

 基于DPU的Ceph存储解决方案
基于DPU的Ceph存储解决方案
描述
1. 方案背景和挑战
Ceph是一个高度可扩展、高性能的开源分布式存储系统,设计用于提供优秀的对象存储、块存储和文件存储服务。它的几个核心特点是:
弹性扩展:Ceph能够无缝地水平扩展存储容量和性能,只需添加新的存储节点即可,无需重新配置现有系统,非常适合云环境的动态需求;
自我修复:通过副本或纠删码技术,Ceph能够自动检测并修复数据损坏或丢失,保证数据的高可用性和持久性;
统一接口:Ceph提供RADOS GW(对象存储网关)、RBD(块设备映射)和CephFS(文件系统)三种接口,满足不同存储需求,且这些接口可以同时在一个集群中使用。
在Kubernetes(K8s)架构下,Ceph可以作为一个强大的存储后端,为容器化的应用提供持久化存储解决方案。Kubernetes通过存储卷插件与外部存储系统集成,Ceph正是通过这样的插件(如RBD插件)与K8s集成,实现存储资源的动态分配和管理。
架构如下图所示:
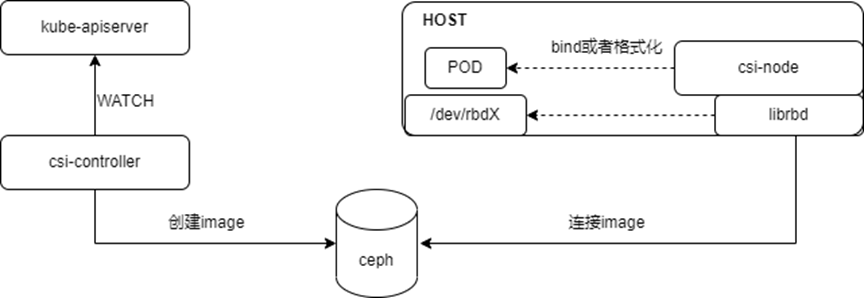
在传统方式下使用Ceph作为存储解决方案,会遇到一些局限性和挑战,尤其是在与现代云原生环境如Kubernetes集成时,这些问题可能会更加突出,具体表现为以下几个方面:
RBD客户端运行于Host,消耗计算资源:传统部署模式下,Ceph的RBD(RADOS Block Device)客户端运行在宿主机(Host)层面,而非直接在容器内部。这意味着所有与Ceph交互的计算任务,包括I/O请求处理、错误恢复等,都需要宿主机的CPU资源来完成。在高负载情况下,这些额外的计算需求可能会对宿主机的资源分配产生压力,影响到运行在相同宿主机上的其他容器应用的性能。
使用RBD协议连接后端存储,性能受限:RBD协议虽然成熟且稳定,但在某些场景下,其性能表现可能不尽人意,尤其是在需要大量小I/O操作或高带宽传输的情况下。这是因为RBD协议在设计上更多考虑了数据的可靠性和一致性,而非极致的性能。这导致数据传输延迟较高,影响到依赖快速存储响应的应用性能,如数据库服务或大数据处理系统。
在Kubernetes架构下,无法直接利用DPU实现卸载和加速:随着DPU(Data Processing Unit)等硬件加速技术的兴起,其在数据处理、网络和存储任务中的加速能力备受瞩目。然而,在传统的Ceph与Kubernetes集成方案中,缺乏直接利用DPU卸载存储相关处理的能力,导致无法充分利用DPU提供的硬件加速优势,限制了存储性能的进一步提升和资源的高效利用。
鉴于以上挑战,探索和实施针对Kubernetes环境优化的Ceph部署方案,如通过专门的Ceph CSI(Container Storage Interface)插件支持DPU卸载,或是利用Ceph的其他高级功能与现代硬件加速技术紧密结合,成为了提升云原生应用存储性能和效率的关键方向。
2. 方案介绍
2.1. 整体架构
本方案采用云原生架构,引入DPU作为Kubernetes集群的Node,为集群之上的容器、虚机和裸金属实例提供存储服务的卸载和加速。整体架构如下所示:
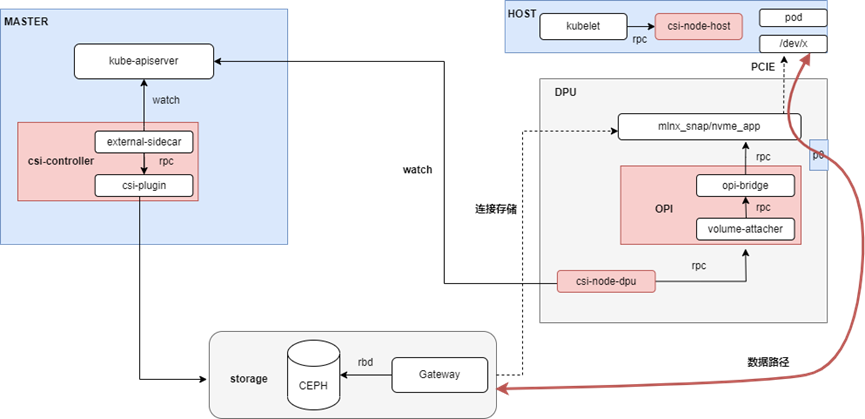
本方案将K8s node分为不同的角色(node-role),不同的组件分别部署在不同的node,主要包含:
Master Node上,部署csi的控制器csi-controller,用于创建volume和NVMe-oF target;
Host Node上,部署csi-node-host,配合csi-node-dpu,通过volumeattachment发现DPU挂载的NVMe盘,然后执行绑定或者格式化;裸机场景没有这个组件;
DPU上,部署csi-node-dpu,volume-attacher和opi-bridge。opi-bridge是卡对opi-api存储的实现,volume-attacher是对DPU存储相关方法的封装;csi-node-dpu 调用volume-attacher给host挂盘;
Storage上,部署Ceph和GATEWAY,GATEWAY是对SPDK封装的一个服务,用于本地连接rbd image,暴露成NVMe-oF target。
2.2. 方案描述
本方案主要由csi-framework、opi-framework和storage三个部分组成,下面将对这三个部分进行介绍。
2.2.1. csi-framework
通过csi-framework我们能快速的接入第三方的存储,让第三方存储很方便的使用DPU的能力。其包括csi-controller、csi-node-host和csi-node-dpu,主要职责是为K8s的负载提供不同的存储能力。
2.2.1.1. csi-controller
Csi-controller以deployment的形式部署在master节点,其架构如下图所示:
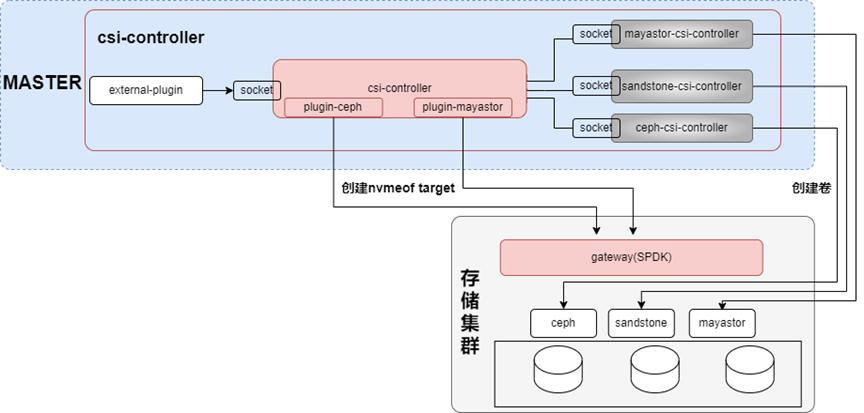
在csi-controller pod中,包含对接存储的csi-controller容器,主要用于在对接存储上创建卷,除此之外,为了让对接存储也能用nvmeof的方式,本架构也开发了对应的插件系统,由插件负责NVMe-oF target的管理。
结合K8s csi的external plugin,csi-controller主要实现以下两类功能:
针对pvc,调用第三方的controller,创建卷,创建快照和扩容等;
针对pod(本质上volumeattachment,简称va),两种连接模式,AIO和NVMe-oF(因为opi目前只支持这两种)。如果是NVMe-oF,则调用不同的plugin在GATEWAY上创建NVMe-oF target;相关的target参数会持久化到va的status,此时va的状态变为attached=true。
2.2.1.2. csi-node
Csi-node以daemonset的形式,部署在所有节点,其架构如下图所示:
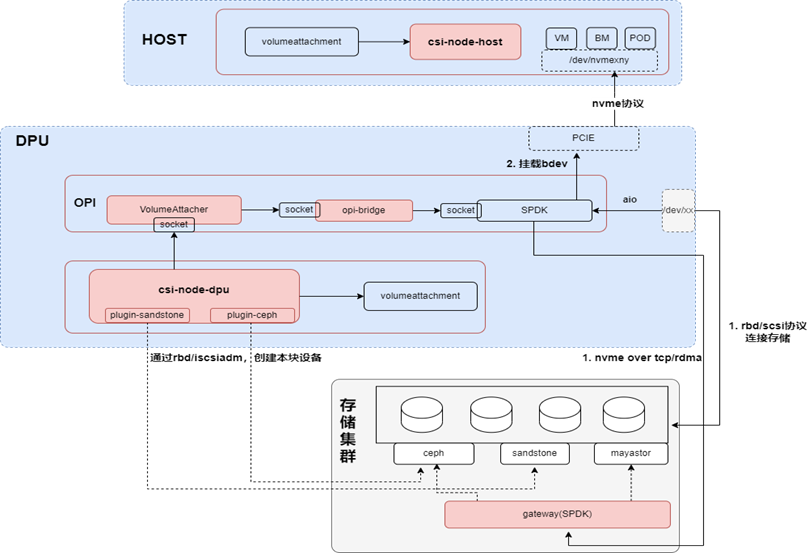
在csi-node的架构中,没有整合第三方的csi-node,是因为第三方csi-node往往是针对非DPU的场景,所以在本框架中,也是使用插件系统,对接不同的第三方存储。插件系统主要用于直连存储,比如通过RBD或者ISCSI,会在本地生成一个块设备,最后把这个块设备再以AIO的方式挂载到PCIE上;如果是使用本框架的NVMe-oF的方式,由csi-node-dpu负责从va获取对应的连接信息,连接NVMe-oF target。
Csi-node按node角色分为csi-node-dpu、csi-node-host和csi-node-default,不同角色的csi-node功能不同,下面分别加以说明:
csi-node-dpu需要处理host和DPU侧的挂盘请求,待csi-node-dpu根据不同的连接模式(AIO或者NVMe-oF),连接远程存储;在pf或者vf上挂载磁盘后,会把挂盘的信息添加到va的annotation;
csi-node-host就能根据va的annotation找到挂载的disk,进行下一步操作;
csi-node-default 也就是默认的工作模式,同非DPU场景的csi-node工作方式。
2.2.2. opi-framework
主要用来兼容不同卡的功能,对上提供统一的接口;通过opi-framework,我们能将第三方存储快速对接到其他DPU。不同DPU通过opi-bridge对接到opi框架,再由volume-attacher提供opi框架没有的功能,其架构如下图所示:
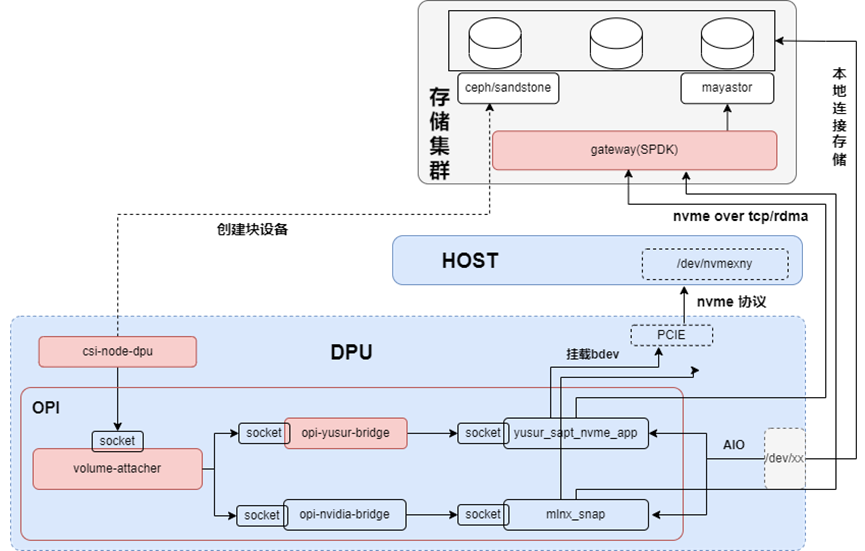
Opi-framewark包括volume-attacher、opi-yusur-bridge、opi-nvidia-bridge和SPDK,提供存储卸载和加速能力。
volume-attacher是bridge之上的一层封装,其主要作用有三个:
参数计算,比如挂载那个vf,使用那个nsid等;同时保证相同的盘,挂载到相同的挂载点;
因为opi-bridge和SPDK都没有数据持久化,所以一旦opi-bridge或者SPDK重启之后,需要volume-attacher进行数据恢复
从上我们知道,opi框架提供的能力有限,比如backend,只支持AIO和NVMe-oF;一旦要使用其他的bdev,比如lvol,此时就没法通过opi-bridge操作,所以volume-attacher还封装了对底层SPDK的操作。
opi-bridge是对opi标准的实现,不同的卡会有不同的bridge,存储方面主要包括对接SPDK的三类接口(frontendmiddleendbackend)。
SPDK是卡上的服务,除了原生SPDK的功能外,主要作用是在pf或者vf上挂载bdev。
2.2.3. storage
除了第三方或者开源的存储系统之外,还提供一个GATEWAY,GATEWAY的能力就是在靠近存储的地方(所以往往和存储系统部署在一起),把卷通过NVMe-oF target的方法是暴露出去;同时支持NVMe-oF multipath实现高可用。
3. 方案测试结果
3.1. Pod挂盘
首先创建pvc,然后在pod的volumes中以Block或者Filesystem的方式使用pvc,关键参数如下所示:
##pvc-xxx.yaml 关键参数 storageClassName: class-ceph ## 通过不同的storageclass,使用AIO或者nvmeof的方式
创建后,相关资源信息如下:
HOST侧,使用nvme list和nvme list-subsys可查看对应的disk和system,如下图所示:

DPU侧,使用rpc.py查看对应的bdev,nvme_ns, nvme_ctrl
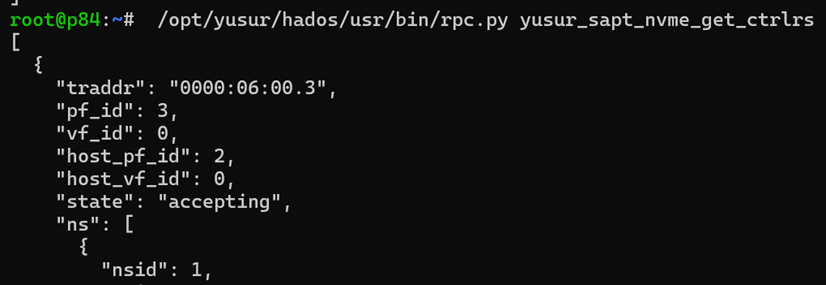
查看对应的bdev,如下所示:
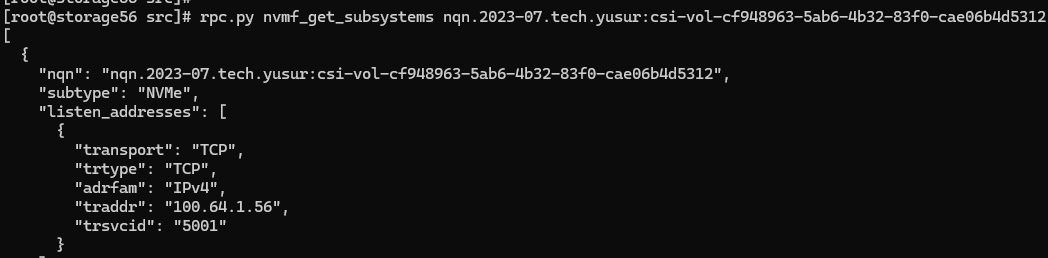
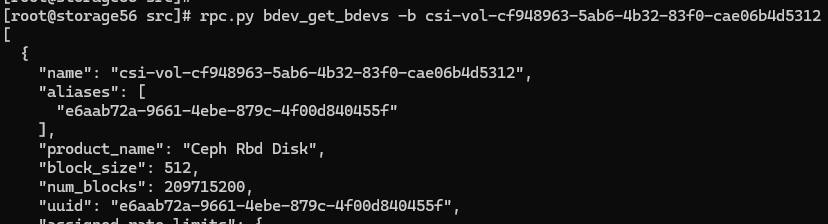
GATEWAY侧,使用rpc.py查看nvme_subsystem,bdev
查看对应的bdev,如下所示:
3.2. 性能对比
本方案基于单节点ceph创建单副本存储池,在以下测试场景与传统ceph方案进行对比:
AIO:DPU上通过RBD协议连接存储,然后把/dev/rbd0通过AIO给到Host;
Host-RBD:测试节点上用RBD 协议连接存储,也是传统ceph方案的方式;
LOCAL-RBD:存储节点上用RBD协议连接存储,用于对比Host-RBD;
Host-NVMe-CLI/TCP:测试节点上通过NVMe-CLI以NVMe/TCP的方式连接存储上的GATEWAY,用来对比卸载模式的性能;
Host-NVMe-CLI/RDMA:测试节点上通过NVMe-CLI以NVMe/RDMA方式连接存储上的GATEWAY,用来对比卸载模式的性能;
NVMe/TCP:DPU上直接TCP协议连接GATEWAY,是本方案的一种连接方式;
NVMe/RDMA:DPU上直接通过RDMA协议连接GATEWAY,是本方案的一种连接方式。
测试不同blocksize下的随机读写指标包括iops,吞吐,延迟和Host CPU消耗。
3.2.1. 存储IOPS
测试结果如下:
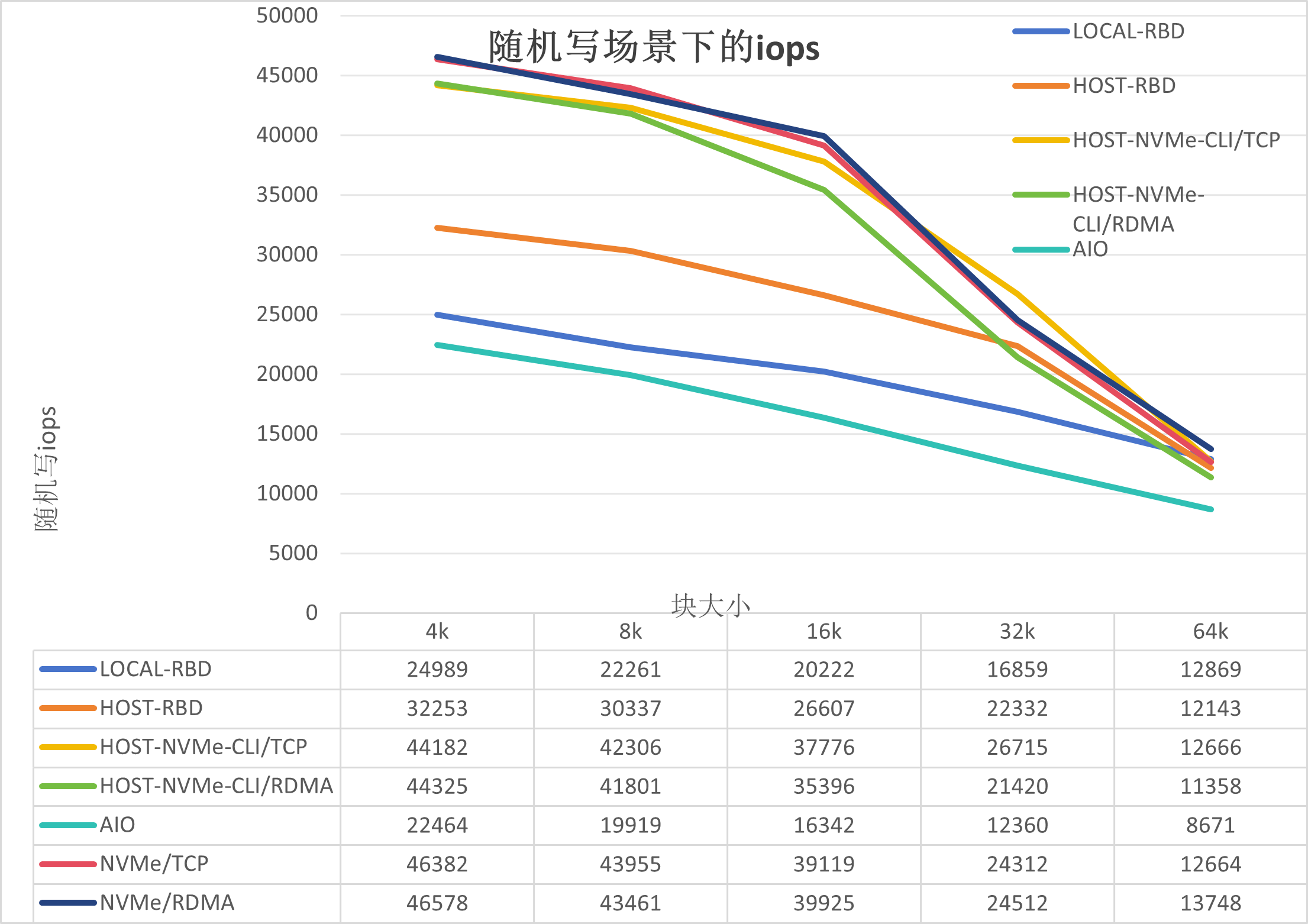
从上图我们可以得出以下结论:
AIO性能最差,是因为AIO是通过DPU里面librbd连接存储,受限于DPU的资源;
LOCAL-RBD的性能较Host-RBD低,是因为本地测试时,内核RBD模块与osd存在资源竞争,导致ceph-osd的CPU上不去,在950%左右,但是在Host-RBD测试时ceph-osd的CPU在1050%左右;
NVMe/TCP的性能较Host-NVMe-CLI/TCP和Host-NVMe-CLI/RDMA稍高,是因为两者的路径不一样,有可能是DPU的SPDK服务带来的加速效果;
NVMe/RDMA与NVMe/TCP基本持平,是因为瓶颈在ceph,这个会基于裸盘给出结论
NVMe/RDMA,NVMe/TCP,Host-NVMe-CLI/TCP和Host-NVMe-CLI/RDMA,高于Host-RBD,是因为GATEWAY的加速作用,能把ceph-osd的CPU进一步提高到1150%左右。
随机读iops如下图所示:
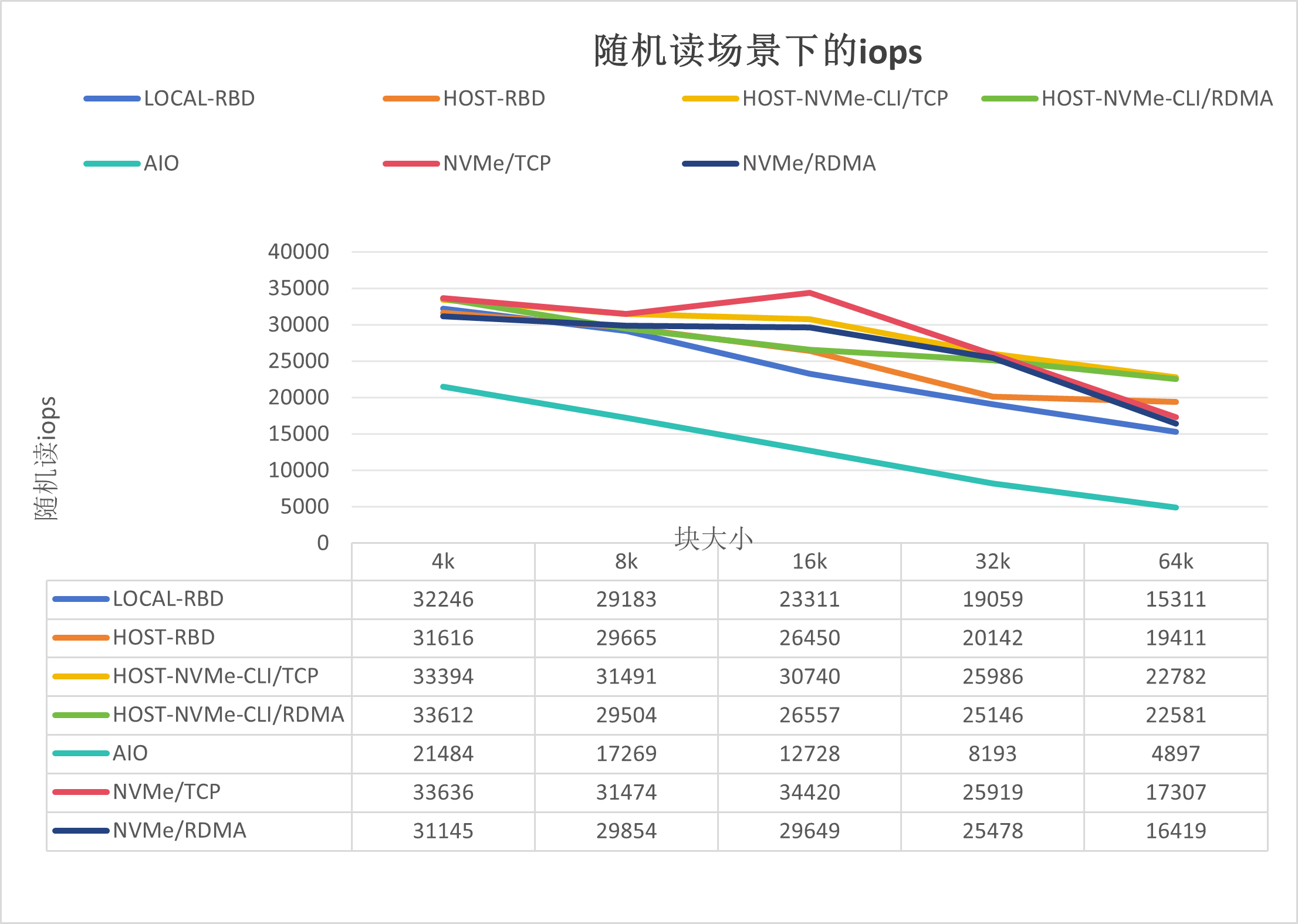
如上图所示,可以得出如下结论:
NVMe/TCP的性能与Host-NVMe-CLI/TCP基本持平,好于Host-RBD;
NVMe/RDMA的性能较NVMe/TCP的稍低,有可能是在随机读场景下RDMA协议的损耗导致。
3.2.2. 存储延迟
测试结果如下:
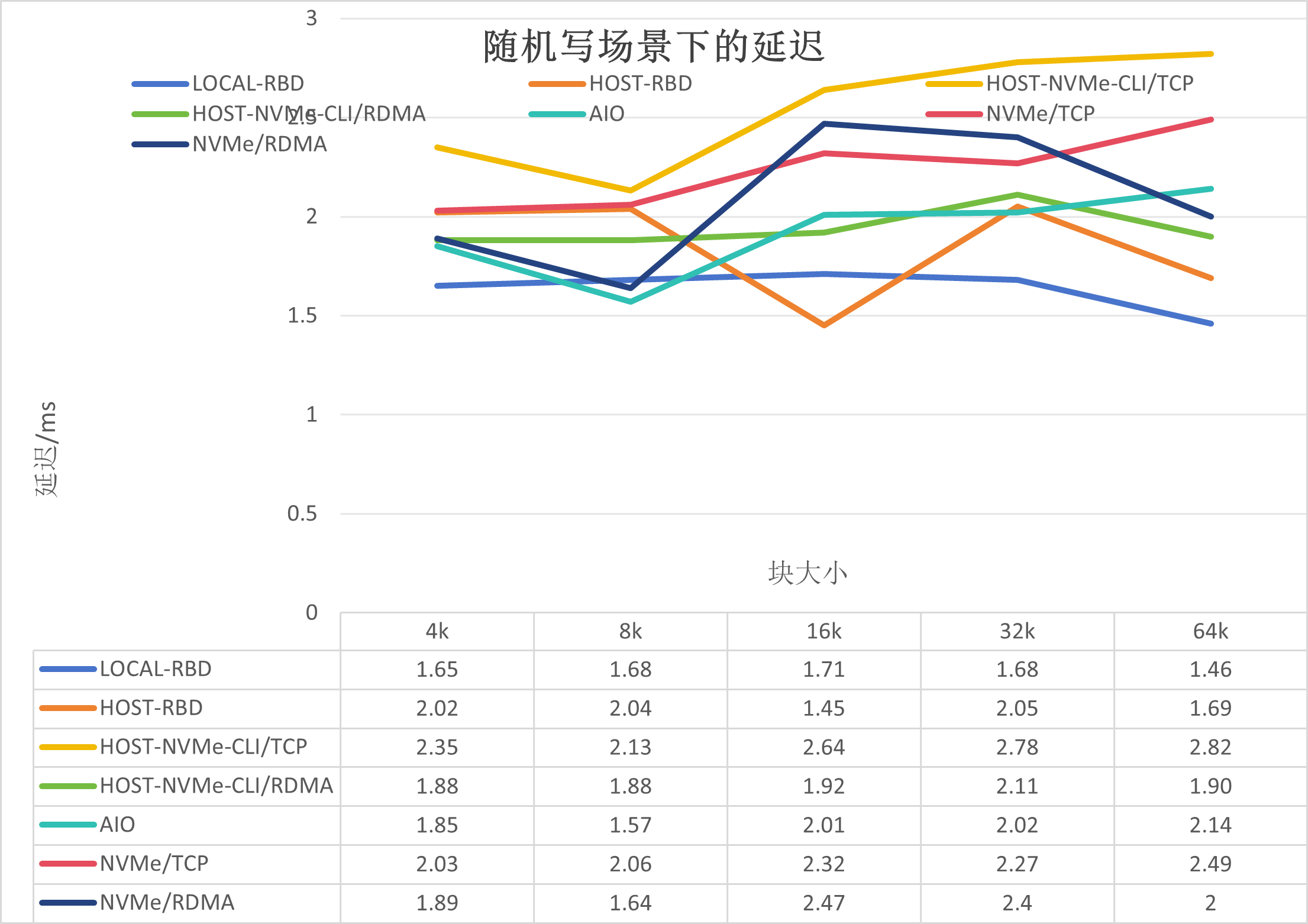
如上图所示,可以得出如下结论:
RDMA的延迟要好于TCP;
HOST-RBD好于其他非本地场景,是因为整体io路径较其他的短。
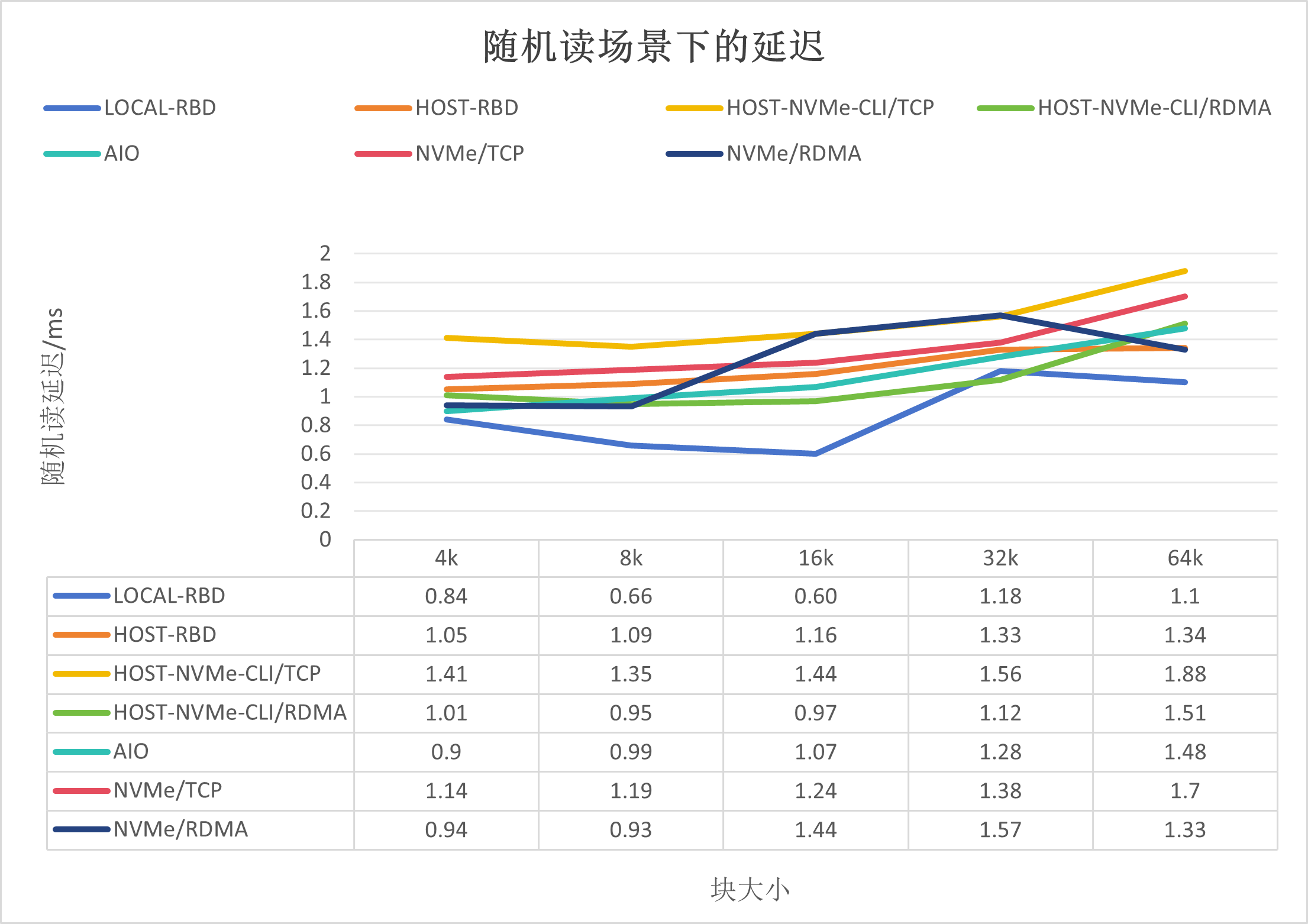
随机读场景下的延迟,如下所示:
3.2.3. CPU消耗
测试结果如下:
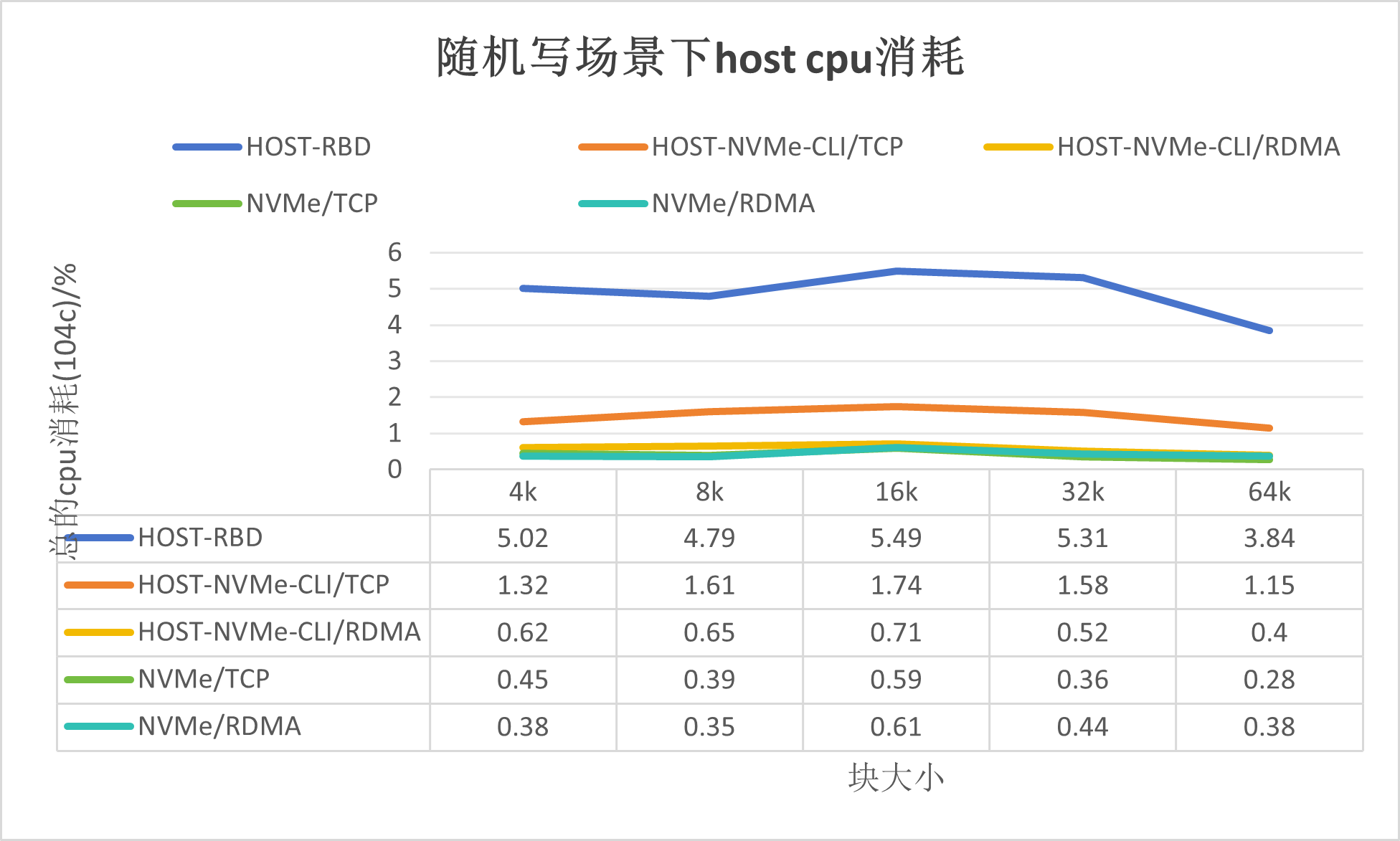
如上图所示,可以得出如下结论:
基于传统的Ceph解决方案,消耗Host CPU在400%-600%之间,其资源消耗在内核模块RBD;
使用Host-NVMe-CLI/TCP的方式,消耗Host CPU在70%-200%之间, 其资源消耗在内核模块NVMe/TCP;
使用Host-NVMe-CLI/RDMA的方式,其资源消耗和卸载模式相当;
基于DPU的ceph解决方案,NVMe/TCP和NVMe/RDMA的Host CPU消耗很低。
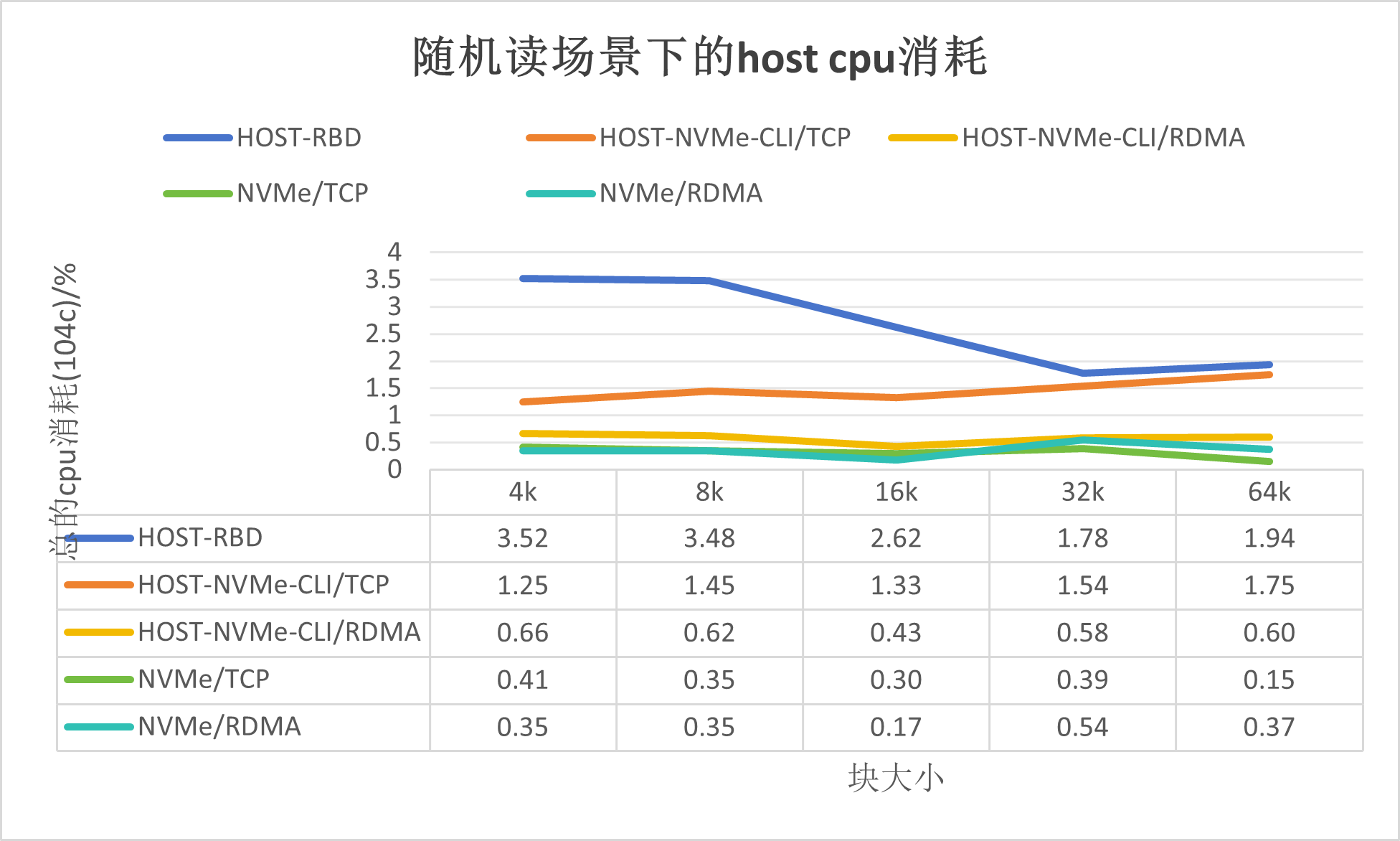
随机读场景下的资源消耗,如下所示:
4. 总结
4.1. 方案优势
基于DPU(Data Processing Unit)的Ceph存储解决方案,为云原生存储领域带来了显著的资源优化,在性能上也有一定改善,具体优势体现在以下几个方面:
1. 资源效率大幅提升:通过将Ceph的控制面和数据面操作下沉至DPU处理,显著减轻了宿主机(Host)的资源消耗。测试结果显示,在并行度为8的场景下,blocksize为4KB时,宿主机CPU资源的使用率明显下降,从502%的消耗,降低到了仅45%,这意味着在实际应用场景中,将大大节省了宝贵的CPU资源,让这些资源能够被应用服务更高效地利用。
2. 性能保持与优化:在对比分析中,基于DPU的Ceph解决方案不仅保持了与传统Ceph部署在性能上的竞争力,而且还展示了显著的提升潜力。通过对比使用Host-NVMe-CLI(分别通过TCP和RDMA协议)、NVMe/TCP和NVMe/RDMA的传统Ceph性能数据,发现基于DPU的方案并未降低原有的Ceph性能表现,反而在某些指标上有所增强。特别是当直接对比基于Host的RBD访问、NVMe/TCP和NVMe/RDMA的性能时,DPU方案展现出了超越这些传统访问方式的性能提升,这表明DPU不仅有效卸载了存储处理任务,还通过其硬件加速特性提升了存储I/O性能。
3. 填补Kubernetes生态空白:在Kubernetes(K8s)生态系统中,虽然有多种存储解决方案和插件,但之前缺乏针对DPU优化的存储卸载和加速服务。这一自研的基于DPU的Ceph解决方案,填补了这一技术空白,为Kubernetes环境下的应用提供了更高效、低延迟的存储支持。通过集成DPU加速能力,不仅增强了云原生应用的存储性能,还为用户提供了更多选择和优化存储配置的灵活性,有助于提升整个云平台的运行效率和成本效益。
综上所述,基于DPU的Ceph存储解决方案通过自研的Kubernetes组件、引入DPU深度优化存储处理流程,显著降低了宿主机资源消耗,保持甚至提升了存储性能,同时为Kubernetes生态引入了创新的存储加速服务,是面向未来云原生架构的重要技术进步。
本方案来自于中科驭数软件研发团队,团队核心由一群在云计算、数据中心架构、高性能计算领域深耕多年的业界资深架构师和技术专家组成,不仅拥有丰富的实战经验,还对行业趋势具备敏锐的洞察力,该团队致力于探索、设计、开发、推广可落地的高性能云计算解决方案,帮助最终客户加速数字化转型,提升业务效能,同时降低运营成本。
审核编辑 黄宇
-
Ceph集群部署与运维完全指南2025-08-29 1839
-
K8s存储类设计与Ceph集成实战2025-08-22 1412
-
《数据处理器:DPU编程入门》DPU计算入门书籍测评2023-12-24 2239
-
什么是DPU?2023-11-03 1794
-
Ceph分布式存储简介&Ceph数据恢复流程2023-09-26 2023
-
SDNLAB技术分享:Ceph在云英的实践2023-06-16 1036
-
DPU技术解决方案的挑战和机遇2022-10-11 2925
-
Ceph是什么?Ceph的统一存储方案简析2022-10-08 2142
-
autobuild-ceph远程部署Ceph及自动构建Ceph2022-05-05 725
-
ceph-zabbix监控Ceph集群文件系统2022-04-26 818
-
Ceph分布式存储系统性能优化研究综述2021-04-13 1288
-
深度解读基于Ceph对象存储的混合云机制2019-07-08 1716
-
如何利用Intel的傲腾技术和CPU提升Ceph性能2019-06-29 6215
-
还在用Ceph吗?不如试试性能更好的碧海存储2019-03-27 2916
全部0条评论

快来发表一下你的评论吧 !
