

浅谈存内计算生态环境搭建以及软件开发
电子说
描述
在当今数据驱动的商业世界中,能够快速处理和分析大量数据的能力变得越来越重要。而存内计算开发环境在此领域发挥其关键作用。存内计算环境利用内存(RAM)而非传统的磁盘存储来加速数据处理,提供了一个高效和灵活的平台。这种环境的核心优势在于其能够提供极高的数据处理速度和效率,使得数据可以直接在内存中被快速访问和处理,这对于需要实时数据处理和分析的应用来说至关重要。
在了解存内计算开发环境的核心优势和作用后,我们现在将转向实现存内计算技术潜力的关键:存内计算生态环境的搭建以及软件开发的具体细节。它们不仅为存内计算应用的开发和运行提供必要的基础,也是实现高效数据处理和分析的关键组成部分。
一.存内计算环境搭建
(一)背景介绍
存内计算环境搭建是一种高效的数据处理方法,它涉及在计算机内存中配置和管理数据及应用程序,以提高数据处理和计算的速度。存内计算环境的搭建对于高效软件的开发至关重要。首先,它提供了快速的数据访问和处理能力,从而显著减少了数据处理时间,这对于实时数据分析和在线事务处理尤为重要。此外,存内计算支持大数据和复杂应用的处理,满足了现代软件开发对于处理大量数据的需求。同时,它还能简化应用架构,提高开发效率。
此外,在搭建存内计算环境时,关键的硬件和软件是不可或缺的。硬件方面,需要足够的RAM来存储数据集和支持计算过程。软件方面,则涉及选择支持存内计算的数据库和应用平台,如SAP HANA、Apache Spark等。不仅如此,还需制定有效的数据管理策略,实施性能优化措施,并考虑安全性与数据备份方案,以及潜在的集群及分布式计算的布局。
(二)研究现状
存内计算环境搭建的主流方法和策略包括集成处理器技术、数据管理和流程优化等。存内计算环境的搭建重点关注存储设备内部的集成计算能力,这通常通过在存储设备中嵌入微处理器或定制硬件来实现。这些处理器可以直接在数据存储的位置进行数据处理任务,大大减少了数据在存储单元和中央处理单元之间的移动,提高了数据处理的速度和效率。其次,在软件层面,存内计算环境需要配备能够支持这种硬件架构的操作系统和文件系统,例如GenStore(图1),其是专门为基因组序列分析设计的存内处理系统[1]。这些系统需要智能地管理数据,将计算密集型的任务分配到最合适的存储设备上。此外,还需开发专门的算法和工具,以优化数据的存储和检索过程,确保计算任务的高效执行。
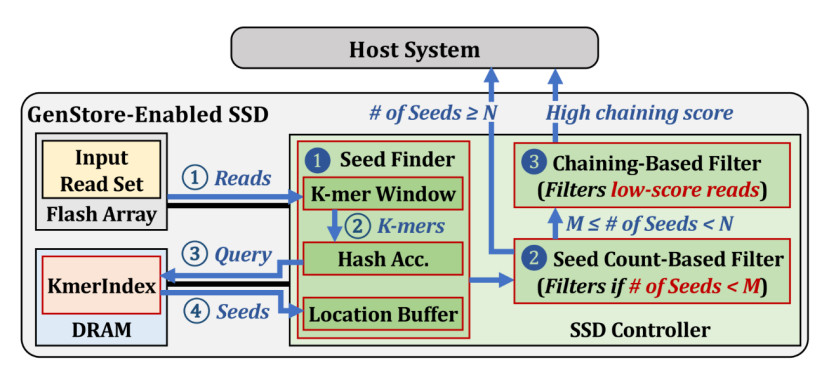
图1 GenStore的概述
在实用工具和平台方面,市场上已经有多种支持存内计算的产品和解决方案。例如,某些高性能固态硬盘(SSD)已经集成了额外的处理能力,能够在设备级别进行数据处理。同时,一些软件提供商也开发了专门的工具和平台,以支持存内计算,使得用户可以更容易地实现和管理这种计算模型。例如,在大数据分析领域,某些企业利用存内计算来处理大规模的数据集,通过在存储设备内部进行初步的数据处理,降低了对传统CPU的依赖,加快了整个数据分析过程。
(三)环境搭建对软件开发的影响
搭建存内计算环境对软件开发的影响是深远的,尤其在提升软件的性能和效率方面。
首先,存内计算环境的出现改变了数据处理的传统模式,将更多的计算任务从中央处理器转移到存储设备中。这要求软件开发者重新思考数据处理和计算任务的分布方式。在存内计算环境中,开发者需要设计能够在存储设备上有效运行的算法和程序,同时也要考虑如何高效地利用存储设备内部的处理器和资源。
此外,在存内计算环境中,软件开发者还需考虑数据在存储设备中的布局。合理的数据布局可以减少数据访问的延迟,并充分利用存储设备的内部带宽。这些考虑不仅涉及到软件本身的编码,还包括对操作系统、文件系统等底层支持的优化。
综上,存内计算环境的搭建不仅促使硬件技术的创新,也推动了软件开发方法的变革。在这种环境中,软件性能和效率的提升依赖于开发者对存储设备计算能力的深入理解和有效利用。因此,软件和硬件之间的紧密协作成为了实现最佳性能的关键。
二.存内计算软件开发
(一)研究背景
存内计算提供了在数据处理和分析中更高的速度和效率,这对于需要处理大量数据的应用尤其重要。然而,这也为软件开发人员带来了新的挑战,例如需要深入了解存内计算的工作原理,以及如何优化代码以充分利用其性能优势。同时,开发人员还需考虑如何在保持软件灵活性的同时,提高与存内计算硬件的兼容性。
为了更好地适应存内计算,开发者们正在探索新的编程模型和语言。这些新工具和语言旨在简化存内计算的编程过程,同时提供强大的功能来支持复杂的数据处理任务。例如,一些研究正在探讨如何将常见的编程概念和结构(如循环和并行处理)适配到存内计算架构中。
(二)研究现状
随着存内计算硬件的发展,软件开发社区正在寻找方法将这种新技术集成到传统的软件开发工作流程中。例如,流行的开源框架Apache Spark已经开始探索如何利用存内计算技术来提高数据处理的效率。此外,TensorFlow等机器学习框架也在调整其算法,以更好地利用存内计算的高速数据处理能力。
Apache Spark是一种广泛使用的大数据处理框架,它的主要特点是基于内存计算,能够快速处理大量数据。近年来,Spark团队开始探索如何将存内计算技术整合到其框架中,以进一步提高数据处理效率。Apache Spark通过优化其内存管理和数据处理算法来适应存内计算架构。这意味着Spark能够更有效地利用基于CIM技术的硬件,减少数据在内存和CPU之间的移动,从而提高整体的数据处理速度。为了充分利用存内计算的高速处理能力,Spark正在调整其核心算法,例如对RDD(弹性分布式数据集)的操作和Spark SQL的查询优化。
图2 Apache Spark 框架
TensorFlow是一个广泛应用于机器学习和深度学习的框架。随着存内计算技术的发展,TensorFlow也在调整其算法以适应这一新的计算模式,例如通过优化其底层数据处理和神经网络训练算法来利用存内计算的优势。另一方面,可以减少在训练深度学习模型时数据在GPU和内存之间的传输,从而加快训练过程TensorFlow开发人员正在增强其框架的灵活性,以支持不同类型的存内计算硬件。这包括改进对异构计算资源的支持,使得TensorFlow能够更有效地在搭载CIM技术的系统上运行。
图3 TensorFlow的计算图
通过开发人员的努力,Apache Spark和TensorFlow不仅能够提高数据处理和机器学习模型训练的速度,还能在能耗和性能方面取得显著改进。这些进展在软件开发领域展示了存内计算技术的巨大潜力,尤其是在处理大数据和复杂计算任务时。随着存内计算技术的不断发展和成熟,预计这些框架将在未来的软件开发中发挥更重要的作用。
(三)软件开发对CIM架构的要求
在软件开发领域,特别是对于数据密集型应用,对CIM架构的需求日益增长。首先,CIM架构必须能够高效处理大数据量,这意味着它需要具备高吞吐量和低延迟的能力。为了提升软件开发的效率,CIM架构还需提供灵活的编程接口和强大的软件支持,让开发者可以轻松地利用其特性。随着数据需求的增长,CIM架构的设计应具备良好的可扩展性,以应对不断增加的计算资源需求。此外,在移动和边缘计算设备中,CIM架构还需在维持高性能的同时,优化能源效率,以满足现代计算环境的需求。
总结与展望
存内计算环境的搭建和软件开发正处于一个快速发展的时期,随着技术的进步,这两个领域都展现出了显著的潜力和多样化的发展趋势。存内计算环境通过利用内存(RAM)加速数据处理,提供了一个高效和灵活的平台,特别适合实时数据分析和在线事务处理。这一环境的优势在于其极高的数据处理速度和效率,显著减少了数据处理时间,并支持大数据和复杂应用的处理。在软件开发领域,Apache Spark和TensorFlow等框架正在适应存内计算架构,优化内存管理和数据处理算法,以更高效地利用基于CIM技术的硬件。这些框架的调整不仅加快了数据处理和机器学习模型训练的速度,还在能耗和性能方面取得了显著改进。
未来展望中,存内计算技术预计将继续发展,尤其在与软件开发的协同方面。预计这一领域将见证更高效、灵活且可扩展的存内计算环境,并且软件开发将更深入地利用其优势,以支持更复杂和数据密集的应用。同时,安全性将成为未来发展的一个重要考虑因素。总之,存内计算和软件开发领域预计将继续紧密合作,推动数据处理和分析技术的进步。
资料来源
Nika Mansouri Ghiasi, Jisung Park, Harun Mustafa,etc. 2022. GenStore: a high-performance in-storage processing system for genome sequence analysis. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '22). Association for Computing Machinery, New York, NY, USA, 635–654.
审核编辑 黄宇
-
小白从0学习CW32的第一天(搭建软件开发环境)2023-05-26 3458
-
浅谈存内计算生态环境搭建以及软件开发2024-05-16 990
-
保护生态环境,打造绿色产品!2014-05-03 3833
-
怎样去搭建一种嵌入式软件开发环境2021-10-28 1247
-
软通动力启航 KS_IoT 智能开发套件 软件开发环境搭建2022-07-01 3787
-
嵌入式软件开发的优缺点浅谈2009-11-28 3621
-
Linux软件开发环境2021-03-25 1274
-
STM32 软件开发环境搭建2021-11-13 1215
-
[IC]浅谈嵌入式MCU软件开发之中断优先级与中断嵌套2021-12-05 1028
-
高光谱遥感在生态环境监测上的应用2022-09-19 3824
-
生态环境监测中的水环境治理如何实现2023-08-08 1320
-
曙光生态环境大数据解决方案助力我国生态环境“大数据”建设2023-10-11 1438
-
软通动力启航KS_IoT智能开发套件_软件开发环境搭建V12022-01-06 3252
-
嵌入式软件开发和软件开发的区别2024-01-22 5009
-
生态环境智慧监测系统方案2025-10-22 991
全部0条评论

快来发表一下你的评论吧 !
