

英飞凌AURIX TC4x微控制器系列中的并行处理单元(PPU)简介
描述
并行处理单元(PPU)是集成在英飞凌AURIX TC4x微控制器系列中的协处理器。PPU旨在卸载主CPU的信号处理、滤波和其他数学运算,从而为要求严格的应用程序(例如实时控制、传感器信号处理和轨迹规划等)提供高计算能力和缩短执行时间,并且能支持实现简单的神经网络算法。
本文将简要介绍PPU的内部结构、功能和应用领域。
1. PPU内部结构
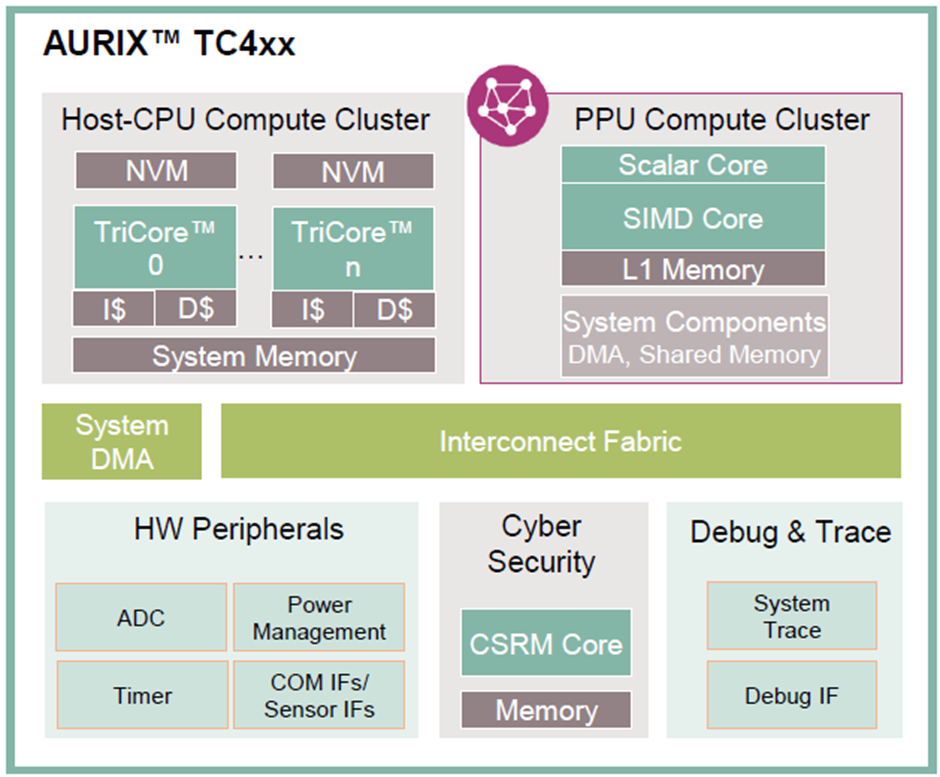
图1. TC4x微控制器示意框图
图1是TC4x 微控制器示意框图,图中右上角是PPU的简化结构,由标量核(scalar core),向量核(vector core/SIMD core),一级缓存,及其它系统资源组成。
01
标量核(Scalar Core):标量核用于执行大量的标量运算,以及任务调度。标量核支持多种算术运算和逻辑运算,还支持硬件浮点运算,从而实现更高的计算效率。另外,标量核提供丰富的硬件功能安全机制,可以辅助实现高功能安全等级的任务。
02
向量核(Vector core/SIMD Core):向量核是 PPU 的另一个重要功能模块,专门用于执行向量运算。向量核支持多种向量算术运算、逻辑运算和专用信号处理,支持整型数和浮点运算,从而实现更高的计算效率。向量核还支持多级流水线和 SIMD(single instruction multiple data,单指令多数据)指令,对不同数据同时执行同样的操作,通过并行执行多个向量运算来提高效率。
03
一级缓存:一级缓存是PPU用于保存计算输入和输出数据的存储空间。由于结构上和运算核紧密耦合,该缓存可以在PPU 的执行过程中对状态进行快速读写,并且有EDC/ECC保护,从而实现更高的执行效率和更高的可靠性。
04
其它系统资源:包括用于快速数据搬运的DMA,共享内存区等等。
2. SIMD 和VLIW指令
2.1 SIMD(Single Instruction Multiple Data)指令
SIMD(Single Instruction Multiple Data)指令是一种并行指令,可以同时对多个不同数据进行相同的操作。这种指令可以大幅提高计算效率,特别是在执行向量运算时效果更为明显。
PPU 的 SIMD 指令集包括多种运算指令,如数学运算、逻辑运算等。这些指令都是并行指令,可以同时对多个数据进行操作,从而大幅提高计算效率。例如,PPU 的 SIMD 加法指令可以一次性对多个数据进行加法运算,从而实现更高的计算速度。
下面是一个示例,假设有两个向量 A 和 B,每个向量包含 16 个 16 位整数 ,要计算 A 和 B 的和。如果使用不支持SIMD指令的标量核,代码示例如下,需要进行16次循环运算,将不同的A[i]、B[i] 数据依次顺序进行加法操作,相当费时。

而如果使用支持SIMD指令的 PPU进行运算,则可以一次完成,假设PPU位宽是256bit(=16*16bit):

由此可见,支持SIMD指令的PPU在进行向量运算时,通过降低同样运算的处理次数,从而有效节省运算时间,提高处理效率。
2.2 VLIW(Very Long Instruction Word)指令
VLIW(Very Long Instruction Word)是一种处理器的并行架构,允许在单个时钟周期内,由处理器的不同部件同时执行多个操作。
例如,如果要执行两个复向量A和B的乘法 ,结果存储在向量C中。

C语言实现如下:

如果在标量核上运算,会顺序执行下列代码,并循环多次:

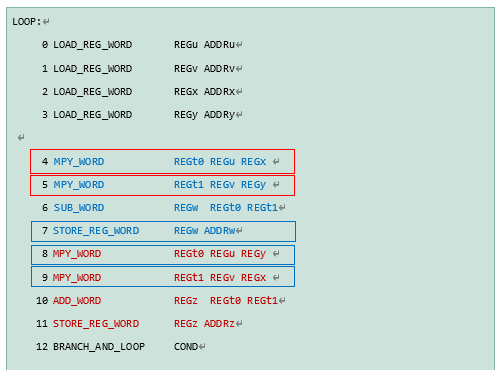
PPU内的向量核有三个处理单元,包括两个浮点运算器,和一个读取/存储部件用于将RAM中的数据搬运到核内寄存器。这三个部件可以同时运行,形成指令层面的并行机制,从而实现VLIW指令。
上列代码由PPU处理,可以将第4和第5行的乘法运算分别分配给两个浮点运算器同时处理,如下红框所示。而在下个指令周期内,第7,8,9行的指令可以分配给三个部件同时处理,如下蓝框所示。从而将原先需要12条指令周期运行的代码缩短到9条(12-1-2=9)指令周期,提高执行效率。
3. 应用场景
PPU适用于不同应用场景,图2 列出了三种较常见的算法。第一种是将时域信号转变为频域信号,以提取频率信息的快速傅里叶变换(FFT)。FFT 在数字信号处理中得到了广泛的应用,如音频信号处理、毫米波雷达信号处理等。
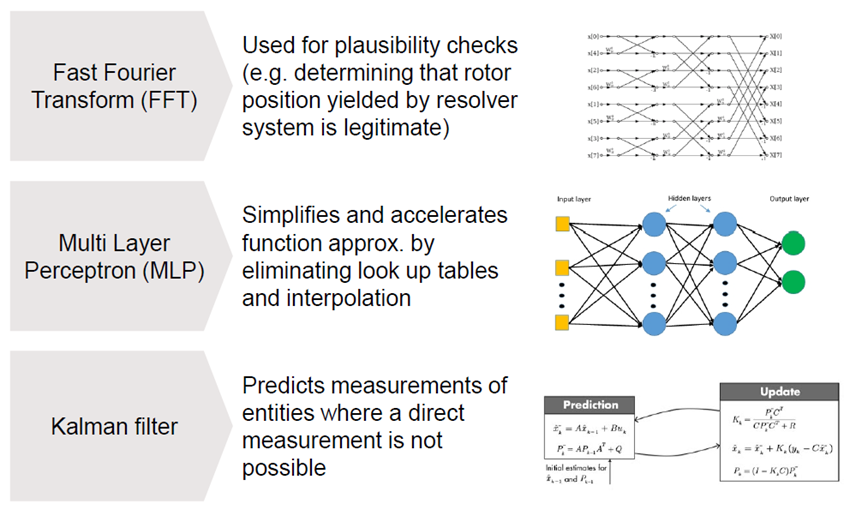
图2. PPU实现的算法
第二种是多层感知算法,它是一种基于人工神经网络的机器学习算法,可以用于分类、回归和模式识别等应用。MLP 由多个神经元组成,每个神经元都包含多个输入和一个输出。MLP 通过学习输入和输出之间的映射关系,从而实现对新数据的预测和分类。MLP 在机器学习和数据挖掘中得到了广泛的应用。除此之外,MLP 还可以用于控制和优化问题。例如,MLP 可以用于控制系统和过程控制,如传感器信号处理分类、辅助驾驶、自动驾驶等。
第三种是卡尔曼滤波,该算法是一种基于状态空间模型的滤波器,可以用于估计未知变量的状态和参数。卡尔曼滤波通过利用系统的动态模型和传感器的观测值,递归地对状态进行估计和预测,从而实现对系统的状态进行优化和控制。卡尔曼滤波在自动控制和信号处理中得到了广泛的应用,例如,卡尔曼滤波可以用于目标跟踪、路径规划算法等。
4. 开发工具
新思科技(Synopsys)为PPU提供了丰富的开发工具资源【1】,包括Metaware编译器及软件组件,下列表格列出了相关工具组件:
| 软件组件 | 描述 |
| MetaWare开发工具包 | 该工具包包含支持内核和应用程序开发编程的C/C++和OpenCL C编译器。它还包括一个调试器和nSIM PPU模拟器,用于调试、分析和优化内核和应用程序。 |
| Simulink基于模型设计的支持 | 从MATLAB模型自动生成优化代码,以便在PPU上执行。 |
| DSP和数学库 | 这些是为在PPU上执行而优化的库,包括矢量DSP和矢量线性代数库。 |
| MetaWare神经网络SDK | 该SDK包括一个神经网络编译器,用于编译和运行为PPU优化的人工智能模型。 |
| AUTOSAR复杂设备驱动程序(CDD)和底层软件驱动(LLD) |
CDD为AUTOSAR应用程序的软件组件(SWC)提供PPU服务。 LLD是一个底层软件驱动,用于处理TriCore和PPU之间的通信。 |
| PPU分配器 | 这是用于在TriCore处理器核心之间进行通信的PPU的静态库。 |
表1. 新思科技提供的PPU工具组件
上述PPU开发工具链,除了新思科技可提供外,Hightec 在提供TC4x TriCore CPU编译器的同时,也集成了Metaware编译工具,及相关软件组件【2】,形成完整的TC4x开发环境工具链。该工具链符合ISO26262 ASIL D,能帮助客户实现快速、可靠、高功能安全等级的基于TC4x微处理器的汽车软件开发。
此外,Tasking也开发了PPU的编译器,并集成在新的SmartCode开发环境中。
5. 总结
总的来说,PPU是一个性能强大的处理器,内部包含标量核、向量核、一级缓存和其它系统资源 等,可以实现高速数字滤波、向量矩阵运算、浮点运算、简单的神经网络等,为要求严格的实时计算应用提供了显着的性能优势。PPU为Tricore 主核卸载了复杂的信号处理和数学运算,使得执行时间更快,而其高可配置性和专用硬件资源使其非常适用于各种应用程序。使用户有更多选择余地,使用不同核构架实施不同性质的运算。
-
英飞凌科技和Eatron合作推进汽车电池管理系统(BMS)2023-11-02 1396
-
英飞凌与Eatron合作推进电池管理管理解决方案2023-11-10 549
-
AURIX™ TC4x免费开发环境介绍2024-08-22 974
-
英飞凌推出新一代AURIX™微控制器,加速汽车的电气化和数字化进程2022-01-17 1840
-
英飞凌AURIX™ TC3x MCU系列新增FreeRTOS支持2024-12-11 428
-
如何在aurix TC333微控制器中配置内存分区?2024-01-30 0
-
英飞凌aurix tc27x系列介绍2017-09-12 3019
-
英飞凌AURIX™ TC4x微控制器赋能TERAKI雷达检测软件,提高自动驾驶的安全性2022-10-19 582
-
英飞凌AURIX TC297微控制器简介2023-09-19 1727
-
英飞凌和Eatron合作2023-11-07 437
-
英飞凌TC3xx系列安全管理单元的使用2023-12-07 2539
-
英飞凌MCU AURIX™ TC4x特性概览 2024年下半年逐步量产2024-02-28 2805
-
英飞凌最新的带神经加速的汽车MCU系列 AURIX TC4x微控制器2024-04-24 1078
-
英飞凌推出新型高性能微控制器AURIX™ TC4Dx2024-11-13 785
-
AURIX TC4x虚拟化技术详解2025-02-07 273
全部0条评论

快来发表一下你的评论吧 !
