

Xilinx FPGA助力高性能SDN
FPGA/ASIC技术
描述
一些人可能认为,就具体效果而言,软件定义网络 (SDN) 受到了人们过多的关注。在 SDN 的早期,部署的出现源自于领先研究机构与快速定制其现有非 SDN 固件的硬件公司的共同不懈努力。尽管这些工作验证了 SDN 的理论,但概念证明阶段的 SDN 与专门针对全球精心策划架构的生产网络实施的 SDN 之间仍有很大差别。
在 Corsa Technology,我们与网络架构师和运营商一起制定了 SDN 的愿景。他们一遍又一遍地告诉我们,正确实施的 SDN 意味着您的网络架构将实时改变和适应流量模式和用户需求。这一灵活性以传统成本的一小部分实现了性能的大幅提升。
以这一理念作为指导原则,Corsa 将 SDN 定义为简单设计模式。很多其他公司也认同这一基本概念:将软件与硬件分离,通过开放接口进行通信,给予软件所有控制权(大脑)并让硬件(体力)尽可能地高性能。但是在 Corsa,我们从性能硬件的角度进一步认真研究了网络新世界秩序需要(图 1)。
我们提出的硬件定义与网络架构师的SDN愿景不谋而合。我们将其称之为“精益硬件”:规模适合部署,具有超高性能,并且灵活性和可扩展性极高,即便是最大网络流量,也能轻松应对。如果仅需要约 10% 的功能,为何要购买庞大且昂贵的大型机器?相反,如果硬件的灵活性和可编程性足够,则您可以对其进行调整和修改以满足特定网络需求。无论是在 WAN 边缘还是园区边缘,同一精益硬件可以在您的网络中肩负着各种元件的作用。
正确实施的 SDN 使您可以摆脱本地、苛刻、固定式、复杂、专有硬件和软件的束缚。简单设计模式中 Corsa 的性能 SDN 可帮助您通过灵活、高性能、可扩展硬件平台实现软件定义网络。
重重压力下的硬件设计
这种灵活的 SDN 网络概念对于网络硬件设计必须如何变化有着直接影响。得益于新的创新,SDN 网络架构可能快速变化,因此 SDN 硬件解决方案的上市时间比以往变得更为重要。
硬件平台是系统设计、板级别设计、机械设计与 SoC 选择或设计的组合体。通常,在 SDN 等新兴市场中,SoC 无法以商用芯片的方式提供,并且硬件解决方案需要采取 ASIC、NPU 或 FPGA 途径得以实现。对于 SDN,鉴于其网络变化的节奏,我们很难做出决策。
使用定制 ASIC,通常需要三年时间才能完成网络硬件的设计、构建与实现工作:六个月的时间进行硬件选型和架构;一年时间进行 ASIC 设计;四个月时间进行开发板设计和制造;十二个月时间进行软件集成和测试。如果所有流程一次性通过,便可实现上述结果。
对于 Corsa,这种时间优先的原型设计方式不可接受。
另一方面,网络处理单元 (NPU) 是一种专为网络应用而设计的可编程商用芯片。尽管它们的确具备高灵活性并且可以重新编程,但它们的带宽有限,这对于大规模交换功能是一大障碍。它们还提供了复杂的专有编程模型,很难更改。由于 SDN 需要全面的灵活性、高性能和大规模,我们同样排除了 NPU。
为通过适当的解决方案满足 SDN 上市时间需求,Corsa 选择了 FPGA,并且利用赛灵思 Virtex®-7 器件的灵活性,用六个月时间开发了一种解决方案。
利用 FPGA 进行设计,我们可以并行进行以下工作(请参见图 2):
• 系统架构(四个月)
• RTL 代码编写(六个月)
• 软件设计(六个月)
•PCB 设计和制造(四个月)
一个重要的事实是,我们可以在 FPGA 平台上即时修改 RTL,同时各种设计活动继续进行并针对性能和规模进行优化。
增量设计的优势
我们采用基于一系列 FPGA 的 Slice 来开发我们的系统架构。这种方法能够开发出具有最小可行特性的单个 Slice,同时为全特性集留下预算容量。不需要像通过基于 ASIC 或 NPU 的方法那样预先全面设计整个架构,然后再迁移到 RTL 中。因此,我们可以与系统并行开发工作码,并能够更加快速地交付给领先客户。
并非每一个用例或应用都需要所有功能。通过利用 FPGA 的硬件级可编程性,我们可以创造更小的 RTL 实现,这些实现与特定用例所需要的功能集和性能相匹配。在设计期间甚至是在现在,可以取代 10G 和 100G MAC,将资源从交换架构转移到分类引擎,以及添加或移除用于特定协议的硬件加速功能。相比 ASIC 或 NPU ,这一灵活性有助于减少门数,进而缩减物理封装尺寸。它还使我们可以回应那些一旦客户参与就会必然出现的无法预见用例。序列设计通常会导致出现先有鸡还是先有蛋的定义难题,即:完全指定 ASIC 或 NPU 要求,但是在产品到达实验室之前,没有详细的客户参与。
SDN 交换设计
SDN 表示就有关如何构建网络设备方面与传统观念分道扬镳。SDN 的一项关键要求是,较之于传统的固定功能硬件,可重编程硬件在构建和销售方面极富竞争力。发挥这一理念,SDN 为网络推出方式带来革命性变化。传统网络设计的原理现在可以显著改进。
以下是激起人们对 SDN 的关注的三个主要因素。
1. 用于解决新网络问题的新网络协议的速度
一项新的网络协议至少需要三年时间才能完成其标准化流程。还需要两到三年时间在硬件中实现,然后才能最终部署。通过 SDN,新协议是通过软件实现,并且几乎是立即部署在安装的系统中。这将周期从五年降至短短数月。
2. 基于开放硬件平台,创新网络创意的精英化
标准更注重策略而非技术。经各方争执和修改,最终的规范是代表各方立场的妥协版本。在此过程中,实力较小的一方通常被忽略或无视。通过 SDN,任何人都可以制定协议并供行业使用。如果运营商看到优势,协议便会繁荣发展,否则便会消亡。要让最佳技术理念取胜,这种“适者生存”的方法是更加可靠的选择过程。
3. 针对尚未开发的协议,通过现场升级来复用基础设施
每年在新网络设备方面的花费达到了数十亿美元。这些设备的生命周期是三到五年。在购买设备时尚未开发的任何协议或功能通常必须等待三到五年,直到设备更新后方可使用。通过 SDN,新协议很有可能能够立即部署在现场的设备中。将设备的生命周期延长到超过五年已成为现实,同时为即将出现的新功能提供即时可用性。
FPGA 对比 ASIC
为增强竞争力,SDN 交换要求高性能、灵活性和大规模,这些要求都以价格合理的套装形式提供。传统观念认为,需要固定功能 ASIC 才能构建此类有竞争力的系统。这在 28nm 技术节点出现之前的确如此。但是,在 28nm 及之后,
FPGA 已经达到了颠覆性规模。它们不再是用于胶合逻辑的大型 PLD 器件。相反,它们终于实至名归,不负上世纪九十年代早期赋予它们的“现场可编程门控阵列”这一称号。
FPGA 技术现在的性能、灵活性和可扩展性如此之高,足以满足网络架构师所需的 SDN 属性列表要求。首先 IP 库、存储器和 I/O 等一些关键方面凸显了 FPGA 技术会给 SDN 带来明显优势。
就 IP 而言,已经使用 FPGA 中的标准单元实现了基本网络功能。其中有大型模块,包括数十个 10/100G 以太网 MAC、PCIe® 接口、Interlaken 接口、嵌入式 ARM® 内核和 DDR3 接口。这些 IP 核为 SDN 交换机设计师提供了大量预先设计和预先优化的模块。
在网络设备中,规模很关键。有助于形成规模的一个特定方面就是存储器,对于包交换,需要大量小型存储结构。这些存储结构提供的带宽和容量,可支持 TB 级或更多流量输入输出处理单元。FPGA 存储器进行了优化且占用芯片面积最小,因此有助于实现 TB 级路由规模。
就 I/O 而言,网络需要大量串行解串器接口,每个接口均包含大量模拟组件、功率放大器和数字逻辑。I/O 专用芯片面积可能过多。FPGA 技术具有卓越的 I/O 模块,就其芯片面积占用而言,能够与网络 ASIC 媲美。
在对芯片面积增加了上述促进因素以后,显然可以看到,基础 FPGA 技术以最佳方式至少将 ASIC 的复杂度降低一半,另外 50% 或更低的芯片面积可考虑用于 CLB 或标准单元。鉴于销量相对较低的网络 ASIC 业务的价值定价(10 万套被视为大数量),任何差价都会水落石出。
这对于 SDN 则意味着我们突然拥有了一个现场可编程的高度可编程平台,以支持先前需要百万美元 NRE 和巨大 ASIC 开发的多种系统。这类似于在所有书籍需要用羽毛笔和墨水瓶书写一次的时代发明了印刷术。
Corsa 的性能 SDN
在 Corsa,我们认识到,网络市场中有两种颠覆性的趋势。第一种是对可编程网络元件的渴望;第二种是 FPGA 作为固定功能芯片替代品的出现。因此我们开始了设计理想的 SDN 交换机的任务。图 3 中显示了此类设备的系统架构。
高性能 SDN 交换机有两个组件。其具有性能很高的包分类引擎,这是交换机结构的先驱。分类器在 OpenFlow 规范中定义为一系列匹配操作表,这些操作表检查包报头并根据包中各种协议的源和目标字段来制定转发决策。一旦制定了转发决策,包进入第二个组件:能够缓冲和交换 TB 级数据的高速交换机结构。
这些数据速率所必需的带宽和容量对于性能 SDN 交换机的物理架构有着显著影响。这些交换机需要 100ms 或更多的包缓冲,以在大量聚合点中(比如在 WAN 或园区边缘)存在流量堵塞的情况下保持高吞吐量。对于 640 Gb 的前面板带宽,可用以下计算得出:
640 Gbps * 0.1 s = 64 Gb 包缓冲存储器
对于 Corsa,这是使用 FPGA 脱颖而出的地方。实现性能 SDN 所需要的存储密度的唯一存储技术是 DDR3 存储器。在 28nm 中,DDR3-1600 是最快速的存储器。为了以全线路速率写入并读取每个包,我们需要 1.28Tb 的存储带宽。在考虑了访问效率低下这一因素之后,单个 DDR3 DIMM 模块能够处理约 64Gb 的流量。这意味着我们需要 10 个 DDR3 DIMM 模块才能为 Internet 规模的 SDN 交换机提供包缓冲。
由于单个 FPGA 无法托管如此多的 RAM,因此导致我们立即通过每个 FPGA 大约三个 DIMM 来寻求分布式架构。我们随后增加了额外的内存容量和带宽以存储 OpenFlow 流水线的包分类数据,如 IPv4 地址、MAC 地址、隧道 ID 等。这为我们带来了每个流水线两个 FPGA 的通道实现方案(每个流水线六个 DDR3 DIMM)。流水线通道与通过架构 FGPA 构建的定制交换机结构绑定在一起,并且控制层通过具备 PCIe 3.0 连接的 Xeon 处理器绑定到包转发引擎(图 4)。
这种设计为我们提供了大量门控,海量的存储带宽和容量以及超高速的控制层连接。利用 OpenFlow 的灵活性,Corsa 构建了用于 Internet 协议规模的路由器、MPLS 交换机、100-Gig 防火墙和 DPI 负载均衡器的线路速率处理引擎,以及众多其他网络用例,绝对无需修改硬件架构,且不影响性能。我们看到网络功能虚拟化 (NFV) 服务链的出现令人有些满意;网络服务报头和协议仍在草拟之中。
规模、性能和灵活性
可编程网络是未来之路。网络运营商从服务速度、基础架构重用及其通过 DevOps 管理复杂性的能力等方面看到了优势。在对可编程网络元件新兴需求的同时,FPGA 正将性能和规模推到全新的高度。在 Corsa,我们认识到这一交会点并在我们的 SDN 硬件平台中使用 FPGA 来实现 SDN 规模、性能和灵活性。
在固定功能厂商继续多年来等待标准、制造 ASIC 并延迟其产品上市的老路的同时,Corsa 能够立即通过我们交付的新系统部署这些新协议。更好的是,由于使用赛灵思 FPGA,我们可以将以前交付的系统升级以支持未来开发的协议。
图 1– SDN 将包转发数据层与控制层隔离。
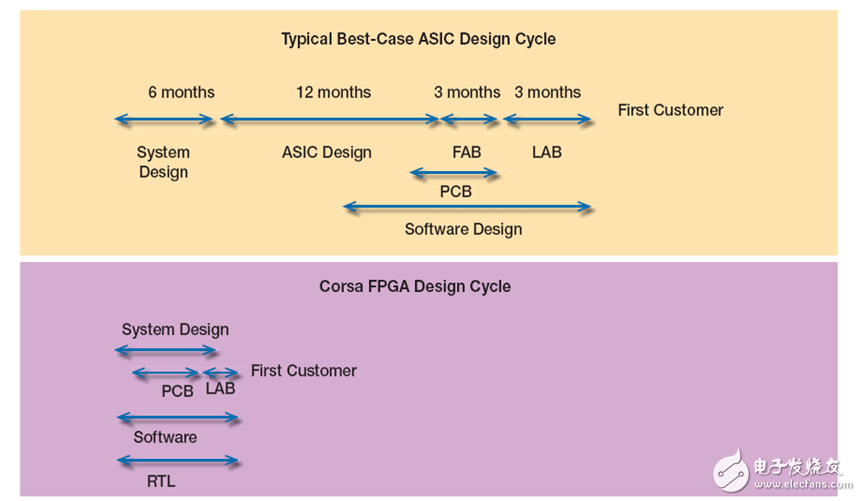
图 2 – Corsa 的基于 FPGA 的设计周期比典型 ASIC 设计周期明显缩短。
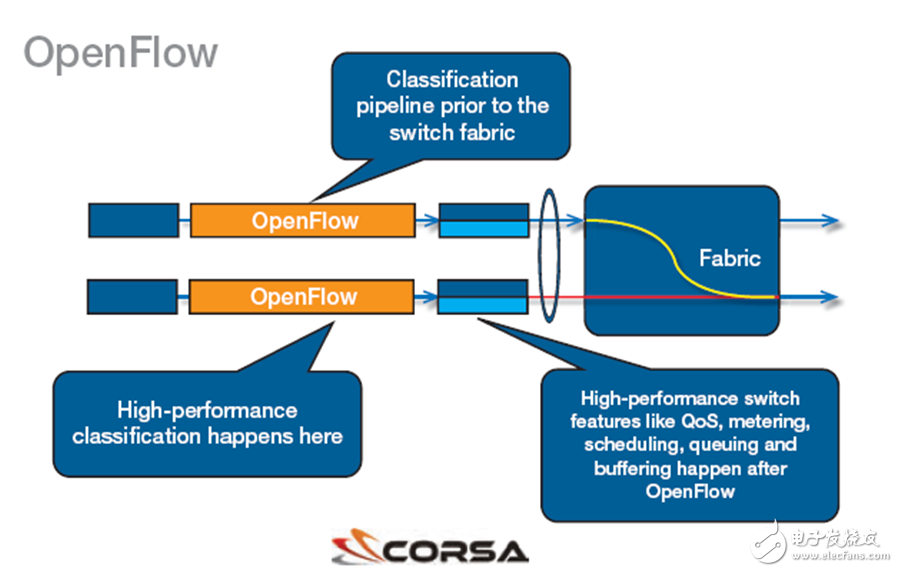
图 3 – 高性能 SDN 交换机的两个主要元件元素是能够进行包分类的引擎和快速交换机结构。
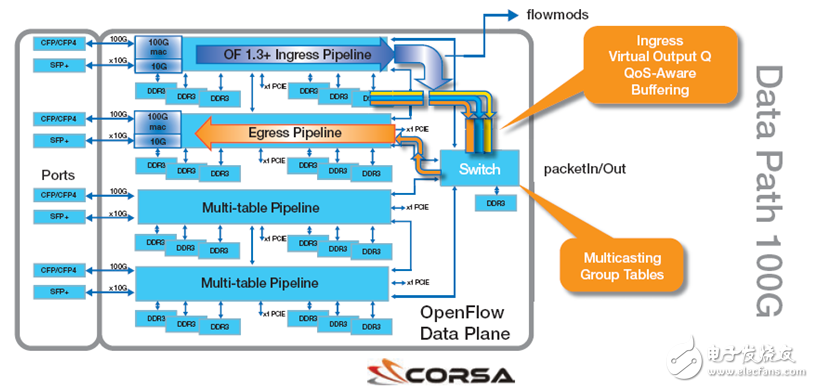
图 4 – Corsa 的高带宽和高容量系统架构具有基于 FPGA 的流水线和交换机结构。
-
Xilinx 7系列FPGA的时钟结构解析2023-08-31 4747
-
FPGA构建高性能DSP2011-02-17 3298
-
Xilinx FPGA在高性能SDN对的应用2019-06-20 3611
-
Xilinx与台积电合作采用16FinFET工艺,打造高性能FPGA器件2013-05-29 1322
-
VadaTech面向17款高性能FPGA的Xilinx套件:设计、功耗和性能领先2017-02-09 408
-
FAST:基于FPGA的SDN交换机开源项目(二)2017-11-16 4579
-
基于FPGA的高性能计算 pdf2018-01-30 1175
-
Xilinx FPGA对数字信号处理的性能2018-06-22 1401
-
极目智能发布旗下最新车规级视觉ADAS解决方案,该系统搭载Xilinx高性能FPGA平台2018-08-07 2457
-
Xilinx的Artix-7 FPGA AC701评估套件专门支持高性能系统2018-09-26 2855
-
华为选择Xilinx 助力FPGA加速云服务器2019-05-05 1943
-
Xilinx 7系列FPGA高性能接口与2.5V/3.3V外设IO接口设计2023-05-15 6815
-
为新时代高性能航天级Xilinx FPGA供电2023-09-14 551
-
Xilinx FPGA串行通信协议介绍2025-11-14 2939
-
AMD UltraScale架构:高性能FPGA与SoC的技术剖析2025-12-15 852
全部0条评论

快来发表一下你的评论吧 !
