

通过强化学习策略进行特征选择
描述
来源:DeepHub IMBA
特征选择是构建机器学习模型过程中的决定性步骤。为模型和我们想要完成的任务选择好的特征,可以提高性能。
如果我们处理的是高维数据集,那么选择特征就显得尤为重要。它使模型能够更快更好地学习。我们的想法是找到最优数量的特征和最有意义的特征。
在本文中,我们将介绍并实现一种新的通过强化学习策略的特征选择。我们先讨论强化学习,尤其是马尔可夫决策过程。它是数据科学领域的一种非常新的方法,尤其适用于特征选择。然后介绍它的实现以及如何安装和使用python库(FSRLearning)。最后再使用一个简单的示例来演示这一过程。
强化学习:特征选择的马尔可夫决策问题
强化学习(RL)技术可以非常有效地解决像游戏解决这样的问题。而强化学习的概念是基于马尔可夫决策过程(MDP)。这里的重点不是要深入定义而是要大致了解它是如何运作的,以及它如何对我们的问题有用。
强化学习背后的想法是,代理从一个未知的环境开始。采取行动来完成任务。在代理在当前状态和他之前选择的行为的作用下,会更倾向于选择一些行为。在每到达一个新状态并采取行动时,代理都会获得奖励。以下是我们需要为特征选择而定义的主要参数:状态、行动、奖励、如何选择行动首先,状态是数据集中存在的特征的子集。例如,如果数据集有三个特征(年龄,性别,身高)加上一个标签,则可能的状态如下:
[] --> Empty set
[Age], [Gender], [Height] --> 1-feature set
[Age, Gender], [Gender, Height], [Age, Height] --> 2-feature set
[Age, Gender, Height] --> All-feature set
在一个状态中,特征的顺序并不重要,我们必须把它看作一个集合,而不是一个特征列表。
对于动作,我们可以从一个子集转到任何一个尚未探索的特性的子集。在特征选择问题中,动作就是是选择当前状态下尚未探索的特征,并将其添加到下一个状态。以下是一些可能的动作:
[Age] -> [Age, Gender]
[Gender, Height] -> [Age, Gender, Height]
下面是一个不可能动作的例子:
[Age] -> [Age, Gender, Height]
[Age, Gender] -> [Age]
[Gender] -> [Gender, Gender]
我们已经定义了状态和动作,还没有定义奖励。奖励是一个实数,用于评估状态的质量。
在特征选择问题中,一个可能的奖励是通过添加新特征而提高相同模型的准确率指标。下面是一个如何计算奖励的例子:
[Age] --> Accuracy = 0.65
[Age, Gender] --> Accuracy = 0.76
Reward(Gender) = 0.76 - 0.65 = 0.11
对于我们首次访问的每个状态,都会使用一组特征来训练一个分类器(模型)。这个值存储在该状态和对应的分类器中,训练分类器的过程是费时费力的,所以我们只训练一次。因为分类器不会考虑特征的顺序,所以我们可以将这个问题视为图而不是树。在这个例子中,选择“性别”作为模型的新特征的操作的奖励是当前状态和下一个状态之间的准确率差值。
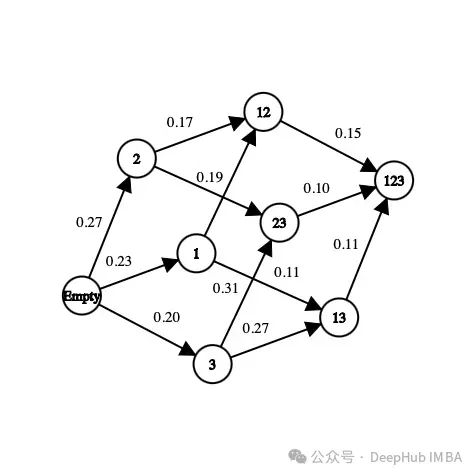
在上图中,每个特征都被映射为一个数字(“年龄”为1,“性别”为2,“身高”为3)。我们如何从当前状态中选择下一个状态或者我们如何探索环境呢?
我们必须找到最优的方法,因为如果我们在一个有10个特征的问题中探索所有可能的特征集,那么状态的数量将是
10! + 2 = 3 628 802
这里的+2是因为考虑一个空状态和一个包含所有可能特征的状态。我们不可能在每个状态下都训练一个模型,这是不可能完成的,而且这只是有10个特征,如果有100个特征那基本上就是无解了。
但是在强化学习方法中,我们不需要在所有的状态下都去训练一个模型,我们要为这个问题确定一些停止条件,比如从当前状态随机选择下一个动作,概率为epsilon(介于0和1之间,通常在0.2左右),否则选择使函数最大化的动作。对于特征选择是每个特征对模型精度带来的奖励的平均值。
这里的贪心算法包含两个步骤:
1、以概率为epsilon,我们在当前状态的可能邻居中随机选择下一个状态
2、选择下一个状态,使添加到当前状态的特征对模型的精度贡献最大。为了减少时间复杂度,可以初始化了一个包含每个特征值的列表。每当选择一个特性时,此列表就会更新。使用以下公式,更新是非常理想的:
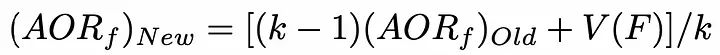
AORf:特征“f”带来的奖励的平均值
K:f被选中的次数
V(F):特征集合F的状态值(为了简单描述,本文不详细介绍)
所以我们就找出哪个特征给模型带来了最高的准确性。这就是为什么我们需要浏览不同的状态,在在许多不同的环境中评估模型特征的最全局准确值。
因为目标是最小化算法访问的状态数,所以我们访问的未访问过的状态越少,需要用不同特征集训练的模型数量就越少。因为从时间和计算能力的角度来看,训练模型以获得精度是最昂贵方法,我们要尽量减少训练的次数。
最后在任何情况下,算法都会停止在最终状态(包含所有特征的集合)而我们希望避免达到这种状态,因为用它来训练模型是最昂贵的。
上面就是我们针对于特征选择的强化学习描述,下面我们将详细介绍在python中的实现。
用于特征选择与强化学习的python库
有一个python库可以让我们直接解决这个问题。但是首先我们先准备数据
我们直接使用UCI机器学习库中的数据:
#Get the pandas DataFrame from the csv file (15 features, 690 rows)
australian_data = pd.read_csv('australian_data.csv', header=None)
#DataFrame with the features
X = australian_data.drop(14, axis=1)
#DataFrame with the labels
y = australian_data[14]
然后安装我们用到的库
pip install FSRLearning
直接导入
from FSRLearning import Feature_Selector_RL
Feature_Selector_RL类就可以创建一个特性选择器。我们需要以下的参数
feature_number (integer): DataFrame X中的特性数量
feature_structure (dictionary): 用于图实现的字典
eps (float [0;1]): 随机选择下一状态的概率,0为贪婪算法,1为随机算法
alpha (float [0;1]): 控制更新速率,0表示不更新状态,1表示经常更新状态
gamma (float[0,1]): 下一状态观察的调节因子,0为近视行为状态,1为远视行为
nb_iter (int): 遍历图的序列数
starting_state (" empty "或" random "): 如果" empty ",则算法从空状态开始,如果" random ",则算法从图中的随机状态开始
所有参数都可以机型调节,但对于大多数问题来说,迭代大约100次就可以了,而epsilon值在0.2左右通常就足够了。起始状态对于更有效地浏览图形很有用,但它非常依赖于数据集,两个值都可以测试。
我们可以用下面的代码简单地初始化选择器:
fsrl_obj = Feature_Selector_RL(feature_number=14, nb_iter=100)
与大多数ML库相同,训练算法非常简单:
results = fsrl_obj.fit_predict(X, y)
下面是输出的一个例子:
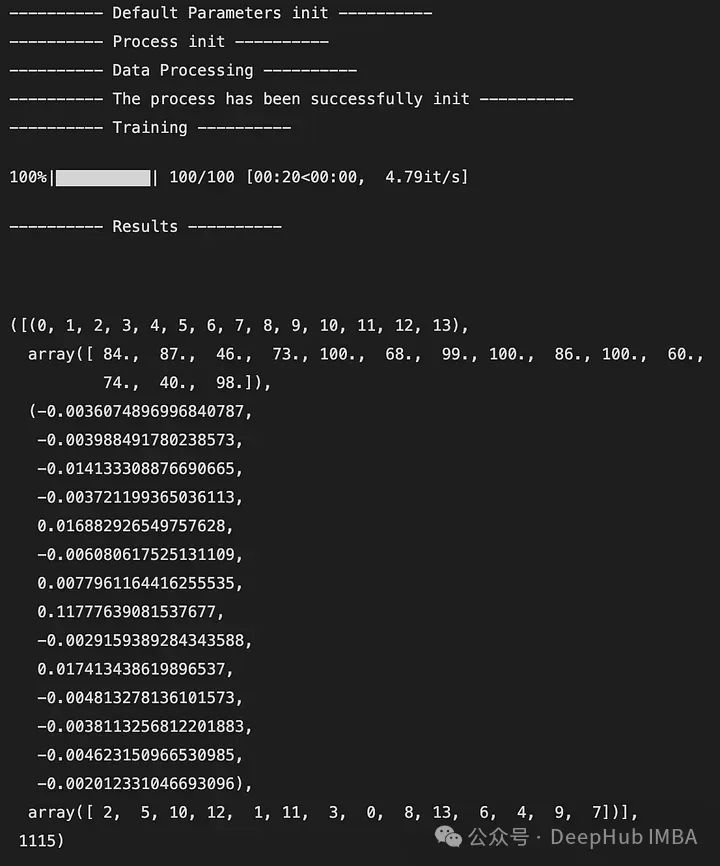
输出是一个5元组,如下所示:
DataFrame X中特性的索引(类似于映射)
特征被观察的次数
所有迭代后特征带来的奖励的平均值
从最不重要到最重要的特征排序(这里2是最不重要的特征,7是最重要的特征)
全局访问的状态数
还可以与Scikit-Learn的RFE选择器进行比较。它将X, y和选择器的结果作为输入。
fsrl_obj.compare_with_benchmark(X, y, results)
输出是在RFE和FSRLearning的全局度量的每一步选择之后的结果。它还输出模型精度的可视化比较,其中x轴表示所选特征的数量,y轴表示精度。两条水平线是每种方法的准确度中值。
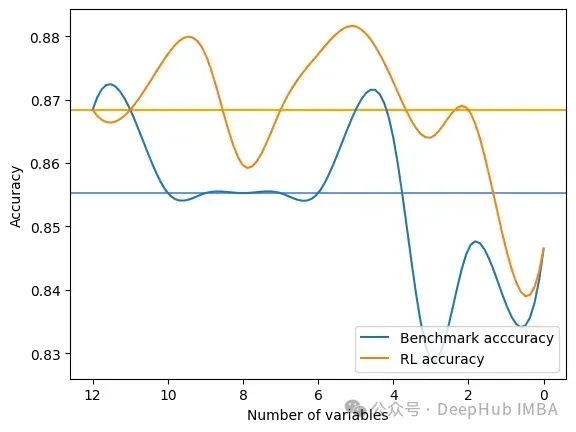
Average benchmark accuracy : 0.854251012145749, rl accuracy : 0.8674089068825909
Median benchmark accuracy : 0.8552631578947368, rl accuracy : 0.868421052631579
Probability to get a set of variable with a better metric than RFE : 1.0
Area between the two curves : 0.17105263157894512
可以看到RL方法总是为模型提供比RFE更好的特征集。
另一个有趣的方法是get_plot_ratio_exploration。它绘制了一个图,比较一个精确迭代序列中已经访问节点和访问节点的数量。
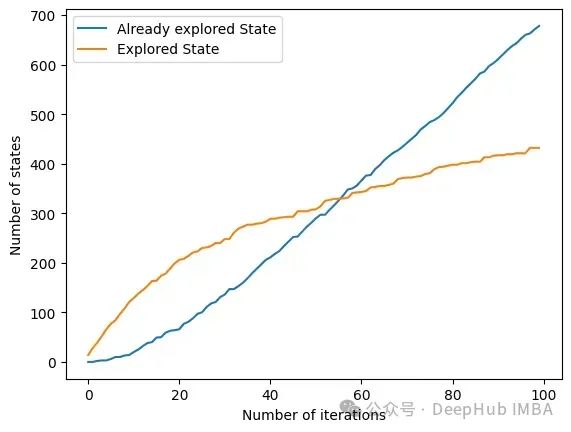
由于设置了停止条件,算法的时间复杂度呈指数级降低。即使特征的数量很大,收敛性也会很快被发现。下面的图表示一定大小的集合被访问的次数。
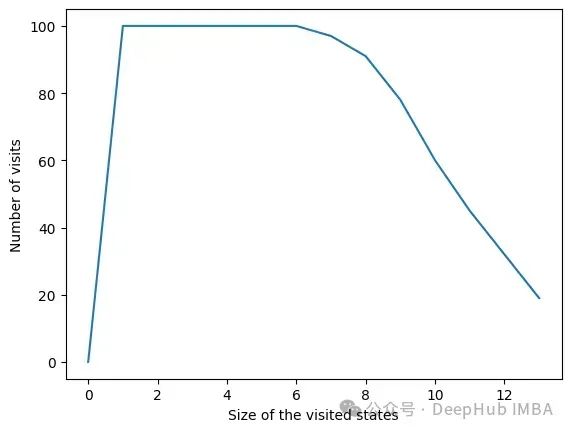
在所有迭代中,算法访问包含6个或更少变量的状态。在6个变量之外,我们可以看到达到的状态数量正在减少。这是一个很好的行为,因为用小的特征集训练模型比用大的特征集训练模型要快。
总结
我们可以看到RL方法对于最大化模型的度量是非常有效的。它总是很快地收敛到一个有趣的特性子集。该方法在使用FSRLearning库的ML项目中非常容易和快速地实现。
-
反向强化学习的思路2019-04-03 2484
-
深度强化学习实战2021-01-10 2952
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28849
-
斯坦福提出基于目标的策略强化学习方法——SOORL2018-06-06 6189
-
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?2018-07-15 18789
-
如何使用深度强化学习进行机械臂视觉抓取控制的优化方法概述2018-12-19 4099
-
对NAS任务中强化学习的效率进行深入思考2019-01-28 6150
-
深度强化学习到底是什么?它的工作原理是怎么样的2020-06-13 7485
-
强化学习在智能对话上的应用介绍2020-12-10 1805
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 1416
-
当机器人遇见强化学习,会碰出怎样的火花?2021-04-13 3337
-
基于强化学习的壮语词标注方法2021-05-14 1058
-
使用Matlab进行强化学习电子版资源下载2021-07-16 1264
-
如何使用 PyTorch 进行强化学习2024-11-05 1925
-
自动驾驶中常提的离线强化学习是什么?2026-02-07 494
全部0条评论

快来发表一下你的评论吧 !
