

商汤小浣熊荣获中国信通院代码大模型能力评估“三好生”
描述
“ 通用能力突出,专用场景全面,应用成熟度优秀 ”。
近日,商汤小浣熊代码大模型在中国信通院“可信AI代码大模型评估”中,荣获4+级最高评级,成为国内首批通过该项评估的企业之一。
商汤小浣熊在代码通用能力、专用场景和应用成熟度等多个评估维度中表现优秀。

依据中国信通院《智能化软件工程技术和应用要求 第1部分:代码大模型》,此次评估聚焦大模型的通用能力、专用场景能力和应用成熟度三大部分,包括16个能力项、100多个能力要求,从输入多样性、任务多样性、语言完备度、结果可接收性、结果准确度等维度,考核代码大模型的全栈技术能力。
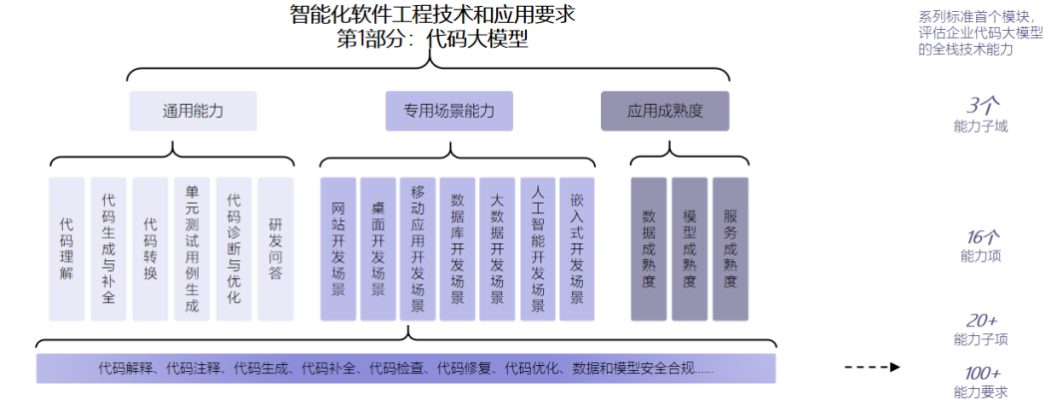
图片来源:中国信通院
商汤小浣熊作为首批参评企业获得4+级评级,是本次评分最高的代码大模型之一。中国信通院测评结果显示:
通用能力方面,小浣熊在代码解释、代码转换等方面表现突出;
专用场景方面,小浣熊支持网站开发、桌面应用开发、移动应用开发、数据库开发等多个场景的开发能力;
应用成熟度方面,小浣熊在数据分类分级、模型性能、模型服务可维护性、风险可控性等方面均表现优秀。
「小浣熊家族」是基于商汤“日日新SenseNova”大模型体系打造的 AI Native 生产力系列工具,覆盖软件开发、数据分析、编程教育等多个场景,旨在通过先进的人工智能技术优化和提升工作效率。现已推出代码小浣熊和办公小浣熊两位产品成员。
代码小浣熊是基于大模型的软件智能研发助手,覆盖软件需求分析、架构设计、代码编写、软件测试等环节,满足用户代码编写、编程学习等各类需求,现已支持Python、Java、JavaScript、C++、Go、SQL等90+主流编程语言和VS Code、JetBrains全家桶、Android Studio等主流IDE。
办公小浣熊是基于大模型的大模型原生数据分析产品,可以通过用户的自然语言输入,自动将数据转化为有意义的分析和可视化结果。
小浣熊家族背后的「小浣熊代码大模型」,在权威测试集HumanEval Coding测试中一次通过率达到78.1%,在数据分析场景下的数据测试集(1000+题目)中以85.71%的正确率超过GPT-4。
自上线以来,小浣熊代码大模型累计为10万+个人用户提供服务,单日代码生成数量达到10亿+Tokens,总体平均代码采纳率超过30%,用户编码能效提升达到20%~78%。
目前,商汤小浣熊代码大模型已经被包括金融、新能源汽车等行业在内的200+企业客户使用,凭借突出的数理能力覆盖多元落地场景。
例如,在与金山办公的合作中,小浣熊代码大模型助力WPS 365打造更高效释放场景能力的智能办公平台,为用户多元、碎片化的办公需求提供新质生产力。
此外,基于小浣熊代码大模型,商汤科技与海通证券合作打造智能研发助手,辅助金融企业研发人员进行代码编程,为开发者提供代码智能补全与对话问答服务,可辅助生产约20%代码,降低开发技术门槛,有效提高开发效率。
未来,商汤小浣熊将持续降低大模型技术的开发和应用门槛,赋能更多场景创新。
-
中国信通院主办的云计算产业盛会在北京拉开帷幕2020-10-29 2387
-
易华录取中国信通院数据集成工具基础能力专项评测证书2022-06-29 2410
-
首批!轻流通过中国信通院无代码开发平台通用能力要求评测2022-08-23 1827
-
华为云应用运维管理平台获评中国信通院可观测性评估先进级2023-07-01 1373
-
中国信息通信研究院院长余晓晖一行到访上海商汤科技2023-07-08 2174
-
国内首批!商汤如影获中国信通院“可信虚拟人”L3卓越级证书2023-09-15 1807
-
新华社研究院:商汤“商量”获评中国大模型市场未来领袖2023-11-29 1272
-
代码小浣熊Raccoon上线,助你丝滑写代码,商汤大语言模型实力加持2023-12-07 1935
-
商汤日日新大模型中标上海电信订单2024-07-29 1434
-
权威认证 “图扑软件数字孪生低代码平台”获中国信通院检测认证2024-11-05 1137
-
商汤日日新SenseNova融合模态大模型 国内首家获得最高评级的大模型2025-06-11 1672
-
商汤大装置万象大模型开发平台获得中国信通院最高评级2025-07-01 1233
-
曙光云荣获中国信通院2025数字政府建设突出贡献单位奖2026-01-13 841
-
商汤科技办公小浣熊接入SenseNova U1系列模型2026-05-08 334
-
商汤小浣熊与Datawhale联合发起国内首届OPC能力挑战赛2026-05-27 222
全部0条评论

快来发表一下你的评论吧 !
