

打破定制加速器的桎梏:在边缘AI中拥抱灵活性
描述
先进计算技术如今已成为提升生产力和改变日常体验的普遍工具。以汽车领域为例,高级驾驶辅助系统(ADAS)具备处理大量计算密集型任务的能力,从摄像头数据预处理直到传感器融合和路径规划,而且这些均不影响车辆的正常行驶里程。
边缘计算方面的最新创新包括Wayve的LINGO-2,这是一个基础模型,将视觉、语言和行动联系起来,用以解释和确定驾驶行为。这类解决方案正推动汽车行业走向新的方向,其中车辆中的AI能够提供诸如直觉、语言响应界面、个性化驾驶风格以及协同驾驶等功能,从而增强自动驾驶体验。
在边缘计算的其他领域,AI笔记本电脑提供了诸多优势,从借助AI赋能的内容创作工具以提高生产效率,到能够在本地运行而无需与云共享用户数据的协同驾驶。这些笔记本电脑将需要比以往任何移动PC更强的AI性能;微软新推出的Copilot+PC就采用了GPT-4模型和40+TOPS的配置,同时具备轻薄设计和全天候续航能力。
边缘基础模型
AI达到这一能力水平并非因为程序员最终成功地将人脑转化为代码,而是研究人员成功地将云中可用的大量加速计算应用于通用模型,正如Rich Sutton在其《苦涩的教训》(The Bitter Lesson)论文中所讨论的那样。基于上述提到的GPT-4等通用基础模型进行微调的解决方案,正成为普及AI的首选方法。与其创建特定领域的算法,不如使用功能强大、可跨多个领域应用的模型,这些模型利用云资源与大量多模态数据进行训练,然后针对特定应用和设备进行微调。
为了适应边缘环境,这些经过调整的模型需要在更小、功能极具受限的设备上运行,这些设备具有严格的安全标准、有限的电源供应和不稳定的互联网连接。它们不仅要提供基本的推理能力,还要支持设备上的微调和终身持续学习。此外,它们还需要与维护最佳用户体验的关键日常功能共享系统级芯片(SoC),如用户界面、图像处理和音频处理。
然而,尽管在可用性能、热管理技术甚至是商业模式方面存在差异,边缘AI仍可借鉴AI在云计算中成功的理念:即从加速器硬件到AI框架的所有方面都使用通用方法。随着晶体管缩放和新封装技术的进步,计算量即便大幅增加也可轻松扩展。是以,为支持客户在边缘AI取得成功,Imagination同时采用了以下两种方案策略:
基于开放标准开发软件
- 提升通用计算加速器的硬件能力
基于开放标准开发软件
Imagination在边缘AI的交付中采取软件优先的方法,以最大化硬件的可编程性和灵活性。启用优化库等软件和工具包提供了一种机制,以实现最高效率和对调度及内存管理的严格控制。目前已经有一个不断增长的框架和库生态系统,它们以OpenCL后端为基础,加速上市时间,并提供了作为异构计算系统子集进行更高级优化和集成的机会。它涵盖了AI部署环境以及计算机视觉和其他通用计算库。
合作是成功的关键。去年,Imagination与其他领先科技公司一起,作为创始成员加入了UXL基金会,这是一个被称为与NVIDIA封闭CUDA语言相抗衡的开放、跨平台、供应商中立组织。该基金会正在开发oneAPI编程模型和DPC++ SYCL实现。通过使这一计划成为Linux基金会下真正的开源项目,UXL基金会为像Imagination 这样的公司提供了催化剂,将已经在高性能计算领域广泛应用的oneAPI标准的优势,扩展到边缘计算领域。这将在应对计算应用的程序快速开发和跨平台复用的挑战中发挥重要作用。
Imagination正通过UXL基金会积极参与并影响oneAPI标准的制定,同时我们也在为边缘平台开发和推出下一代计算工具和软件堆栈。我们与合作伙伴和客户紧密合作,鼓励更广泛地参与并采用这一标准。我们旨在为开发过程中的所有利益相关者,提供易于访问的适用于Imagination平台的工具包,这些工具包将提供符合当前边缘计算应用开发周期典型需求的“功能性到高性能再到最优”的工作流程,同时也利用构建和运行时目标独立性的优势。
提升通用计算加速器的能力
Imagination帮助客户在边缘AI领域取得成功第二个策略,主要通过保持硬件灵活性和可编程性的同时,向边缘设备注入更强的计算性能。目前,边缘计算加速通常在以下处理器类型中进行:
中央处理器(CPUs):SoC的传统控制中心和主要工作组件;CPU越来越具备AI能力,拥有一定程度的并行性(例如多核)并支持相关数据格式;它们可以根据需要卸载更专业的计算处理器。
数字信号处理器(DSPs):广泛应用于汽车、电信等多个市场,用于音频、视频、摄像头和连接性处理,最近还通过矢量处理支持AI应用。
图形处理器(GPUs):GPU本质上是可编程和通用的。虽然它们传统上仅用于图形加速,但近年来其并行性已应用于诸如超分辨率、点云处理和非机器学习算法等计算应用中,并且越来越多地采用低精度算术功能。
神经处理单元(NPUs):高度优化的领域特定加速器,专注于低精度算术,以有效处理深度学习算法训练中常见的密集矩阵乘法代码。
未来的问题是:这些处理器类型中哪一种为下一代边缘AI加速器提供了最佳基础?
这是Imagination擅长解决的问题。我们的工程师通过创造创新解决方案来解决技术难题,使客户能够成功。我们在四个市场中出货超过130亿颗芯片,产品范围涵盖GPU、CPU、AI IP以及软件。我们的工程团队在设计用于计算和AI的半导体技术方面拥有丰富的经验,从针对CNN风格工作负载优化的NNA产品线开始,目前该产品线已运用于多个汽车和消费市场的SoC中,例如玄铁TH1520 SoC。
尽管客户在NNA上取得了许多成功,但Imagination认识到边缘AI将需要开发新一代更灵活和可编程的NPU,或是新一代GPU加速器,这些加速器在保持能效的同时提供更强的计算性能。这与依赖通用而非过度定制化方法的原则相一致,正是这一原则使得AI在云端取得了成功,而这一目标的实现将得益于半导体市场上几个关键趋势的推动。
打破定制加速器(ASIC)的桎梏
首先,值得更详细地探讨为什么通用加速器比高度定制化的硬件更受欢迎。当前边缘AI的处理方式,特别是在注重性能的设备如汽车和笔记本电脑中,聚焦于NPU:这是一种高度优化的处理器,能在较小的面积或功耗预算内实现高效率。与传统的GPU张量核心相比,NPU具有更大的矩阵片规模,具有专门为神经网络加速设计的固定功能硬件,关注低精度数值格式,进行graph编译和优化以减少数据的搬运和增强数据的本地性。
低精度数字格式
半导体计算中关键趋势之一是,提升通用加速器(如GPU)计算性能的是低精度数字格式的激增。这些格式历来是NPU领域的专属,但现在在GPU等其他加速器中也越来越常见。像开放计算项目(Open ComputeProject,简称OCP, 这样的组织正开始推动从FP32到FP4及微缩比例(MX)兼容格式的标准化工作,这些格式适用于CPU、GPU、NPU等多种处理器。预期这些数字格式将从数据中心领域扩展到整个软件生态系统中。
先进工艺节点带来的机遇与挑战
此外,多年以来,半导体行业一直受益于摩尔定律:在相同硅片面积上每代性能的提升。英特尔、三星和台积电等晶圆厂,对于挖掘这种逻辑电路尺寸缩小带来的好处起到了根本性作用。先进工艺节点是通用加速器提升计算性能至边缘AI所需水平的关键之一。
然而,SRAM(静态随机存取存储器)被证明很难缩小。随着AI模型对性能、数据本地性和低延迟要求的提高,实际上任何给定处理器,特别是如NPU这样的领域特定加速器,对SRAM的需求反而增加了。未来的疑问是,我们是否真的能承受将如此昂贵的资源专门分配给仅在其功能需要时才激活的单一处理器?
与此同时,随着晶体管密度的增加,热管理问题比现在变得更加严峻。高度优化且能耗大的加速器加剧了这一挑战,在SoC内部形成了工作负载特定的热点,难以缓解。
然而,如果像CPU和GPU这样的通用加速器在保持能效的同时增加其计算能力,那么基于少量高效、通用、可扩展加速器的边缘SoC,将是解决先进工艺节点热管理挑战的一个有前景的方案。这种方法最小化了暗硅现象,为系统设计师提供了在整个核心中分布处理而非创建特定应用热点的机会,并保证了集成、系统和编程复杂度的可控性。
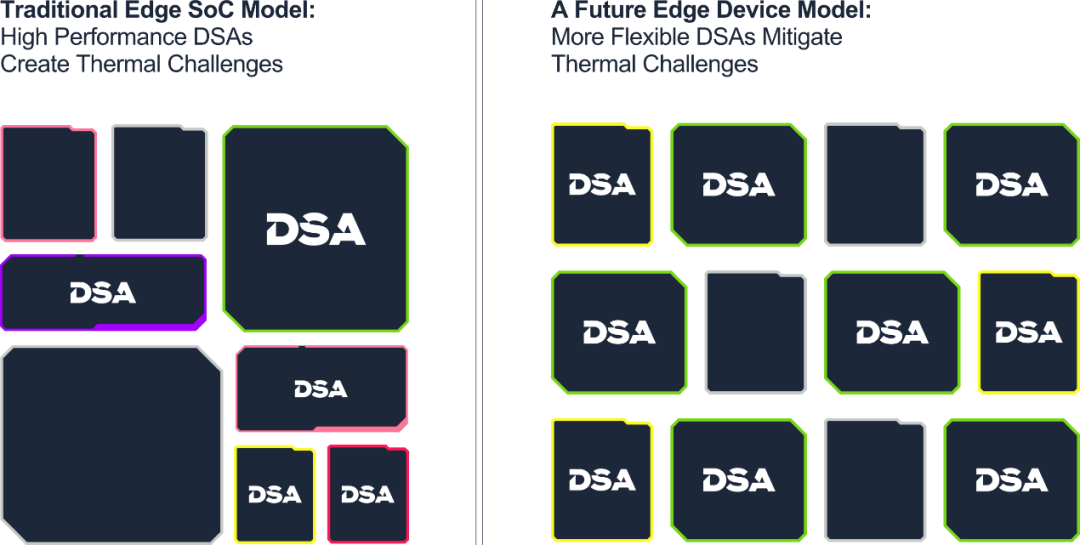
边缘AI的下一代技术
考虑到这些发展,基于GPU和RISC-V架构的下一代处理器正逐步成为提供高性能、低功耗且适用于通用目的的加速器,这是边缘AI所必需的。Imagination在边缘图形和计算技术领域处于世界领先地位。我们的GPU彻底改变了智能手机市场,并且从未停止开拓创新,比如生产出了首款能够在移动设备上实现的实时光线追踪的高效架构。随着GPU和RISC-V CPU成为实现边缘AI的首选处理器,我们的工程师正在开发客户及更广泛技术生态系统取得成功所需的技术解决方案。未来几个月将有确切内容发布。在此期间,如果:
您是一家开发具备AI能力SoC的半导体公司
您是对即将改变用户体验的技术感兴趣的原始设备制造商(OEM)
您是一家开发基于AI应用的软件公司
都可以通过与我们销售团队预约会议来提前了解Imagination的计算产品路线图。
-
当我问DeepSeek AI爆发时代的FPGA是否重要?答案是......2025-02-19 6555
-
FPGA+AI王炸组合如何重塑未来世界:看看DeepSeek东方神秘力量如何预测......2025-03-03 7730
-
实现汽车测功器应用的灵活性2009-10-06 3765
-
电源系统设计中灵活性和可配置性的好处2017-04-07 4084
-
硬件帮助将AI移动到边缘2019-05-29 2566
-
如何去提高电源管理的灵活性?2021-04-23 1617
-
开放式FPGA能否增加测试的灵活性?2021-05-11 1230
-
嵌入式Linux的灵活性2021-11-04 1326
-
嵌入式边缘AI应用开发指南2022-11-03 1484
-
ARM定制说明:在ARM上实现创新和更大的灵活性2023-08-23 645
-
什么是AI加速器 如何确需要AI加速器2022-02-06 6216
-
边缘设备中计算机视觉和语音的AI推理加速器应用2022-08-16 2041
-
康瑞电子讲解连接器的设计具备灵活性是关键!2022-12-28 658
-
OPSL 优势1:波长灵活性2024-07-08 1254
-
边缘计算中的AI加速器类型与应用2025-11-06 1195
全部0条评论

快来发表一下你的评论吧 !
