

智能驾驶域控制器的SoC芯片选型
描述
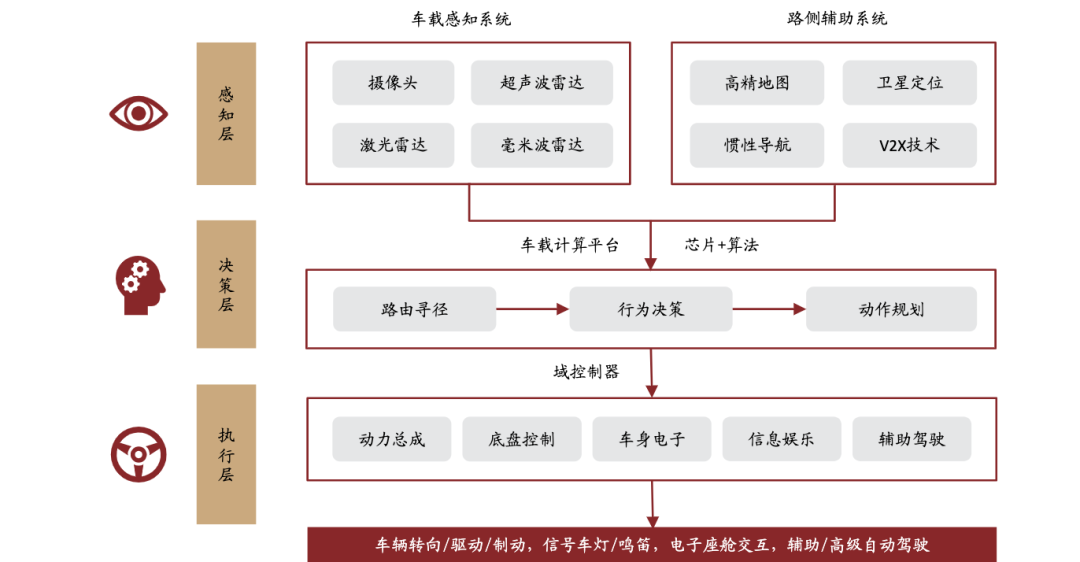
智能驾驶产业链由感知层、决策层、执行层组成。感知层的车载感知系统主要包括摄像头、超声波雷达、激光雷达、毫米波雷达等;路侧辅助系统主要包括高精地图、卫星定位、惯性导航和V2X技术等。决策层主要包括ADAS算法、车载芯片、车载存储器、高精地图、云平台。执行层主要包括电子驱动、电子转向、电子制动、灯光。平台层主要包括大数据、智能驾驶解决方案、传统车联网、智能座舱。终端组成主要包括车载OBU、路测单元RSU、手机APP、边缘计算。
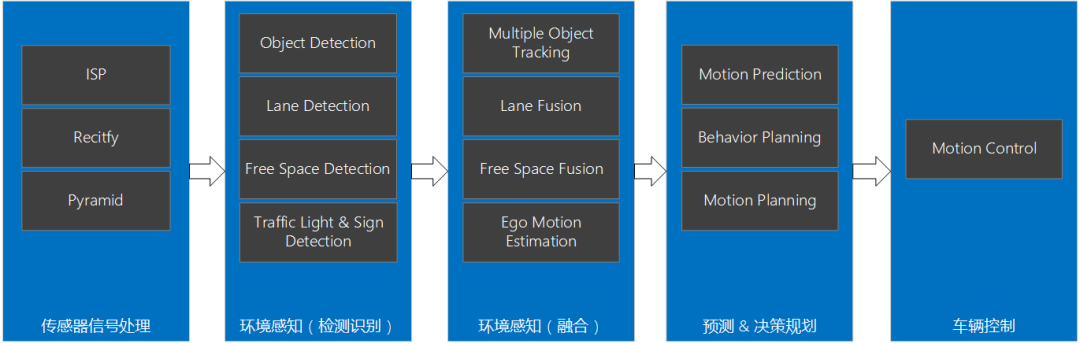
随着智能驾驶行业的发展,智能驾驶功能日益复杂,主流智驾辅助功能渗透率稳步提升,车道保持辅助、紧急制动辅助、自适应巡航、盲区监测、车道居中辅助、并线辅助、自动变道辅助、自动泊车入位、记忆泊车等功能逐渐落地。智能驾驶系统对传感器、算力需求日益旺盛。智能驾驶系统既需要大量的算力,也需要多种类型的计算资源,典型的智能驾驶系统处理流程如下。
智能驾驶系统是一种能够自主感知、决策和执行行驶任务的车辆控制系统。智能驾驶的等级划分通常基于国际标准化组织(ISO)的标准,分为L0到L5六个等级。这些等级反映了自动驾驶系统的成熟度和自动化程度。以下是每个等级的具体描述:
L0:无自动化。驾驶员全权负责驾驶过程,没有任何自动化功能介入。这是传统驾驶方式,不涉及自动驾驶技术。
L1:辅助驾驶功能。车辆提供部分自动化功能,如自适应巡航控制、自动泊车等,但驾驶员仍需承担主要的驾驶任务和责任。自适应巡航控制是一种智能化的巡航系统,能够根据前方路况自动调整车速和车辆行驶姿态,减轻驾驶员的驾驶压力。而自动泊车则是一种自动停车辅助系统,能够在车辆找到合适的停车位后自动完成停车过程,无需驾驶员操作方向盘、油门和刹车等。此外,车道保持功能也是L1级别自动驾驶的一个重要组成部分,它可以通过摄像头和传感器识别道路边界,自动调整车辆行驶轨迹以保持车辆在车道内稳定行驶。这些功能能够辅助驾驶员完成部分驾驶任务,提高驾驶的便利性和安全性。
L2:部分自动化。车辆可以在特定条件下自主完成某些驾驶任务,主要包括自适应巡航、自动泊车、车道保持、变道辅助和自动变道功能等,这些功能能够在一定程度上减轻驾驶员的驾驶压力,提高驾驶的便利性和安全性,驾驶员仍需监控驾驶环境并准备接管。其中,自适应巡航和自动泊车功能在L1级别自动驾驶中已经出现,而在L2级别中得到了进一步的提升和完善。此外,车道保持功能在L2级别自动驾驶中也更加智能化和成熟,能够自动识别道路边界并调整车辆行驶轨迹,保持车辆在车道内稳定行驶。变道辅助和自动变道功能则能够帮助驾驶员在合适时机自动完成变道操作,提升行车安全。
L3:条件自动化。在特定环境下,车辆可以在大部分时间内自主驾驶,驾驶员不必始终保持注意力,但需要在系统请求时及时接管。这个级别的自动驾驶可以在特定情况下完成车辆周边环境的识别和驾驶,并根据收集到的数据进行自主决策和执行相应的操作。除了常规的功能外,还包含了更多复杂场景的自动泊车功能、高速路况的自动驾驶以及记忆式导航等更为高级的自动驾驶功能。具体来说,它能在特定的场景下实现车辆的自动识别车道、自适应巡航、自动变道等功能,甚至在高速公路上自动完成超车动作。此外,还可以根据导航信息自主规划出行路线,并在特定情况下完成自主超车等动作。
L4:高度自动化。车辆可以在各种环境和条件下自主驾驶,驾驶员在大多数时间可以不必参与驾驶,系统可以在特定情况下自主处理复杂路况。在某些情况下,驾驶员可能不需要任何操作。智能驾驶功能主要有自适应巡航、自动泊车、交通拥堵辅助、车道偏离预警和车辆主动避障等功能。当车辆处于复杂环境或不确定情况时,它能自动识别车道并处理紧急事件,如自动变道、自动避让等。此外,它还可以根据导航信息自主规划出行路线,并在特定情况下自主完成驾驶任务,如自动驶入高速公路等场景。总的来说,L4级别的自动驾驶系统已经具备了高度的智能化和自主决策能力。
L5:完全自动化。这是最高级别的自动驾驶,车辆可以在任何环境和条件下完全自主驾驶,驾驶员在车内或车外都可以完全脱离驾驶任务。车辆可以像机器人一样自主行驶和操作。完全自主驾驶:L5级别自动驾驶系统能够在各种道路和环境中完全自主驾驶,无需任何人工干预。自主规划路线:系统可以根据导航目标自主规划最优路线,并自动选择道路、调整速度、避让障碍物等。智能感知和决策:通过高清地图、激光雷达、摄像头等多种传感器,系统能够全面感知周围环境,并实现自主决策和判断。复杂场景处理:系统能够处理复杂场景下的驾驶任务,包括高速公路、市区道路、雨雪天气等环境,并具备应对突发情况的能力。安全保障功能:系统具备多种安全保障措施,如自动刹车、避障、车道保持等,确保乘客和行人的安全。目前许多公司和研究机构都在朝着这个目标努力研发相关技术。需要注意的是,尽管技术发展迅速,但达到L5级别的自动驾驶仍需要解决许多技术和法规方面的问题。
整个智能驾驶系统处理过程通常需要涉及以下几种类型的计算资源:
- 深度学习类:环境感知模块是深度学习算力使用的大户,包括常见的各类图像、激光点云检测算法,比如物体检测、车道线检测、红绿灯识别等,都会涉及大量的典型神经网络(NN)的运算。此类模块通常使用高度定制化的NN加速器来实现。
- 视觉处理类:此类属于计算密集型,但并非深度学习类的算法模块,比如图像信号处理(ISP)、图像金字塔(Pyramid)、畸变矫正(Rectify)、局部特征提取、光流跟踪、图像编解码(Codec)等运算。此类模块通常使用硬化的专用视觉加速器来实现低时延。
- 通用计算类:虽然定制化的深度学习、视觉处理加速器可以满足大部分常见的成熟的计算密集型运算,但仍然无法覆盖全部需求。随着前沿技术的快速发展和自研技术的深入,往往还会产生相当一部分自定义的运算模块。此类模块通常也是计算密集型的操作,无法使用CPU高效实现,因此还需要通用的计算密集型处理单元(比如DSP、GPU)来实现。
- 逻辑运算类:此类模块包含大量的逻辑运算,不适合使用计算密集型的处理器实现,一般使用通用的CPU处理器来实现。此类模块包括常见的多传感器感知融合算法(比如卡尔曼滤波KF)、基于优化的决策规划算法、车辆控制算法、系统层面的功能逻辑、诊断逻辑、影子模式数据挖掘功能等。
典型的智能驾驶系统算力部署参考如下图。

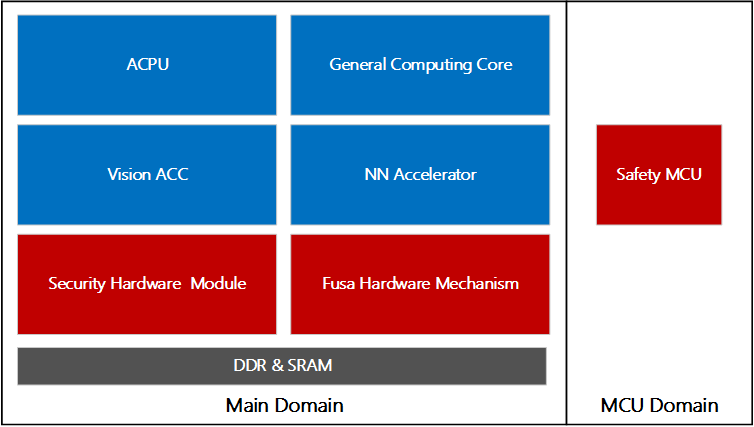
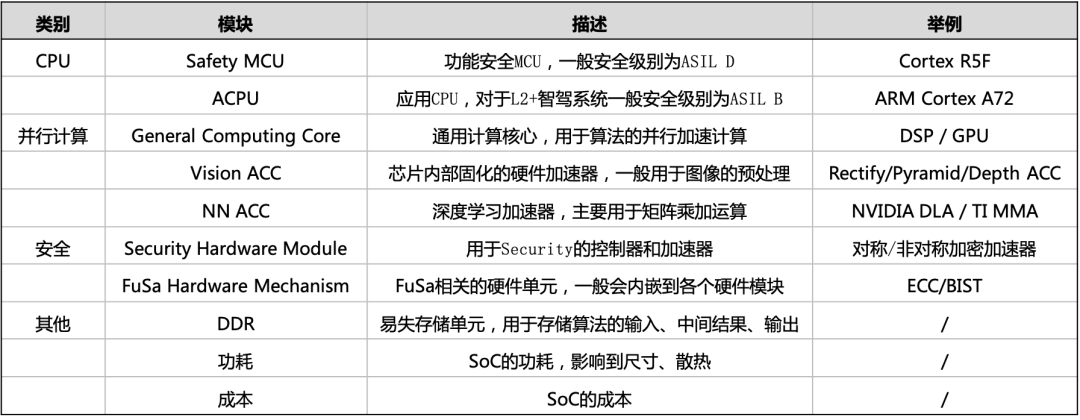
智能驾驶系统设计之初就得考虑芯片选型,如何在众多的SoC芯片选型是一门复杂的系统工程,不单需要考虑深度学习算力,还需要考虑CPU算力、安全、内存带宽、功耗、成本等。大疆车载在智能驾驶核心芯片的选型上积攒了一些经验,在此予以分享。 一颗典型SoC的主要组成:
1、CPUCPU的内部架构可以简化为如下模型。
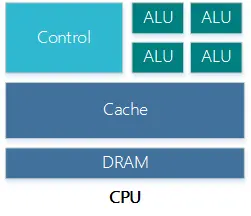
CPU内有负责取指/分支预测/数据转发等的Control、逻辑运算的ALU、高速缓存Cache和DRAM等存储单元。相对GPU等并行运算核心,CPU的Control单元和存储单元功能更加强大,适合做逻辑控制。
在车载SoC中,根据功能不同CPU又分为Safety MCU和ACPU,前者性能较弱但实时性和安全性更强,后者多核心、高主频、性能强大但实时性和安全性有所降低。
1.1、Safety MCUSafety MCU有多种常见的CPU架构,如英飞凌的TriCore、瑞萨的G3KH、ARM Cortex M7、ARM Cortex R5F。既有外置安全的MCU方案,也有内置安全的MCU方案,如德州仪器TDA4内置Cortex R5F,SoC一般会内置Safety MCU来提高系统的集成度。
例如,Cortex R5F MCU核心的内部架构复杂程度参考下图,主要特点如下:
- 8级流水线;
- CPU主频可以支持到1.0 Ghz,远超传统MCU;
- Data Processing Unit负责各种运算和逻辑控制;
- FPU负责浮点运算;
- L1 Instruction/Data Cache是一级缓存,参考容量16KB+16KB;
- Memory Protection Unit用于内存保护,保护能力有限,一般只能支持十几个区域的保护;
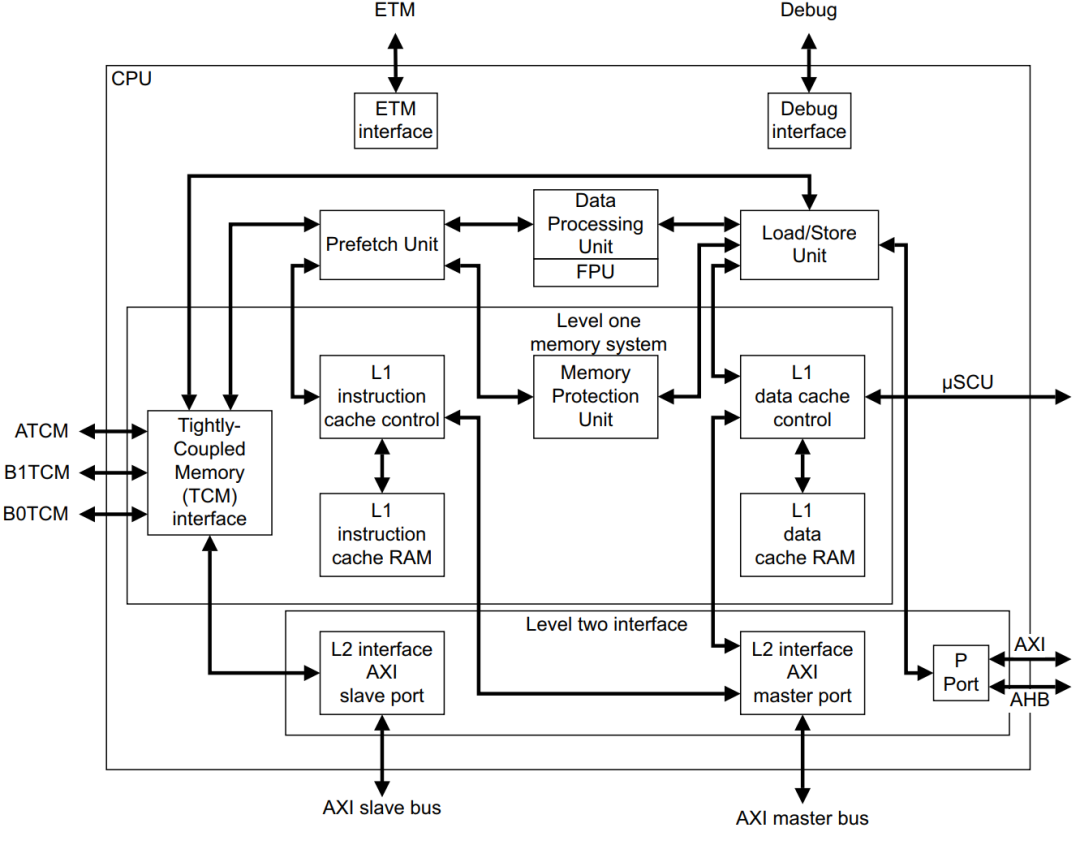
引自《DDI0460D_cortex_r5_r1p2_trm.pdf》
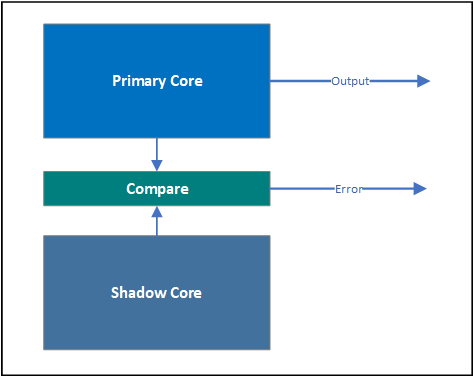
在Safety MCU(安全微控制器)的设计中,一个关键的特性是采用了所谓的锁步核架构,这一架构通过成对出现的核心——通常被称为“Primary Core”和“Shadow Core”——来实现高可靠性的操作。这种设计通过一种独特的方式确保了MCU在复杂环境中的稳定性和安全性。锁步核技术的核心在于,两个核心在指令级别上实现了完全同步的操作,即它们在同一时刻执行相同的指令,并产生相同的结果。为了确保两者的一致性,系统配备了一个“Compare”机制,该机制会周期性地比较两个核心的输出结果。如果比较结果显示两者结果相同,则MCU继续正常运行;若结果不同,则表明系统中可能出现了错误或故障,此时需要采取适当的安全措施,如关闭系统或进行故障隔离。虽然锁步核架构使用了两个核心,但从计算能力的角度来看,它实际上只相当于一个核心的性能。这是因为两个核心必须保持同步,并且在任何时刻都执行相同的指令。然而,这种设计上的限制换来了更高的可靠性和安全性。锁步核技术是实现MCU核心高诊断覆盖度的一种传统而有效的方法。通过在Primary Core和Shadow Core之间进行比较,系统能够在第一时间检测到潜在的错误或故障,从而避免它们对系统稳定性和安全性造成威胁。经过多年的实践验证,这种方法已经在微控制器和复杂度较低的微处理器领域展现出了其卓越的性能和可靠性。
Safety MCU除要求CPU核心达到ASIL D外,往往会要求内部总线、外设接口、电源等跟Main Domain隔离。否则,可能因为低安全级别的Main Domain的异常,如错误操作外设寄存器,导致MCU Domain异常。
Safety MCU的算力一般使用KDMIPS(Kilo Dhrystone Million Instructions executed Per Second)表示,如Cortex R5F的算力约2 KDMIPS。
因为MCU运算和内存资源比较有限,且不支持MMU(Memory Management Unit,比MPU强大的内存管理单元),一般只能运行如FreeRTOS之类的小型RTOS。车载行业一般要求RTOS达到ASIL D级别,常用的MCU RTOS主要有AUTOSAR OS, SafeRTOS。一般没有配套的libc和STL库,对C++的支持不够友好,比较难开发维护复杂软件。因为Safety MCU的软硬件的安全性和实时性都较高,一般用于运行整车的数据交互、诊断、控制算法等软件。
综上,我们在进行Safety MCU选型时,除了关注Safety MCU的算力,还需要重点关注总线、外设等的隔离性,另外也需要关注片内RAM的大小,全球汽车MCU原厂有恩智浦、德州仪器、意法半导体、微芯、英飞凌、瑞萨、芯力能、英特尔/Mobileye、高通、英伟达、安霸、ARM、特斯拉、比亚迪半导体、杰发、芯驰、芯旺、芯擎、芯钛、黑芝麻智能、昆仑芯、后摩智能、西井科技、奕行智能、寒武纪行歌、海思、地平线、爱芯元智、元视芯、兆易创新、中颖、中微半导、芯海、国芯科技、杰发科技、肇观电子、美仁、辉芒微、比亚迪半导体、智芯科技、旗芯微、航顺、赛腾微、琪埔微、小华半导体、云途半导体、曦华科技、复旦微电、国民技术、极海、先楫半导体、紫光国微、蜂驰高芯、灵动微、东软载波、希格玛微电子、汇春科技、华芯微电子、爱思科微电子、凌欧创芯、峰岹科技、泰矽微、旋智科技、芯弦半导体、盛骐微、君正、士兰微、晟矽微电、耐能、芯科集成、澎湃微、恒烁、钜泉、奕斯伟、凌思微、全志、华大北斗、瑞芯微等。

1.2、ACPU常用的ACPU的架构有MIPS和ARM,但以ARM的Cortex A系列为主。相比较MCU,ACPU的架构更复杂、主频更高、Cache和RAM性能更优,整体性能更强。
例如,Cortex A72 ACPU核心的内部架构复杂程度参考下图,比Safety MCU要复杂许多,相同主频下算力约为Cortex R5F的3倍,主要升级如下:
- 15级流水线:- Branch prediction可以提升分支预测的成功率;- Decode可以支持多条指令并行解码;- Dispatch可以支持同时发射多条指令;- Interger execute / Adv SIMD and FP / Load store等多个执行单元可以并行工作;
- 可以支持更高的CPU主频,如2.0 GHz;
- Instruction / Data Cache是一级缓存,参考容量48KB+32KB;
- 二级缓存一般较大,参考容量1MB,可极大降低指令和数据Cache Miss的概率,减少对DDR的访问;
- 支持MMU,可实现内核态和用户态之间、不同进程之间的地址隔离,提高内存访问的安全性;
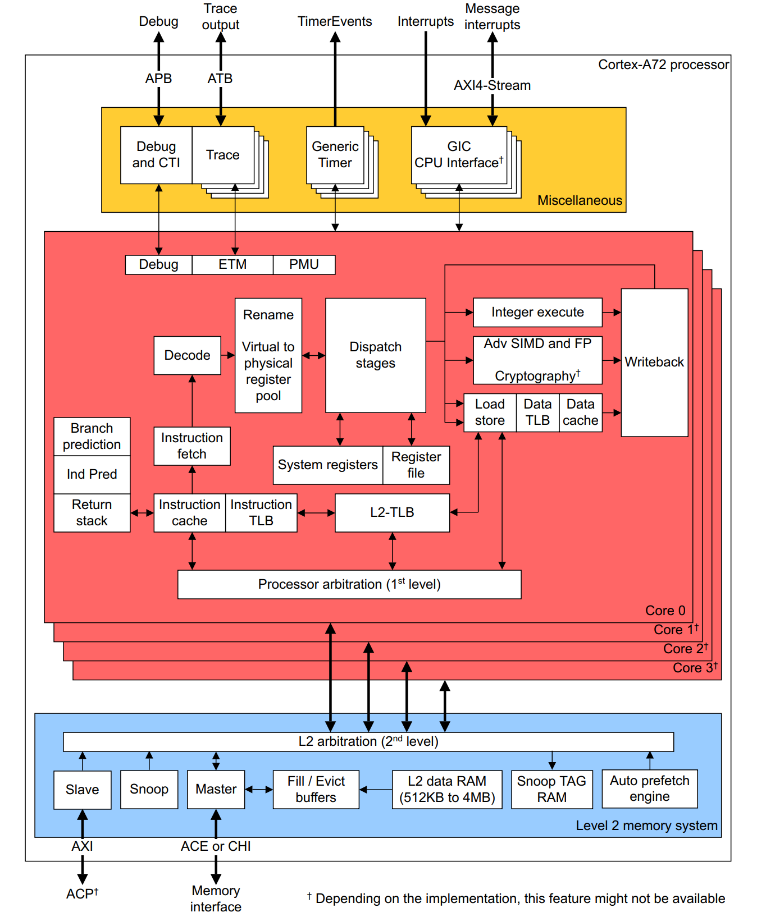
引自《cortex_a72_mpcore_trm_100095_0003_06_en.pdf》
对L2+系统,除要求ACPU核心达到ASIL B外,常用外设一般也要求达到ASIL B,如IPC/DMA/CSI,具体硬件安全级别要求依赖功能安全分解。
ACPU的算力一般使用KDMIPS表示,如Cortex A72的算力约11 KDMIPS。ACPU的算力取决于使用的CPU核心的架构和CPU的主频,一般架构越新支持的主频越高,常用CPU核心算力信息参考如下。
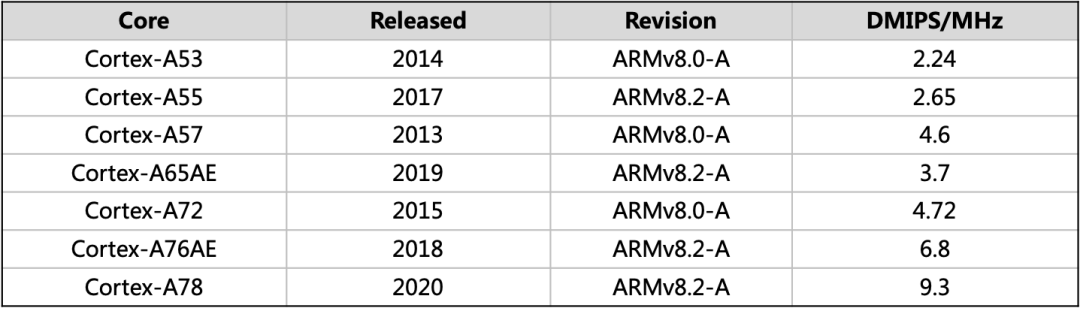
以AE结尾的ACPU Core可以支持锁步,实现ASIL D功能安全级别,如Cortex-A65AE。未来L3~L4系统会对ASIL D ACPU算力有越来越多的需求。
ACPU不仅主频高,资源充足,还具备运行大型操作系统如Linux的能力,为智能驾驶系统提供了强大的计算平台。在L2+级别的智能驾驶系统中,功能安全要求往往对操作系统提出了ASIL B级别的严格标准。在这种情况下,QNX或VxWorks等操作系统成为了首选。这些操作系统不仅支持多进程并发执行,而且每个进程都拥有独立的地址空间,实现了进程间的有效隔离。这种设计确保了系统的稳定性和安全性,即使某个进程崩溃,也不会影响到其他进程的正常运行。同时,这些操作系统还支持智能驾驶系统中成百上千个线程的复杂调度。通过高效的线程管理机制,系统能够充分利用ACPU的多核性能,实现快速响应和高效处理。这对于实现智能驾驶系统的各种复杂功能,如传感器数据的预处理、加速器的调度、感知融合、导航规划等至关重要。
ACPU在智能驾驶系统中的应用不仅限于软件模块的部署。随着NN(神经网络)算力的增加,ACPU需要处理更多的传感器数据、更高分辨率的相机图像以及更复杂的场景和功能。为了满足这些需求,ACPU的算力也在不断提升。现在,ACPU能够支持更多高分辨率传感器数据的预处理、深度学习模型的前后处理、更复杂的感知融合功能以及轨迹预测和行为规划等任务。这些功能的实现都离不开ACPU强大的计算能力和高效的处理速度。此外,ACPU还配套了功能安全认证的libc和STL库等开发工具,为上层软件的开发提供了极大的便利。这些工具不仅提高了开发效率,还确保了软件的安全性和可靠性。
综上,ACPU的选型需要重点关注算力,同时需要留意外设和操作系统的功能安全级别。此外,ACPU算力应该和NN算力相匹配,以发挥最优的系统性能。
2、并行计算2.1、DSPDSP芯片,也称为数字信号处理器,是一种具有特殊结构的微处理器,相比于通用CPU,更适用于计算密集度高的处理。
在DSP芯片内部,通常采用程序和数据分开的哈弗结构,广泛采用流水线操作,同时具有专门的硬件乘法器,提供特殊的DSP指令,可以用来快速的实现各种数字信号处理算法。
DSP芯片一般具有如下的主要特点:
- 程序和数据空间分开,可以同时访问指令和数据;
- 片内具有快速RAM,通常可通过独立的数据总线进行连接;
- 有专门的硬件乘法器,在一个指令周期内可完成一次乘法和一次加法;
- 具有低开销或无开销的循环及跳转的硬件支持;
- 在单时钟周期内可以操作多个硬件地址发生器;
- 具有快速中断处理和硬件I/O支持;
- 支持流水线操作,使不同指令之间的取指、译码和执行等操作可以并行执行;
与通用微处理器相比,DSP芯片的其他通用功能相对较弱一些。DSP结构示图如下。
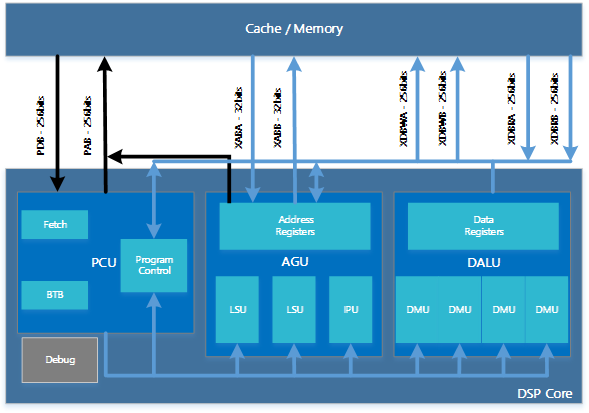
通过独立的指令总线和数据总线与外部数据存储进行连接,外围通常会配置L1和L2 cache,提高数据存取效率。
内部主要分为程序控制单元(PCU)、地址发生单元(AGU)和数据计算单元(DALU),外加一些地址寄存器和数据寄存器。每个处理单元都是独立的硬件模块,通过指令流水将各个模块并行起来处理,提高DSP的处理能力。
在DSP评估过程中,运算速度是DSP芯片的一个最重要的性能指标,通常有如下几个方面的考量:
- 数据位宽长度;
- 单周期内的乘累加个数;
- 寄存器个数;
- 单周期内同时可处理的指令个数;
- 内联指令丰富程度;
- 外围SRAM大小;
随着DSP在图像、音频和机器学习领域的应用,芯片厂商对DSP也同样做了新场景的适配和支持,如TI的C71 DSP,除了支持常见的标量运算和矢量运算,还增加的矩阵乘加速器(MMA),进一步的提升了DSP的专用能力,让开发者更容易进行NN模型部署。
业内知名的DSP芯片厂要包括德州仪器、亚德诺等。也有多家国产DSP芯片进军汽车市场,包括进芯电子、中科昊芯等。其中进芯电子已经推出了32位浮点DSP芯片AVP32F335系列产品,中科昊芯即将推出HXS320F280039C、HXS320F28379D等32位浮点RISC-V DSP芯片产品。
2.2、GPUCPU的功能模块多,适合复杂的运算场景,大部分晶体管用在控制电路和存储上,少部分用来完成运算工作。GPU的控制相对简单,且不需要很大的Cache,大部分晶体管被用于运算,GPU的计算速度因此大增,拥有强大的浮点运算能力。
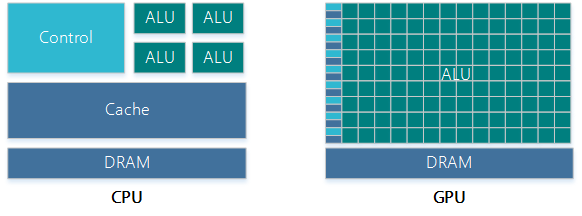
CPU与GPU架构对比示意图当前的多核CPU一般由4或6个核组成,以此模拟出8个或12个处理进程来运算。普通的GPU就包含了几百个核,高端的有上万个核,这对于处理大量的重复处理过程有着天生的优势,同时更重要的是,它可以用来做大规模并行数据处理。
在应用方面,GPU适合前后计算步骤无依赖性、相互独立的计算场景,很多涉及到大量计算的问题基本都有这种特性,比如图形学的计算、挖矿和破解密码等,这些计算可以分解为多个相同的小任务,每个小任务由GPU中的单个核处理,GPU通过众核并发的方式提高同时处理小任务的个数,从而提高计算速度。而CPU更适合前后计算步骤严密关联,逻辑依赖较高的计算场景。
GPU相比CPU有几个特点:
- 运算资源非常丰富;
- 控制部件占得面积非常小;
- 内存带宽大;
- 内存延时高,对比CPU使用多级缓存缓解延时,GPU采用多线程的方式处理;
- GPU处理需要数据高度对齐;
- 寄存器资源极为丰富;
实际CPU与GPU最大的区别是带宽,CPU像法拉利,跑的很快,但要是拉货,就不如重卡。GPU像重卡,跑的不快,但一次拉货多。有些货可以全部打包装车运输,如这些货都来自一个地方,大小相同,需要运输到一个地方,这就是计算密集型任务。有些货不行,比如这些货要去不同地方,体积大小不一,不能多个打包,只能多次运输,这就是控制密集型任务。CPU在缓存、分支预测、乱序执行方面花了很多精力,用大量寄存器实现这些功能,保证了高速度,频率一般都远高于GPU,每次速度很快,但大量寄存器占用大量空间,考虑到成本以及半导体的基本定律(单颗die面积不超过800平方毫米,否则良率会急速下降),CPU的核心数非常有限,每次能带的货很少。GPU相反,不考虑分支预测与乱序执行,用最快的寄存器代替缓存,结构简单,晶体管数量少,可以轻易做到几千核心,每次能带的货很多,但速度不快。所以,相对来说,GPU更适合处理分支少,数据量大,计算简单且重复的运算任务。
2.3、深度学习能力广义上来说,只要能够运行人工智能算法的芯片都叫做深度学习芯片。但是通常意义上的深度学习芯片,指的是针对深度学习算法做了特殊加速设计的芯片。
通常来说,深度学习芯片普遍以OPS(Operations Per Second)为单位来评估深度学习的理论峰值算力。OPS的物理计算单位是乘积累加运算(Multiply Accumulate, MAC),是在微处理器中的特殊运算。1 * MAC = 2 * OPS。实现此运算操作的硬件电路单元,被称为“乘累加器”。这种运算的操作,是将乘法的乘积结果b*c和累加器a的值相加,再存入累加器a的操作:a ← a + b*c
深度学习算力理论值取决于运算精度、MAC的数量和运行频率。对于定点和浮点计算单元共用核心的加速器,可大致简化为INT8精度下的MAC数量在FP16精度下等于减少了一半,FP32再减少一半,依次类推。例如,假设芯片内有512个MAC运算单元,运行频率为1GHz,则INT8的算力为512 * 2 * 1GHz = 1TOPS(Tera Operations Per Second),FP16的算力为0.5TOPS,FP32的算力为0.25TOPS。
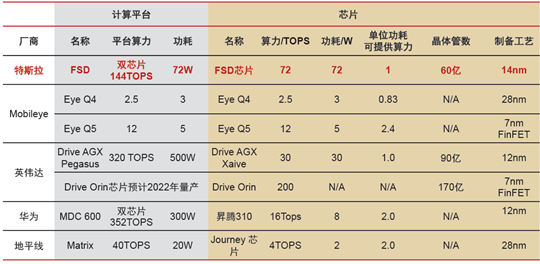
通常,各大芯片厂商宣传的TOPS往往都是运算单元的理论值,而非整个硬件系统的真实值。实际运行起来,真正的有效算力可能只有理论值的30%算力,甚至更低。这里就涉及到“算力利用率”的概念。比如说,某个神经网络模型需要的理论算力是1TOPS,而实际运行的SoC的标称算力是4TOPS,那么利用率只有25%。以下是特斯拉、Mobileye、英伟达、华为、地平线芯片的算力对比表。
以ResNet-50及MobileNet V1网络在SoC A和SoC B上的运行数据为例,实际的有效算力会因为图片分辨率、网络结构差异等原因而不同。
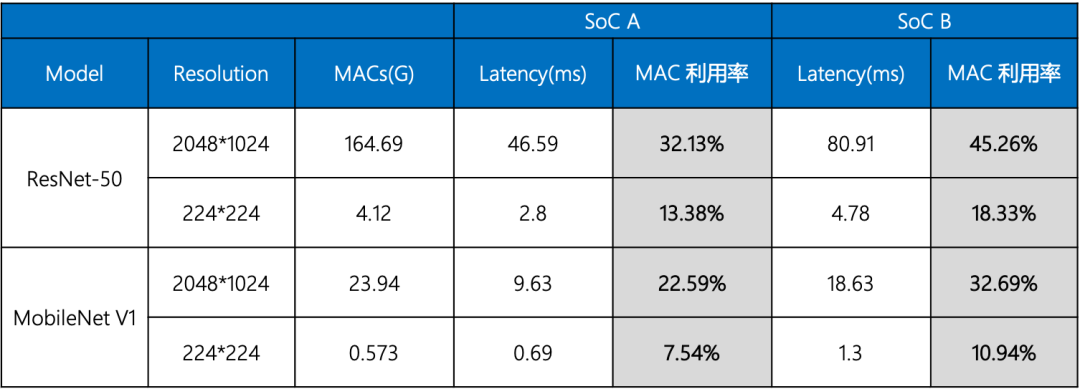
这又是什么原因呢?通常来说,实际的有效算力主要受两方面的影响:1)处理器的计算架构:从上表可以看到,即使是同一款SoC,对不同网络结构的利用率差异也非常大。这是因为深度学习加速器本身是高度定制化的计算架构,只有执行和加速器特性比较匹配的网络结构才能发挥出较高的利用率。
2)存储带宽:存储带宽决定数据搬运的速度。如果存储带宽跟不上计算速度,则数据无法及时到达计算单元,导致处理器的计算单元空置,从而导致处理器的算力利用率大打折扣。智能驾驶应用的处理场景通常具有图像分辨率大、并行样本量(batch size)小、网络结构小的特点,这对于存储带宽的要求通常会更高。
同汽车的动力指标,马力不如百公里加速时间更真实反映整车动力性能;同理,有效算力比理论算力更能反映芯片实际性能。所以,在SoC选型时需要重点关注SoC全系统能够提供的有效算力。
2.4、算力多样化需求在深度学习推理端,各家芯片往往都会根据自家的神经网络推理框架设计对应的NN处理器,各种TPU/NPU/DPU…层出不穷,芯片厂家根据神经网络特点,通过定制化的设计处理器,使得软硬件的适配度更高,从而提高芯片算力的利用率。
市场上,除了NN处理器,像高通/德州仪器等公司的车载芯片,在SoC上配备了GPU/DSP/CV加速器等通用算力处理器来提高车载芯片的处理能力和算法开发的扩展性。
在智能驾驶系统中,大部分的计算可以通过深度学习处理器来完成。但是,对于一些算法开发能力较强的公司来说,会根据实际的业务场景需求,来设计自己的神经网络结构,芯片厂商提供的NN处理器的算子库无法满足他们的需求,往往存在一些自定义算子的开发。另外,ISP、多传感器融合、定位与建图等功能还会涉及一些非深度学习的视觉算法的实现。此时,车载芯片上的GPU/DSP/CV加速器将可以很好的补充这部分算力需求。
DSP能够提供低功耗的矢量处理能力,相比于CPU,可以使用DSP的SIMD指令很好的应对并行度高,数据连续性较好的算法。对于并行度高,但是数据连续性较差的算法,如果部署在DSP上,将对IO带宽带来很大的挑战,无法充分发挥DSP的计算能力,但是GPU的高并发特点,可以很好的应对这种算法。同时,GPU的图像处理能力能够满足智能驾驶场景中渲染和可视化的需求。
综上,SoC选型时,需要根据业务需求,合理规划和分配算力,实现SoC各个模块协调高效合作,而非只关注深度学习算力。
3、安全3.1、网络安全(Cybersecurity)随着UNECE WP29 R155法规、ISO/SAE 21434标准的发布,国内也紧跟着发布了一系列车载网络安全相关的国标、法规,包括网络安全技术相关的、流程相关的、数据保护相关的等等,这一切表明网络安全在智能网联汽车行业的重视程度在逐日提升。
网络安全机制的实现讲究纵深防御,上层包括面向服务的应用防火墙、对服务访问的鉴权和授权等,中间层包括操作系统的进程访问权限管理、文件系统加密、以太网防火墙、安全通信、调试接口管控、安全审计等,底层包括安全启动、安全升级、安全存储、密钥管理等基础功能。在芯片选型时,关于网络安全往往会考虑如下方面:
- 芯片的封装。尽量选择BGA封装的芯片。
- 芯片防信道攻击的能力。目前很多侧信道攻击的手段可以很轻易获取到芯片运行时的关键资产,例如密钥。
- 芯片的调试接口。例如JTAG,可通过某种硬件机制永久关闭,或者可通过软件安全机制控制芯片调试接口的开关。
- 芯片的安全启动。安全启动一般起始于芯片的BootRom,通过校验固件的签名,来防止固件被恶意篡改,确保了固件的完整性。
- 芯片的安全运行环境。该运行环境主要用于管理芯片运行时的关键资产,例如芯片的安全配置、密钥等,并通过硬件来实现安全算法加速服务。
- 芯片的内存保护单元。例如MMU或MPU,该单元一般集成在处理器中,由运行在处理器上的操作系统进行配置,实现运行态的内核/进程/线程的地址虚拟化和数据隔离。
- 芯片唯一SN。一般会用于绑定、认证等安全业务。
除了以上技术要求之外,在芯片选型时,也需要考虑供应商网络安全资质的要求,例如是否有CSMS管理体系。
3.2、功能安全(FuSa)众所周知 “智能驾驶、安全第一”。SoC作为智能驾驶控制器的核心,其安全性能是确保最终交付安全产品的关键。因此在SoC芯片的设计选型中,必须把功能安全作为核心指标进行评估:
- SoC芯片支持的功能安全完整性等级(ASIL)是否满足最终产品的安全等级需求;
- SoC芯片的安全设计是否匹配当前的产品的功能安全概念;
- SoC芯片是否全面考虑支持不同驾驶自动化等级产品应用;
为了实现上述目标,同时需要对SoC供应商的功能安全的设计和开发能力进行全面评估:
- 对SoC的安全设计概念进行评估,包括安全需求、安全状态、故障容错时间间隔等;
- 对SoC的安全机制设计进行评估,包含诊断机制、自检机制、安全隔离和冗余设计等;
- 对SoC的安全分析结果进行评估,包括定性安全分析、定量安全分析和相关失效分析结果等;
- 对SoC的开发工具链的鉴定报告进行检查,包括工具软件的置信度评估结果,软件工具开发过程评估等;
- 对厂商提供的SoC相关的安全审核、认证和评估结果进行检查,包括是否是独立的第三方审核和评估,评估范围、评估报告的等;
功能安全的级别跟SoC的功能安全目标相关。评估时需要细分SoC内部各个模块的功能安全等级,从软件和硬件维度,确认SoC的功能安全设计是否能够全面、有效的满足自家产品的安全需求。在产品应用层面,还需要全面评估产品引入功能安全设计后,潜在的SoC算力需求增加、通信带宽增大、存储容量需求增加等方面的变化,确保SoC安全功能设计能够在项目中完整落地。
4、其他4.1、内存带宽SoC内部的CPU、NN加速器、GPU等除了执行指令外,还会从DDR读取指令和读写数据。但DDR的访问不能单周期完成,典型的访问延时100ns+。尽管Cache在一定程度上可以缓解DDR的访问延时问题,但考虑到多核心并发、随机访问DDR,DDR带宽往往会成为CPU和各个加速器运行的瓶颈。例如,假设NN加速器处理一帧图像,50ms用于DDR数据的加载和存储,50ms用于在数据运算,此时帧率是10Hz;如果DDR的带宽减半,此时需要100ms用于DDR数据的加载和存储,50ms用于在数据运算,此时帧率为6.7Hz。可见,DDR带宽可以间接影响各个处理器和加速器的运行的效率。
常用的单通道(32bit) DDR的频率和带宽参考如下。

如下图为内存多通道交织的例子:如果只使用一个通道,对DDR的访问是单通道串行的;如果CPU同时连接到4通道的DDR,4个通道之间的访问可以并发,提高DDR带宽。
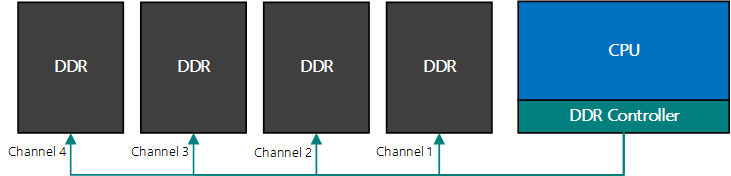
综上,除了关注DDR的单通道带宽外,还需要重点关注DDR的通道数,如理论上双通道的DDR带宽是单通道的2倍。
4.2、功耗和成本相同的芯片规格,芯片的工艺会直接影响到芯片的功耗,如7nm和16nm 30T算力的SoC功耗大约为15W和30W。算力的增加同样会增加功耗,如7nm 30T和200T算力的SoC功耗大约为15W和100W。功耗的大小又会影响到结构和散热,较高的功耗需要增加风扇、尺寸、铜管、材料等,进一步增加域控制器的成本。
算力的增加也意味着芯片成本的增加,如200T算力的SoC的价格约为30T算力的SoC的7倍,所以在选择芯片规格的时候也要重点关注对算力的真实需求,过多的预留可能会导致成本的浪费。
4.3、丰富的IO接口资源自动驾驶的主控处理器需要丰富的接口来连接各种各样的传感器设备。目前业界常见的自动驾驶传感器主要有:摄像头、激光雷达、毫米波雷达、超声波雷达、组合导航、IMU以及V2X模块等。
- 对摄像头的接口类型主要有:MIPI CSI-2、LVDS、FPD Link等;
- 激光雷达一般是通过普通的Ethernet接口来连接;
- 毫米波雷达都是通过CAN总线来传输数据;
- 超声波雷达基本都是通过LIN总线;
- 组合导航与惯导IMU常见接口是RS232;
- V2X模块一般也是采用Ethernet接口来传输数据。
除了上述传感器所需IO接口外,常见的其它高速接口与低速接口也都是需要的,比如:PCIe、USB、I2C、SPI、RS232等等。
4.4、芯片的生态(工具链)芯片整个软件的工具链或者对一些算法的开发是不是能满足客户的需求。也就是说芯片的生态怎么样,是否具备一个良好的生态系统能够支撑客户做可落地化的开发,也是主机厂或Tier1在选择芯片时候的重要考量因素之一。
根据盖世汽车研究院数据显示,2023年高通座舱域控芯片装机量超226万颗,市场占比近六成。排在高通之后的同样是从消费电子芯片领域跨界而来的AMD,其2023年座舱域控芯片装机量近57.6万颗,市场占比超15%。这主要来自于为特斯拉代工的和硕与广达,对应车型为Model 3与Model Y。
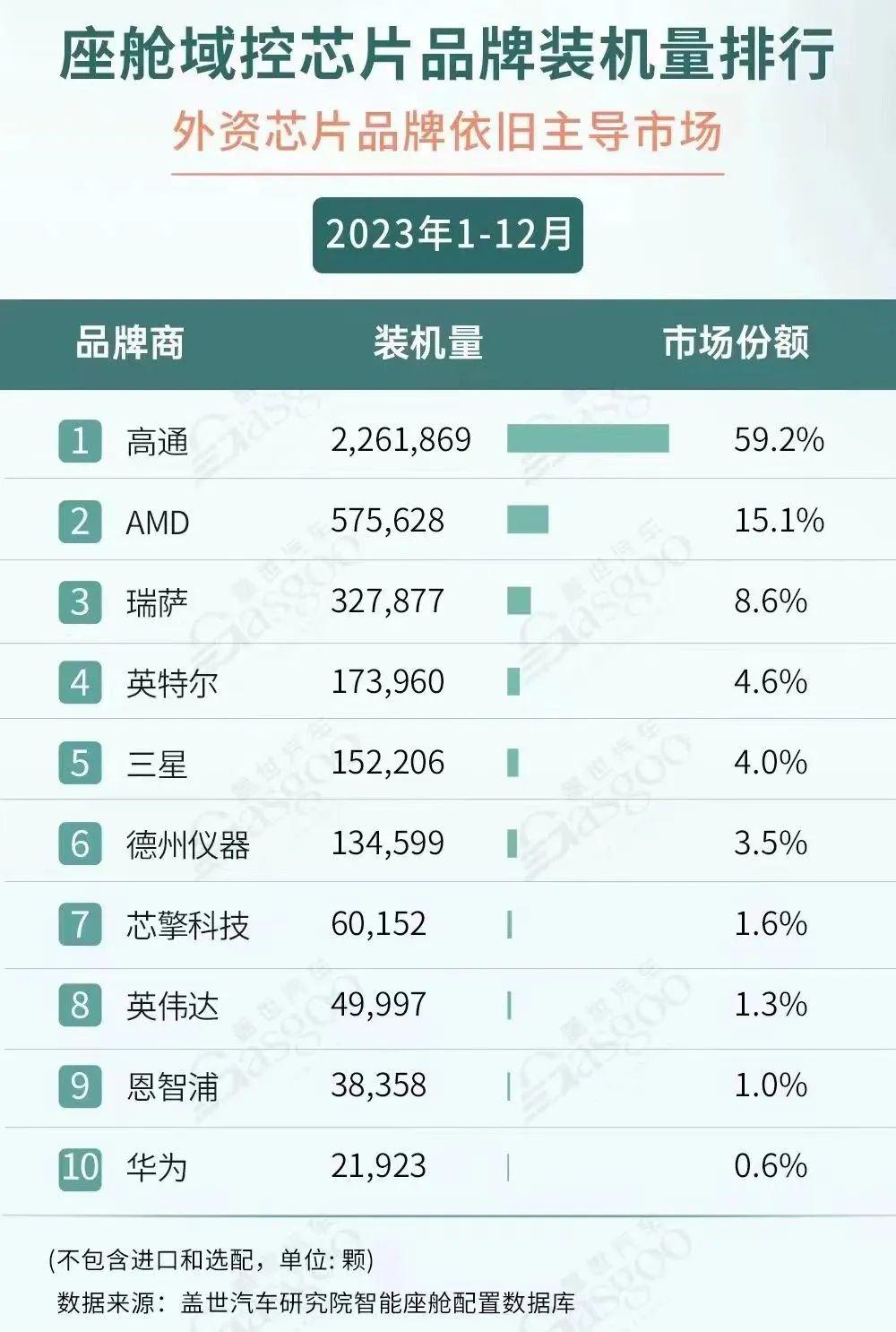
瑞萨排位第三,2023年座舱域控芯片装机量近32.8万颗。德赛西威是主要客户,其超20万套座舱域控采用的瑞萨的M3或H3。除德赛西威外,这两款芯片也用于安波福、佛吉亚、华阳通用的座舱域控产品中,配套量居高的车型包括艾瑞泽8、哈弗H6等。英特尔、三星、德州仪器也都在10万级以上,其中英特尔近76%座舱域控芯片配套于东软的座舱域控产品;三星则主要供应LG;德州仪器主要供应安波福。芯擎科技凭借60,152颗的装机量,拿到了“第七”的排位,高于英伟达与恩智浦。据悉,该年度“龍鹰一号”主要配套北斗智联和亿咖通的座舱域控产品,涉及车型领克08 EM-P、睿蓝7等。华为此次排位第十,麒麟芯片2023年装机量为21,923颗,主要配套阿维塔11、阿维塔12等车型。
注:转载至 网络 文中观点仅供分享交流,不代表贞光科技立场,如涉及版权等问题,请您告知,我们将及时处理
-
域控制器是下一代智能汽车架构的关键2019-06-27 5538
-
车身域控制器的原理是什么呢2022-02-14 2468
-
智能驾驶域控制器的SoC芯片选型2022-08-11 3847
-
英恒科技正式发布CAELUS自动驾驶域控制器开源计划2021-05-28 3415
-
继IPU03之后的新一代智能驾驶域控制器2021-10-20 3454
-
智能驾驶域控制器的类型划分及灵活的合作模式2022-08-17 2554
-
澳克诺领跑智驾域控制器,加速自动驾驶进入量产时代2022-09-14 1531
-
汽车ADAS域控制器SoC架构介绍2022-10-12 5205
-
知行科技亮相盖世汽车第二届智能汽车域控制器创新峰会2022-11-18 1049
-
大陆集团将安霸CV3 AI域控制器SoC主芯片集成到其高级驾驶辅助系统中2022-11-22 1651
-
汽车五大域控制器有哪些?汽车域控制器和ecu的区别2023-11-23 11254
-
Hailo-8 AI加速器与瑞萨R-Car SoC为知行科技的iDC High域控制器赋能2024-01-31 1287
-
怎么选智能汽车域控制器芯片2024-02-01 3574
-
德赛西威智能驾驶域控制器荣获ASIL D认证2024-11-29 1539
-
爱普生 SG-8101CGA:ADAS 智能驾驶域控制器的 “智慧芯” 动力2025-03-12 899
全部0条评论

快来发表一下你的评论吧 !
