

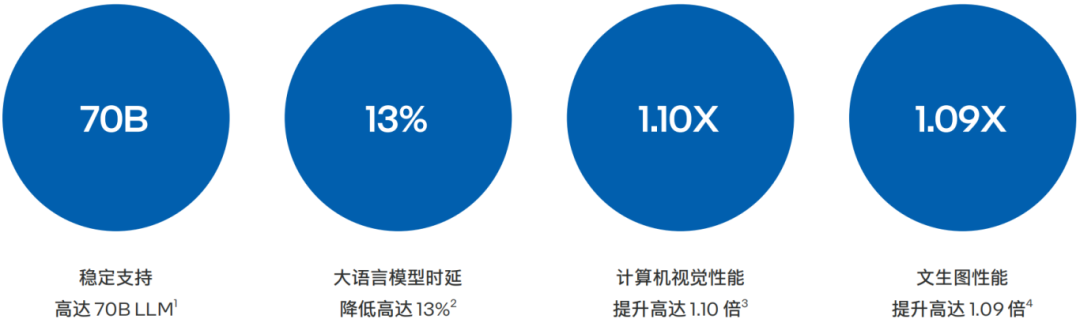
宁畅B5000 G5多节点服务器采用第五代英特尔至强可扩展处理器
描述
“基于第五代英特尔 至强 可扩展处理器的宁畅B5000 G5多节点服务器,可以在满足大量AI推理场景在吞吐量、时延、容量、并发能力等方面的需求,而且与专用的GPU服务器相比,在灵活性方面更具优势。我们希望能够与英特尔进行更加深度的合作,持续优化该方案的AI推理性能,助力用户加速拥抱大模型。”
“大模型已经成为行业用户进行业务变革的重要驱动力,这带来了规模巨大且仍在快速提升的算力需求。英特尔提供了面向大模型应用的全栈方案,第五代英特尔 至强 可扩展处理器则凭借较高的性能与灵活性,非常适合运行特定域专用模型或长尾模型。通过与宁畅合作,我们希望能够满足更多用户对于大模型推理的性能需求,加速业务转型。”
挑 战
大语言模型等AI模型的快速发展凸显了模型推理的算力瓶颈,给服务器带来了多方面的挑战:
在性能层面,模型的规模不断增长,对于算力的需求不断提升。除了硬件层面的提升之外,通过将模型数据格式转化为较低精度的数据、调用矢量神经网络指令(VNNI)等方式,也有助于提升模型的性能表现。
在灵活性层面,专用的AI推理服务器具有较高的性能表现,但是在应用场景方面有着较为严格的限制,无法高效、灵活地应对多种工作负载的运行需求。对于模型推理需求变化频繁、规模相对较小的用户而言,需要更加灵活的推理服务器,以在不同的工作负载间进行灵活切换。
在成本方面,服务器的算力密度越高,就越有利于节约数据中心空间以及数据中心能耗、设备等方面的成本。同时,通过优化AI推理性能表现,能够进一步节约成本。
解决方案概述
大语言模型(LLM)作为人工智能(AI)应用的一个重要分支,可以处理多种自然语言任务,如文本分类、问答、对话等,在互联网、金融、医疗、教育等行业有着广泛的应用,并被普遍认为是实现通用人工智能的重要方式。近年来,大语言模型实现了“井喷”式的发展,在展现人工智能的革命性价值的同时,也带来了算力层面的巨大挑战。统计数据显示,从2017年到2022年,模型的规模增长了15,000倍,典型的大模型参数规模已经达到了千亿甚至万亿级别。当大模型落地到实际场景之后,模型推理带来了庞大的算力消耗,用户需要应对大模型推理所带来的算力、总体拥有成本(TCO)、灵活性等挑战。
宁畅B5000 G5多节点服务器作为高密度的服务器,能够为大语言模型等AI应用提供强大的算力支撑。宁畅B5000 G5多节点服务器实现了对于第五代英特尔 至强 可扩展处理器的支持,能够借助第五代英特尔 至强 可扩展处理器的强大算力,以及处理器内置的英特尔 高级矩阵扩展(英特尔 AMX),实现大模型推理等AI应用的加速,在灵活性方面较专用的AI服务器更具优势。此外,宁畅B5000 G5多节点服务器还能够借助RDMA (Remote Direct Memory Access) 技术以及英特尔 以太网控制器E810,提供高速的跨节点通信。
宁畅B5000 G5多节点服务器
宁畅B5000 G5多节点服务器是一款基于英特尔 至强 可扩展处理器自主开发的高密度产品,在4U的空间可最大支持到8个双路节点,单节点已全面支持最新的第五代英特尔 至强 可扩展处理器。整个服务器的8个双路节点间互相独立,互不干扰。B5000 G5多节点服务器可支持更多的计算核心,兼备卓越的计算性能和灵活的IO扩展能力。B5000 G5可实现数据中心的高密部署、提供强大计算性能,也可以满足用户业务多样性与灵活性的需求。
该服务器具备如下优势:
全新升级极致性能:支持第五代英特尔 至强 可扩展处理器,计算性能强劲,总线带宽高达16GT/s;支持DDR5 5600MHz内存频率,内存带宽相比较上一代提升50%;全面支持PCIe 5.0,传输速率提升100%。
多节点计算灵活配置:4U8节点高密度架构,支持8个双路计算节点;机箱模块化设计,配置交换和管理集管理模块;整机最大支持4个NDR/HDR Multi Host模块或8个HDR 200G直通模块;单节点支持2个2.5寸硬盘,兼容U.2 NVMe SSD。
多重监控绿色节能:机箱搭配多级管理,包含统一的CMM管理和整机业务交换管理,整机管理支持前后维护模式,同时可完成整机所有节点IP的管理,实时监控整机状态,提供关键部件健康状态的监控和上报功能,全面保障健康运行;机箱采用模块化设计,贯彻绿色节能的设计理念,整机采用集中供电和散热,搭载高效的智能调速策略,根据环境和整机工作负载实时调速,达到静音运行的效果。
采用第五代英特尔 至强 可扩展处理器为AI推理提供强大算力支持
宁畅B5000 G5多节点服务器支持第五代英特尔 至强 可扩展处理器,进一步提升了算力密度,并提升了能效,能够为计算、存储、网络等多种类型的应用构建强大的性能基础。
第五代英特尔 至强 可扩展处理器为拓展HPC与AI应用提供了强大的性能基础。新一代处理器拥有更可靠的性能,更出色的能效。它在运行各种工作负载时均可实现显著的每瓦性能增益,在AI、数据中心、网络和科学计算的性能和总体拥有成本(TCO)方面亦有更出色的表现。相较上一代产品,第五代英特尔 至强 可扩展处理器可在相同功耗范围内提供更高的算力和更快的内存。此外,它与一代产品的软件和平台兼容,因此部署新系统时可大大减少测试和验证工作。

图2. 第五代英特尔 至强 可扩展处理器具备更强大性能
除了利用第五代英特尔 至强 可扩展处理器带来的基础性能的提升之外,宁畅B5000 G5多节点服务器还重点利用了处理器提供的AI加速能力。
该处理器内置了创新的英特尔 AMX加速引擎。英特尔 AMX针对广泛的硬件和软件优化,它进一步增强了前代技术 — 矢量神经网络指令(VNNI)和BF16,从一维向量发展为二维矩阵,以便最大限度地利用计算资源,提高高速缓存利用率,以及避免潜在的带宽瓶颈,显著增加了人工智能应用程序的每时钟指令数(IPC),可为AI工作负载中的训练和推理提供性能提升,可对参数量多达200亿的模型进行推理和调优10。
为了进一步增强AI推理性能表现,宁畅B5000 G5多节点服务器还能够英特尔 以太网控制器E810中的RDMA (Remote Direct Memory Access) 功能,降低网路数据传输过程中的时延,提供高速的跨节点通信,化解大规模AI推理任务在集群通信中的网络瓶颈。
宁畅测试了基于第五代英特尔 至强 可扩展处理器的B5000 G5多节点服务器在多种AI推理工作负载中的性能表现。
大语言模型 (LLM):高密度、多并发、支持高达70B
LLaMa2是Meta发布的免费可商用版本的大模型,LLaMa2模型系列包含70亿、130亿和700亿三种参数变体。LLaMa2相比第一代在预训练语料库大小上增加了40%,LLaMa2接受了2万亿个Token的训练,精调Chat模型在100万人类标记数据上训练,上下文长度是第一代的两倍,并采用了分组查询注意力机制等优化结构。
第四代/第五代英特尔 至强 可扩展处理器的代际时延数据对比如图3所示,在LLaMa2-7B和LLaMa2-13B模式中,时延均有13%的下降11。
此外,第五代英特尔 至强 可扩展平台可支持多通道大容量的内存,使用64G内存时,单节点(Node)至少可以扩展到1024GB内存,这样可支持LLM模型的并发。其中,70B-4Node可同时支持28个LLM模型并发,13B-1Node可同时支持40个LLM模型并发,7B-1Node可同时支持72个LLM模型并发。 在第二次token时,时延可低至63.5毫秒。除了在模型并发上有卓越表现外,模型之间的切换也在10毫秒之内,几乎无感,模型驻留数最高可达到576个12。
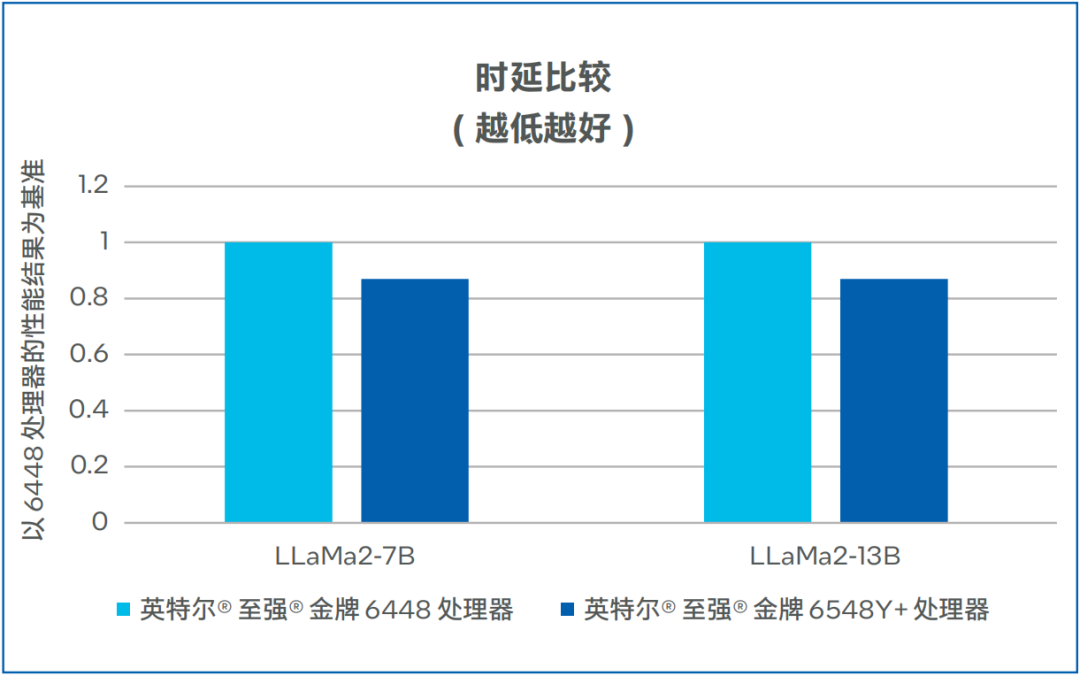
图3. LLaMa2-7B和LLaMa2-13B时延比较
Resnet 50
ResNet50是一种非常流行的卷积神经网络模型,ResNet50的主要特点是引入了“残差块”(Residual + Block)。在传统的神经网络中,每一层都是在前一层的基础上添加新的变换,而在ResNet中,每一层都是在前一层的基础上添加新的变换,同时还保留了前一层的原始输入,这种设计使得网络可以更好地学习输入和输出之间的差异,而不是直接学习输出,这有助于提高模型的性能。
宁畅的测试数据如图4所示,相较第四代英特尔 至强 可扩展处理器,基于第五代英特尔 至强 可扩展处理器的宁畅B5000 G5多节点服务器,将ResNet50推理性能提升了10%13。
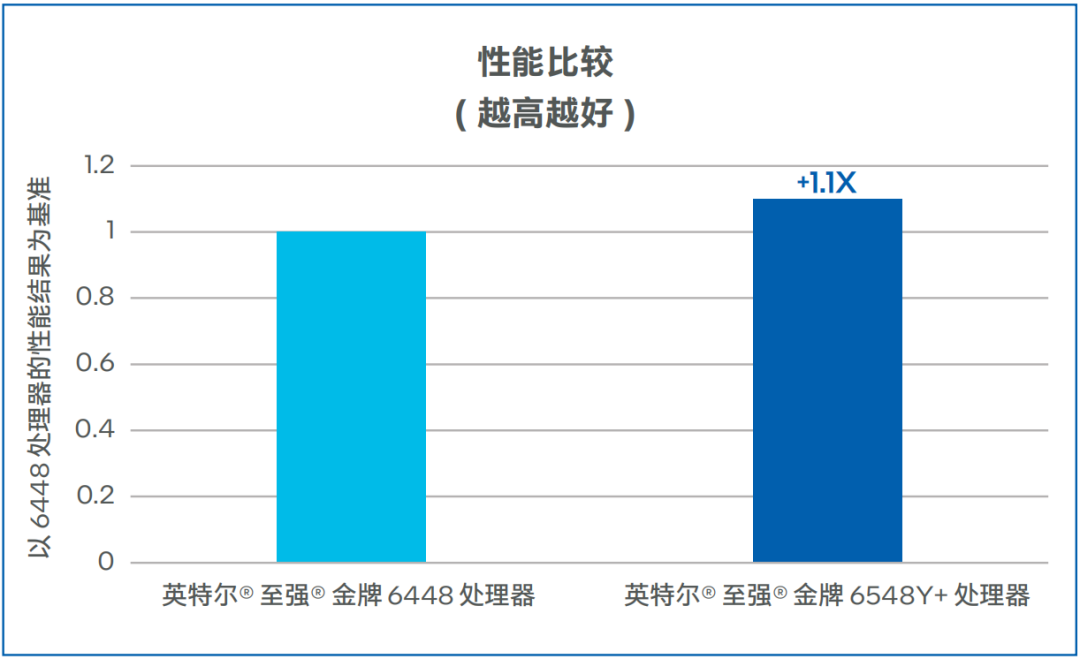
图4. ResNet50性能比较(越高越好)
文本生成图像
(Stable Diffusion)
Stable Diffusion是一种基于潜在扩散模型(Latent Diffusion Models) 的文本到图像生成模型,能够根据任意文本输入生成高质量图像,同时还保留了图像的语义结构。Stable-Diffusion一般需要数秒完成图片生成,生成的图像具有较高的逼真度和细节表现力。宁畅的测试数据如图5所示,相较第四代英特尔 至强 可扩展处理器,基于第五代英特尔 至强 可扩展处理器的宁畅B5000 G5多节点服务器,将Stable Diffusion推理性能提升了9%14。
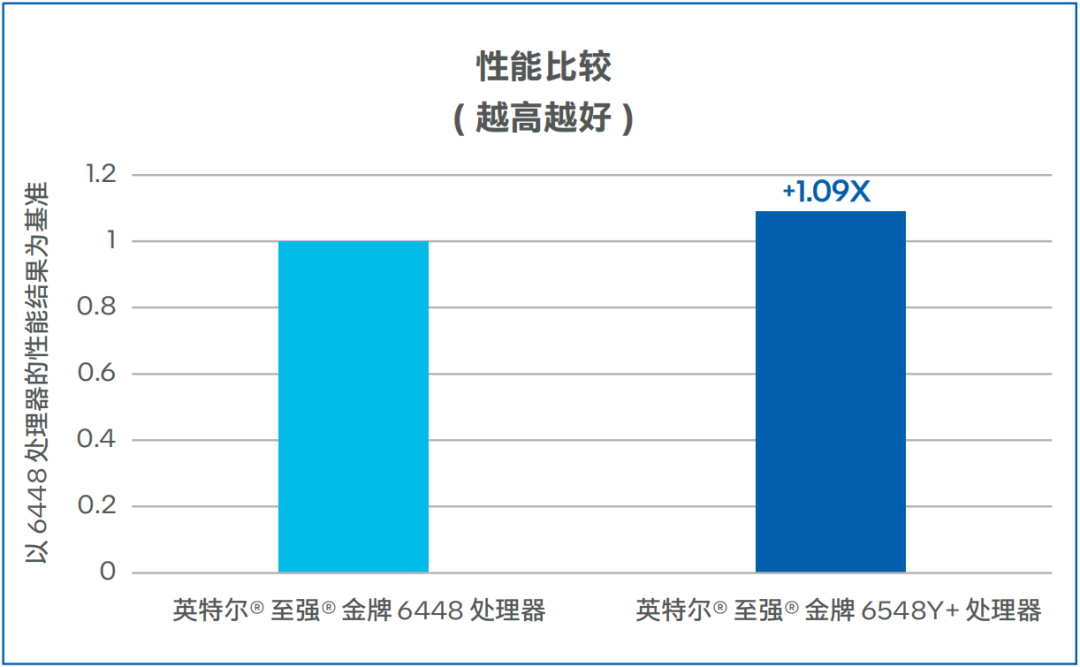
图5. Stable Diffusion性能比较
上述测试主要基于单节点配置环境完成,用户还可通过部署更多节点,来获得更高的性能表现。
收 益
基于第五代英特尔 至强 可扩展处理器的宁畅B5000 G5多节点服务器为用户的AI推理任务带来了如下收益:
在保证特定精度的前提下,模型推理的吞吐量、时延等性能指标方面能够比肩常规GPU,满足大语言模型等AI模型的推理需求。
可以在4U8节点上同时执行多个AI推理任务,在特定的服务质量(SLA)要求下,实现较高的并发量,有助于提升资源的利用率,降低AI推理的总体拥有成本(TCO)。
无需增加专门的硬件便可以支持高效的AI推理,有助于提升服务器的灵活性,敏捷地满足多种应用工作负载的支撑需求。
展 望
大模型应用已经进入到爆发期,《中国人工智能大模型地图研究报告》显示,2023 年,全球发布的大模型数量已经超过200个,其中中国发布的大模型已经达到了79个15。面对百亿、千亿乃至万亿规模的大模型数据处理、训练、调优及推理需求,用户迫切希望构建符合自身业务特点和需求的AI算力平台,进行计算资源的合理配置。基于第五代英特尔 至强 可扩展处理器的宁畅B5000 G5多节点服务器凭借在性能、灵活性等方面的优势,有望成为用户推动大模型推理的重要基础设施。
除了模型推理之外,基于第五代英特尔 至强 可扩展处理器的宁畅B5000 G5多节点服务器还在更多场景中,提供了卓越的性能、扩展性与敏捷性。双方将在技术探索、产品升级、应用推广等多个层面深度协作,建设从云到边缘的基础设施,推动数字资源平等,打破数字鸿沟,以澎湃的算力赋能数字经济的高速发展。
审核编辑:刘清
-
第五代英特尔至强处理器,AI特化的通用服务器CPU2024-03-18 6745
-
浪潮信息NE5260G7服务器适配第五代英特尔至强处理器2024-03-06 1875
-
英特尔至强处理器优化升级,助力打造未来高能效数据中心2024-02-26 1749
-
第五代英特尔至强可扩展处理器以强劲性能,打造更“全能”的计算2024-01-19 1356
-
H3C UIS超融合方案采用第五代英特尔至强可扩展处理器2024-01-13 2783
-
英特尔专家为您揭秘第五代英特尔® 至强® 可扩展处理器如何为AI加速2023-12-23 1414
-
宝德服务器全面升级到第五代英特尔®至强®平台2023-12-21 1588
-
64核+高内存带宽!英特尔发布第五代至强服务器,加速AI原生应用落地2023-12-20 3779
-
64核+高内存带宽!英特尔发布第五代至强可扩展处理器,加速AI原生应用落地2023-12-19 6297
-
第五代英特尔至强可扩展处理器 AI 性能大幅提升,英特尔加注推动人工智能无处不在2023-12-18 1360
-
英特尔发布酷睿Ultra和第五代至强可扩展处理器2023-12-16 2651
-
AI无处不在,宁畅G50系列服务器全新升级2023-12-15 1741
全部0条评论

快来发表一下你的评论吧 !
