

1024 CSDN 程序员节-基于存内计算WTM2101芯片开发板验证语音识别
电子说
描述
前言
在今年的 CSDN 程序员节上,我参与了这次知存科技举办的一个 AI Workshop 小活动——“基于存内计算芯片开发板验证语音识别”,并且有幸成为完成任务的学习者之一XD。上一次参与类似的活动是算能公司举办的“千校万里行”AIGC 大模型编译部署活动,感觉虽然只是简单的烧录现成代码,经历这几次活动后 AI 小白也能有一个小小的成就感。趁着这股新鲜感还没冷却,我打算写一篇博文来记录下这次活动的一些经历,也供后续参与的童鞋参考~
任务目标
AISHELL-WakeUp-1 数据集是中英文唤醒词语音数据库,命令词为“你好,米雅” “hi, mia” ,语音数据库中唤醒词语音 3936003 条,1561.12 小时,邀请 254 名发言人参与录制。录制过程在真实家居环境中,设置 7 个录音位,使用 6 个圆形 16 路 PDM 麦克风阵列录音板做远讲拾音(16kHz,16bit)、1 个高保真麦克风做近讲拾音(44.1kHz, 16bit)。此数据库可用于声纹识别、语音唤醒识别等研究使用。
本 demo 以该数据集为例,用不同网络结构展示模型训练及移植过程。
我们最终想要通过语音“你好,米雅”唤醒开发板。具体步骤如下:
训练得到模型,并转换为知存科技开发板相应格式模型。
工具链编译模型,得到模型权重表。
烧写模型权重。
烧写代码。
成功运行后,当我们对着开发板说出“你好,米雅”时,开发板就会通过串口发送“已唤醒”的信息。
开发板信息如下:
WTMDK2101-X3 是针对 WTM2101 AI SOC 设计的评估板,包含:
(1) WTM2101 核心板,即我们的存算芯片。
(2) 和 I/O 板:WTM2101 运行需要的电源、以及应用 I/O 接口等.

任务步骤
首先,本机上下载训练数据和训练代码并运行。这样我们就得到要烧录到知存开发板上的对应格式的模型。

这一步结束后,我们可以得到以下模型+运行代码:
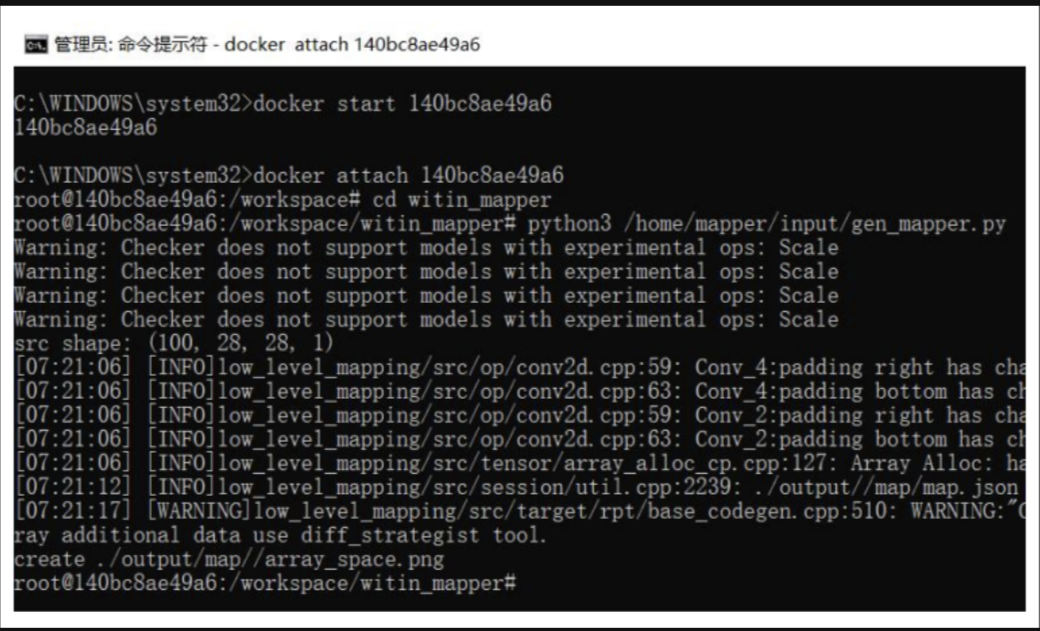
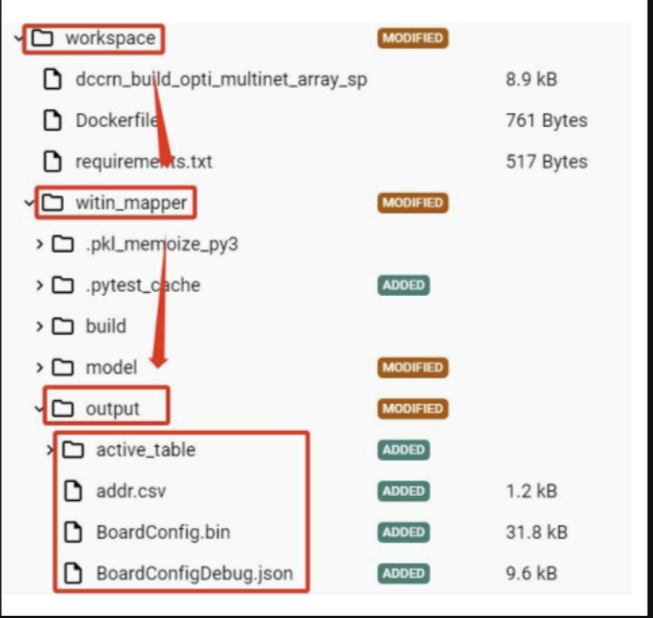
将代码放入 docker 工具链环境中,编译运行,得到输出的模型权重表:
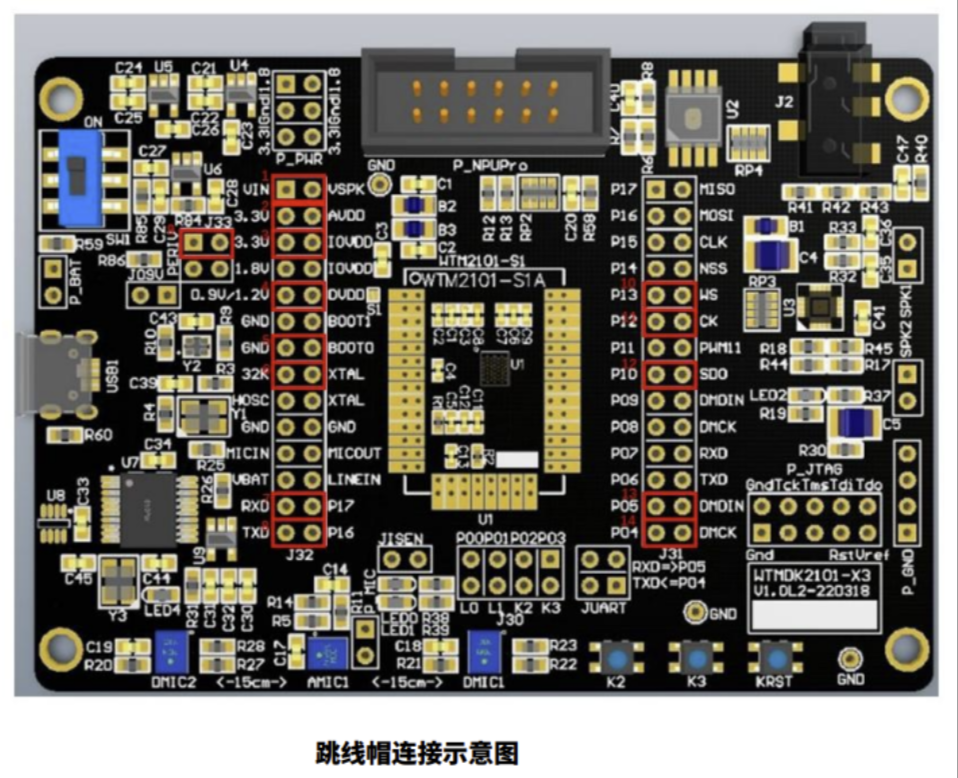
开发板连接好跳线帽、数据线如下图:
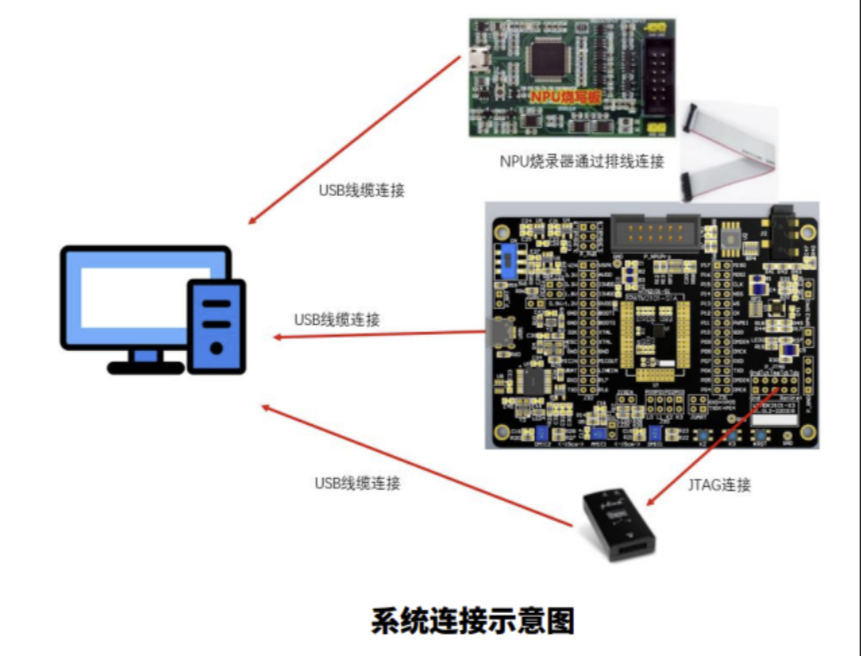
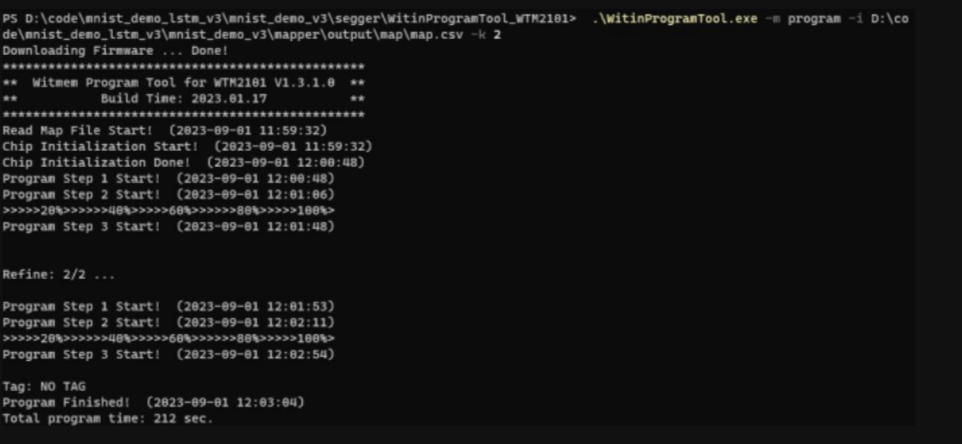
通过烧写工具 WitinProgramTool 将模型权重烧录到开发板上:
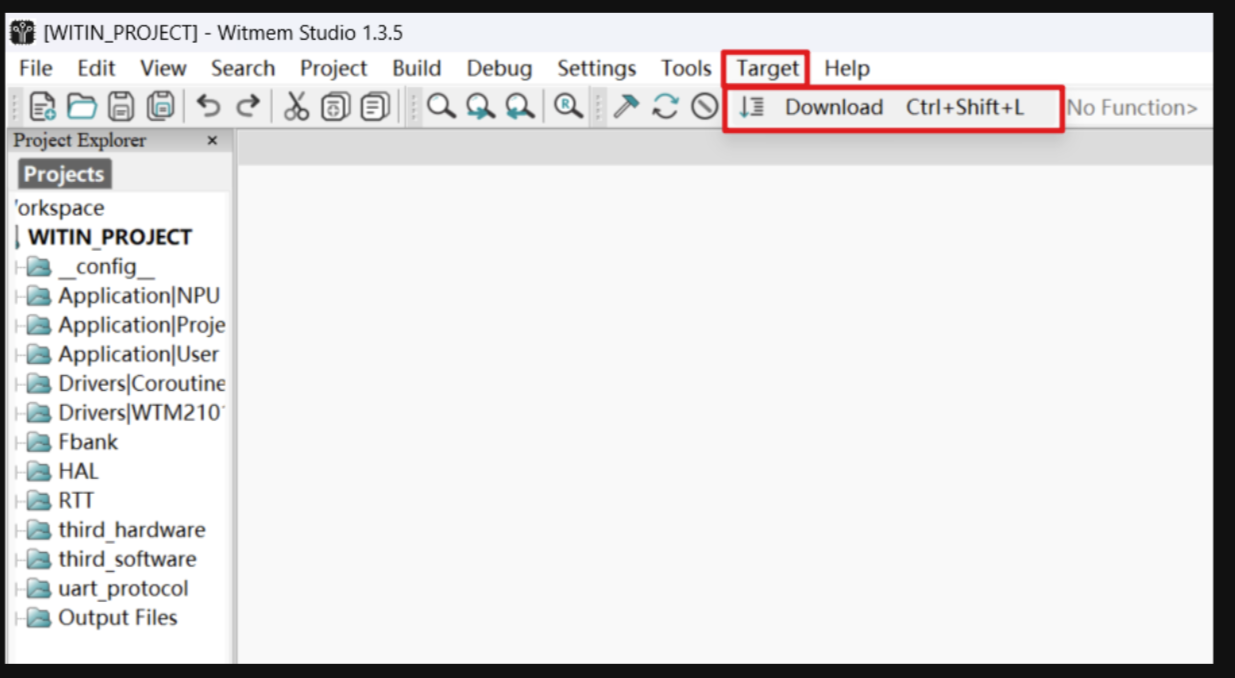
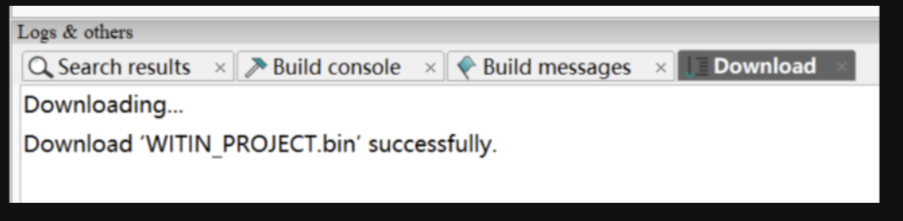
通过知存 IDE Witmem Studio,烧录提供好的工程代码。
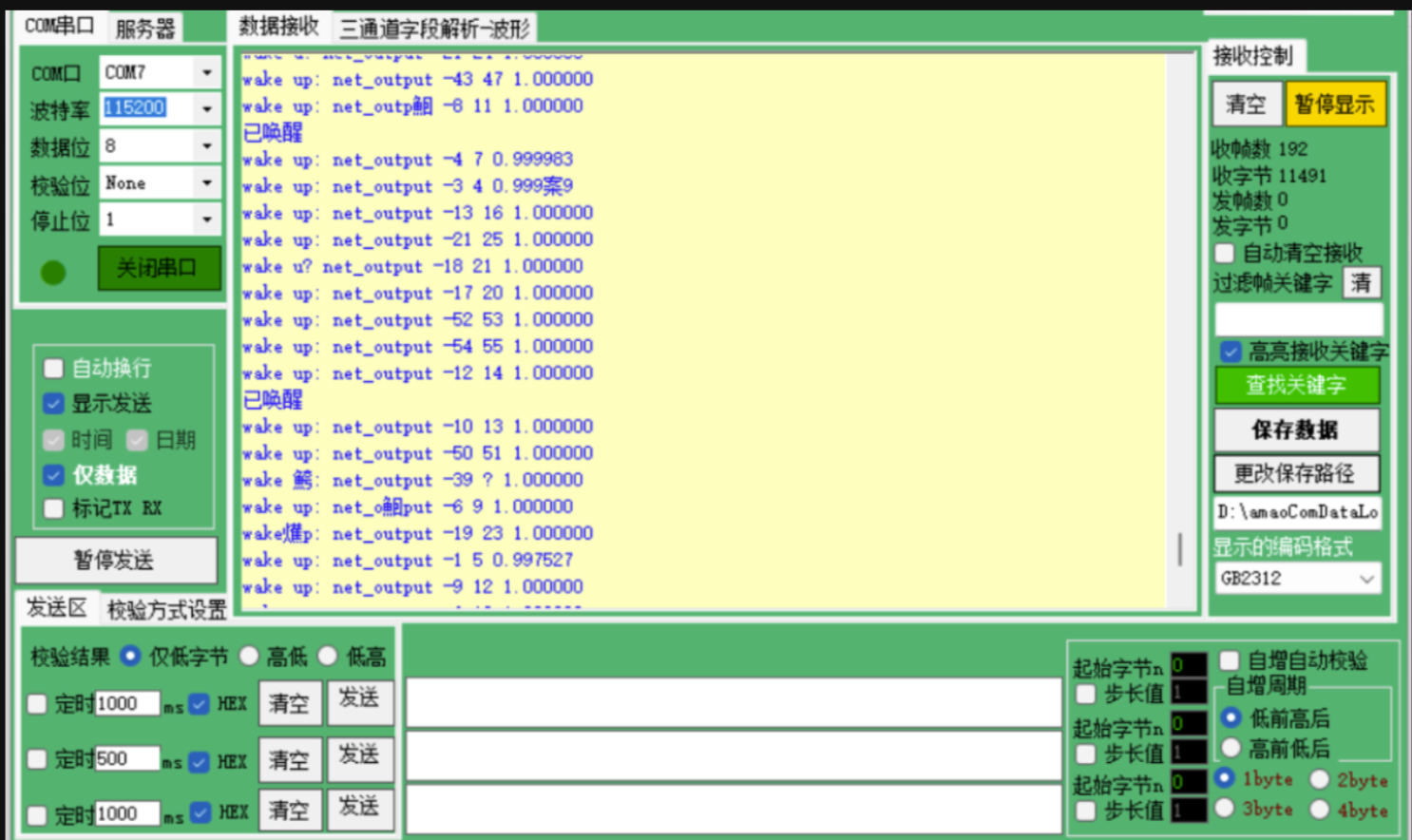
打开串口调试助手(波特率115200,数据位8,停止位1,无校验位)。若成功运行,此时当我们对着开发板说出“你好,米雅”或 “Hi, Mia” 时,串口便会输出“已唤醒” 的提示信息。
总结
对我个人而言,我接触 AI 非常少,只在前后端、嵌入式领域有过一些涉猎。因此,这次活动虽然在 AI 领域前辈来看可能是比较轻松的一个小任务,不过这份成就感让我很满足,我也大致能理解各个流程的作用。

从今年5月的 ST 峰会上大力推广的边缘AI,7月 RV 峰会上百家争鸣的 AI 应用,这两次算能和知存科技的 AI 硬件体验活动,我逐渐也能感觉到 AI (特别是当下的 AIGC)对嵌入式领域同样不容小觑的影响。现阶段自己的学习还停留在一些简单的控制,RTOS 这些。也许加深一些学习后,未来也可能在嵌入式深度学习领域有所学习~
审核编辑 黄宇
-
知存科技WTM2101芯片助力导览行业AI新体验2024-11-06 1747
-
第五届长沙·中国1024程序员节开幕2024-10-25 1090
-
从MRAM的演进看存内计算的发展2024-05-17 2843
-
【基于存内计算芯片开发板验证语音识别】训练手册2024-05-16 1664
-
1024程序员节特别篇 | 知存科技xCSDN北京·杭州双城嘉年华精彩回顾2023-10-24 1561
-
2023 长沙-中国1024程序员节全面启动2023-08-28 2050
-
创新成果受肯定,WTM2101芯片亮相中关村论坛多个展区2023-06-07 1589
-
知存科技WTM2101语音芯片的具备四个优势2023-04-23 1945
-
存内计算的前景如何2023-02-09 2311
-
1024程序员节怎么过?带上电脑去旅行!2022-10-24 2100
-
长沙1024程序员节求索论道 1024点亮软件定义时代2020-10-24 6279
全部0条评论

快来发表一下你的评论吧 !
