

Amdocs使用NVIDIA NIM加速生成式AI性能并降低成本
描述
电信公司正在利用生成式 AI,通过自动化流程、改善客户体验和优化网络运营来提高员工生产力。
Amdocs 是一家领先的通信和媒体公司软件和服务提供商,打造了一个电信专用生成式 AI 平台——amAIz,为电信公司提供了一个开放、安全、经济高效且跨大语言模型(LLM)的框架。Amdocs 正在利用 NVIDIA DGX Cloud 和 NVIDIA AI Enterprise 软件,提供基于商用 LLM 的解决方案,以及适用于特定领域的模型,使服务提供商能够构建和部署企业级生成式 AI 应用程序。
Amdocs 也在使用 NVIDIA NIM,这是一组易于使用的推理微服务,旨在加速生成式 AI 在企业中的大规模部署。该多功能微服务支持来自开放社区的模型和 NVIDIA API 产品目录中的 NVIDIA AI Foundation 模型,以及自定义 AI 模型。NIM 旨在推动高吞吐量、低延迟的无缝 AI 推理,同时保持预测的高准确性。
客户计费用例
电信公司的联络中心会收到大量客户的计费查询电话。他们向客服寻求解释,因为各种操作可能会影响他们的账单,包括客户的移动计划、促销期结束或意外收费。
Amdocs 正在开发一种基于 LLM 的解决方案,该解决方案通过对账单问题提供即时准确的解释来帮助客户。该解决方案旨在减少客服代理的工作量,使他们能够专注于更复杂的任务。
图 1 显示了从数据收集和准备到 LLM 微调,再到评估的总体流程。
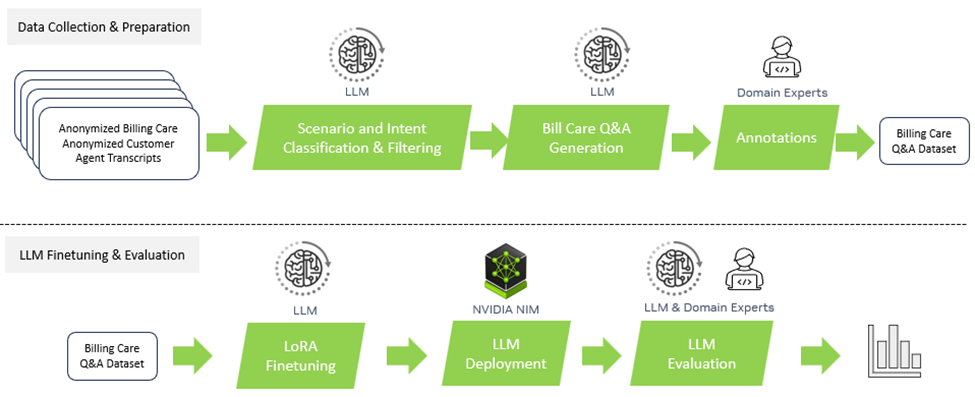
图 1. 从数据收集和准备到 LLM 微调和评估的整体流程
数据收集和准备
为了解决这个问题,他们从匿名的通话记录和账单中创建了一个新的数据集,由电信客服专家标记。该数据集包含数百个注释问题和答案,这些问题和答案被分类到相关场景中。大部分数据用于微调,性能在一个小测试集(几十个样本)上报告。
表 1 显示了所收集数据的一个示例。该问题与计费更改有关,注释的答案基于客户历史账单。

表 1. 移动计划促销到期场景中收集的数据示例
在这个过程中,Amdocs 使用 OpenAI GPT-4 LLM 这一工具来过滤通话记录并将其分类到不同场景中。然后,LLM 被用于生成潜在的问答对,这些问答对被领域专家重新访问和标记。
数据格式和提示工程
作为基线,Amdocs 使用 Llama2-7b-chat、Llama2-13b-chat 和 Mixtral-8x7b LLM 来增强具有意向分类和账单问答功能的客户服务聊天机器人。Amdocs 设计了带有指令的提示,其中包括目标账单(原始 XML 格式的连续一到两个计费月)及其相关问题。
使用基准 LLM 和零样本或少样本推理的初始实验表现不佳,主要是由于从客户账单中提取相关信息的复杂性。此外,原始 XML 格式需要详细说明 LLM 的计费格式。因此,由于某些 LLM(例如,Llama2 的 4K tokens)的最大上下文长度的限制,Amdocs 在将账单和指令纳入提示中时面临挑战。
为了适应上下文窗口,Amdocs 的第一项工作是简化提示中的计费格式说明。图 2 显示了使用 Llama2 标记器(tokenizer),重新格式化后的 token 平均数量从 3909 个减少到 1153 个。
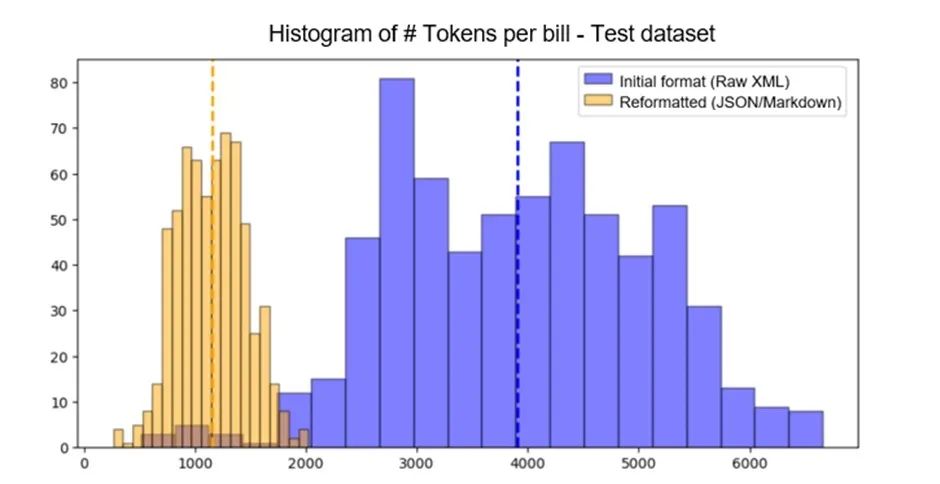
图 2. 使用新计费格式减少的 token 数量
NVIDIA DGX Cloud 上的 LLM 微调
由于注释数据量有限,Amdocs 探索了参数高效微调(PEFT)方法,如低秩自适应(LoRA)。他们用两种基础 LLM 架构(Llama2 和 Mixtral)进行了几次微调实验,研究了一到两个时期的几个 LoRA 超参数。
Amdocs 的实验是在 NVIDIA DGX Cloud 上进行的,这是一个面向开发者的端到端 AI 平台,提供基于最新 NVIDIA 架构的可扩展能力,并与世界领先的云服务提供商共同设计。Amdocs 使用的 NVIDIA DGX Cloud 实例包含以下组件:
8 个 NVIDIA 80GB Tensor Core GPU
88 个 CPU 核心
1TB 系统内存
在多 GPU 环境下执行微调周期,每个周期不到一个小时。
使用 NVIDIA NIM 部署 LLM
NVIDIA NIM 基于 NVIDIA Triton 推理服务器所构建,采用 TensorRT-LLM 对 NVIDIA GPU 上的 LLM 推理进行优化。NIM 通过预先优化的推理容器来推动无缝的 AI 推理,这些容器开箱即用,在加速的基础设施上提供极佳的延迟和吞吐量,同时确保预测的准确性。无论是在本地还是在云中,NIM 都提供了以下优势:
简化 AI 应用程序开发
为最新的生成式 AI 模型预先配置的容器
通过服务级别协议提供企业支持,并定期更新 CVE 的安全性
支持最新的社区前沿的 LLM
成本效益和性能
对于该应用程序,Amdocs 使用自托管的 NVIDIA NIM 实例来部署经过微调的 LLM。他们公开了类似 OpenAI 的 API 端点,为他们的客户端应用程序启用了统一的解决方案,该解决方案使用 LangChain 的 ChatOpenAI 客户端。
在微调探索过程中,Amdocs 创建了一个流程,通过 NIM 自动部署 LoRA 微调检查点。对于微调后的 Mixtral-8x7B 模型,该过程花费了大约 20 分钟。
结果
Amdocs 已经看到了这一过程的多重效率。
准确性提高:通过与 NVIDIA 合作,显著提高了 AI 生成响应的准确性,准确性提高了 30%。这类改进对于加快推动生成式 AI 在电信行业的广泛应用和满足面向消费者的生成式 AI 服务的需求至关重要。
使用 NVIDIA NIM,Amdocs 在成本和延迟方面都有所改进。
运营成本降低:Amdocs 在 NVIDIA 基础设施上的电信检索增强生成(RAG)使部署用例所消耗的 token 在数据预处理和推理方面分别降低了 60% 和 40%,以更低的成本提供相同水平的准确性。
延迟降低:该协作成功地将查询延迟减少了约 80%,从而确保最终用户体验到近乎实时的响应速度。这项加速提升了用户在商业、医疗、运营等领域的体验。
LLM 准确性评估
为了在微调阶段评估测试数据集上跨模型和提示的性能,Amdocs 使用了图 3 中的高级流程。

图 3. 包括 LLM-as-a-Judge 和人类专家在内的 LLM 评估过程
对于每个实验,Amdocs 首先在测试数据集上生成 LLM 输出预测。
然后,使用外部 LLM-as-a-Juage 来评估预测,提供准确性和相关性的指标。对符合预定义标准的实验进行自动回归测试,以验证预测细节的准确性。由此得出的分数是多种指标的混合,包括以下:
F1 分数
无幻觉指示器
准确结论指示器
回答相关性
对话一致性
无回退指示器
完整性
毒性指标
最后,手动评估性能最佳的模型,以确认总体准确性。这一过程确保了微调后的 LLM 既有效又可靠。
图 4 显示了不同 LLM 的总体准确度得分。Amdocs 观察到,与基础版本相比,Mixtral-8x7B 和 Llama2-13b-cat 的 LoRA 微调版本的准确率分别提高了 20-30%。结果还显示,与托管 LLM 服务相比,准确率提高了 6%。
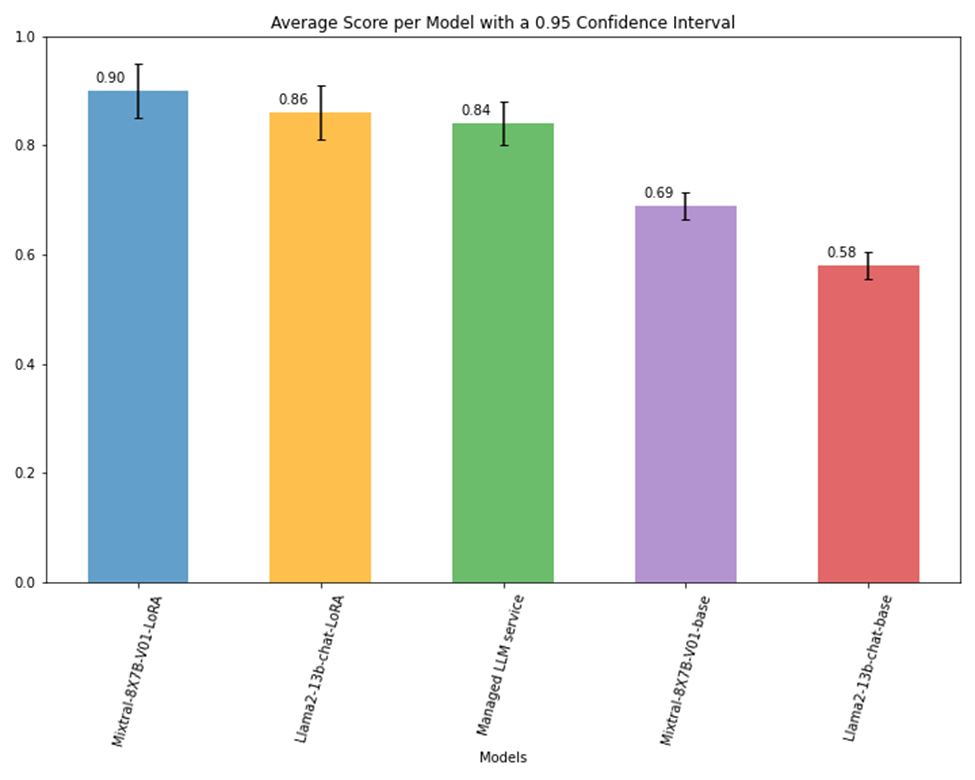
图 4. 前三名模型的平均得分提升情况
Token 消耗
重新格式化计费数据导致输入 token 减少了 60%。虽然经过微调的 LLM 产生了相当或更好的性能,但这些模型也使输入 token 额外节省了约 40%。这归因于最小化提示指令的域自定义。
图 5 显示了 Mixtral-8x7B、Llama2-13b 和托管 LLM 服务的 token 消耗之间的比较。输入 token 数量的差异主要是由于托管 LLM 服务为很好地执行任务中所需的详细指令。对于域定制的 Llama2 和 Mixtral-8x7B 模型,减少是由于持续的上下文格式改进。
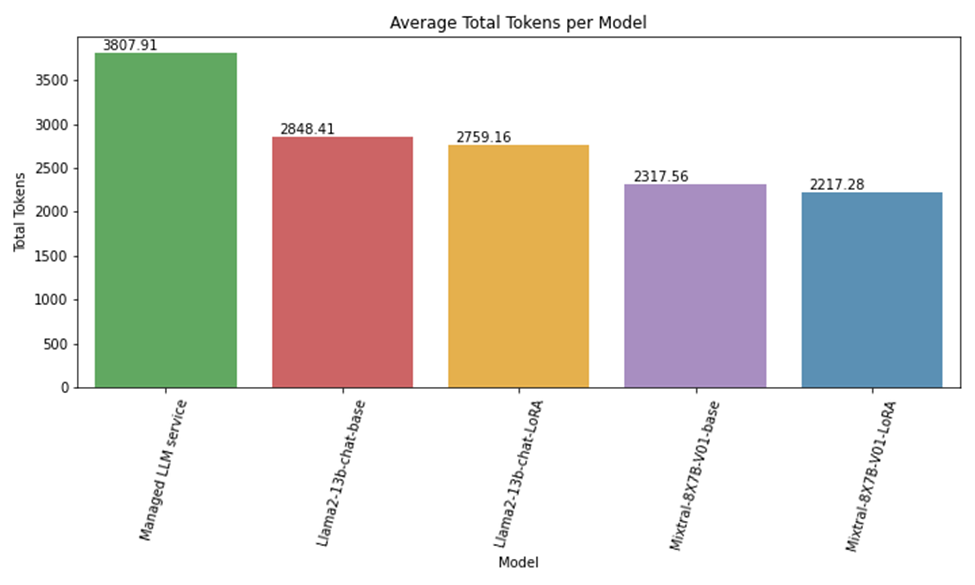
图 5. Mixtral-8x7B、Llama2 和托管 LLM 服务的标记消耗情况
LLM 延迟
在使用 NVIDIA NIM 对 NVIDIA 80GB GPU 上部署的模型进行评估期间,Amdocs 观察到平均推理速度比先进的托管 LLM 服务快 4-6 倍,约 80%。
图 6 显示了使用单个 LLM 调用执行的延迟实验,并计算了整个生成周期的平均延迟。Llama2-13b 模型部署在一个 GPU 上,而 Mixtral-8x7B 部署在两个 GPU 上。当使用自托管端点时,响应延迟更加一致,如图 6 所示的 0.95 置信区间线所示。
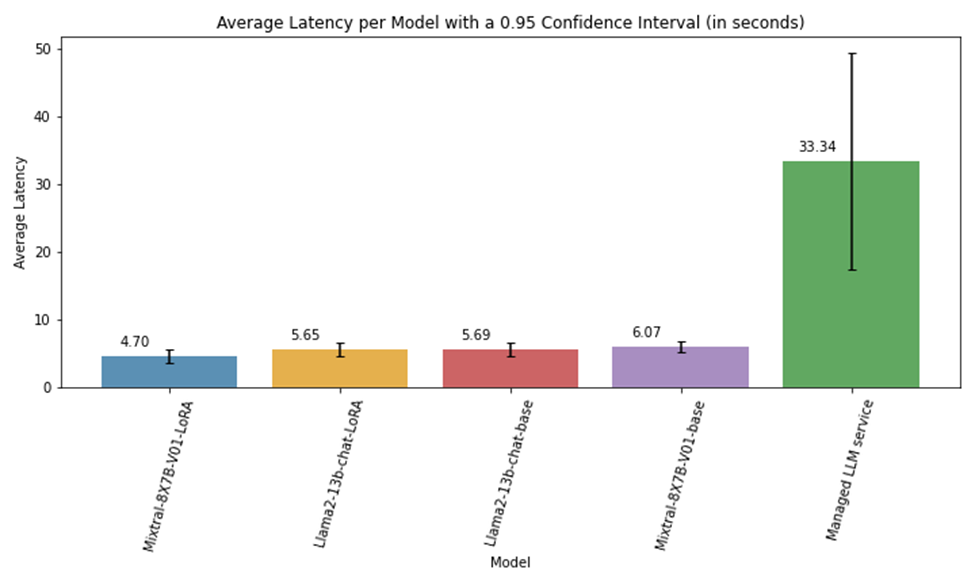
图 6. 每个模型的平均延迟(以秒为单位)
结论和下一步行动
NVIDIA NIM 推理微服务改善了延迟,使 Amdocs 应用程序中的处理速度更快。通过优化数据格式和微调 LLM,Amdocs 提高了其计费问答系统的准确性,同时显著降低了成本。在整个过程中,Amdocs 面临着不同的挑战,需要创造性的数据格式化、及时的工程设计和模型相关的定制。定义一个明确的模型评估策略和严格的测试是他们成功的关键。
Amdocs 正在采取下一步行动,通过使用 Multi-LoRA 为不同的应用程序创建定制模型,这是一种能够在推理过程中动态加载多个模型自适应的技术。这种方法优化了内存使用,因为只有基本模型是一致加载的,而模型层自适应是根据需要动态加载的。
通过与 NVIDIA 合作,Amdocs 启动了将生成式 AI 集成到其核心产品组合中的战略。该战略从确定应用领域开始,通过用户体验设计使生成式 AI 的功能对用户更加友好,并优先处理快速工程。Amdocs 将继续使用 NVIDIA DGX Cloud 和 NVIDIA AI Enterprise 软件,以电信公司分类法定制大语言模型(LLM), 以进一步提高准确性并优化生成式 AI 训练和推理的成本。
Amdocs 计划在多个战略方向上继续将生成式 AI 集成到 amAIz 平台中。
使用 AI 驱动的语言和情感分析增强客户查询路由
增强其 AI 解决方案的推理能力,以提供针对客户特定需求的建议
解决需要广泛的领域知识、多模式和多步骤解决方案的复杂场景,如网络诊断和优化
这些战略将使运营和创新更加高效和有效。
审核编辑:刘清
-
电机企业降低成本的误区2018-10-11 2411
-
PADS中的ECAD/MCAD高效协作如何降低成本2019-05-17 4486
-
智慧医疗可以更好地利用大数据 改善医疗服务并降低成本2020-03-15 2884
-
AN-0972:AD7329如何帮助降低成本2021-04-25 869
-
利用可靠隔离技术缩小尺寸并降低成本2022-12-22 899
-
电路板pcb打样降低成本的方法2023-12-13 2112
-
英伟达推出全新NVIDIA AI Foundry服务和NVIDIA NIM推理微服务2024-07-25 1703
-
全新NVIDIA NIM微服务将生成式AI引入数字环境2024-08-02 1824
-
CC2340系统降低成本的方案剖析2024-08-27 852
-
NVIDIA NIM助力企业高效部署生成式AI模型2024-10-10 1613
-
降低成本城域网2024-10-12 493
-
中国AI企业创新降低成本打造竞争力模型2024-10-22 2060
-
NVIDIA助力Amdocs打造生成式AI智能体2024-11-19 1763
-
租用站群服务器时如何降低成本?2025-01-22 1006
-
NVIDIA 发布保障代理式 AI 应用安全的 NIM 微服务2025-01-17 415
全部0条评论

快来发表一下你的评论吧 !
