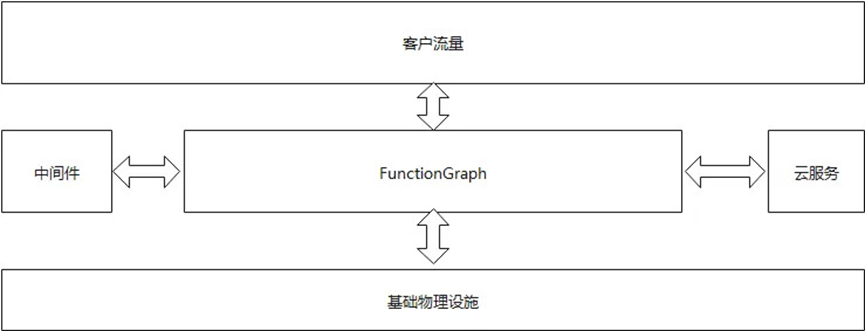
图 1 FunctionGraph 的周边交互
针对常见的问题,梳理出了 4 个大类,如表 1 所示。
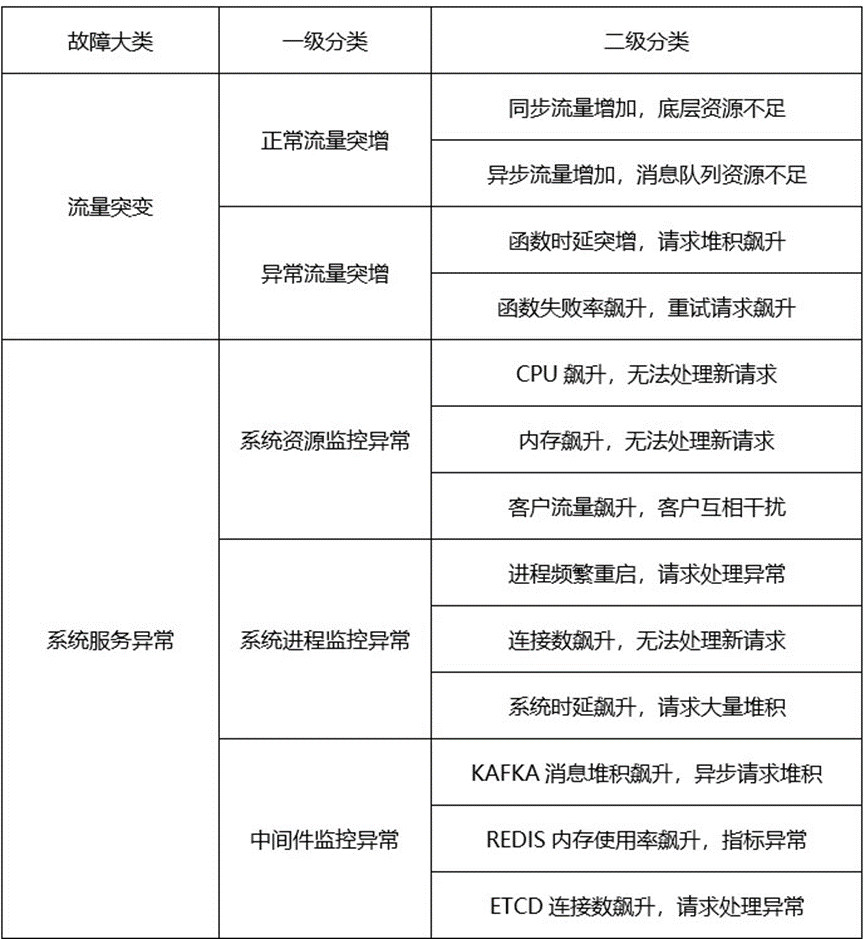
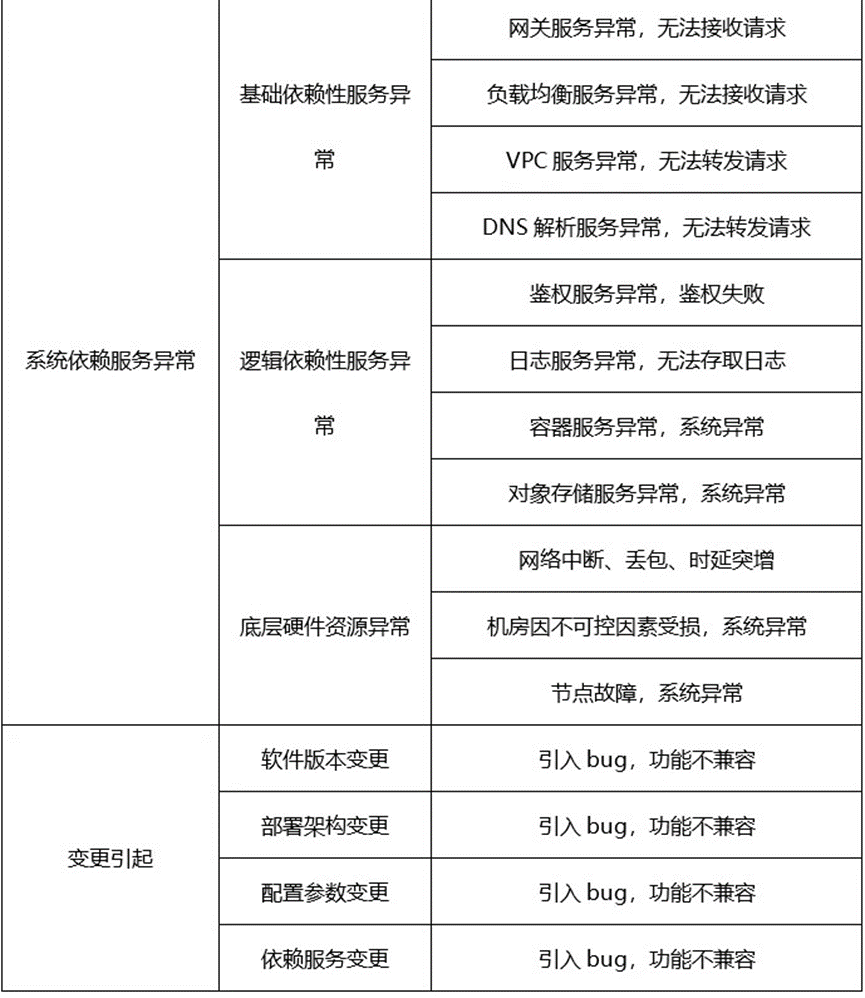
表 1 FunctionGraph 常见问题总结
针对这些问题,我们总结了如下几类通用的治理办法。
1.流量突变治理
过载保护+弹性扩缩容+熔断+异步削峰+监控告警,基于防御式的设计思想,通过过载保护+熔断确保系统所有资源受控,然后在此基础上通过提供极致的扩容能力来满足大流量,合适的客户场景推荐异步削峰来减缓系统压力,监控告警用来及时发现过载问题。
2.系统服务异常治理
容灾架构+重试+隔离+监控告警,通过容灾架构避免系统整个宕机,通过重试来减少系统异常对客户业务的影响,通过隔离快速剥离系统异常点,防止故障扩散,通过监控告警快速发现系统服务异常问题。
3.系统依赖服务异常治理
容灾架构+缓存降级+监控告警,通过容灾架构减少依赖服务单点故障,通过缓存降级确保依赖服务故障后系统仍能正常运行,通过监控告警快速发现依赖服务异常问题。
4.变更引起治理
灰度升级+流程管控+监控告警,通过灰度升级避免正式客户由于系统升级异常而造成的全局故障,通过流程管控将人为变更的风险降到最低,通过监控告警快速发现变更后的故障。
FunctionGraph 系统设计实践
为了解决表 1 出现的问题,FunctionGraph 在架构容灾、流控、重试、缓存、灰度升级、监控告警、管理流程上等多方面做了优化,可用性大幅提升。下面主要介绍一些 FunctionGraph 面向异常的设计实践,在弹性能力、系统功能等暂不展开。
容灾架构
实现华为云容灾 1.1 架构(例:服务 AZ 级故障域、集群跨 AZ 自愈能力、AZ 级服务依赖隔离),FunctionGraph 管理面和数据面集群部署多套,每套集群 AZ 隔离,实现同 region 内的 AZ 容灾。如图 2 所示,FunctionGraph 部署多套数据面集群(承担 FunctionGraph 函数运行业务)和 dispatcher 调度集群(承担 FunctionGraph 的流量集群调度任务),用来提升系容量以及容灾。当前其中某个元戎集群异常时,dispatcher 调度组件能及时摘除故障集群,并将流量分发至其他几个集群。
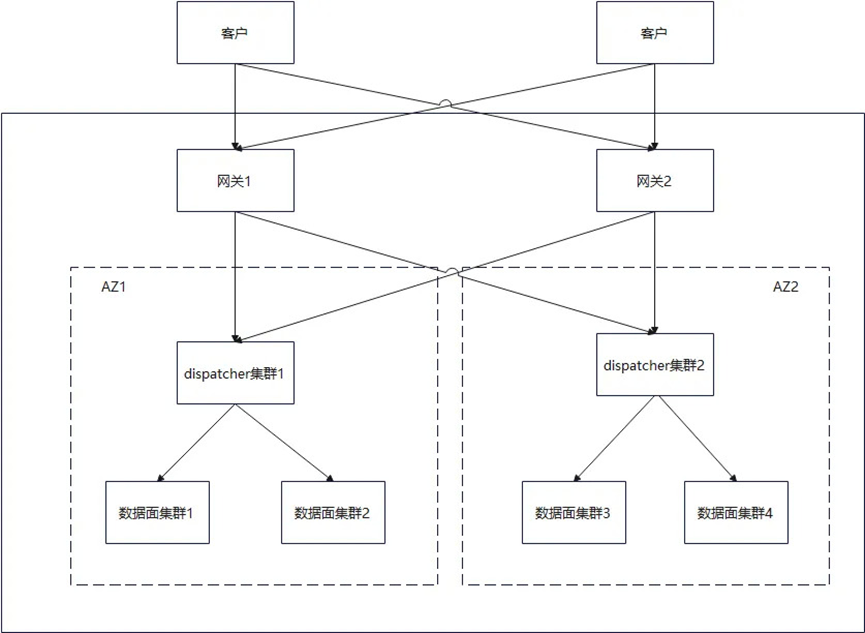
图 2 FunctionGraph 简略架构图
分布式无中心化架构设计,支持灵活的横向扩缩容
这个策略是逻辑多租服务设计的关键,需要解决无中心化后,组件扩缩容后的重均衡问题。
1.静态数据管理的无中心化
逻辑多租服务的元数据,初期由于量少,可以全部存储到同一套中间件中。随着客户上量,需要设计数据的拆分方案,支持数据的分片,应对后续海量数据读写,以及可靠性压力。
2.流量调度功能的无中心化
组件功能设计,支持无中心化(常见中心化依赖:锁、流控值、调度任务等),流量上量后,可扩展组件副本数量,组件通过自均衡策略,完成流量的重新负载。
多维度的流控策略
FunctionGraph 上的客户函数流量最终达到 runtime 运行时之前,会经过多个链路,每个链路都有可能出现超过其承载阈值的流量。因此,为了确保各个链路的稳定性,FunctionGraph 在每条链路上,防御性的追加了不同的流控策略。基本原则解决计算(cpu)、存储(磁盘、磁盘 I/0)、网络(http 连接、带宽)上的函数粒度的资源隔离。
函数流量从客户侧触发,最终运行起来的链路流控如图 3 所示。
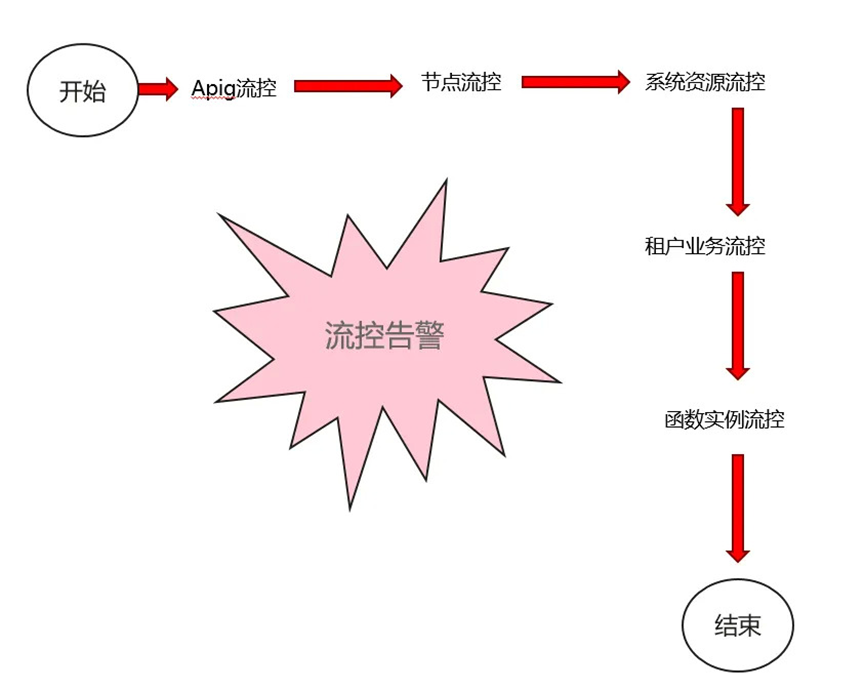
图 3 FunctionGraph 流控
1.网关 APIG 流控
APIG 是 FunctionGraph 的流量入口,支持 Region 级别总的流量控制,可以根据 region 的业务繁忙程度进行弹性扩容。同时 APIG 支持客户级别的流量控制,当检测到客户流量异常时,可以快速通过 APIG 侧限制客户流量,减少个别客户对系统稳定性的影响。
2.系统业务流控
针对 api 级别的流控
客户流量通过 APIG 后,走到 FunctionGraph 的系统侧。基于 APIG 流控失效的场景,FunctionGraph 构建了自身的流控策略。当前支持节点级别流控、客户 api 总流控、函数级别流控。当客户流量超过 FunctionGraph 的承载能力时,系统直接拒绝,并返回 429 给客户。
系统资源流控
FunctionGraph 是逻辑多租服务,控制面和数据面的资源是客户共享的,当非法客户恶意攻击时,会造成系统不稳定。FunctionGraph 针对共享资源实现基于请求并发数的客户流控,严格限制客户可用的资源。另外对共享资源的资源池化来保证共享资源的总量可控制,进而保证系统的可用性。例如:http 连接池、内存池、协程池。
并发数控制
构建基于请求并发数的 FunctionGraph 函数粒度的流控策略,FunctionGraph 的客户函数执行时间有毫秒、秒、分钟、小时等多种类型,常规的 QPS 每秒请求数的流控策略在处理超长执行的请求时有先天不足,无法限制同一时刻客户占用的系统共享资源。基于并发数的控制策略,严格限制了同一时刻的请求量,超过并发数直接拒绝,保护系统共享资源。
http 连接池
构建高并发的服务时,合理的维护 http 的长连接数量,能最大限度减少 http 连接的资源开销时间,同时保证 http 连接数资源的可控,确保系统安全性的同时提升系统性能。业界可以参考 http2 的连接复用,以及 fasthttp 内部的连接池实现,其原理都是尽量减少 http 的数量,复用已有的资源。
内存池
客户的请求和响应报文特别大,同时并发特别高的场景下,单位时间占用系统的内存较大,当超过阈值后,会轻松造成系统内存溢出,导致系统重启。基于此场景,FunctionGraph 新增了内存池的统一控制,在请求入口和响应出口,校验客户请求报文是否超过阈值,保护系统内存可控。
协程池
FunctionGraph 构建于云原生平台上,采用的 go 语言。如果每一个请求都使用一个协程来进行日志和指标的处理,大并发请求来临时,导致有海量的协程在并发执行,造成系统的整体性能大幅下降。FunctionGraph 引入 go 的协程池,通过将日志和指标的处理任务改造成一个个的 job 任务,提交到协程池中,然协程池统一处理,大幅缓解了协程爆炸的问题。
异步消费速率控制
异步函数调用时,会优先放到 FunctionGraph 的 kafka 中,通过合理设置客户的 kafka 消费速率,确保函数实例始终够用,同时防止过量的函数调用,导致底层资源被迅速耗光。
3.函数实例控制
客户实例配额
通过限制客户总配额,防止恶意客户将底层资源耗光,来保障系统的稳定性。当客户业务确实有需要,可以通过申请工单的方式快速扩充客户配额。
函数实例配额
通过限制函数配额,防止单个客户的函数将客户的实例耗光,同时也能防止客户配额失效,短时间内造成大量的资源消耗。另外,客户业务如果涉及数据库、redis 等中间件的使用,通过函数实例配额限制,可以保护客户的中间件连接数在可控范围内。
4.高效的资源弹性能力
流控属于防御式设计思想,通过提前封堵的方式减少系统过载的风险。客户正常业务突发上量需要大量的资源时,首先应该解决的是资源弹性问题,保证客户业务成功的前提下,通过流控策略兜底系统出现异常,防止爆炸面扩散。FunctionGraph 支持集群节点快速弹性、支持客户函数实例快速弹性、支持客户函数实例的智能预测弹性等多种弹性能力,保证客户业务突增时依然能正常使用 FunctionGraph。
重试策略
FunctionGraph 通过设计恰当好处的重试策略,使系统在发生异常的时候,也可以保障客户的请求最终执行成功。如图 4 所示,重试的策略一定要有终止条件,否则会造成重试风暴,更轻松的击穿系统的承载上限。
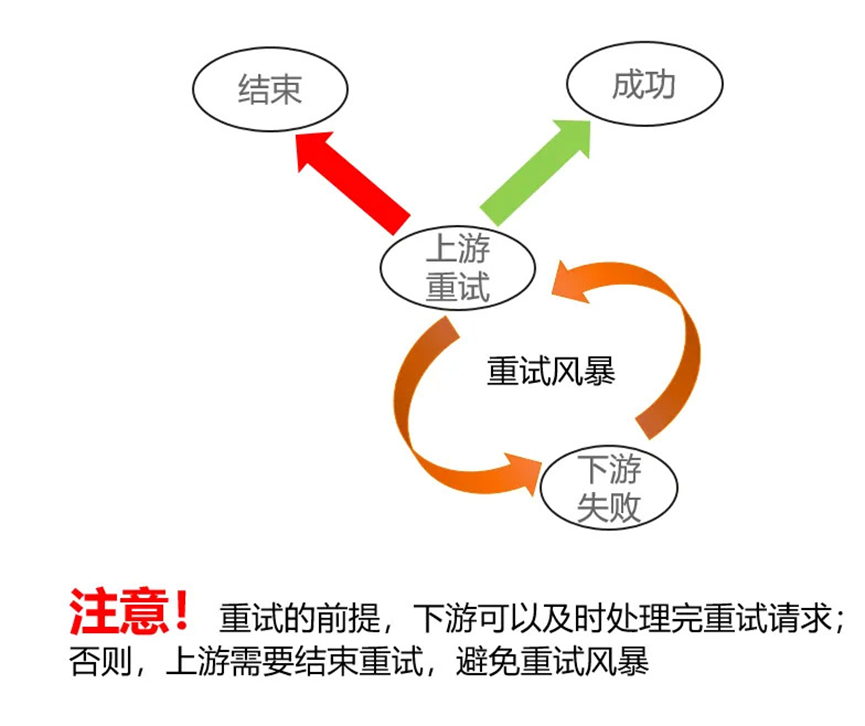
图 4 重试策略
1.函数请求失败重试
同步请求
当客户请求执行时,遇到系统错误时,FunctionGraph 会将请求转发至其他集群,最多重试 3 次,确保客户的请求,在遇到偶现的集群异常,也可以在其他集群执行成功。
异步请求
由于异步函数对实时性要求不高,客户函数执行失败后,系统可以针对失败请求做更为精细的重试策略。当前 FunctionGraph 支持二进制指数退避的重试,当函数由于系统错误异常终止后,函数会按 2,4,8,16 指数退避的方法,当间隔退避到 20 分钟时,后续重试均按照 20 分的间隔进行,函数请求重试时间最大支持 6 小时,当超过后,会按失败请求处理,返回给客户。通过二进制指数退避的方式,可以最大程度保障客户业务的稳定性。
2.依赖服务间的重试
中间件的重试机制
以 redis 为例,当系统读写 redis 偶现失败时,会 sleep 一段时间,再重复执行 redis 的读写操作,最大重试次数 3 次。
http 请求重试机制
当 http 请求由于网络波动,发生 eof、io timeout 之类的错误时,会 sleep 一段时间,在重复 http 的发送操作,最大重试次数 3 次。
缓存
缓存不仅可以加速数据的访问,而且当依赖的服务故障时,仍然可以使用缓存数据,保障系统的可用性。从功能类别划分,FunctionGraph 需要进行缓存的组件有两类,1 是中间件,2 是依赖的云服务,系统优先访问缓存数据,同时定期从中间件和依赖的云服务刷新本地缓存数据。方式如图 5 所示。
1.缓存中间件数据
FunctionGraph 通过发布订阅的方式,监听中间件数据的变化及时更新到本地缓存,当中间件异常时,本地缓存可以继续使用,维持系统的稳定性。
2.缓存关键依赖服务数据
以华为云的身份认证服务 IAM 为例,FunctionGraph 会强依赖 IAM,当客户发起首次请求,系统会将 token 缓存到本地,过期时间 24 小时,当 IAM 挂掉后,不影响老的请求。FunctionGraph 系统的使用。其他关键的云服务依赖做法一直,都是把关键的数据临时缓存到本地内存。
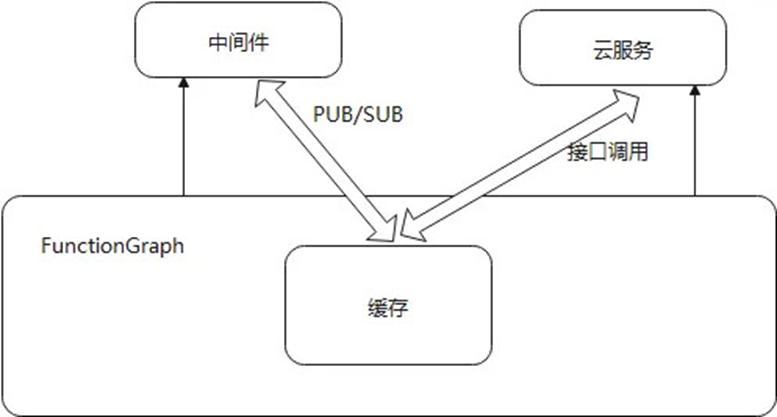
图 5 FunctionGraph 的缓存措施
熔断
上面的种种措施,可以保障客户业务平稳运行,但当客户业务出现异常一直无法恢复或者有恶意客户持续攻击 FunctionGraph 平台,系统资源会一直浪费在异常流量上,挤占正常客户的资源,同时系统可能会在持续高负荷运行异常流量后出现不可预期的错误。针对这种场景,FunctionGraph 基于函数调用量模型构建了自身的断路器策略。具体如图 6 所示,根据调用量的失败率进行多级熔断,保证客户业务的平滑以及系统的稳定。
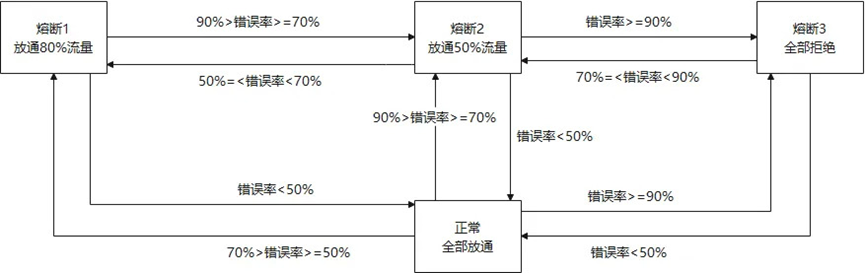
图 6 熔断策略模型
隔离
1.异步函数业务隔离
按照异步请求的类别,FunctionGraph 将 Kafka 的消费组划分为定时触发器消费组、专享消费组、通用消费组、异步消息重试消费组,topic 同理也划分为对等类别。通过细分 consumer 消费组和 topic,定时触发器业务和大流量业务隔离,正常业务和重试请求业务隔离,客户的业务请求得到最高优先级的保障。
2.安全容器隔离
传统 cce 容器基于 cgroup 进行隔离,当客户增多,客户调用量变大时,会偶现客户间的互相干扰。通过安全容器可以做到虚拟机级别的隔离,客户业务互不干扰。
灰度升级
逻辑多租服务,一旦升级出问题,造成的影响不可控。FunctionGraph 支持按 ring 环升级(根据 region 上业务的风险度进行划分)、蓝绿发布、金丝雀发布策略,升级动作简要描述成三个步骤:
1.升级前集群的流量隔离
当前 FunctionGraph 升级时,优先将升级集群的流量隔离,确保新流量不在进入升级集群;
2.升级前集群的流量迁移、优雅退出
将流量迁移到其他集群,同时升级集群的请求彻底优雅退出后,执行升级操作;
3.升级后的集群支持流量按客户迁入
升级完成后,将拨测客户的流量转发到升级集群,待拨测用例全部执行成功后,在将正式客户的流量迁进来。
监控告警
当 FunctionGraph 出现系统无法兜住的错误后,我们给出的解决措施就是构建监控告警能力,快速发现异常点,在分钟级别恢复故障,最大程度减少系统的中断时间。作为系统高可用的最后一道防线,快速发现问题的能力至关重要,FunctionGraph 围绕着业务关键路径,构建了多个告警点。如表 2 所示。

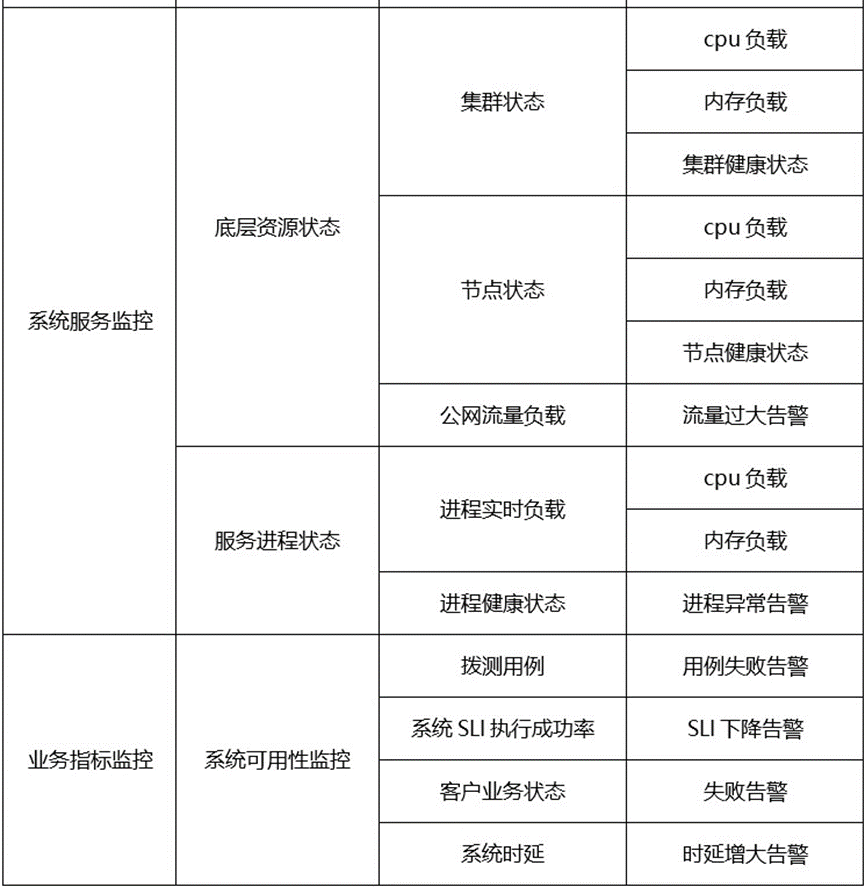
表 2 FunctionGraph 构建的监控告警
流程规范
上面的一些措施从技术设计层面解决系统可用性的问题,FunctionGraph 从流程上也形成了一套规章制度,当技术短期无法解决问题后,可以通过人为介入快速消除风险。具体有如下团队运作规范:
1.内部 war room 流程
遇到现网紧急问题,团队内部快速组织起关键角色,第一时间恢复现网故障;
2.内部变更评审流程
系统版本在测试环境浸泡验证没问题后,在正式变更现网前,需要编写变更指导书,识别变更功能点和风险点,经团队关键角色评估后,才准许上现网,通过标准的流程管理减少人为变更导致异常;
3.定期现网问题分析复盘
例行每周现网风险评估、告警分析复盘,通过问题看系统设计的不足之处,举一反三,优化系统。
客户端容灾
业界最先进的云服务,对外也无法承诺 100%的 SLA。所以,当系统自身甚至人力介入都无法在急短时间内快速恢复系统状态,这时候和客户共同设计的容灾方案就显得至关重要。一般,FunctionGraph 会和客户一同设计客户端的容灾方案,当系统持续出现异常,客户端需要针对返回进行重试,当失败次数达到一定程度,需要考虑在客户端侧触发熔断,限制对下游系统的访问,同时及时切换到逃生方案。
总结
FunctionGraph 在做高可用设计时,整体遵循如下原则“冗余+故障转移”,在满足业务基本需求的情况下,保证系统稳定后在逐步完善架构。
“冗余+故障转移”包括以下能力:
容灾架构:多集群模式、主备模式
过载保护:流控、异步削峰、资源池化
故障治理:重试、缓存、隔离、降级、熔断
灰度发布:灰度切流、优雅退出
客户端容灾:重试、熔断、逃生
未来,FunctionGraph 会持续从系统设计、监控、流程几个维度持续构建更高可用的服务。如图 7 所示,通过构建监测能力快速发现问题,通过可靠性设计快速解决问题,通过流程规范来减少问题,持续提升系统的可用性能力,为客户提供 SLA 更高的服务。
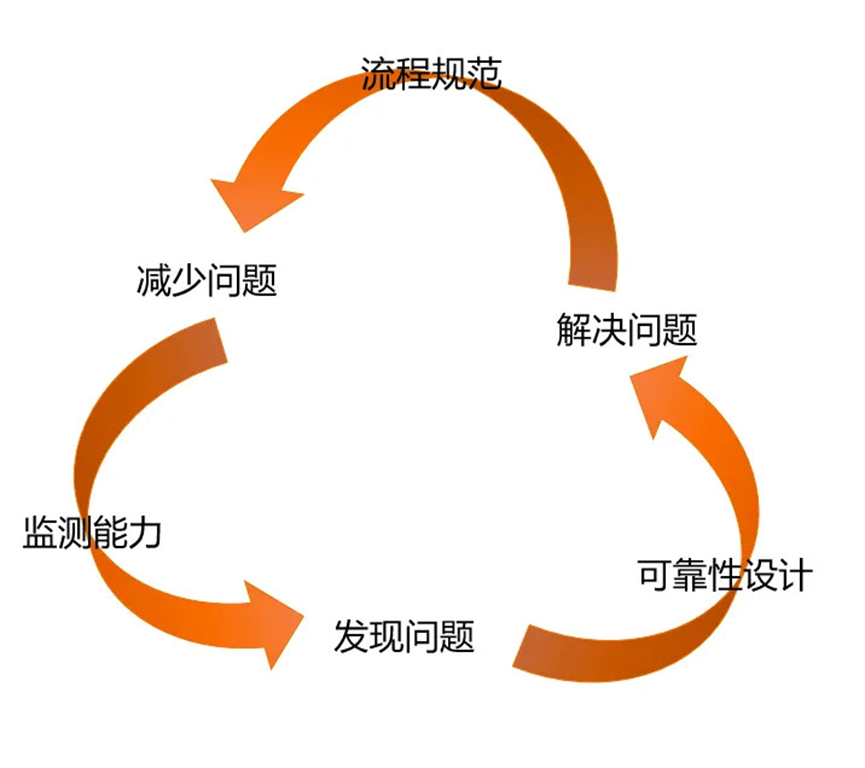
图 7 FunctionGraph 高可用迭代实践
参考文献
[1]高可用定义:
https://zh.wikipedia.org/zh-hans/%E9%AB%98%E5%8F%AF%E7%94%A8%E6%80%A7
[2]SLA 定义:
https://zh.wikipedia.org/zh-hans/%E6%9C%8D%E5%8A%A1%E7%BA%A7%E5%88%AB%E5%8D%8F%E8%AE%AE
审核编辑 黄宇
-
高德地图基于阿里云MaxCompute的最佳实践2018-02-27 4199
-
云上拍客梨视频 基于阿里云的技术实践分享2018-06-28 2167
-
华为云深度学习服务,让企业智能从此不求人2018-08-02 3299
-
构建高可用UPS供电系统2018-09-30 2291
-
【合作伙伴】华为云--智能见未来2022-12-12 1459
-
华为云网站高可用解决方案,保障企业业务连续可用,数据更安全2023-07-04 1227
-
体验华为云 Serverless FunctionGraph,一分钟上线应用2023-09-02 1291
-
云上多活高可用架构,助力企业实现业务无缝切换与持续稳定运行2023-11-08 1456
-
华为云全新上线 Serverless 应用中心,支持一键构建文生图应用2023-11-13 1395
-
华为云耀云服务器 L 实例:保障网站的稳定性和高可用性2023-11-21 883
-
如何构建弹性、高可用的微服务?2023-11-26 1291
-
华为云网站高可用解决方案引爆华为云开年采购季:助力多场景下业务高可用、数据高可靠2024-03-17 907
-
华为云 FunctionGraph 引领 AIGC 革命,赋能智慧未来2024-03-19 1182
-
全球销量领先车企基于 Serverless 服务构建数据实时处理的千万级车联网业务2024-07-11 42854
-
华为云全域 Serverless 8 月更新盘点2024-09-27 1876
全部0条评论

快来发表一下你的评论吧 !
