

实时语音识别系统在家庭监护机器人的实现
音频技术
描述
摘要:
文中阐述的是家庭监护机器人项目中语音识别系统设计的部分,通过DSP、DMA和ARM Cortex-A8的并行处理,利用双缓冲的方法,在嵌入式Linux上实现了基于ATK的实时语音识别系统。文中对该系统的软硬件进行了设计。在硬件方面,给出语音识别系统的硬件组成原理,并提供了关键部分原理图;在软件方面,提出实时语音识别的方法,给出应用程序实现流程。最后通过真人说话来进行语音识别实验,实时语音识别率达到了94.67%以上,实验验证了系统的软件硬件设计的正确性。
语音是人类最常用的交流方式,也是人类和计算机交流最渴望的方式。因此用语音同计算机交流也成为了最近研究的热点,计算机对语音的理解是计算机科学中的一个引人人胜的、富有挑战性的课题。
进入90年代,随着多媒体时代的来临,迫切要求语音识别系统从实验室走向实用。许多发达国家如美国、日本、韩国以及IBM、Apple、AT&T、NTT等着名公司都为语音识别系统的实用化开发研究投以巨资。IBM公司于1997年开发出汉语ViaVoice语音识别系统,次年又开发出可以识别上海话、广东话和四川话等地方口音的语音识别系统ViaVoice‘98.目前市场上已经出现了语音识别电话、语音识别记事本等产品,如美国VPTC公司的Voice Organizer和法国的Parrot等。
我国语音识别研究工作开始的较晚,但近年来发展得很快,一直紧跟国际水平,国家也很重视,并把大词汇量语音识别的研究列入“8 63”计划,由中科院声学所、自动化所、清华大学电子工程系及北京大学等单位研究开发,取得了高水平的科研成果,如中科院自动化所研制的非特定人、连续语音听写系统和汉语语音人机对话系统,其字准确率或系统响应率可达90%以上。鉴于中国未来庞大的市场,国外也非常重视汉语语音识别的研究。美国、新加坡等地聚集了一批来自大陆、***、香港等地的学者,研究成果已达到相当高水平。
1 系统设计
文中是家庭监护机器人项目中的语音识别系统设计部分,设计目的是设计出一种可以识别语音的、协助监护家庭行动不方便人员的机器人。为实现该语音识别系统,设计了语音识别系统总体结构框图,如图1所示。
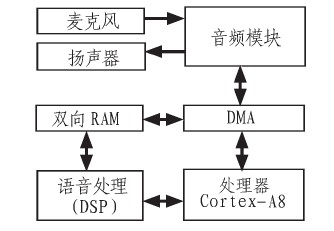
图1 系统总体结构框图
1.1 硬件设计
文中所研究和设计的功能,都是应用在移动机器人上的。因而系统的研究设计需要考虑到体积小、省电、便于移动的特性,并需具有便于家庭用户操作的友好显示界面。对于语音识别部分,需要用到用于语音识别算法处理的处理器、语音采集电路和语音输出电路,如图 2所示。其中语音识别算法运算的处理器主要负责算法的运算处理,相当于机器人的大脑;语音采集电路负责采集外部的声音信号,相当于机器人的耳朵;语音输出电路负责输出话语声音,相当于机器人的嘴巴。
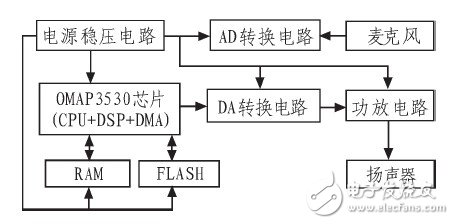
图2 系统硬件结构图
1)语音识别算法处理器选择
根据系统设计功能的要求,目前常用的语音识别芯片种类一般有:单片机(MCU)、DSP和SoC(System on Circuit)。考虑到普通单片机(MCU)资源的紧缺及运行速度较慢的缺点,因而在本系统设计将不考虑使用单片机(MCU)作为语音识别的处理器。DSP包含用作数字信号处理的专用部件,运算能力强、精度高,但目前DSP的价格比较高,同时考虑到本系统的特性,需要选择一种既有较强的运算能力,合适于语音识别的功能,并且能实现较好的用户操作界面,并带有文件系统(用于识别地图)的功能,因而选择DSP并不是明智之举。目前Texas Instruments公司新推出的一款芯片OMAP3530,它具有双内核ARM CortexTM-A8的内核和TMS320C64+TM DSP内核,属于高性能的OMAP35x架构系列产品,满足了系统设计的各种功能特性要求。
2)语音编解码芯片选择
机器人选择一款合适的语音处理芯片是非常重要的。考虑到系统中用到了各种电源,并需要对电源进行管理,因此选择TI公司配套的TPS 65930芯片来作为系统语音识别部分的音频编解码处理功能的硬件平台是非常合适的。该芯片是一个集成了电源管理、ADC、嵌入式电源控制(EPC)、全功能的音频编解码器于一体的芯片,满足了系统所有电源管理和音频编解码的需要,为设计的PCB板节省了空间,同时减少了多电源硬件设计的负责布线烦恼。
3)电路设计
本文的设计是用在移动机器人上的,因而需要语音的输入、识别处理及语音输出的功能。对于语音的输入采集,本文使用声音传感器麦克风及外围电路来实现。对于语音输出部分,使用功率放大器结合喇叭来使用。设计语音部分原理图如图3所示。
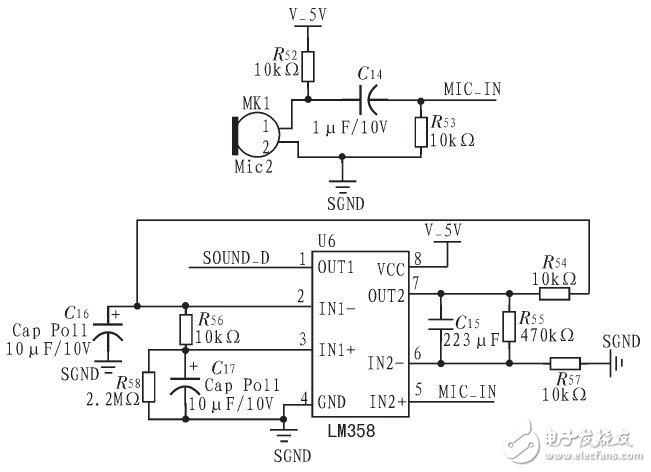
图3 语音输入原理图
1.2 软件设计
HTK(Hidden Markov Model Toolkit)是一套专门的建立和处理隐马可夫模型(HMMs)的实验工具包,由英国剑桥大学工程系(Cambridge University Engineering Department,CUED)开发的,主要应用于语音识别领域,也可以应用于语音合成、字符识别和DNA排序等研究领域。HTK经过剑桥大学、 Entropic公司及Microsoft公司的不断增强和改进,使其在语音识别领域处于世界领先水平。
基于HTK的语言识别时,识别结果适用只能显示在DOS或终端上,而且不利于将结果保存、移植或者二次开发利用。在本语音识别系统中使用了HTK接口工具ATK(AnApplication Toolkit for HTK)。ATK是由英国剑桥大学开发的开源语音识别工具,是对HTK的C++多线程封装,跟HTK一样,它支持Linux和Windows,它包括 HTK(HTKLib)、AHTK、AGram、ANGram、ADict、AHMMs、AResource、ARMan、ARec、ACode、 ASour ce、ATee、AComponent、ABuffer、APacket、Asyn、FLite(SYNLib)、ALog模块部件。
基于ATK的语音识别软件应用系统的由语音信号采集模块、基于DMA的双向高速RAM存取模块、ATK语音识别模块、系统管理模块、语音输出模块等模块组成,如图4所示。
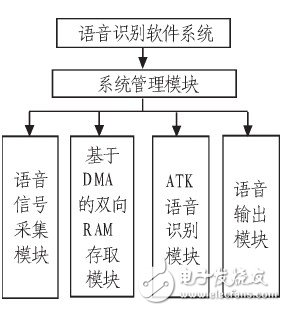
图4 系统软件设计结构图
在软件设计中,系统管理模块主要负责系统的总体管理调度,是应用系统的调度中心;语音信号采集模块主要负责控制数据采集芯片TPS 65930;基于DMA的双向RAM存取模块主要负责实现DMA驱动及双向RAM的读写存取,使用了通道1来实现高速地把语音信号采集到的数据存储到 RAM上,并使用通道2实现高速地把RAM的数据取出来,用于语音的识别;语音输出模块主要负责把相应的音频数据送到TPS65930,并控制TPS6 5930对接收到的音频解码输出到功放电路,实现语音输出的功能。软件的设计流程图如图5所示。
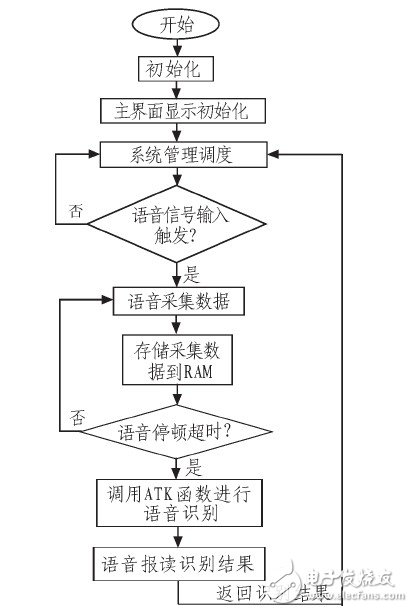
图5 软件设计流程
2 语音识别系统实验及结果
文中设计的语音识别系统如图6所示。在实验中总共进行了3轮话语测试,每轮300句话语测试,其中 150句为家庭监护机器人需要识别的话语,150句话语为机器人不予置理的无关话语。本系统只设置10个需要识别的话语,由15名学生分别读音进行测试。同时对无关话语也是由该15名学生,每人10句分别随机读音测试。从显示结果可以看出,第1轮中,先测试的150句无关话语中,能正确识别出无关话语数为 150句,识别出无关话语率为100%,但对需识别的话语中,正确识别出148句,2句识别出错,识别率为98.67%;在第2轮中,同样先测试的150 句无关话语中,能正确识别出无关话语数为150句,识别出为无关话语率为100%,但对需识别的话语中,正确识别出142句,8句识别出错,识别率为 94.67%;在第3轮中,同样先测试的150句无关话语中,能正确识别出无关话语数为150句,识别出无关话语率为100%,但对需识别的话语中,正确识别出146句,识别率为97.33%.在3轮测试中,系统都能实时响应所有语句,未出现漏句现象。并且在实验测试的过程中,系统的响应速度都非常快,感观上没有时间延迟,与真人交流速度相当。
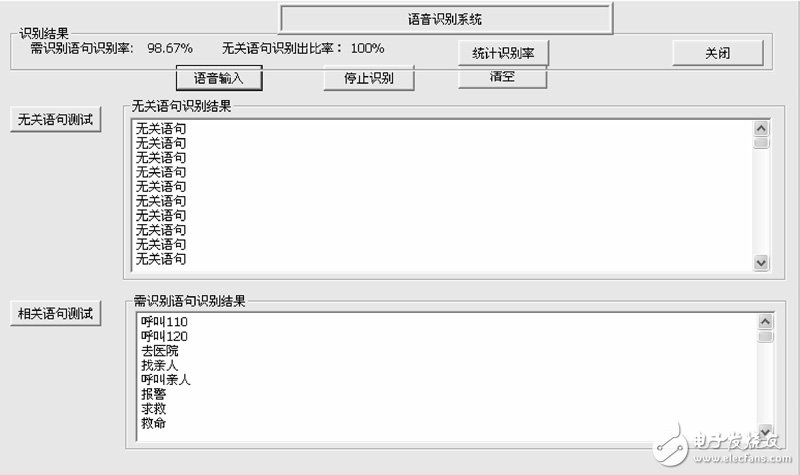
图6 系统实验界面
从实验测试结果可看出,对于识别10个需要识别的话语的识别率高达94.67%以上,具有较高的识别率,因而该语音识别系统较好达到了家庭监护机器人使用的要求。
3 结论
文中通过DSP、DMA和ARM Cortex-A8的并行处理,利用双缓冲的方法,在嵌入式Linux上实现了基于ATK的实时语音识别系统。该系统可以实时地实现语音识别,具有较高识别率,较快的响应速度。可以应用在家庭监护机器人及其相关领域中。
-
实时语音识别系统在家庭监护机器人电路设计2014-10-23 2201
-
智能机器人在家用医疗保健中的设计2009-11-28 3945
-
SPCE061A语音识别机器人应用方案2011-03-08 4654
-
会物体识别和语音识别的nao机器人2015-02-13 10742
-
【Aworks申请】家庭服务机器人2015-07-19 2094
-
【WRTnode2R申请】家庭智能监护机器人2015-09-10 1874
-
智能语音机器人2015-12-02 14256
-
请问电销机器人智能语音识别的原理是什么?2018-06-12 4380
-
AI语音智能机器人开发实战2019-01-04 6580
-
家庭智能小管家机器人资料分享!2019-10-09 3656
-
微信控制的家庭智能机器人(附语音聊天、人脸检测、自主巡航等)2020-09-30 3795
-
语音识别系统在智能家庭系统中的应用是什么?2021-05-31 2246
-
嵌入式语音识别系统中的电路设计是如何的2021-12-20 1817
-
语音识别系统在家庭监护机器人的实现2012-05-09 1668
-
德国计划开发情感识别系统实时反应的机器人2018-03-27 2100
全部0条评论

快来发表一下你的评论吧 !
