

 LLM之外的性价比之选,小语言模型
LLM之外的性价比之选,小语言模型
描述
电子发烧友网报道(文/周凯扬)大语言模型的风靡给AI应用创造了不少机会,无论是效率还是创意上,大语言模型都带来了前所未有的表现,这些大语言模型很快成为大型互联网公司或者AI应用公司的杀手级产品。然而在一些对实时性要求较高的应用中,比如AI客服、实时数据分析等,大语言模型并没有太大的优势。
在动辄万亿参数的LLM下,硬件需求已经遭受了不小的挑战。所以面对一些相对简单的任务,规模较小的小语言模型(SLM)反而更加适合。尤其是在端侧的本地AI模型,在低功耗算力有限的边缘AI芯片支持下,小语言模型反而更适合发挥最高性能,而不是促使硬件一味地去追求更大规模模型的支持。
微软Phi
2023年,微软推出了一个基于Transformer架构的小语言模型Phi-1,该模型只有13亿参数,且主要专注于基础的Python编程,实现文本转代码。整个模型仅仅用到8块A100 GPU,耗时四天训练完成的。
这也充分说明了小语言模型的灵活性,在LLM普遍需要成百上千块GPU,花费数十乃至上百天的时间完成模型的训练时,SLM却只需要千分之一的资源,就可以针对特定的任务打造适合的模型。
近日,微软对Phi模型进行了全面更新,推出了Phi-3-mini、Phi-3-small和Phi-3-medium三个版本。其中Phi3-mini是一个38亿参数的小语言模型,同步推出的Phi-3-small和Phi-3-medium分别为70亿参数和140亿参数的模型。
Phi-3-mini有支持4K和128K两个上下文长度的版本,也是这个规模的模型中,第一个支持到最高128K上下文长度的版本,微软声称其性能甚至超过不少70亿参数的大模型。通过在搭载A16芯片的iPhone 14上测试,在纯粹的设备端离线运行下,Phi-3-mini可以做到12 token每秒的速度。
谷歌Gemma
在Gemini模型获得成功后,基于大语言模型框架Gemini,谷歌也开发了对应的轻量小语言模型Gemma。Gemma分为20亿参数和70亿参数的版本,其中20亿参数的Gemma可以在移动设备和笔记本电脑上运行,而70亿参数的版本则可以扩展至小型服务器上。虽然资源占用不高,但Gemma在各项基准测试中,依然可以与更大规模的模型相媲美,比如130亿参数的Llama-2等。
此外,谷歌不仅提供了预训练版本的Gemma,也支持通过额外的训练来实现模型调优,用于修改Gemma模型的行为,提高其在特定任务上的表现,比如通过人类语言互动进行训练,提高聊天机器人中响应式对话输入的表现等。
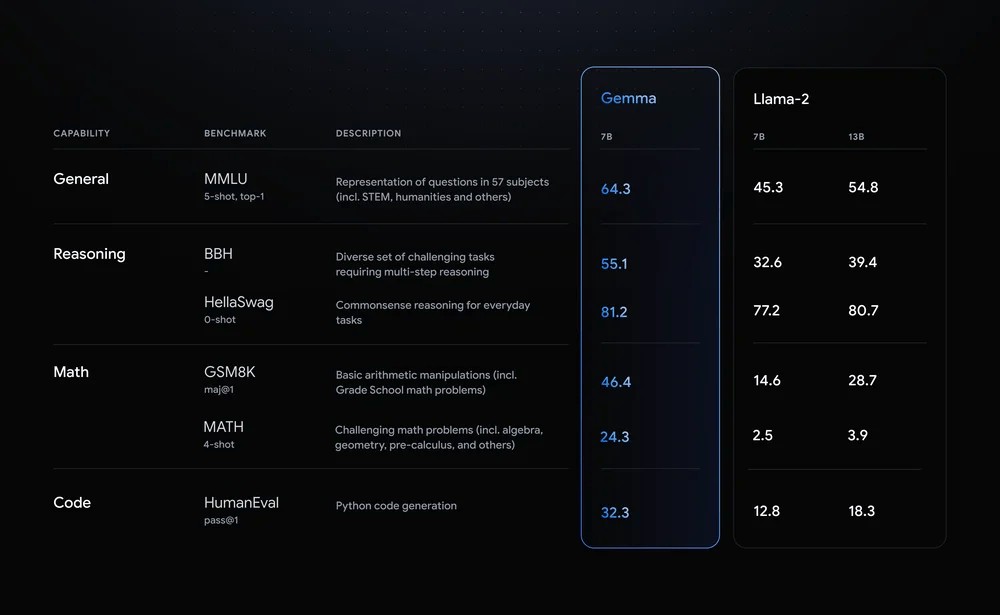
Gemma与Llama-2的性能对比/谷歌
在对运行设备的要求上,Gemma自然比不上大哥Gemini,但谷歌与英伟达合作,针对从数据中心到云端再到RTX AI PC的GPU都进行了优化,这样一来不仅具有广泛的跨设备兼容性,也能确保扩展性和高性能的双重优势。
写在最后
小语言模型的出现为行业带来了新的选择,尤其是在大多数大模型应用还是在不断烧钱的当下,小语言模型加速落地的同时,也提供了训练成本更低的解决方案。但与此同时,小语言模型的缺陷依然不可忽视,比如其规模注定了无法存储足够的“事实性知识”,其次这类小语言模型很难做到多语言支持。但我们必须认清小语言模型的存在并不是为了替代大语言模型,而是提供一个更加灵活的模型方案。
-
小白学大模型:从零实现 LLM语言模型2025-04-30 1548
-
无法在OVMS上运行来自Meta的大型语言模型 (LLM),为什么?2025-03-05 348
-
新品| LLM630 Compute Kit,AI 大语言模型推理开发平台2025-01-17 1637
-
什么是LLM?LLM在自然语言处理中的应用2024-11-19 5195
-
如何训练自己的LLM模型2024-11-08 2333
-
新品|LLM Module,离线大语言模型模块2024-11-02 2022
-
LLM大模型推理加速的关键技术2024-07-24 3614
-
大模型LLM与ChatGPT的技术原理2024-07-10 19390
-
LLM模型的应用领域2024-07-09 2433
-
大语言模型(LLM)快速理解2024-06-04 3120
-
基于Transformer的大型语言模型(LLM)的内部机制2023-06-25 2756
-
大型语言模型(LLM)的自定义训练:包含代码示例的详细指南2023-06-12 3890
全部0条评论

快来发表一下你的评论吧 !
