

 闭卷开考全国一卷,AI大模型高考数学全部不及格?!
闭卷开考全国一卷,AI大模型高考数学全部不及格?!
描述
电子发烧友网报道(文/周凯扬)当下的大模型除了卷商业化变现外,又开辟出了一个新的“赛博斗蛐蛐”赛道,以各种评测标准来测试大模型在语言、数学、推理和代码方面的综合成绩。作为国内最权威的考试之一,高考则是最能代表学生综合能力的一次考验,而大模型这个特殊身份的考生,如果参加高考究竟会获得怎样的成绩,也激起了网友的好奇之心。
上海人工智能实验室的大模型评测体系OpenCompass在近日举办了这么一次测试,让6大开源模型和GPT-4o参加一次特殊的“高考”,然而这些大模型获得的成绩却让不少人大跌眼镜。
闭卷开考全国一卷
在这次大模型参加高考中,OpenCompass的首轮测试采用了全国新课标I卷的语数外试卷作为题源,该卷的覆盖省份包括江苏、浙江、河北、福建、山东、湖北、湖南、广东等。为了方便测试,除了省去其他非统一学科外,其中英语省去了30分的听力,所以其单科总分变为了120分。
为了做到“闭卷”,这些受测的模型中,包括Mistral的开源对话模型Mixtral 8x22B、零一万物的Yi-1.5-34B大模型、智谱AI的GLM-4-9B、上海人工智能实验室推出的InternLM2-20B-WQX大语言模型以及阿里巴巴的Qwen2-57B和Qwen2-72B。
以上开源模型的开源时间均早于本届高考,发布时间最新的是InternLM专门在高考前夕推出的文曲星系列大模型,InternLM2-WQX。即便如此,其发布于6月4日的时间也满足了闭卷考试的前提。唯一的例外是商用闭源模型GPT-4o,但其成绩也仅仅是作为评测参考。
在阅卷评分上,OpenCompass请到了多位有阅卷经验的高中教师对主观题答案进行评分,每份考卷都由至少3位教师评阅取平均分,甚至对分差较大的题目进行了二次审核。另外值得关注的是,为了保证阅卷老师在主客观题上产生对大模型“先入为主”的观念,OpenCompass在阅卷之后才告知阅卷老师答案由大模型生成,并对成绩做一个整体分析。
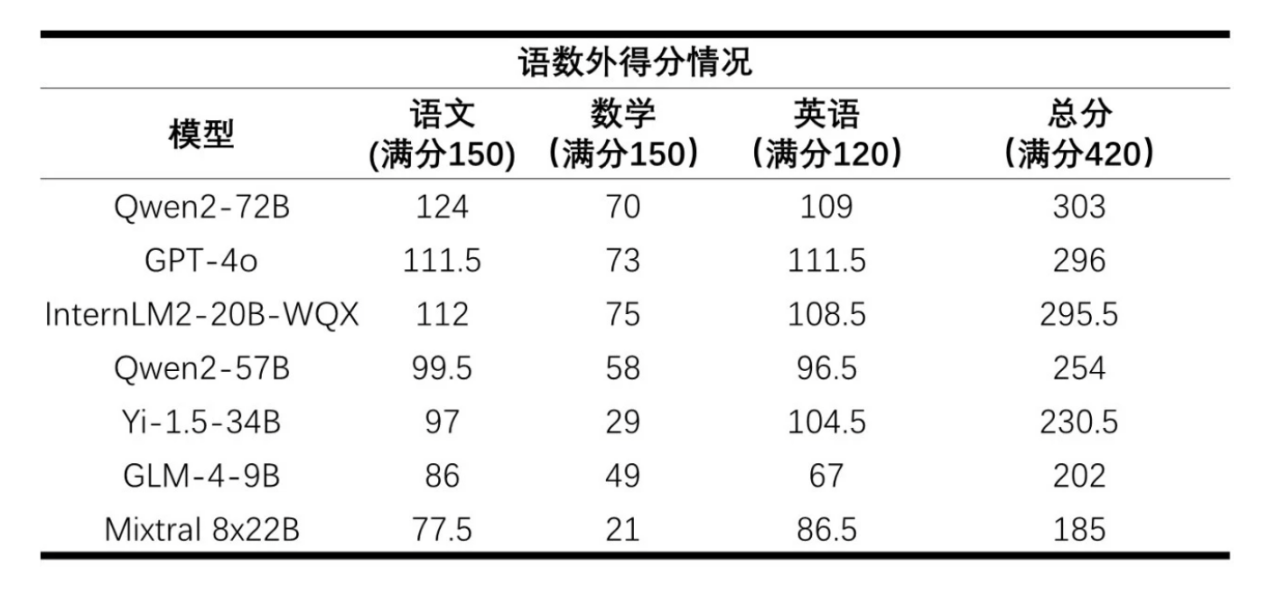
AI大模型高考语数外得分 / 上海人工智能实验室
从总分来看,阿里巴巴的通义千问大模型Qwen2-72B排名第一,其次是成绩相近的GPT-4o和InternLM2-20B-WQX。然而单从数学这一门科目来看,所有的大模型都没有及格,Mixtral 8x22B甚至只获得了21分的成绩。
语言能力依然是LLM的强项,但“应试”能力仍有提升空间
在这次“高考测试”中,不少大模型都在语文和英语上获得了不错的成绩,尤其是在英语试卷上,GPT-4o更是在英语上获得了111.5的高分。在语文上,还是国内的模型更具优势,尤其是在文言文阅读、古诗文阅读和名句默写上。
有趣的一点是,在语文作文上,各大模型都没有拉开较大差距。但据上海人工智能实验室的观察,大模型的作文都倾向于将“首先”“其次”和“然后”这样表达先后顺序的词放在段首。此外,目前多数大模型都没有对一些“应试”类题型做出优化,比如在语文考试中,阅读理解中的一些本体、喻体、暗喻等概念,大模型尚不能完全理解,所以在语言文字运用题型上,比如补写句子等题目就普遍得分不高。
而在英语考试中,尽管各大模型整体表现良好,但部分模型并不适应完形填空、七选五这样非传统问答式的题型,会出现答案错位的情况,因此得分率依然处于一个较低的水平。
在英语续写和作文的撰写上,大模型都存在忽略题目要求的现象,普遍出现了超出字数限制而扣分的情况,且单段文字过长。在故事续写这样的题型中,部分大模型也会展开不合实际的联想,比如InternLM2-20B-WQX的作答中,就出现了出租车内司机拨通银行内线电话的离谱情节。
数学不及格,主观问答题成为最大短板
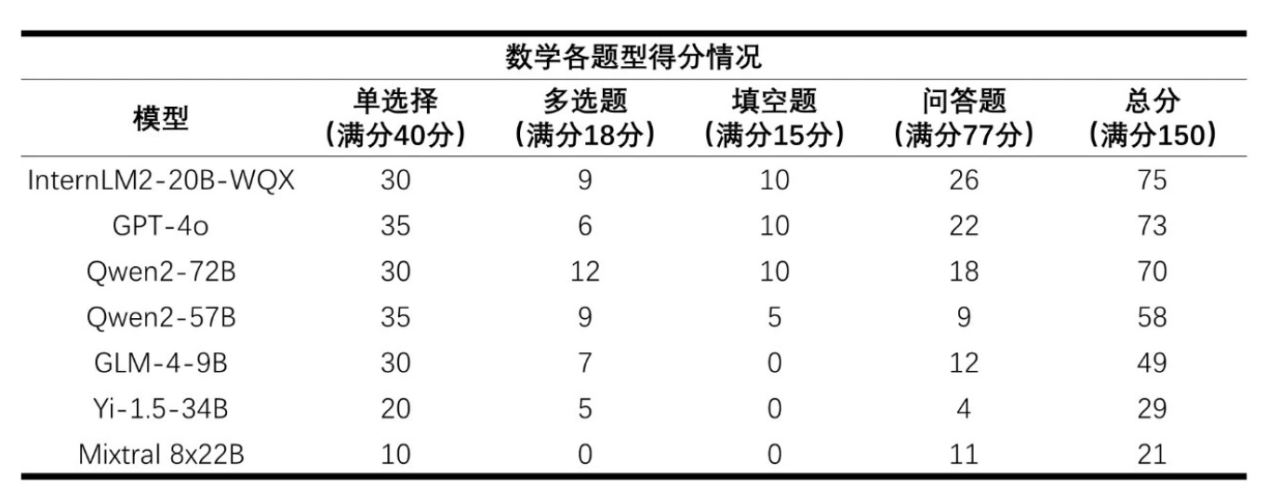
AI大模型数学各题型得分 / 上海人工智能实验室
相较语言能力测试成绩,AI大模型在数学能力测试上获得的成绩就显得不尽如人意了。最高分为InternLM2-20B-WQX取得的75分,可以说在数学这门学科上,几乎所有的大模型都败下阵来。全国新课标I卷的数学试卷中存在两道带图题,对于不支持多模态输入的大模型而言,只能选择输入题干文字从而将图片舍弃,这也是失分严重的原因之一。

Qwen2-72B的带图题答案 / 上海人工智能实验室
以上图中的带图题答案为例,大模型仅仅给出了一个解题框架,并没有给出具体数值的答案。GPT-4o和InternLM2-20B-WQX等大模型虽然给出了具体答案和解题过程,但最终得到的是一个错误的答案。
之所以InternLM2-20B-WQX能在数学考试上获得相对较高的成绩,也归功于其团队在数学大模型上的积累。今年年初InternLM发布了数学模型书生·浦语数学(InternLM2-Math)。书生·浦语数学也是首个同时支持形式化数学语言以及解题过程评价的开源模型,如此一来不仅可以用于数学计算解答,也可以用于数学基础研究和教学。
尽管如此,在数学考试的问答主观题上,大模型依然成绩惨淡。这是因为大模型的回答多数比较凌乱,也出现了不少常见的错误解答但答案正确的现象。所以在77分满分的问答题上,最高的InternLM2-20B-WQX也只仅仅得了26分。
AI大模型是不合格的考生吗?
根据阅卷老师的点评来看,AI大模型依然还是一个比较“死板”的考生,尤其是在主观题上。以语文的主观题为例,很多大模型在第一步审题就失败了,所以答非所问。在英语题目上,大模型的实力还是毋庸置疑的,但还是会在题型和作文中出现纰漏。
至于数学依然是所有大模型的弱项,大模型更像是记住了公式但不会运用的学生,在大部分题目上更倾向于穷举而非推理。至于带图的立体几何解答题,大模型更是缺乏空间概念,导致出现离谱的解答过程和答案。由此看来,大模型的“应试”能力依然有所欠缺,但在飞速迭代下,相信未来这种障碍会越来越少。
-
AI撰写高考作文,好比让数学家制作预制菜2023-06-09 3553
-
LabVIEW_学习札记_-_第一卷_上2013-10-18 4439
-
2003年高考数学模拟试卷2009-01-09 851
-
C算法第一卷 (pdf版)2009-10-24 832
-
C语言教程之统计不及格的人数问题2016-04-25 630
-
Cyclone 器件数据手册(第一卷)2016-11-10 876
-
“高考机器人”今年高考目标数学110分!然而3个月前曾败给文科生2017-06-07 1362
-
机器人考完高考数学!10分钟得100分,2019年或参加高考语文2017-06-08 2573
-
高考AI智能机器人比拼:10分钟完成数学答卷2017-06-09 2410
-
准星数学高考机器人介绍2017-09-20 2026
-
谷歌人工智能DeepMind,参加高中数学考试不及格2019-07-05 846
-
2021高考全部结束,多地高考查分时间公布|电子发烧友发来祝福2021-06-10 1250
-
AI应用加速 海南高考首次采用AI智能巡考2024-06-04 1633
-
学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”2025-06-09 1581
全部0条评论

快来发表一下你的评论吧 !
