

使用Ryzen ™ AI处理器构建聊天机器人
描述
人工智能处理器和软件将个人计算的强大功能带到人工智能PC上,将工作、协作和创新的效率提升到一个全新的水平。 生成式AI应用程序(如AI聊天机器人)由于高处理要求而存在于云中。在这篇博客中,我们将探索Ryzen ™ AI技术的构建模块,并展示利用它来构建一个仅在Ryzen AI笔记本电脑上以最佳性能运行的AI聊天机器人是多么容易。
全栈Ryzen™ AI软件
Ryzen AI配备了一个专用的神经处理单元(NPU),用于与CPU内核集成在片上的AI加速。AMD Ryzen AI软件开发工具包(SDK)使开发人员能够采用在PyTorch或TensorFlow中训练的机器学习模型,并在由Ryzen AI支持的PC上运行它们,可以智能地优化任务和工作负载,释放CPU和GPU资源,并以更低的功耗确保最佳性能。了解更多关于Ryzen AI产品的信息。
SDK包括用于在NPU上优化和部署AI推理的工具和运行时库。安装很简单,该套件配备了各种预量化的准备部署模型的拥抱脸AMD模型动物园。开发人员可以在几分钟内开始构建他们的应用程序,在Ryzen AI PC上释放AI加速的全部潜力。
构建AI Chatbot
人工智能聊天机器人需要大量的处理能力,以至于它们通常生活在云中。nbsp;实际上,我们可以在PC上运行ChatGPT,但是本地应用程序通过Internet将提示发送到服务器进行LLM模型处理,并在收到响应后简单地显示响应。
然而,在这种情况下,本地和高效的AI聊天机器人不需要云支持。您可以从Hugging Face下载一个开源的预训练OPT1.3B模型,并通过一个简单的三步过程将其部署在Ryzen AI笔记本电脑上,并使用预构建的Gradio Chatbot应用程序。
步骤1:从Hugging Face下载预训练的opt-1.3b模型
步骤2:量化从FP32到INT 8的下载模型
步骤3:使用模型部署Chatbot应用程序
先决条件
首先,您需要确保满足以下先决条件。
AMD锐龙AI笔记本电脑与Windows®(R) 11个操作系统
Anaconda,如果需要,请从 这里
最新的Ryzen AI AIE驱动程序和软件。遵循简单的单击安装 这里
本博客的辅助材料发布在AMD GitHub存储库中。
接下来,克隆存储库或下载并解压缩Chatbot-with-RyzenAI-1.0.zip到安装Ryzen AI SW的根目录中。在本例中,它是C:UserahoqRyzenAI
cd C:UsersahoqRyzenAI
git clone alimulh/Chatbot-with-RyzenAI-1.0
#激活安装RyzenAI时创建的conda环境。在我的情况下,它是ryzenai-1.0-20231204-120522
Conda activate Ryzenai-1.0-20231204-120522
#使用requirements.txt文件安装gradio pkage。聊天机器人的浏览器应用程序是用Gradio创建的
pip安装-r要求. txt
#初始化路径
setup.bat
现在,您可以通过3个步骤创建聊天机器人:
Step-1从Hugging Face下载预训练模型
在此步骤中,从Hugging Face下载预训练的Opt-1.3b模型。您可以修改run.py脚本,从您自己或您公司的存储库下载预训练模型。Opt-1.3b是一个大的,~4GB的模型。下载时间取决于网速。在这种情况下,它花了~6分钟。
cd Chatbot-with-RyzenAI-1.0
python run.py--model_name opt-1.3b --下载
下载的模型保存在文件夹opt-1.3b_pretrained_fp32中,如下所示。

步骤2量化下载的模型从FP32到Int8
下载完成后,我们使用以下命令对模型进行重新配置:
python run.py--model_name opt-1.3b-python
量化是一个两步的过程。首先,FP32模型是“平滑量化”的,以减少量化过程中的精度损失。它本质上是识别激活系数中的异常值并相应地调节权重。因此,在量化期间,如果离群值被丢弃,则误差引入是可忽略的。Smooth Quant是由AMD的先驱研究人员之一Song Han博士发明的,他是麻省理工学院EECS系的教授。下面是平滑量化技术如何工作的可视化演示。
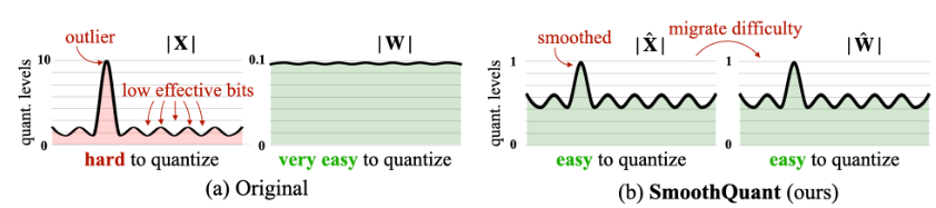
你可以在这里了解更多关于平滑量化(smoothquant)技术的信息。在平滑建模过程之后,条件模型沿着与mart.json文件一起保存在opt-1.3b_smoothquant文件夹的“model_onnx”文件夹中。以下是平滑量化对数的屏幕截图:

平滑量化需要约30秒才能完成。一旦完成,最佳量化器用于将模型转换为int 8。int 8量化模型然后保存在“opt-1.3b_smoothquant "文件夹内的”model_onnx_int8“文件夹中。量化是一个离线过程。大约需要2-3分钟完成,需要一次完成。下面是Int 8量化日志的屏幕截图:
Step-3评估模型并使用聊天机器人应用程序部署它
接下来,评估量化模型并使用以下命令以NPU为目标运行它。注意,模型路径被设置为我们在上一步中保存int8量化模型的位置,
python run.py --model_name opt-1.3b --target aie --local_path。 opt-1.3b_smoothquantmodel_onnx_int8
在第一次运行期间,模型由内联编译器自动编译。编译也是一个两步的过程:首先,编译器识别可以在NPU中执行的层和需要在CPU中执行的层。然后创建子图集。一组用于NPU,另一组用于CPU。最后,它为每个子图创建针对相应执行单元的指令集。这些指令由两个ONNX执行提供程序(EP)执行,一个用于CPU,一个用于NPU。在第一次编译之后,已编译的模型保存在该高速缓存中,因此在后续部署中它避免了编译。下面是一个屏幕截图,其中模型信息是在编译流程中打印出来的。

编译后,模型在NPU和CPU上运行。将应用测试提示。LLM Opt1.3B模型的响应显示了正确的答案。请记住,我们下载并部署了一个公开的预训练模型。因此,它的准确性是主观的,可能并不总是像预期的那样。我们强烈建议在生产部署之前对公开可用的模型进行微调。下面是测试提示和响应的屏幕截图:

现在,让我们使用保存在路径opt-1. 3b-smoothquantmodel_onnx_int 8中的int 8量化模型启动聊天机器人
python gradio_appopt_demo_gui. py——model_file. opt—1.3b_smoothquantmodel_onnx_int8
如命令提示符所示,聊天机器人应用程序在端口1234上的本地主机上运行。
打开浏览器并浏览到http://localhost:1234。
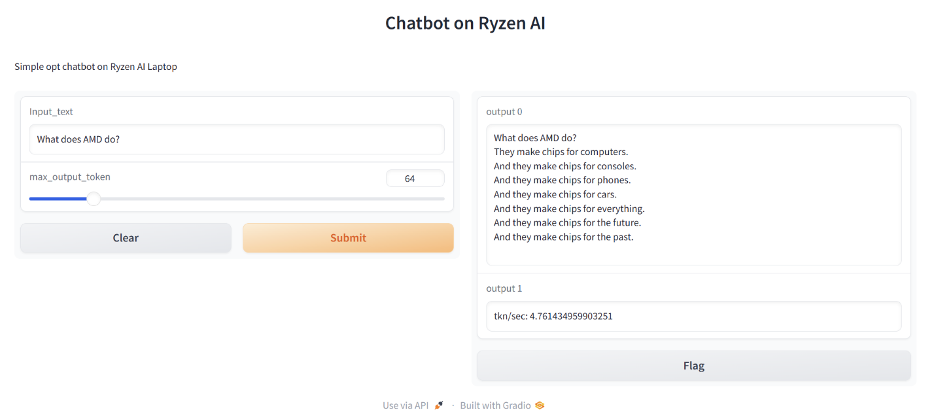
在浏览器应用程序上,设置max_output_token=64并输入提示“AMD做什么?“输入文本框中。聊天机器人输出如下所示的响应。它还将KPI(关键性能指标)计算为token/sec。在这种情况下,它是每秒约4.7个令牌。
恭喜你,你已经成功构建了一个私人AI聊天机器人。它完全运行在笔记本电脑上,OPT1.3B是一种LLM(大型语言模型)。
结论
AMD锐龙™ AI全栈工具使用户能够在AI PC上轻松创建以前无法实现的体验-开发人员使用AI应用程序,创作者使用创新和引人入胜的内容,企业主使用工具优化工作流程和效率。
我们很高兴能将这项技术带给我们的客户和合作伙伴。如果您有任何问题或需要澄清,我们很乐意听取您的意见。查看我们的GitHub存储库以获取教程和示例设计,加入我们的讨论论坛,或发送电子邮件至amd_ai_mkt@amd.com。
审核编辑 黄宇
-
聊天机器人在国内为什么只能做客服?2017-06-20 3829
-
聊天机器人的自动问答技术实现2019-06-03 3189
-
如何利用Python+ESP8266 DIY 一个智能聊天机器人?2022-02-14 2311
-
聊天机器人的作用分析2017-09-20 1231
-
如何避免聊天机器人的5个错误策略2018-12-06 4586
-
一个基于Microsoft聊天机器人Tay的示例2020-04-09 3647
-
构建聊天机器人需要哪些资源?2020-10-27 3231
-
GoGlobal 推出全新 AI 聊天机器人 – ChatGoGlobal2023-04-20 1897
-
聊天机器人开源分享2023-06-20 904
-
全球与中国AI聊天机器人市场:增长趋势、竞争格局与前景展望2023-08-01 2985
-
如何用AI聊天机器人写出万字长文2023-12-26 2639
-
谷歌AI聊天机器人改名为Gemini2024-02-18 2222
-
英伟达推出全新AI聊天机器人2024-02-19 2059
-
ChatGPT 与传统聊天机器人的比较2024-10-25 2107
-
自然语言处理在聊天机器人中的应用2024-12-05 2202
全部0条评论

快来发表一下你的评论吧 !
