

机器学习的经典算法与应用
描述
关于数据
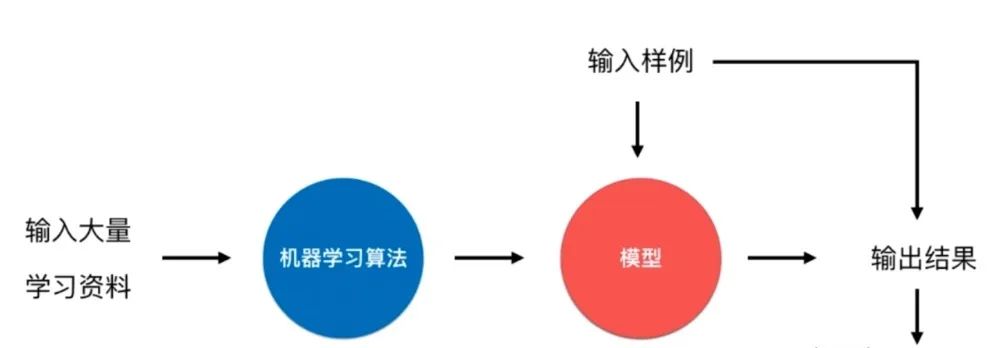
机器学习就是喂入算法和数据,让算法从数据中寻找一种相应的关系。Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
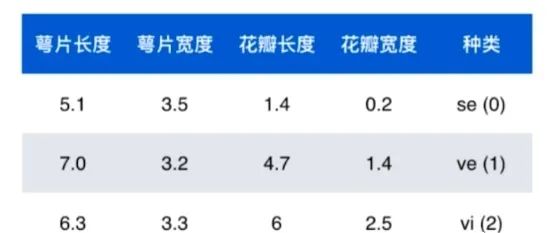
数据的整体成为数据集(dataset),数据中的每一行为1个样本(sample),除最后一行,每一列表达样本的一个特征(feature),最后一列,通常称为标记(label)。在鸢尾花的数据集中,每个样本有4个特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度,下面每一行数据称为一个样本的特征向量。所有的特征向量组成的空间称为特征空间(feature space),而分类任务的本质就是对特征空间的一种切分方式。
特征可以很具体也可以很抽象,在图像中,每一个像素点都是一个特征,一个28*28的图像有784个特征。所以,特征将很大程度上决定了算法结果的准确性和可靠性。这就是特征工程。
机器学习的基本任务1. 分类
- 二分类,在实际生活中其实大多数都可以用二分类解决,比如垃圾邮件分类,肿瘤辨别等。
- 多分类,比如手写数字识别,比如更加复杂的图像识别。在实际的生活中,很多复杂问题都可 以被转换为是一种多分类问题,但并不是说使用多分类是最佳的一种解决方式。
2. 回归
回归任务的特点:结果是一个数字的值,而非一个类别。比如预测房子价格,比如预测一个学生成绩,股票价格等等。在一些情况下,回归任务可以简化成分类任务,比如预测一个学生的成绩,可以将成绩分为几个不同的等级,这样就能将一个连续的回归问题转换为分类问题。
什么是机器学习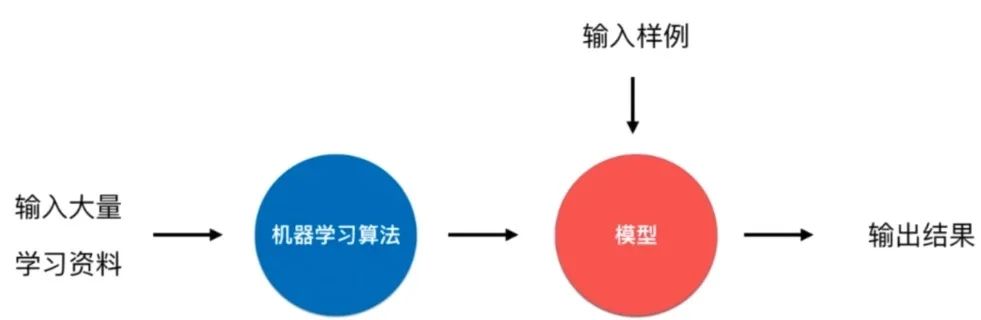
机器学习算法的目的就是帮助我们建立一个模型f(x),而不是我们人为建模得到的。其实分类和回归问题大多都是在监督学习中完成的。
二、机器学习的分类
1、监督学习
所谓监督学习其实就是给机器的训练数据拥有"标记"或者"答案"。比如图像拥有一定的标定信息,可能是类别,也可能是定位框等。机器学习的算法中大多都是监督学习,比如k近邻、线性回归和多项式回归、逻辑回归、SVM、决策树和随机森林等。
2、非监督学习
相对于监督学习,非监督学习就是给机器训练的数据没有"标记"或者"答案",通常情况下,非监督学习用来辅助监督学习。非监督学习一般对没有“标记”的数据进行分类,这就是聚类。比如电商网站使用非监督学习,根据顾客的浏览记录,对顾客进行分类,从而完成一些类似推荐的任务。非监督学习的意义、聚类、异常检测
降维
- 特征提取
- 特征压缩,比如刚刚提到的28*28的图像有784个特征,那么就可以考虑进行一下特征压缩。
- 特征压缩就是在尽可能损失少的信息,将高维向量压缩成低维向量,这样可以大大提高机器学习的运算效率。
- 降维处理的另外一个目的就是对数据进行可视化,对自己数据有一个大致了解。
3、半监督学习
所谓的半监督学习就是我们面对的任务一部分是有"标记"或者"答案",另一部分没有。因为在现实生活中很多任务都因为各种不同原因造成标记的缺失。比如我们手机中的相册中照片一些可能是在上海拍的,一些是在北京拍的,但是也会存在一些照片根本没有标记,那么手机相册中所有的照片就满足半监督学习的这个形态。通常都是先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练与预测。其实就是这两种学习模式的结合。
4、强化学习
强化学习是根据周围环境的情况,采取行动,根据采取行动的结果,学习行动的方式。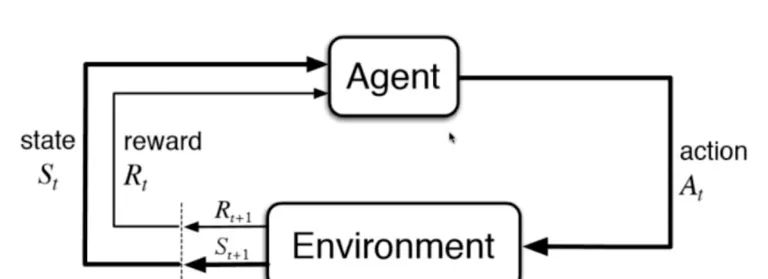
比如AlphaGo,无人驾驶都会用到增强学习
三、机器学习的其他分类1、批量学习(离线学习)和在线学习
- 批量学习(batch learning)、又叫离线学习
 优点:简单问题:如何适应环境的变换。比如垃圾邮件的样式。解决方案:定时重新批量学习,来适应环境的整体变换。缺点:每次重新批量学习,运算量巨大。在某些环境变换非常快的情况下,甚至是不可能的。比如股市的变化。
优点:简单问题:如何适应环境的变换。比如垃圾邮件的样式。解决方案:定时重新批量学习,来适应环境的整体变换。缺点:每次重新批量学习,运算量巨大。在某些环境变换非常快的情况下,甚至是不可能的。比如股市的变化。
- 在线学习(online learning)
 优点:及时反映新的环境变换问题:新的数据带来不好的变化?解决方案:需要加强对数据的监控,比如异常检测。其他适用范围:数据量巨大,无法批量学习的环境。2、参数学习与非参数学习
优点:及时反映新的环境变换问题:新的数据带来不好的变化?解决方案:需要加强对数据的监控,比如异常检测。其他适用范围:数据量巨大,无法批量学习的环境。2、参数学习与非参数学习
- 参数学习(Parameteric learning)
比如一个线性拟合问题y=wx+b,我们需要学习的参数就是w和b,参数学习的一个特点就是一旦学习到了参数,就不再需要原来的数据集。
- 非参数学习(Noneparameteric learning)
相对的非参数学习,不需要对模型进行过多的假设,通常在预测的过程中,喂给机器学习算法的那些数据集也要参数预测的过程,此外,需要特别注意的一点就是,非参数学习不等于没参数!
四、机器学习的“哲学”思考
数据越多越好?
2001年,微软的一篇论文,对比了四个不同的机器学习算法,给予足够多的数据时,四种算法的表现都是随着数据集的不断增大,准确率越高,当数据量大到一定程度的时候,算法结果准确度基本差不多。
这就带来一个问题,就是如果数据足够多,那么数据即算法?由此,就拉开了大数据的帷幕,人们对数据也越来月重视。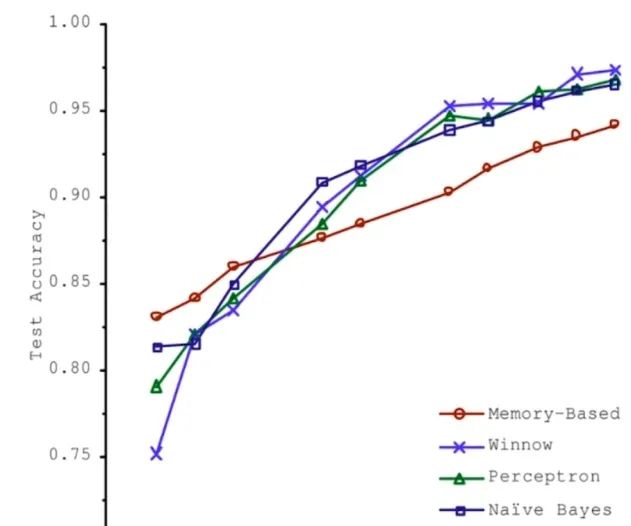 首先,由此可以得出结论,数据确实非常重要,而且现阶段使用到的机器学习算法大多都是以数据为驱动的,高度地依赖数据的质量,那么由此就需要收集更多的数据,提高数据的质量。也就有了数据清理、数据 预处理之说。那么从数据层面,我们需要考虑,如何提高数据的代表性,研究更重要的特征。算法为王?Alpha Zero的出现,之所以非常的突破,其原因在于我们并没有给Alpha Zero任何数据,所有的数据都是由算法产生的,这样的一个突破似乎打破了之前的数据越多越好,数据集算法的这么一个说法。也是由于围棋这个环境的特殊性导致算法能够自己产生数据,于是就有算法为王这么一种状况,可能在其他领域并不适用,但是它给予了我们一个启示:算法依然很重要。再好的数据都需要有高效、优秀的算法作为辅助,才能最大成都发挥数据本身的作用。如何选择机器学习算法?在机器学习算法中,远不止下面几种,那么如何选择合适的机器学习算法完成自己既定的任务呢?
首先,由此可以得出结论,数据确实非常重要,而且现阶段使用到的机器学习算法大多都是以数据为驱动的,高度地依赖数据的质量,那么由此就需要收集更多的数据,提高数据的质量。也就有了数据清理、数据 预处理之说。那么从数据层面,我们需要考虑,如何提高数据的代表性,研究更重要的特征。算法为王?Alpha Zero的出现,之所以非常的突破,其原因在于我们并没有给Alpha Zero任何数据,所有的数据都是由算法产生的,这样的一个突破似乎打破了之前的数据越多越好,数据集算法的这么一个说法。也是由于围棋这个环境的特殊性导致算法能够自己产生数据,于是就有算法为王这么一种状况,可能在其他领域并不适用,但是它给予了我们一个启示:算法依然很重要。再好的数据都需要有高效、优秀的算法作为辅助,才能最大成都发挥数据本身的作用。如何选择机器学习算法?在机器学习算法中,远不止下面几种,那么如何选择合适的机器学习算法完成自己既定的任务呢? 那么和选择相关的问题,最简单也就是最深刻的就是奥卡姆的剃刀,简单的就是好的?那么在机器学习的领域中,什么叫简单?第二个就是没有免费午餐的定理。可以严格地数学推导出:任意两个算法他们的期望性能是相同的!!!这也就是说其实没有那种算法从严格意义上比另外一种算法好,只是都在各自的领域中表现突出。相当于是说所有的算法是等价的,但这有一个前提,就是任意两个算法,把他们作用于所有的问题中,那么对于有些问题A算法比B算法好,但对于有些问题B算法比A算法好,但平均来说,这两个算法是一样的。这就是说需要具体到某个特定问题的时候,有些算法可能更好。整体而言,没有一种算法绝对的比另外一种算法好。也就说脱离具体问题去谈哪个算法好是没有意义的。最终的结论就是,我们在面对一个具体问题的时候,尝试使用多种算法进行对比实验是必要的!面对不确定的世界,怎样看待机器学习算法进行预测的结果?最典型的问题就是比如预测股市,预测世界经济趋势扥等等等。我们到底应该怎样看待这个结果?到底是机器学习算法本身起到了决定性作用,使得我们得到了一个准确的预测结果,还是其实只是一个巧合,机器学习本身并没有起到太大的作用。在使用机器学习的过程中存在的机器伦理问题?比如无人驾驶决策的过程中存在的一个无法避免的问题是车的道路左边是小孩,右边是老人,此时车辆无法避免,必须要做出决策,是老人还是孩子?如果选择自毁,那么车里坐的是一个孕妇,此时就牵涉到伦理问题。甚至还会有人说人工智能威胁论等等。
那么和选择相关的问题,最简单也就是最深刻的就是奥卡姆的剃刀,简单的就是好的?那么在机器学习的领域中,什么叫简单?第二个就是没有免费午餐的定理。可以严格地数学推导出:任意两个算法他们的期望性能是相同的!!!这也就是说其实没有那种算法从严格意义上比另外一种算法好,只是都在各自的领域中表现突出。相当于是说所有的算法是等价的,但这有一个前提,就是任意两个算法,把他们作用于所有的问题中,那么对于有些问题A算法比B算法好,但对于有些问题B算法比A算法好,但平均来说,这两个算法是一样的。这就是说需要具体到某个特定问题的时候,有些算法可能更好。整体而言,没有一种算法绝对的比另外一种算法好。也就说脱离具体问题去谈哪个算法好是没有意义的。最终的结论就是,我们在面对一个具体问题的时候,尝试使用多种算法进行对比实验是必要的!面对不确定的世界,怎样看待机器学习算法进行预测的结果?最典型的问题就是比如预测股市,预测世界经济趋势扥等等等。我们到底应该怎样看待这个结果?到底是机器学习算法本身起到了决定性作用,使得我们得到了一个准确的预测结果,还是其实只是一个巧合,机器学习本身并没有起到太大的作用。在使用机器学习的过程中存在的机器伦理问题?比如无人驾驶决策的过程中存在的一个无法避免的问题是车的道路左边是小孩,右边是老人,此时车辆无法避免,必须要做出决策,是老人还是孩子?如果选择自毁,那么车里坐的是一个孕妇,此时就牵涉到伦理问题。甚至还会有人说人工智能威胁论等等。
来源: 小白学视觉
-
机器学习的经典算法与应用2023-05-28 2397
-
#硬声创作季 机器学习经典算法:00_00_人工智能课程简介Mr_haohao 2022-10-03
-
如何自学人工智能?机器学习详细路径规划2018-08-04 9915
-
机器学习经典算法-最优化方法2017-09-04 909
全部0条评论

快来发表一下你的评论吧 !
