

芯来科技与华东师范大学SOLE实验室合作推动LLVM/CLANG编译器优化
描述
随着RISC-V这一革命性的开源指令集架构在全球范围内的迅速普及,它为半导体行业带来了前所未有的机遇与挑战。在此大背景下,芯来科技和华东师范大学SOLE实验室携手合作,致力于在RISC-V处理器上进行深入的LLVM/CLANG编译器优化以及程序性能优化和调优。
我们不仅优化了LLVM编译器的多个关键环节,提升了代码生成效率和执行性能,还针对视频编解码、性能测试等应用场景进行了深入分析和优化,提高了相关软件的执行效率。
此次合作在RISC-V处理器上实现了一定程度的性能提升,同时,我们也希望能够为RISC-V性能优化领域的同仁们提供一些有益的借鉴和参考。我们相信,通过持续的技术创新和开放的合作精神,我们可以共同推动这一领域的发展和进步。下面是我们本次合作的主要成果。
一、MCP Pass冗余指令的删除优化
在LLVM-17.x版本当中,生成的RISC-V端代码会出现冗余数据搬运指令无法删除的问题,详情如下图所示。在两个红框显示的vmv指令当中,v0以及v8寄存器的值都没有得到改变,但LLVM最终生成的RISC-V代码依然会对这两个值进行重复搬运。

冗余vmv指令无法在LLVM/Clang中消除的示例
经过核查,出现该问题的根因是LLVM的Machine Copy Propagation Pass对寄存器使用的Def-Use记录不当所导致。经过对该问题进行修复后,该工作已经提交到了LLVM的上游仓库。该优化亦应用到了LLVM多个后端的代码生成当中,如RISC-V、X86以及AMDGPU的后端代码生成当中。
二、RVV的低精度数据向量化取余以及右移代码生成优化
C语言会采用Promotion Rule来保证混合精度或者是低精度数据运算结果的准确性,当遇到低精度数据如int8或者int16类型的数据进行逐元素(Element-Wise)取余或者是算术右移操作时,会先将相应的数据提升至32位,再将结果进行截断至原来的精度以保证运算结果的正确性。然而,取决于RVV 1.0指令集动态调整元素大小的特性,该过程需要一系列的vsetvli类指令进行操作。
考虑到相关的计算溢出结果以及指令的行为在RVV 1.0指令集中已经得到明确定义,在LLVM编译器生成相关代码时可以进行下图所示的优化:
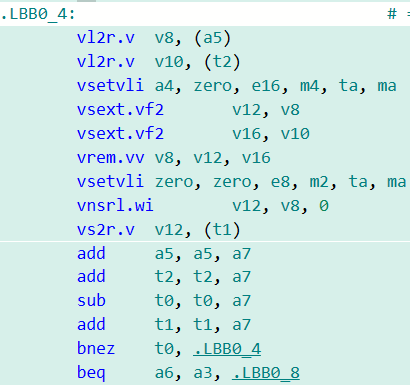
Element-wise vrem.vv优化前

Element-wise vrem.vv优化后

Element-wise vsra.vv优化前

Element-wise vsra.vv优化后 这些优化不仅可以从指令的语义上保证计算结果的正确性,而且能有效地避免频繁复杂的数据精度提升与下降操作,这些优化工作亦被提交到了LLVM的上游仓库当中。
三、FFMPEG X264编解码热点采集分析
RISC-V Vector 1.0向量化指令集可以被用于视频编解码应用的加速处理当中,而FFMPEG作为最常见的音视频处理软件之一,在其关键核心且可向量化函数当中,大部分亦都利用RVV 1.0汇编或者Intrinsic进行了重写。尽管如此,如何针对其常用的x264编解码功能进行编译优化机会的探索,依然是提高其执行效率的一个重要手段。
我们采集对比了GCC 14.1与LLVM/Clang 17.2编译出来的FFMPEG,在进行x264视频编解码时的热点函数,详情下图所示。根据结果可以看到,热点函数都聚集在了libx264的x264_piexel_sad类函数之上。
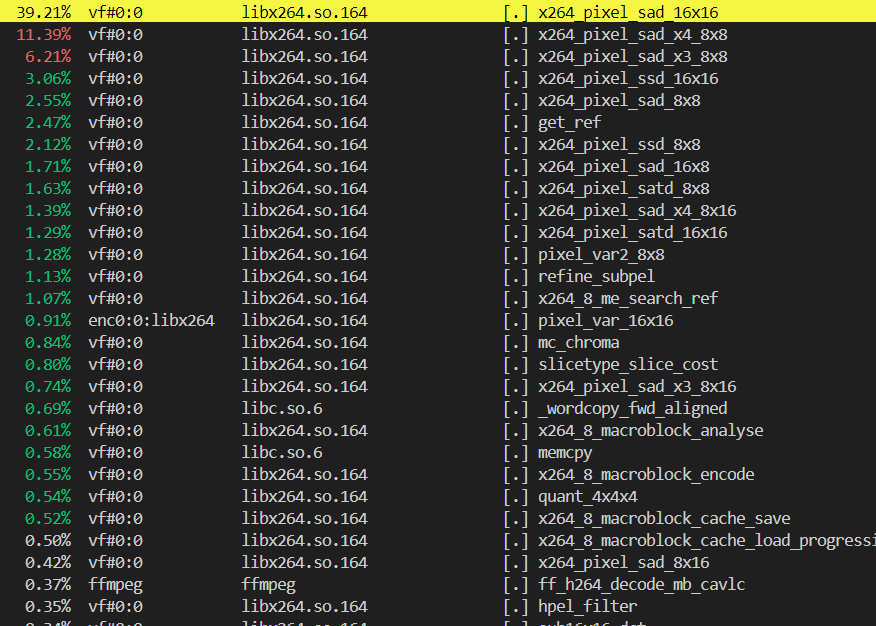
FFMPEG X264编码热点分析(GCC)

FFMPEG X264编码热点分析(LLVM/Clang)
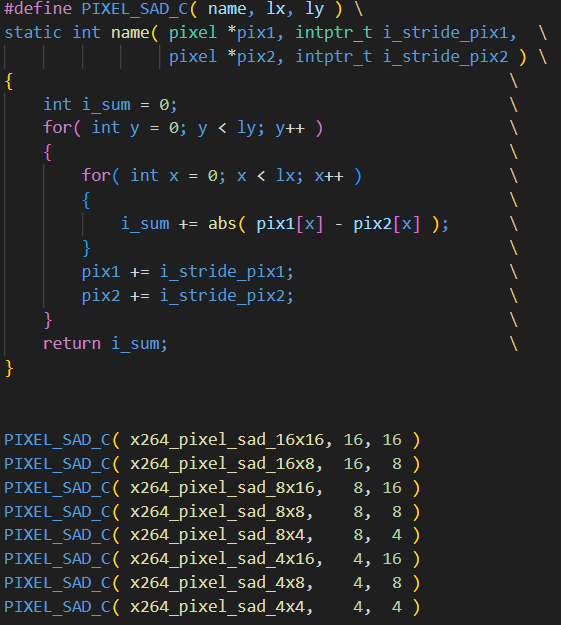
x264_pixel_sad类函数声明
而这类x264_piexel_sad函数本质上就是一系列的abs函数的处理,这类函数的定义可以如上图所示。
以16x16的迭代大小为例子,下面的图分别对比了LLVM/Clang以及GCC在该函数上生成代码的细致区别(开启-O3)。
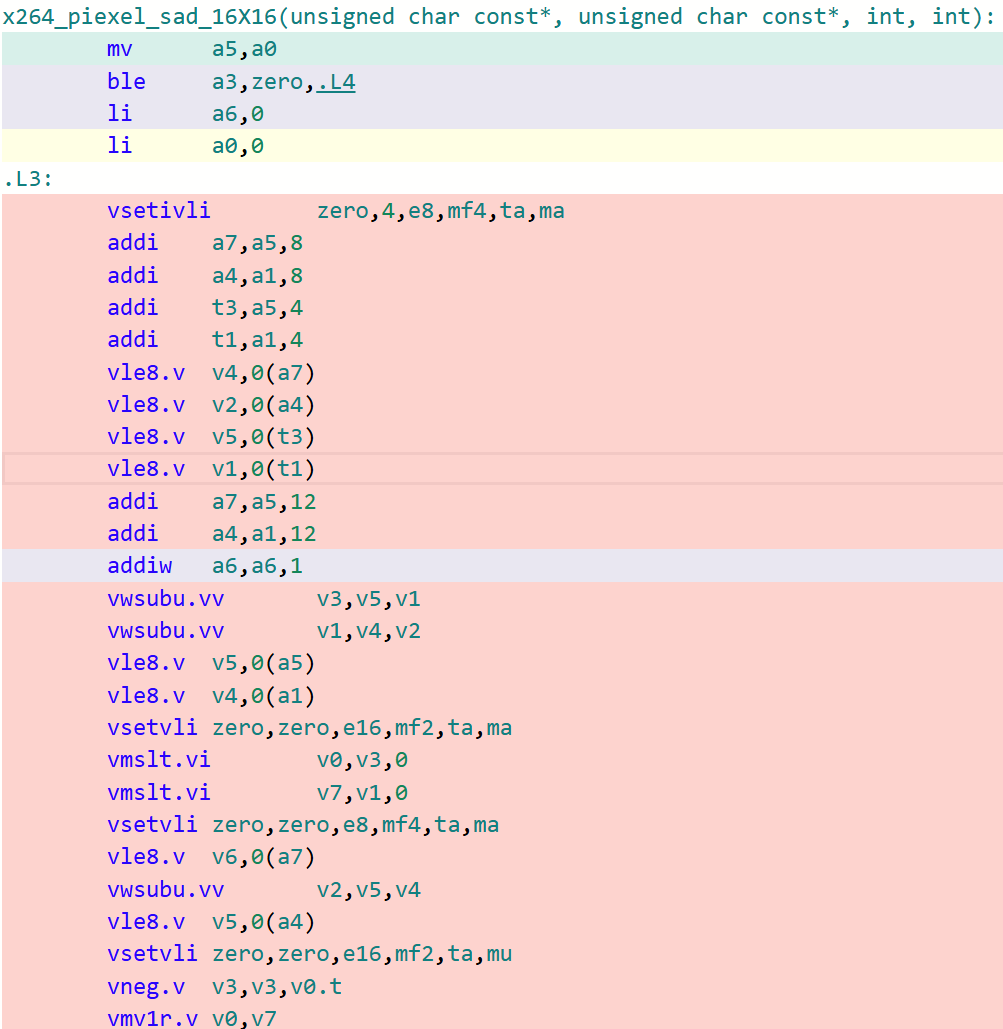
x264_piexel_sad_16x16函数 GCC生成代码
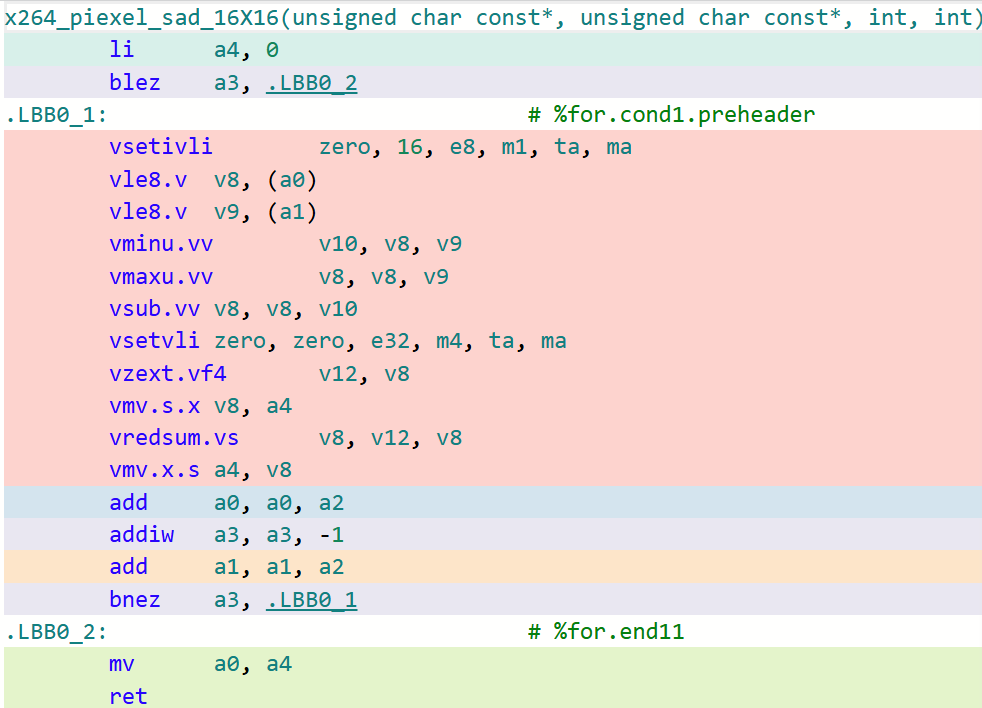
x264_piexel_sad_16x16函数 LLVM/Clang生成代码
可以看到,在默认O3的选项下,GCC生成的代码对于这类核心函数的处理效率远不如LLVM/Clang。这是因为GCC默认采用LMUL=1(向量化分组大小为1)的大小进行代码生成,即其生成的RVV代码采用的LMUL大小不能高于1。在探索到这些根因后,可以采用GCC最新14.1版本中所提供的-mrvv-max-lmul=dynamic选项对这类生成的代码进行改进,采用该选项优化后的代码如下图所示:

LMUL设置为dyanamic时GCC生成的代码
此时,GCC在此处生成的代码执行效率已经能够和LLVM/Clang相匹配。因此,我们在采用GCC编译的FFMPEG进行x264视频编解码时,为了更高的核心代码执行效率,建议将GCC动态调整LMUL大小的编译选项进行开启。
四、CoreMark的Jump Threading优化
Coremark是评估CPU性能常见的一个测试程序,但是采用LLVM/Clang编译器编译优化coremark程序跑分效果远远比不上GCC,因此我们分析了Coremark程序的热点函数,发现可以通过Jump Threading技术来进行优化,Jump Threading是一种专门用于控制流程图(CFG)优化的一种编译优化技术,它会在执行分支前遇到确定变量的值时,直接执行确认值在分支以后的路径,即采用无条件的跳转替代条件跳转,详情如下图所示:
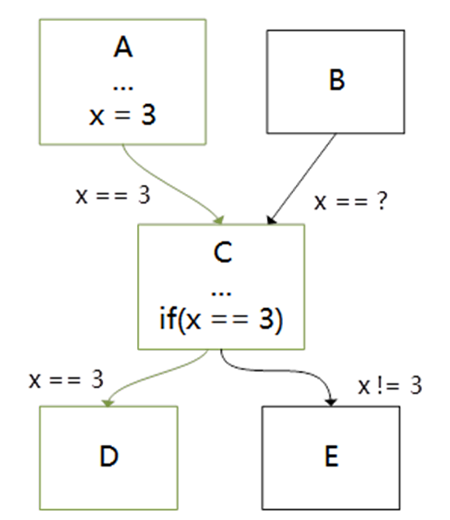
优化前的CFG
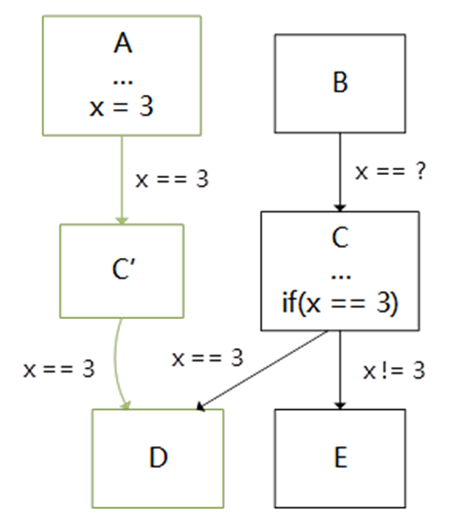
优化后的CFG
该优化会对CFG路径中变量的值进行扫描遍历,并寻找到可以利用无条件跳转替换条件判断的路径,并进行基本块的克隆与路径的替换。考虑到该扫描过程较为耗时,LLVM中默认的Jump Threading优化采取较为轻量级的扫描方式。通过在芯来编译工具链的LLVM/Clang中引入一系列更为激烈的Jump Threading扫描优化手段后,将采用Clang编译的CoreMark并运行在芯来N300模拟器上的跑分提升约18%。
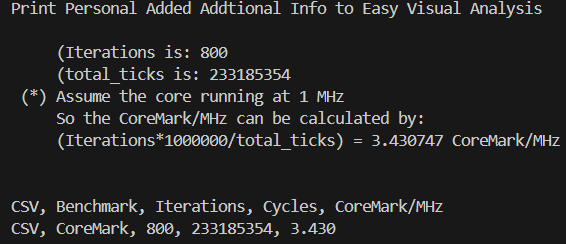
LLVM/Clang调优前CoreMark跑分
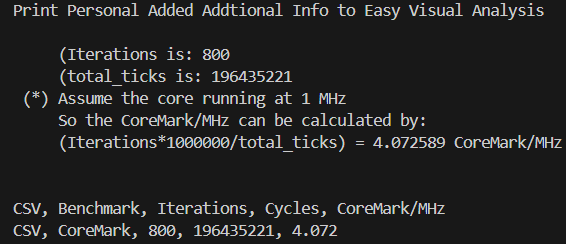
引入额外Jump Threading优化后的CoreMark跑分
五、SPEC CPU 2006的编译选项调优
SPEC CPU 2006 INT是业界常用的CPU性能基准测试套件,为了提高SPEC CPU 2006 INT的测试跑分,常常需要找到更适合的编译选项来对编译器进行调优,以获得更好的SPEC分数。然而,考虑到目前大部分的最佳跑分配置都是利用业界专用编译器,如Intel的ICC编译器以及AMD的AOCC编译器等进行跑分。对于RISC-V指令集架构平台,这类专用的编译器并不能够适用。同时,假如采用Ref测试集来进行编译选项的调优,则需要消耗大量的测试时间。
为了加速调优,我们采用了一种更为灵活且快捷的基于Qemu仿真器的动态指令计数对比的编译选项调优方法。下图展示了采用GCC-13对SPEC CPU2006 INT的TEST测试集进行选项调优的结果。
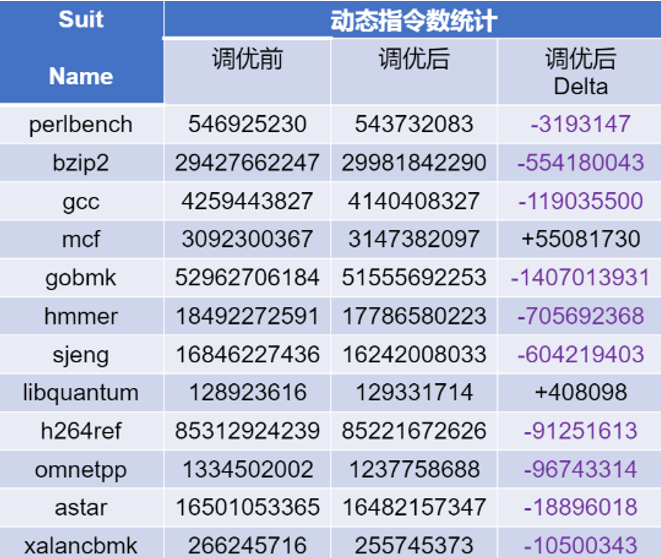
SPEC CPU 2006 INT动态指令数目调优结果
经过精心调优的编译选项在SPEC CPU2006 INT的多项测试程序中显著降低了动态指令的数量。进一步地,我们在FPGA开发板上进行了实际的性能对比测试。结果表明,这种基于动态指令计数的调优方法不仅有效,而且在资源受限的开发板或仿真CPU主频受限的FPGA环境中,为编译选项的优化提供了一种切实可行的策略。这一发现为在类似条件下的性能提升开辟了新的探索路径。
此次合作是双方在技术研究和应用开发领域共同努力的成果,它体现了我们团队在探索和实践过程中的专注与努力。同时,我们对于能够参与到产学研合作这一推动技术革新的重要力量中来而深感荣幸。相信通过这样的合作模式,我们能够与业界同仁共同学习、相互启发,为整个技术社区的发展贡献绵薄之力。
审核编辑:彭菁
-
华为联合华东师范大学发布Wi-Fi 7高品质万兆校园网联合示范点2026-05-30 502
-
维智科技助力华东师范大学打造空间人工智能新高地2026-03-31 567
-
华东师范大学开源鸿蒙技术俱乐部成立仪式暨操作系统技术论坛圆满举办2026-01-21 813
-
华东师范大学开源鸿蒙技术俱乐部成立仪式暨操作系统技术论坛——邀您共同见证!2026-01-17 1296
-
华东师范大学教授:生活中的传感器2024-02-20 1234
-
华大半导体与华东师范大学共建“集成电路工程技术联合实验室”2023-09-21 2192
-
华东师范大学:激光定制3D微流控芯片连续制备不同尺寸半导体聚合物纳米颗粒用于荧光传感2023-07-06 2663
-
科伦特为华东师范大学希平双语学校量身打造LED显示大屏2022-09-01 1250
-
全国大学生GIS应用技能大赛(开发试题参考)精选资料分享2021-07-12 2018
-
由华为与华东师范大学联合举办的昇腾核心开发者协会揭牌2021-01-07 4696
-
STM32中断优先级与相关使用概念 华东师范大学2014-03-24 2142
-
2007年全国大学生电子设计竞赛华东师范大学竞赛组织工作总结2010-03-26 838
-
物理实验分析与研究课程(华东师范 宦强)2010-03-24 580
-
实验室规程及仪器管理(华东师范大学)2010-03-17 1147
全部0条评论

快来发表一下你的评论吧 !
