

【基于存内计算芯片开发板验证语音识别】训练手册
电子说
描述
实验环境搭建
模块⼀:软件包下载及环境搭建
步骤一:搭建docker、mappper环境:
①Linux下通过Docker直接下载,获取指令:
docker pull witin/toolchain:v001.000.034
②Window环境,可以通过docker desktop来使用docker:
下载安装Docker desktop(win10或以上):
通常需要更新WSL,下载链接如下,更新后需要重启生效
旧版 WSL 的手动安装步骤 | Microsoft Learn
3.Docker desktop 基本使用教程:
Docker-desktop(Docker桌面版)——入门篇_dockerdesktop干嘛用的-CSDN博客
4.Docker desktop通常默认安装在c:Program Filedocker,可以通过软连接的形式修改Docker安装路径:
如何将Docker(Windows桌面版)自定义安装目录_自定义docker安装路径-CSDN博客
5.在Docker desktop里,可以通过搜索获得witin_toolchain,我们需要的是034版本(ps:Hub反应慢可以开VPN获取,或者使用镜像路径,具体操作方式见3链接)
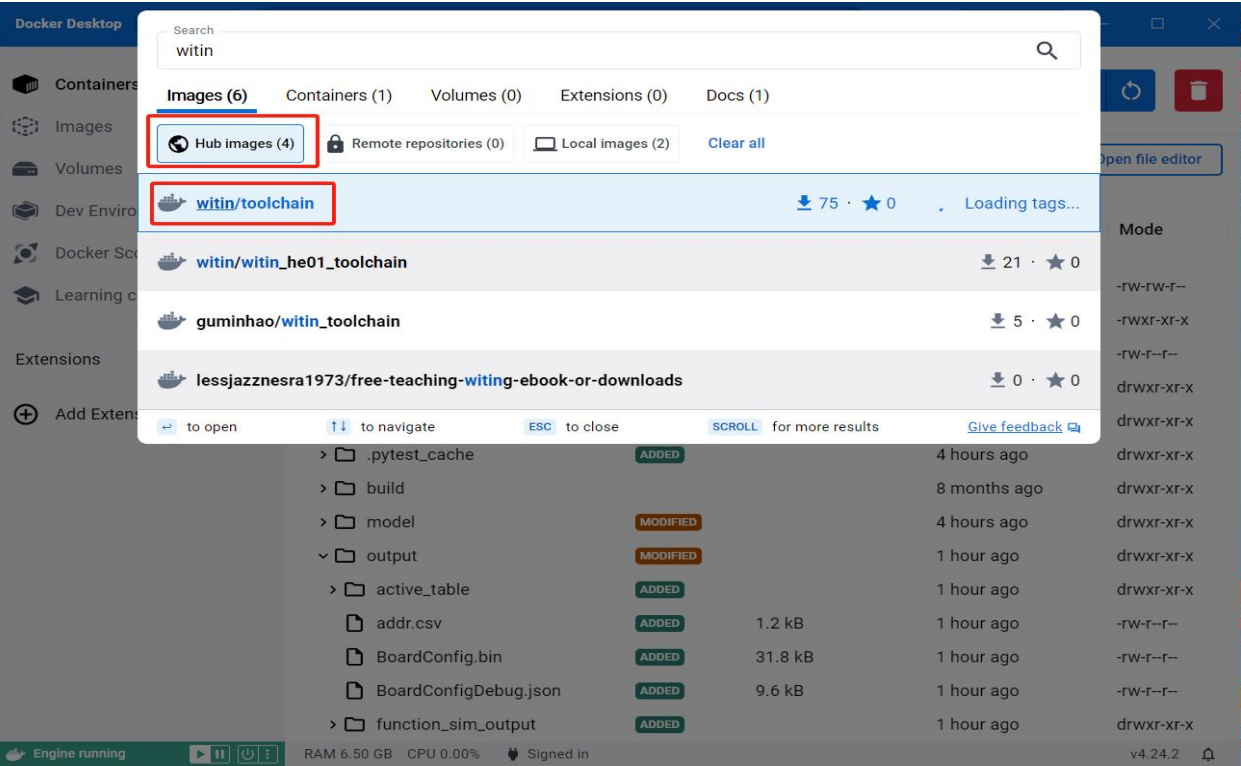
6.测试:
①:管理员模式下打开命令行窗口
docker run -it --name XXXX witin/toolchain:v001.000.034
②:默认进入workspace目录下,可以进入witin_mapper下执行测试脚本:
cd witin_mapper
python3
tests/python/frontend/onnx/witin/wtm2101/precision/XXXX.py
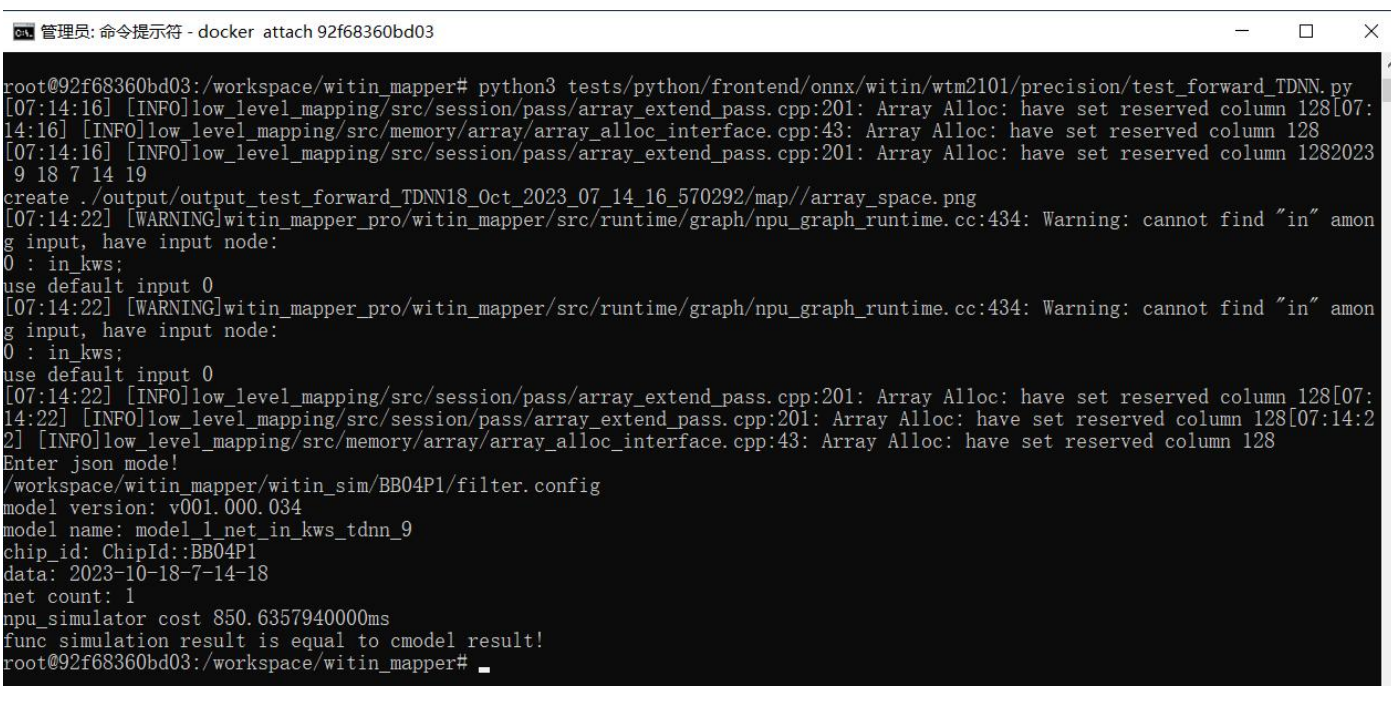
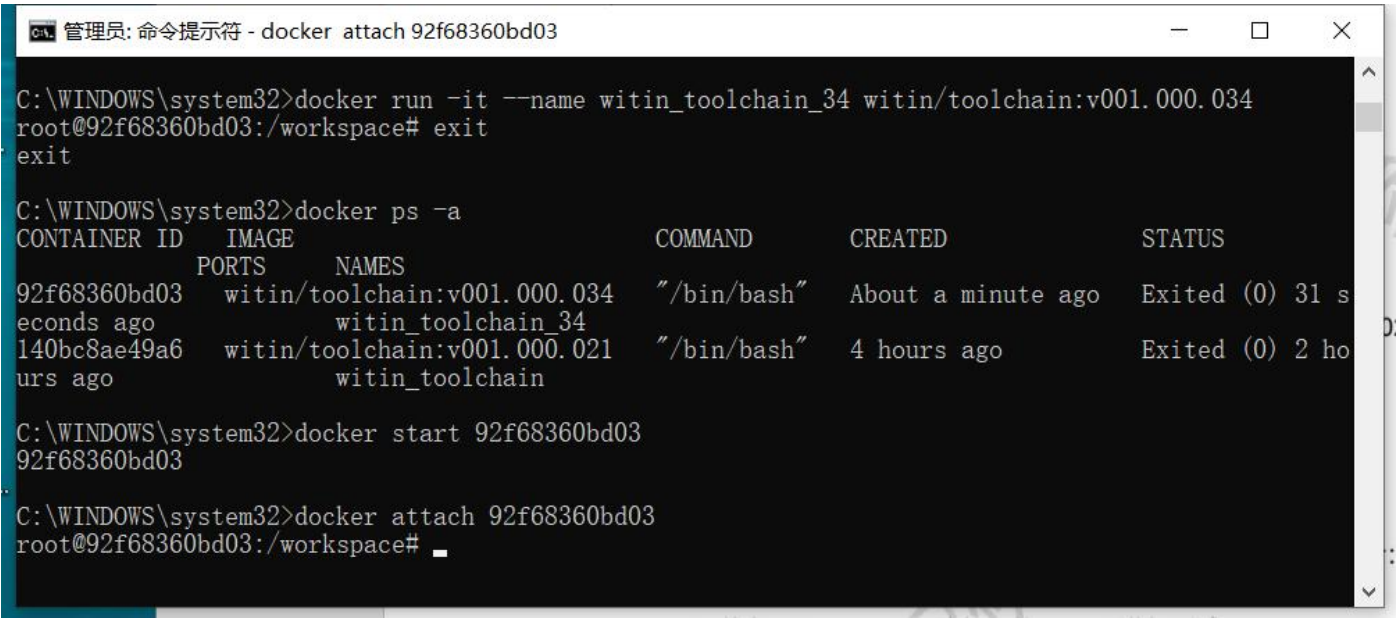
③:使用exit退出,再次进入可按如下操作:
④:通过docker ps -a获取容器id,然后打开进入容器
步骤二:搭建IDE环境
①预先下载安装包,下载安装
②默认安装路径,直接点击安装
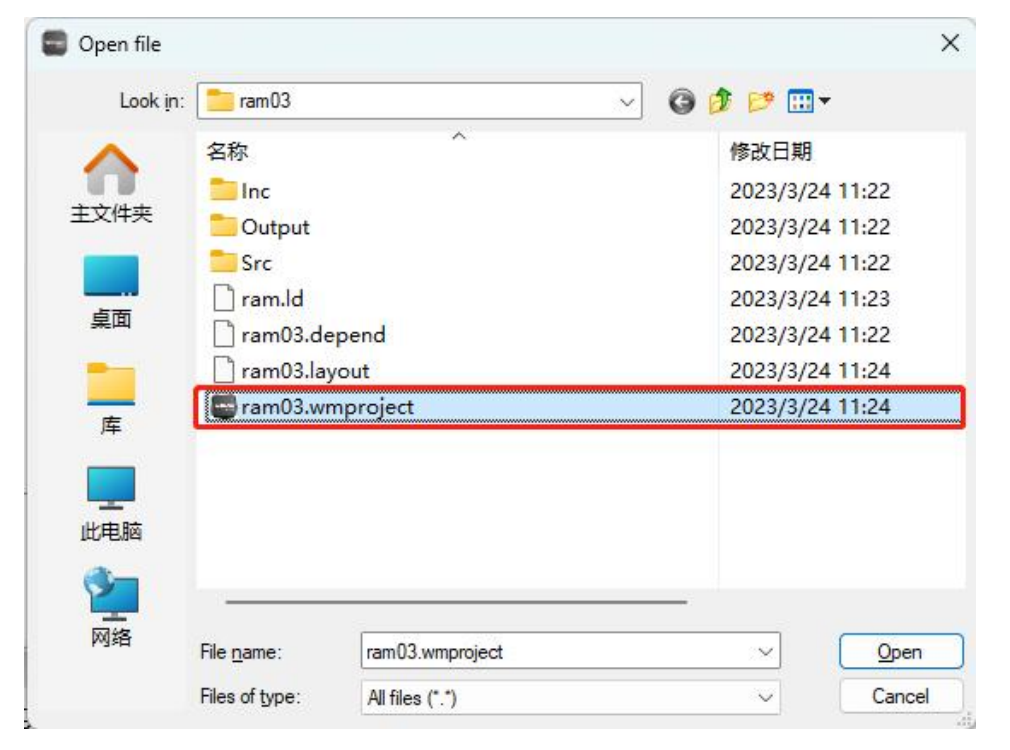
③从主菜单的File->Open…菜单,或者点击工具栏的按钮,打开选择文件对话框,选择要打开的项目文件,即***.wmproject文件即可,点击【打开】按钮即可打开工程。如下图所示。
步骤三:其他需要安装的软件
① 请确保安装以下环境:python, git, pytorch
步骤四:下载训练数据
① 最新数据集在软件安装包中
工程软件安装包:https://download.csdn.net/download/m0_58966968/88602575
实验环境安装包:https://download.csdn.net/download/m0_58966968/88602555
动⼿实验: 简单语音识别系统开发
模块⼀:简介
WTMDK2101-X3介绍
WTMDK2101-X3是针对WTM2101 AI SOC设计的评估板,包含:
(1)WTM2101核心板,即我们的存算芯片。
(2)和I/O 板:WTM2101运行需要的电源、以及应用I/O接口等.

核心板示意图

WTMDK2101-X3 I/O 板示意图
2, AISHELL-WakeUp-1数据集介绍
AISHELL-WakeUp-1数据集是中英文唤醒词语音数据库,命令词为“你好,米雅” “hi, mia”,语音数据库中唤醒词语音3936003条,1561.12小时,邀请254名发言人参与录制。录制过程在真实家居环境中,设置7个录音位,使用6个圆形16路PDM麦克风阵列录音板做远讲拾音(16kHz,16bit)、1个高保真麦克风做近讲拾音(44.1kHz,16bit)。此数据库可用于声纹识别、语音唤醒识别等研究使用。
本demo以该数据集为例,用不同网络结构展示模型训练及移植过程。
模块⼆:搭建算法训练工程,完成算法训练与量化
模型训练工程搭建:
本demo提供DNN和DNN_DEEP两种网络结构的示例,网络结构如下,本教程以DNN为例。
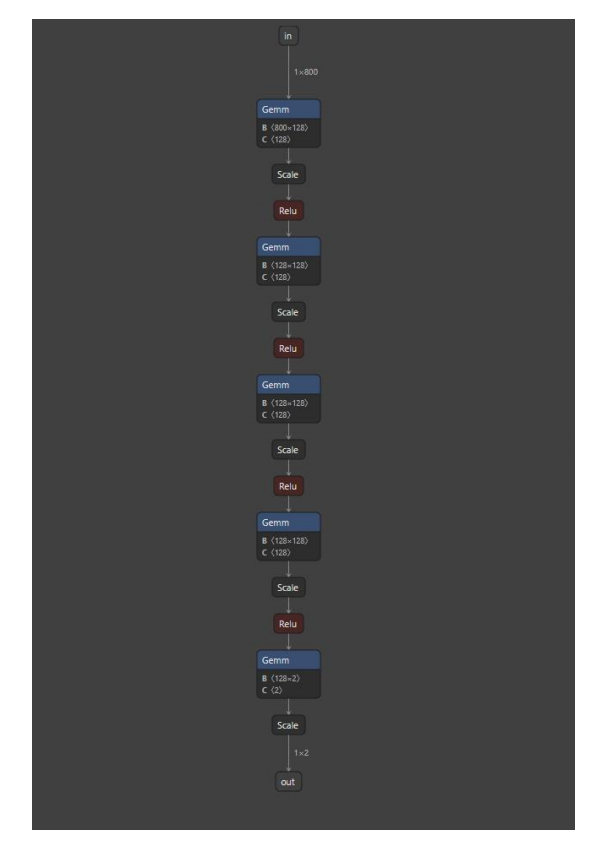
DNN
步骤一:配置python/config.py,参数释义见代码注释。
步骤二:运行python/train.py,模型训练完毕后,在models/net_type文件夹下生成bestModel.pth,此即我们的模型权重。
步骤三:运行python/onnx_converter.py,在models/net_type文件夹下生成bestModel.onnx。此步骤即完成原始模型到知存onnx格式模型的转换。
模块三:算法模型转换
1,Dcoker下Mapper转换流程
步骤一:拷贝至指定文件夹
我们将mapper/input 拷贝至witin/toolchain:v001.000.034的指定文件夹下(通常为/home,需与gen_mapper.py文件里描述一致)
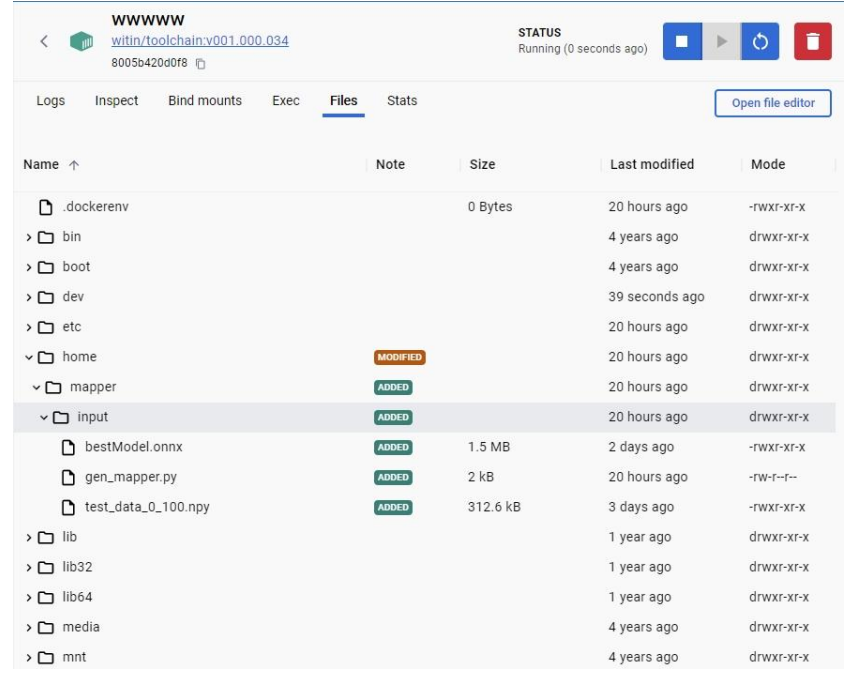
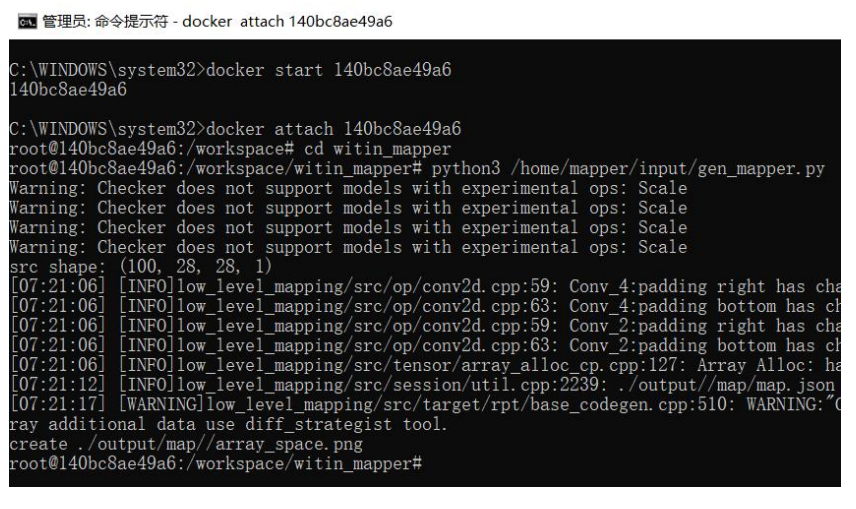
步骤二:在workplacewitin_mapper下执行gen_mapper.py
docker start id
docker attach id
cd witin_mapper
python3 /home/mapper/input/gen_mapper.py
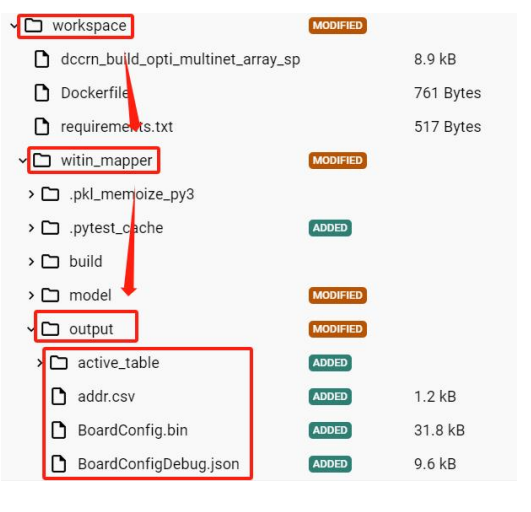
步骤三:在对应的output文件下获得输出
模块四:算法模型烧写
步骤一:系统连接:
进行模型烧录和开发时,我们需要将JTAG,核心板,NPU烧写板连接好,并打开开关,如系统连接示意图所示。
步骤二:
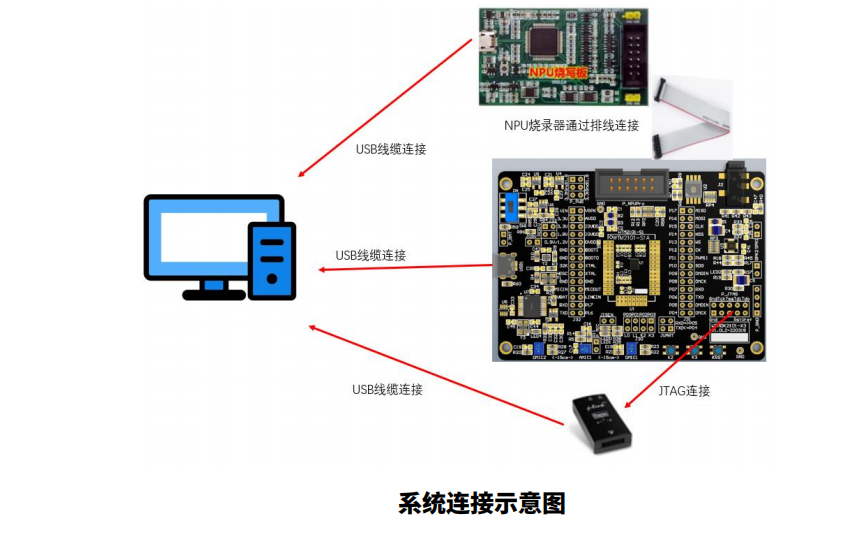
系统连接示意图
步骤三:跳线帽连接:
如跳线帽连接示意图所示,按照红框标注进行跳线连接。含义解释:
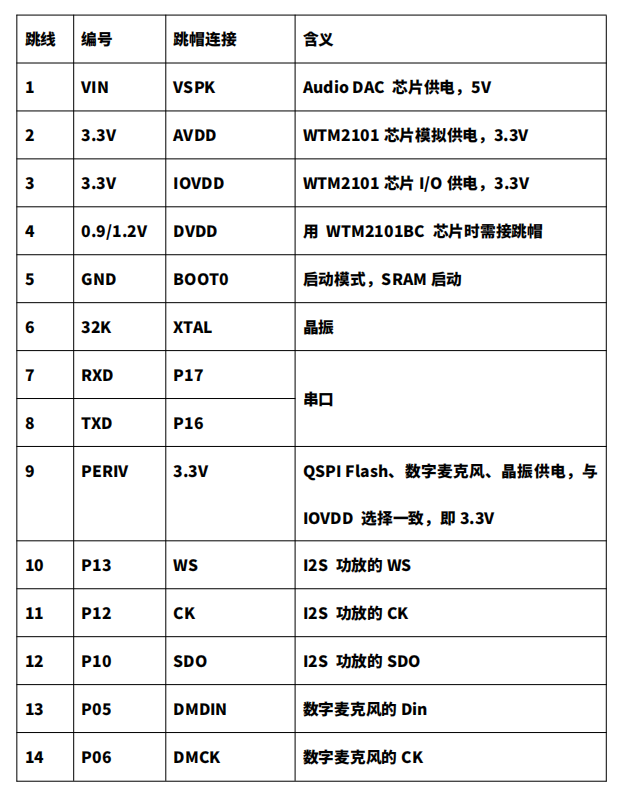

跳线帽连接示意图
步骤四:
使用project/ WitinProgramTool_WTM2101下的WitinProgramTool.exe进行模型权重烧写。烧写时的开发板接线请参考其他文档。
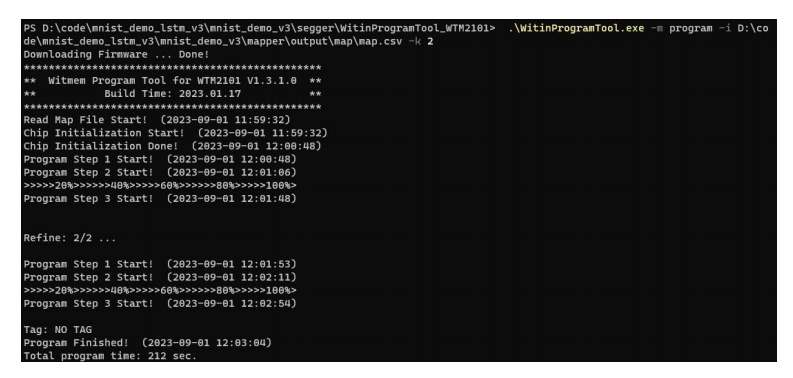
步骤五:烧写指令:
.WitinProgramTool.exe -m init
.WitinProgramTool.exe -m program -i XXXXmap.csv -k 2
其中XXXX为步骤2.(3)中生成的mapper/output/map
示例:
模块五:算法模型在芯片运行推理
步骤一:
从官网下载知存IDE Witmem Studio。
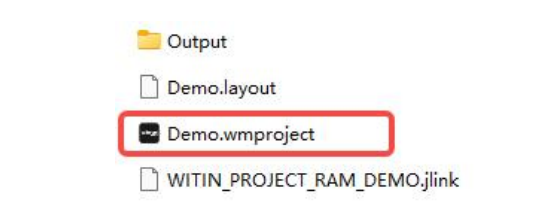
步骤二:
生成的mapper/output/register.c放在project/Model,使用Witmem Studio打开project/Project/SES-RISCV/Demo.wmproject。
步骤三:Target->Download下载工程:
注:本demo所用为x3开发板,所用串口GPIO为16,17。若是其他开发板,请根据情况修改串口。
步骤四:
打开tools中的串口工具,设置波特率115200,查看准确率输出

至此,我们完成了基于存内计算X3开发板的语音识别从训练到部署全流程,本教程结束。
审核编辑 黄宇
-
 nijianno1
2025-05-07
0 回复 举报您好,请问通过什么渠道购买开发板呢 收起回复
nijianno1
2025-05-07
0 回复 举报您好,请问通过什么渠道购买开发板呢 收起回复
-
明远智睿SSD2351开发板:语音机器人领域的变革力量2025-05-28 811
-
存内计算原理分类——数字存内计算与模拟存内计算2024-05-21 6373
-
1024 CSDN 程序员节-基于存内计算WTM2101芯片开发板验证语音识别2024-05-20 2005
-
存内计算技术工具链——量化篇2024-05-16 2796
-
【时擎科技AT1000开发板试用体验】初体验之开箱即用语音识别2022-06-17 1479
-
关于FPGA开发板和原型验证系统对比介绍2022-04-28 4037
-
[CB5654智能语音开发板测评] 语音识别开发板的比较2022-03-09 4490
-
语音识别芯片LD3320开发手册2021-12-16 2740
-
【1024平头哥开发套件开发体验】 语音识别开发板的比较2021-12-13 2385
-
【 平头哥CB5654语音开发板试用连载】智能门禁语音识别2020-03-13 1478
-
新唐科技语音识别技术资料2016-12-12 1883
-
【龙邱Lark7618语音识别开发板免费试用】开发板申请项目计划2016-06-06 4056
-
龙邱Lark7618语音识别开发板套件手册2016-05-09 7917
全部0条评论

快来发表一下你的评论吧 !
