

基于CPU的大型语言模型推理实验
描述
随着计算和数据处理变得越来越分散和复杂,AI 的重点正在从初始训练转向更高效的AI 推理。Meta 的 Llama3 是功能强大的公开可用的大型语言模型 (LLM)。本次测试采用开源 LLM 的最新版本,对 Oracle OCI 上的 Ampere 云原生处理器进行优化,最终证明提供了前所未有的性能和灵活性。
在超过 15T 数据标记上进行训练,Llama3 模型的训练数据集比 Llama2 的训练数据集大 7 倍,数据和规模均提升到了新的高度。Llama3 的开放访问模型在语言细微差别、上下文理解以及翻译和对话生成等复杂任务方面表现都很出色。作为正在进行的 Ampere llama.cpp优化工作的延续,企业现在可以使用基于 Ampere 的 OCI A1 形状,体验最先进的 Llama3 性能。
Ampere架构
Ampere 云原生处理器优化了功耗,提供行业领先的性能、可扩展性和灵活性,帮助企业有效地处理不同的工作负载的同时,适应应用程序越来越高的要求,以及不断增长的数据量和处理需求。通过利用云基础设施进行水平扩展,支持处理大规模数据集并支持并发任务。通过单线程内核消除嘈杂邻居效应、更高的内核数量提高计算密度以及降低每个计算单元的功耗从而降低整体 TCO 。
Llama3 vs Llama2
随着对可持续性和功耗的日益关注,行业正趋向于选择更小的 AI 模型,以实现效率、准确性、成本和易部署性。Llama3 8B 在特定任务上可提供与 Llama2 70B 相似或更好的性能,因为它的效率和较低的过拟合风险。大型 100B LLM(例如 PaLM2、340B)或闭源模型(例如 GPT4)的计算成本可能很高,且通常不适合在资源受限的环境中进行部署。高昂的成本,以及由于其尺寸大小和处理要求的复杂,部署起来可能很麻烦,在边缘设备上尤为明显。Llama3 8B作为一个较小的模型,将更容易集成到各种环境中,从而能够更广泛地采用生成式 AI 功能。
Llama3 8B的性能
在之前成功的基础上,Ampere AI 的工程团队对llama.cpp进行了微调,以实现 Ampere 云原生处理器的最佳性能。基于 Ampere 的 OCI A1 实例现在可以为 Llama 3 提供最佳支持。这个优化的 Llama.cpp 框架在 DockerHub 上免费提供,二进制文件可在此访问:
在基于 Ampere 的 OCI A1 Flex 机器上进行的性能基准测试表明,即使在较大批量的情况下,Llama 3 8B 型号的功能也令人印象深刻。在单节点配置下,吞吐量高达每秒 91 个TokenTokens,推理速度凸显了 Ampere 云原生处理器对 AI 推理的适用性。OCI 区域的广泛可用性确保了全球用户的可访问性和可扩展性。
下列图表详细介绍了具有 64 个 OCPU 和 360 GB 内存的单节点 OCI Ampere A1 Flex 机器的关键性能指标,并发批量处理大小为 1-16,输入和输出 TokenToken大小为 128。Llama 3 8B 的性能与 Ampere A1 上的 Llama 2 7B 相当。
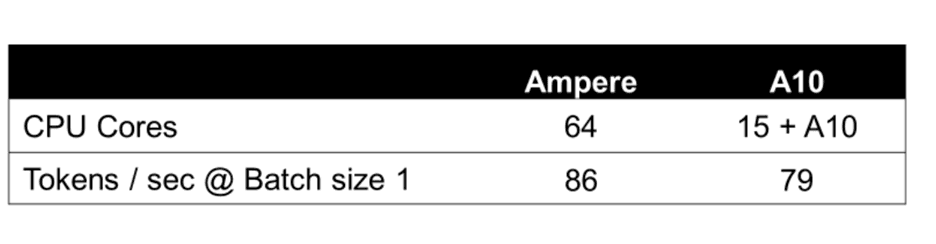
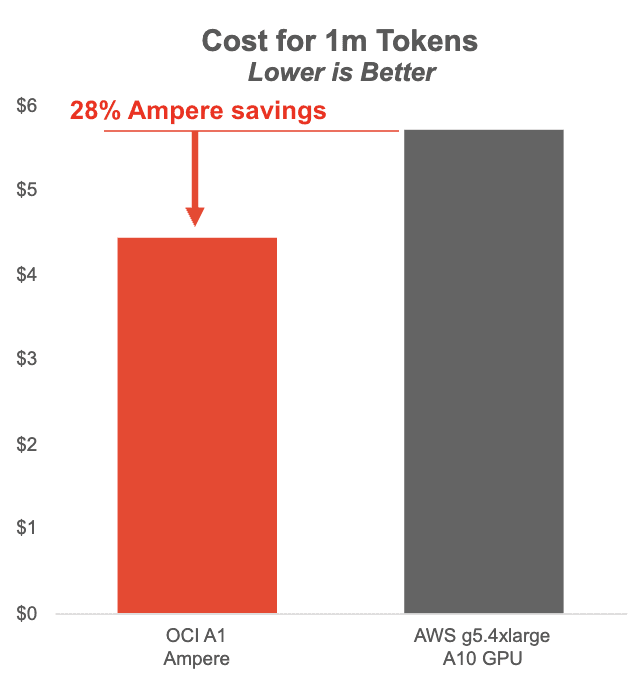
下图显示了在基于 Ampere 的 OCI A1 实例上运行的 Llama3 8B 与 AWS 上的 NVIDIA A10 GPU 的每百万个 Token 的成本。Ampere A1 实例在批量大小为 1-8 时可节省大量成本,同时提供更流畅的用户体验。
Ampere的无 GPU AI 推理解决方案在小批量和低延迟应用方面处于领先地位。
每秒Token数 (TPS):每秒为 LLM 推理请求生成的Token数。此度量包括首次Token的时间和Token间的延迟。以每秒生成的Token数报告。
服务器端吞吐量 (TP):此指标量化服务器在所有并发用户请求中生成的Token总数。它提供了服务器容量和效率的汇总度量,以处理跨用户的请求。此指标是根据 TPS 报告的。
用户侧推理速度 (IS):此指标计算单个用户请求的平均Token生成速度。它反映了服务器的响应能力,从用户的角度来看,它提供了一定级别的推理速度。此指标是根据 TPS 报告的。
实际操作
Docker镜像可以在 DockerHub 上免费获取,llama.aio 二进制文件可以在 Llama.aio二进制文件中免费获取。这些图像在大多数存储库(如 DockerHub、GitHub 和 Ampere Computing 的 AI 解决方案网页 )上都可用。
Ampere 模型库(AML)是由 Ampere 的 AI 工程师开发和维护的 Ampere 动物园模型库。用户可以访问 AML 公共 GitHub 存储库,以验证 Ampere Altra 系列云原生处理器上 Ampere 优化的 AI 框架的卓越性能。
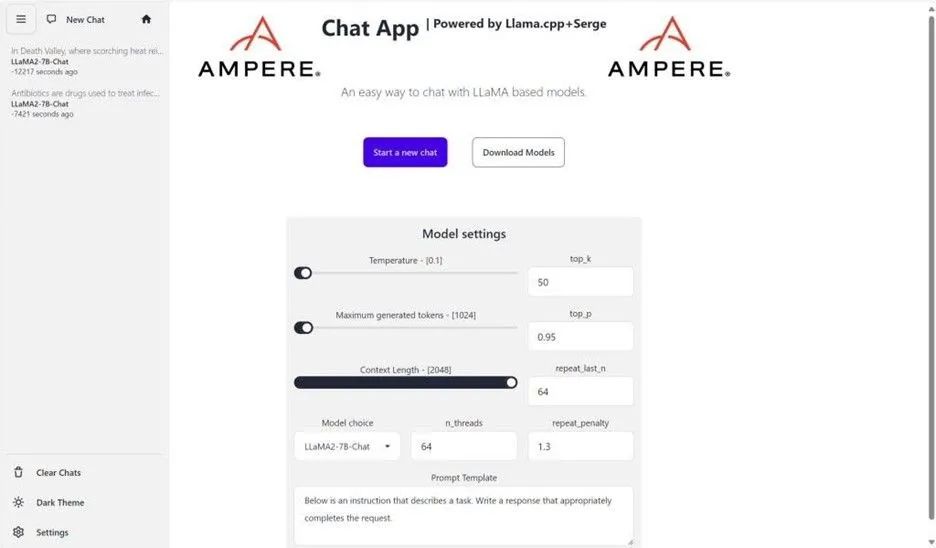
要简化部署过程并测试性能,请参阅 Ampere 提供支持的 LLM 推理聊天机器人和 OCI 上的自定义市场图像,该图像提供用户友好的 LLM 推理llama.cpp和 Serge UI 开源项目。这使用户能够在 OCI 上部署和测试 Llama 3,并体验开箱即用的部署和即时集成。以下是 OCI 上 Ampere A1 计算的 OCI Ubuntu 22.04 市场镜像的 UI 一瞥:
后续步骤
持续创新是 Ampere 一直以来的承诺,Ampere 和 Oracle 团队正在积极致力于扩展场景支持,包括与检索增强生成 (RAG)和 Lang 链功能的集成。这些增强功能将进一步提升 Llama 3 在 Ampere 云原生处理器上的能力。
如果您是现有的 OCI 客户,则可以轻松启动 AmpereA1 LLM 推理入门映像。此外,Oracle 还提供长达 3 个月的 64 个 Ampere A1 核心和 360GB 内存的免费储值,以帮助验证 Ampere A1 flex 形状上的 AI 工作负载,储值将于 2024 年 12 月 31 日结束。
在基于 Ampere 的 OCI A1 实例上推出 Ampere 优化的 Llama 3 代表了基于 CPU 的语言模型推理的里程碑式进步,具有无与伦比的性价比、可扩展性和易于部署等优势。随着我们不断突破 AI 驱动计算的界限,我们邀请您加入我们的行列,踏上探索和发现的旅程。请继续关注更多更新,我们将探索使用 Ampere 云原生处理器解锁生成式 AI 功能的新可能性。
-
LLM推理模型是如何推理的?2026-01-19 922
-
大模型推理显存和计算量估计方法研究2025-07-03 883
-
大语言模型开发框架是什么2024-12-06 1291
-
使用vLLM+OpenVINO加速大语言模型推理2024-11-15 2617
-
LLM大模型推理加速的关键技术2024-07-24 3614
-
如何加速大语言模型推理2024-07-04 2293
-
【大语言模型:原理与工程实践】大语言模型的评测2024-05-07 1934
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 890
-
HarmonyOS:使用MindSpore Lite引擎进行模型推理2023-12-14 475
-
大型语言模型的逻辑推理能力探究2023-11-23 2417
-
大型语言模型的应用2023-07-05 3090
-
基于Transformer的大型语言模型(LLM)的内部机制2023-06-25 2758
-
大型语言模型有哪些用途?大型语言模型如何运作呢?2023-03-08 9706
-
大型语言模型有哪些用途?2023-02-23 6359
全部0条评论

快来发表一下你的评论吧 !
