

智谱AI领跑司南OpenCompass 2.0月度榜单,GLM-4展示强大实力
描述
近期,大模型开源开放评测体系司南(OpenCompass 2.0)公布了2024年4月大语言模型最新评测榜单,智谱AI的GLM-4继续保持国产大模型第一的领先身位。
大模型开源开放评测体系司南(OpenCompass 2.0)由上海人工智能实验室发布。其月度榜单从基础能力和综合能力的设计出发,构建了一套高质量的中英文双语评测基准体系,对主流开源模型和商业API模型进行了全面评测分析。评测榜单涉及的大语言模型和多模态大模型超过150个,更有包括Meta、阿里巴巴、腾讯、百度等30余家国内外企业和科研机构采用OpenCompass助力开展技术研发。
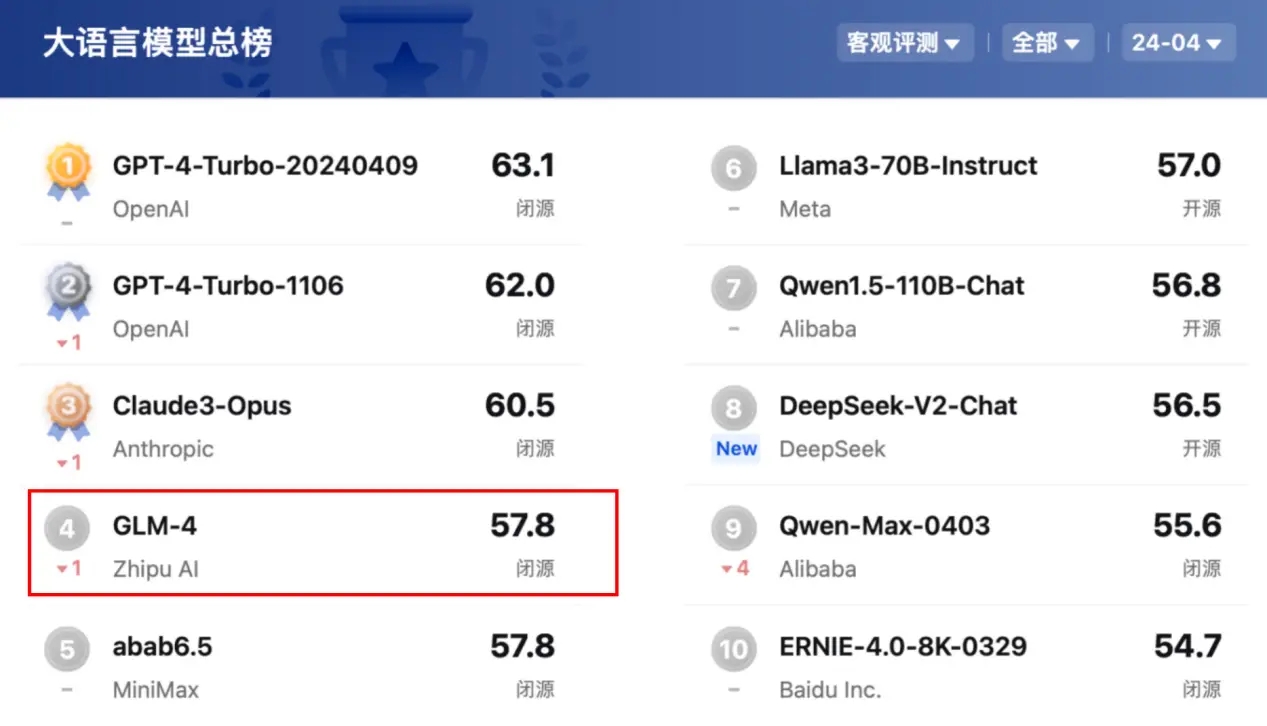
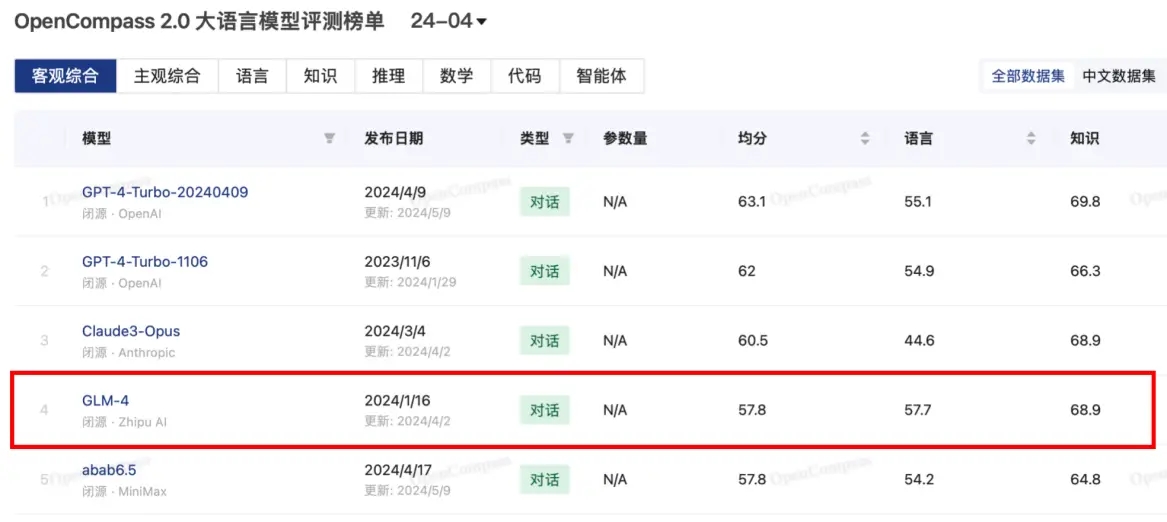
在4月客观评测榜单中,OpenCompass基于语言、知识、推理、数学、代码、智能体六个维度构建了15000余道高质量中英文双语问题,并引入OpenCompass团队首创的循环评估 (Circular Evalution) 策略,系统性分析了国内外大模型的客观性能。其中,GLM-4位列第四名,仅次于GPT-4-Turbo系列与Claude3-Opus,成为国内大模型客观评测月度总榜第一名。在语言维度方面,GLM-4分数达到57.7分表现突出,超过GPT-4-Turbo系列与Claude3-Opus。在知识维度上,GLM-4得到68.9分,超过第二名的GPT-4-Turbo-1106,与第三名Claude3-Opus不相上下。
值得一提的是,GLM-4此前便长期占据OpenCompass 2.0榜单前列,并多次在权威榜单与全球顶级大模型一较高下。清华《SuperBench大模型综合能力评测报告》显示,GLM-4在语义理解等方面的能力表现超过了GPT-4-Turbo等国际一流模型,在代码、智能体等方面,排名国内第一。在SuperCLUE-Fin(SC-Fin)中文原生金融大模型测评基准中,GLM-4斩获一项A+及多项A级评价,在国内大模型中排名第一。
据了解,GLM-4是由智谱AI于今年1月推出的新一代基座大模型。GLM-4整体性能逼近GPT-4,它可以支持更长的上下文,具备更强的多模态能力。同时,它的推理速度更快,支持更高的并发,大大降低推理成本。依托GLM-4 All Tools能力,GLM-4智能体能够实现自主根据用户意图,自动理解、规划复杂指令,自由调用网页浏览器、Code Interpreter代码解释器和多模态文生图大模型以完成复杂任务。
开发者可以通过智谱AI大模型开放平台bigmodel.cn接入GLM-4模型开放API,便捷高效地体验GLM-4的强大能力。
审核编辑 黄宇
-
沐曦股份曦云C系列GPU产品Day 0适配智谱GLM-5.1旗舰模型2026-04-09 380
-
华为昇腾深度适配智谱AI全新开源模型GLM-52026-02-25 1343
-
曦云C系列GPU Day 0 适配智谱全新一代大模型GLM-52026-02-12 1092
-
广和通MagiCore 2.0机芯盒入选2025年度AI+硬核应用创新榜单2026-02-02 548
-
沐曦股份曦云C系列GPU Day 0适配智谱GLM-4.6V多模态大模型2025-12-17 836
-
华为CANN与智谱GLM端侧模型完成适配2025-08-11 2776
-
智谱 GLM-PC 开放体验,多模态 Agent 升级2025-01-24 1615
-
智谱GLM-Zero深度推理模型预览版正式上线2025-01-02 1138
-
智谱AI宣布GLM-4-Flash大模型免费开放2024-08-28 1845
-
智谱AI发布全新多模态开源模型GLM-4-9B2024-06-07 1706
-
智谱AI亮相2024 ICLR,分享面向AGI的三大技术趋势2024-05-11 1173
-
大模型开源开放评测体系司南正式发布2024-02-05 1983
-
智谱AI推出新一代基座大模型GLM-42024-01-17 1837
全部0条评论

快来发表一下你的评论吧 !
