

GRU模型实战训练 智能决策更精准
描述
上一期文章带大家认识了一个名为GRU的新朋友, GRU本身自带处理时序数据的属性,特别擅长对于时间序列的识别和检测(例如音频、传感器信号等)。GRU其实是RNN模型的一个衍生形式,巧妙地设计了两个门控单元:reset门和更新门。reset门负责针对历史遗留的状态进行重置,丢弃掉无用信息;更新门负责对历史状态进行更新,将新的输入与历史数据集进行整合。通过模型训练,让模型能够自动调整这两个门控单元的状态,以期达到历史数据与最新数据和谐共存的目的。
理论知识掌握了,下面就来看看如何训练一个GRU模型吧。
训练平台选用Keras,请提前自行安装Keras开发工具。直接上代码,首先是数据导入部分,我们直接使用mnist手写字体数据集:
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import load_model
# 准备数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
模型构建与训练:
# 构建GRU模型 model = Sequential() model.add(GRU(128, input_shape=(28, 28), stateful=False, unroll=False)) model.add(Dense(10, activation='softmax')) # 编译模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 模型训练 model.fit(x_train, y_train, batch_size=128, epochs=10, validation_data=(x_test, y_test))
这里,眼尖的伙伴应该是注意到了,GRU模型构建的时候,有两个参数,分别是stateful以及unroll,这两个参数是什么意思呢?
GRU层的stateful和unroll是两个重要的参数,它们对GRU模型的行为和性能有着重要影响:
stateful参数:默认情况下,stateful参数为False。当stateful设置为True时,表示在处理连续的数据时,GRU层的状态会被保留并传递到下一个时间步,而不是每个batch都重置状态。这对于处理时间序列数据时非常有用,例如在处理长序列时,可以保持模型的状态信息,而不是在每个batch之间重置。需要注意的是,在使用stateful时,您需要手动管理状态的重置。
unroll参数:默认情况下,unroll参数为False。当unroll设置为True时,表示在计算时会展开RNN的循环,这样可以提高计算性能,但会增加内存消耗。通常情况下,对于较短的序列,unroll设置为True可以提高计算速度,但对于较长的序列,可能会导致内存消耗过大。
通过合理设置stateful和unroll参数,可以根据具体的数据和模型需求来平衡模型的状态管理和计算性能。而我们这里用到的mnist数据集实际上并不是时间序列数据,而只是将其当作一个时序数据集来用。因此,每个batch之间实际上是没有显示的前后关系的,不建议使用stateful。而是每一个batch之后都要将其状态清零。即stateful=False。而unroll参数,大家就可以自行测试了。
模型评估与转换:
# 模型评估
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 保存模型
model.save("mnist_gru_model.h5")
# 加载模型并转换
converter = tf.lite.TFLiteConverter.from_keras_model(load_model("mnist_gru_model.h5"))
tflite_model = converter.convert()
# 保存tflite格式模型
with open('mnist_gru_model.tflite', 'wb') as f:
f.write(tflite_model)
便写好程序后,运行等待训练完毕,可以看到经过10个epoch之后,模型即达到了98.57%的测试精度:

来看看最终的模型样子,参数stateful=False,unroll=True:
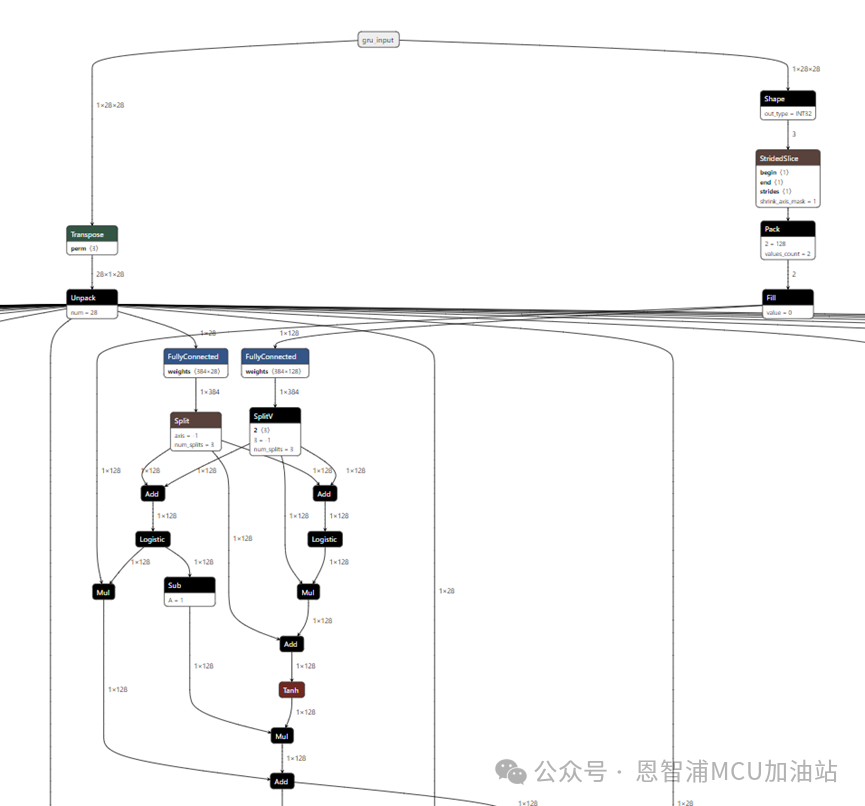
这里,我们就会发现,模型的输入好像被拆分成了很多份,这是因为我们指定了输入是28*28。第一个28表示有28个时间步,后面的28则表示每一个时间步的维度。这里的时间步,指代的就是历史的数据。
现在,GRU模型训练就全部介绍完毕了,对于机器学习和深度学习感兴趣的伙伴们,不妨亲自动手尝试一下,搭建并训练一个属于自己的GRU模型吧!
希望每一位探索者都能在机器学习的道路上不断前行,收获满满的知识和成果!
-
AI大模型微调企业项目实战课2026-04-16 930
-
九天菜菜大模型agent智能体开发实战2026一月班2026-04-15 417
-
AI模型训练与部署实战 | 线下免费培训2026-04-07 819
-
如何训练自己的AI模型——RT-Thread×富瀚微FH8626V300L模型训练部署教程 | 技术集结2026-02-09 832
-
不仅管设备,还能管数据!智能系统让运维决策更精准2025-09-05 961
-
深入GRU:解锁模型测试新维度2024-06-27 2265
-
GRU是什么?GRU模型如何让你的神经网络更聪明 掌握时间 掌握未来2024-06-13 3925
-
《初级电工技能实战训练》pdf2022-02-08 1267
-
有数据中台,企业级数据决策效率会更高吗?2021-11-04 1166
-
超大Transformer语言模型的分布式训练框架2021-10-11 5001
-
人工智能基本概念机器学习算法2021-09-06 2786
-
什么是决策树模型,决策树模型的绘制方法2021-02-18 14254
-
Pytorch模型训练实用PDF教程【中文】2018-12-21 5202
全部0条评论

快来发表一下你的评论吧 !
