

ARM NEON技术在车位识别算法中的应用
ARM
描述
摘要:为了在车位检测系统中不使用DSP的情况下,达到实时处理和节约成本的目的,在嵌入式Linux系统中使用了CORTEX-A系列的NEON协处理器技术来优化一种车位图像检测算法的代码。在CORTEX-A8平台上使用该图像处理算法进行了大量的处理测试,图像算法处理速度得到很大提升。最后在多个平台下使用该图像处理算法进行测试对比,使用了NEON技术后其算法处理速度提升明显,能够满足实时要求。
0 引言
随着城市越来越多家庭拥有汽车,相应的停车场建设数目也越来越多,停车场管理系统也越来越重要。
而国内城市车多人多,空间拥挤给停车厂管理带来诸多不便。车位检测系统设计成嵌入式终端是一个好的选择。图像检测算法的复杂度给实时检测带来难题,一般的图像处理都是基于DSP完成,这带来了成本的上升。
ARM 公司CORTEX-A 系列处理器的出现,极大地缓解了这个难题。
ARM 平台能够很好地支持Linux 系统,Linux 系统具有强大的网络通讯功能,也给程序移植等带来便利。本文的检测算法在ARM平台基于NEON技术进行了优化,在保证检测精度的同时,处理速度提升明显,与使用DSP相比,大大节约了成本,为停车场管理系统的研究提供新的方向。
1 ARM NEON技术介绍
ARM 的NEON 通用SIMD 引擎可有效处理当前和将来的多媒体格式,从而改善用户体验。NEON 技术是通过清晰方式构建的,并可无缝用于其本身的独立流水线和寄存器文件。NEON 技术是ARM Cortex-A系列处理器的128 位SIMD(单指令多数据)体系结构扩展,旨在为多媒体应用提供更加强大的加速功能,从而明显改善程序性能。它具有32 个寄存器,64 位宽(是16 个寄存器,128 位宽的双倍视图)NEON 指令特点如下:
(1)寄存器被视为同一数据类型的元素的矢量;
(2)数据类型可为:有符号/无符号的8 位、16 位、32 位、64 位单精度浮点;
(3)指令在所有通道中执行同一操作。
NEON 寄存器可在多个通道内进行并行运算,如图1所示。
NEON 的指令都是以v 字母开头的,例如:vadd.i16q0,q1,q2,这就是一个NEON 的指令了,很明显的特点就是v 开头,i 主要用来表明是一个整型(int),16 表示一个16 位的型,q0,q1,q2 都是128 位的寄存器(q 打头的寄存器都是128 位的)。这个指令就是让q1,q2 中装载8 个16位的数据,然后执行加法操作,最后放到q0中去。这么一个指令就完成了8次加法运算,这也就是性能的提升,对于其他运算也是如此。
2 系统设计和算法介绍
本系统基于CORTEX-A8平台实现,车位检测系统架构如图2所示。
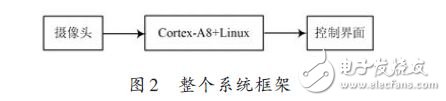
采集通过模拟摄像头,由TVP5150解码后输出8位Y∶Cb∶Cr=4∶2∶2的数据传送的A8平台,TVP5150驱动基于VIDEO FOR LINUX2(V4L2)开发,因此视频采集程序调用V4L2相关API函数即可完成。然后调用相关图像处理程序,提取多个图像特征,与背景图像对比,进行有车无车检测,然后TCP/IP网络 将图像和有车位车情况发送到上位机。
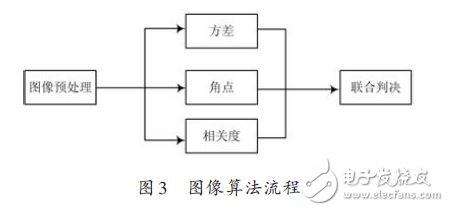
车位检测算法流程如图3所示。
本系统目前在一处地下停车场进行测试验证,如图4在停车中采集到的背景和待测图像,通过对100幅采集到800×600 分辨率的现场图像,在CORTEX-A8 平台上进行测试,平均检测时间为538 ms,该算法在地下停车场中准确率97%.表1 中给出了处理一幅待测图像CORTEX-A8 和ARM11 平台优化前平均时间的测试对比结果(均使用GCC交叉编译)。


3 图像处理算法在CORTEX-A8 平台上的优化
本系统是Cortex-A8和Linux系统上搭建,Linux下使用的编译器为GCC.本文中使用普通C 语言优化和NEON编程优化对图像相关函数进行了优化,并进行了测试对比,下面给出方差函数variance代码进行优化前后的对比说明,如图5优化前的代码。

3.1 C语言级别优化
对于一般C语言级别的优化,对于图像这类矩阵数据而言,主要针对循环优化。以第一个循环为例,如图6对于C语言级别循环优化后的代码如图6所示。

由优化后的结果可见,通过对循环展开,有效的减少了循环跳转次数,跳转为原来的1 4 。但是也可以发现,加法运算次数,几乎和原来相同并没有减少。对于其他for循环和其他函数进行优化后,测试时间对比如表2所示。

由表中数据可见,使用普通C 语言界别优化,并没有明显提升,原因是在Linux系统上使用GCC编译器进行编译的,在选择-O2 级别优化的时候,已经对循环进行了优化,所以运行速度没有明显提升。
3.2 使用NEON技术的优化
GCC 编译器从4.3 版本开始,很好地提供了对ARM NEON 技术的支持。例如GCC 中的函数:
uint32x2_t vadd_u32(uint32x2_t,uint32x2_t),对应汇语言:vadd.i32 d0,d0,d0.uint32x2_t代表这个数据类型是2 个32 位无符号整型。在使用GCC 编译器中的NEON 技术时,需要包含头文件《arm_neon.h》.NEON增强指令集是在Cortex-A系列发布后才具有的功能,因此ARM11 无法使用NEON 技术。对方差函数variance第一个for循环优化后的代码对比如图7所示。

由优化后程序代码可见,循环跳转次数为原来的1 4 ,但是由于使用了NEON 相关的vld1q_u32 函数,一次可在NEON的128位寄存器中装入4个32位数值,调用vaddq_u32可对4个数据时同时进行加法运算,在一个指令周期就完成了4次加法运算,理论上加法运算次数为原来的1 4 ,大大提高了运算性能。
对于第二个for循环也可以采用类似方法优化,只是调用的函数略有不同,具体考参考GCC的技术文档,有详细的使用说明。
其他函数如预处理、角点、相关度函数的优化和此方法类似,重点针对循环和可以并行运算的代码进行优化。
表3 中给出了Cortex-A8 平台使用NEON 技术优化后与ARM11测试时间的对比。

4 结语
通过使用ARM NEON 技术,对于图像处理这类矩阵运算进行并行优化,可大大提高处理速度,进行优化后,速度较优化前提升了达2倍之多,较ARM11提升了8 倍的速度。ARM COTEX-A 系列所使用的NEON 技术,不仅使车位图像检测算法的速度有很大提升,在信号处理等多媒体处理算法中,也有广阔的应用前景。
-
ARM NEON在矩阵&向量计算中的加速概述2023-12-01 5046
-
PB331在车位诱导系统的应用2026-01-30 137
-
Bluetooth在车位锁上的应用2018-02-01 4846
-
ARM NEON技术在车位识别算法中有哪些应用?2019-09-02 2182
-
ARM Neon是什么2021-07-16 783
-
小白快速上手Arm NEON编程手册指南2022-07-15 6446
-
简述ARM SVE的发展以及和NEON的区别来探讨Vector在AI中的应用2022-09-19 3655
-
如何使用Arm Compiler 6自动矢量化功能为Neon编译2023-08-02 892
-
Arm Neon技术指南2023-08-08 627
-
多帧图像综合技术在车牌识别中的应用2010-02-21 695
-
基于DSP的图像处理在车牌识别中的应用2010-02-24 614
-
图象处理技术在车牌识别中的应用2009-12-08 1388
-
Arm NEON编程技术上手指南2022-12-06 2963
-
NEON编程中的一些常见优化技巧2022-12-12 3209
-
从CPU优化技术层面讲解Arm NEON2022-12-26 3031
全部0条评论

快来发表一下你的评论吧 !
