

深入GRU:解锁模型测试新维度
描述
之前带大家一起使用Keras训练了一个GRU模型,并使用mnist的手写字体数据集进行了验证。本期小编将继续带来一篇扩展,即GRU模型的测试方法。尽管我们将其当作和CNN类似的方式,一次性传给他固定长度的数据,但在具体实现上来说,还是另有门道的。让我们慢慢讲来。
首先回顾前面我们最终训练并导出的测试模型:
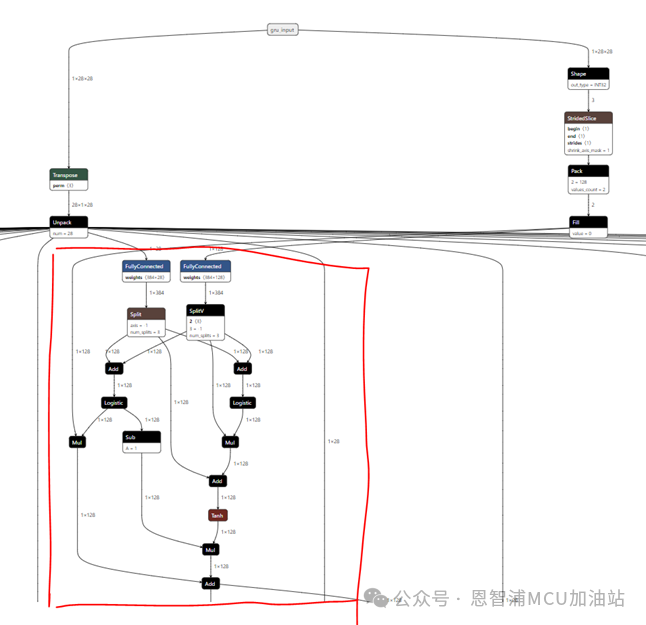
注意红色标注的位置,这就是一个典型的GRU节点:
模型的输入是28*28,代表的含义是:时间步*特征维度,简单来说,就是一次性送入模型多久的数据,即时间步实际上是一个时间单位。例如,我们想测试1s的数据进行检测。那么可以将其提取出来10*28的特征向量,那么每一个特征代表的就是1s/10即100ms的音频特征。了解了时间步,再回到模型本身,这里就是其中一种模型推理形式。即一次性将所有的数据都送进去,即1s对应的特征数据。然后计算得出一个结果。好处是:所见所得,和CNN类似,缺点是:必须等待1s数据,且循环time_step次。
那有没有替代方案呢?当然,那就是小编要提到的另一种,我们在导出模型时候将time_step设置为1,并且设置stateful=True,同时将time_step=N的模型权重设置到新模型上。这里的stateful=True要注意,因为我们将之前连续的time_step拆成了独立的,因此需要让模型记住前一次的中间状态。
可能这里大家有些疑问,为什么两个模型time_step不同,权重竟然通用。这就要说GRU模型的特殊性了,我们刚才看到的被展开的小GRU节点,其实是权重共享的。也就是说,不管展开多少次,他们的权重不会变(这个读者可以打开模型自行查看验证)。因此,就可以用如下代码生成新模型,并设置权重:
|
# 构建新模型 new_model = Sequential() new_model.add(GRU(128, batch_input_shape=(1, 1, 28), unroll=True, stateful=True)) new_model.add(Dense(10, activation='softmax')) new_model.set_weights(model.get_weights()) |
让我们看看模型的样子:
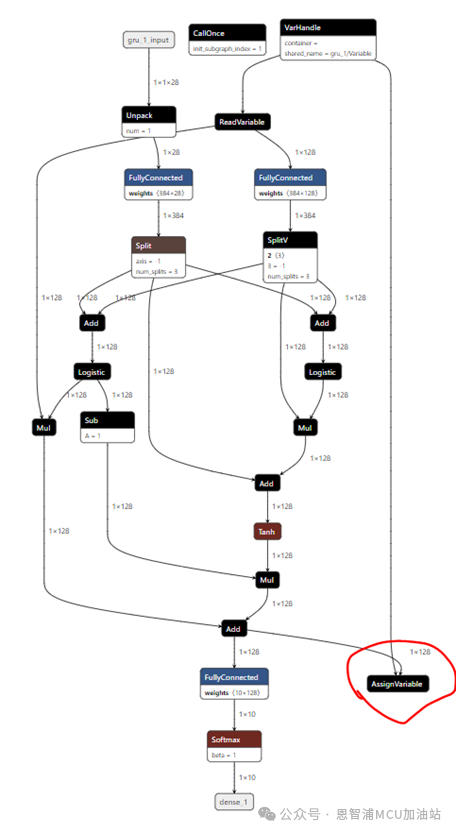
是不是看起来非常清爽,请注意右下角那个AssignVariable,这个就是为了保存当前状态,在下一次推理可以直接使用上一次的状态。需要注意的是,由于模型输入变成了一个time step,即1*28,在送入模型前,要注意一下。后续处理部分,依旧是FullyConnected+Softmax的形式,其他没有改变,照常即可。
至此,所有关于GRU模型的介绍以及使用就全部讲完了。MCU端的部署要靠大家自行体验了,因为模型本身实际上可以使用和CNN一样的推理方案,只是内部结构不同而已,希望对大家有所帮助!
恩智浦致力于打造安全的连接和基础设施解决方案,为智慧生活保驾护航。
-
模型捉虫行家MV:致力全流程模型动态测试2025-07-09 1055
-
企业级Claude API应用方案!完整调用攻略来袭:带你解锁Claude 3.5/3.7大模型2025-03-19 2701
-
【「大模型启示录」阅读体验】如何在客服领域应用大模型2024-12-17 2438
-
摩尔线程与智谱AI完成大模型性能测试与适配2024-06-14 2575
-
GRU模型实战训练 智能决策更精准2024-06-13 2906
-
按键荷重测试仪的多维度分析2023-10-18 1698
-
PyTorch教程10.2之门控循环单元(GRU)2023-06-05 1019
-
Stage模型深入解读2023-03-15 3689
-
基于篇章信息和Bi-GRU的事件抽取综述2021-04-23 1408
-
基于双编码器网络结构的CGAtten-GRU模型2021-04-01 1358
-
十款畅销手机指纹解锁速度横向测评2018-11-08 3015
-
Google对基于循环网络的模型的改进2018-06-30 4438
-
高维度矩阵怎样实现?2017-06-02 3072
-
基于模型的设计(MBD)的深入讨论2016-06-14 16359
全部0条评论

快来发表一下你的评论吧 !
