

基于高光谱数据的典型地物分类识别方法研究
电子说
描述
一、引 言
随着光谱学的不断发展,人们对地物光谱属性、特征的认知也在不断深入,许多隐藏在狭窄光谱范围内的地物特性逐渐得以发现。高光谱数据具有光谱范围广、光谱分辨率高、数据量大等特点,更容易获取地物的局部精细信息,对光谱细节特征具有良好的表现能力。自从高光谱技术诞生以来,已有大批学者在农作物识别与分类、土壤重金属污染监测、植被识别与分类等高光谱分类领域进行广泛研究。如何探究不同样本间光谱特征差异以及提高分类识别精度是当前高光谱分类领域需解决的重要问题。
针对上述科学问题,诸多学者分别开展了基于对原始光谱数据进行光谱变换、平滑等预处理技术,然后通过主成分分析、支持向量机等传统方法应用于高光谱分类识别研究。传统方法可以应用于高光谱分类识别研究,但预处理方法有很多种,如何选择和组合这些方法会对分类结果产生很大影响,由此造成的耗时长、分类精度较低等问题一直难以解决。
随着数据集规模的增加和人工智能(AI)快速的发展,机器学习(ML)在各个科学领域的应用越来越流行。深度学习作为机器学习领域中一个新的研究方向,近年来也逐渐应用于光谱分类、光谱检测等领域中。
随着成像光谱仪器的广泛应用,利用光谱数据进行物质分类与识别已经成为一项重要的研究内容,研究不同分类算法对最终的目标识别准确度具有重要意义。目前现有研究中主要分为传统方法和深度学习方法,传统方法存在耗时长、分类精度较低等问题,深度学习方法能够简化预处理步骤,取得较高精度,但大多数研究只进行单次训练,并没有针对错分样本进行精细研究,很难从光谱特征分析的角度解释分类结果。首先,利用连续投影算法(SPA)进行基础波段筛选,探究特征波段对原始光谱的信息承载能力,由此探究不同地物间光谱特征的差异。
二、实验数据与分析
2.1研究区域与样本
本次实验所选区域为黑龙江省双鸭山市友谊农场,粮食作物有大豆、玉米、水稻等,经济作物有甜菜、葵花籽、白瓜籽、烤烟等。测量地物为玉米、大豆和水稻,其中5月由于播种时间较短,玉米、大豆在土壤中属于刚出芽的状态,因此将5月的玉米和大豆样本划分为裸土类别。共选取697个样本,其中大豆204个样本、玉米190个样本、水稻40个样本、裸土263个样本。
2.2 仪器设备与采集方法
本次测量可使用莱森光学便携式地物光谱仪,其光谱测量范围覆盖近紫外-可见光-近红外波段。光谱测量在野外进行,选择地表覆盖均匀且场地最短边长度不小于50m的人工或天然场地为本次反射率测量场地。对基本采样单元采用十字五点采样法进行光谱采集。测量了大豆、玉米、水稻和裸土的反射率光谱并拍照记录各类地物表面状态,如图1所示。测量时,光谱仪探头距离地物1m,因此采集到的大豆、玉米光谱为叶片和土壤的混合光谱,水稻光谱为叶片和水体的混合光谱。

图1 4类地物表面状态。(a)大豆;(b)玉米;(c)水稻;(d)裸土
2.3光谱预处理
对采集到的4类地物原始光谱数据进行分析,如图2所示。波长范围在350~1800nm内,各个地物光谱曲线较为平滑,没有明显的光谱噪声,在波长为1800nm附近存在严重的噪声,这是由于在波长为1800nm处存在水汽吸收通道,与地物的含水量有关。此外,由于测量在野外进行,天气环境和操作的影响导致在波长为1800nm之后的光谱信息有较大的波动且含有噪声数据。如果采用全波段光谱数据进行后续分析处理,会对所建分类模型的精度产生极大影响,导致模型不可靠。因此,选择采用波长范围在350~1800nm的光谱数据进行相关分析,为了简化传统方法采用一些预处理步骤,不再对光谱数据进行其他变换,直接利用截取后的光谱数据进行后续分析处理。
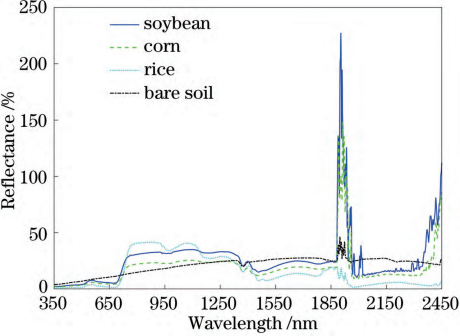
图2 350~2500 nm 四类地物平均反射率光谱曲线
2.4光谱特征分析
波长范围在350~1800nm的4类地物光谱数据,如图3所示。由图3可知,大豆、玉米和水稻等3种地图2350~2500nm四类地物平均反射率光谱曲线物的反射光谱曲线走势一致,同其他绿色植被一样,在波长为670nm的红光波段有一处吸收带,其反射率较低;在波长为550nm的绿光波段有一个明显的反射峰;在波长为700nm处反射率急速增高,至波长为1100nm的近红外波段反射率达到高峰,这是植被的独有特征;在波长为1300nm之后,因绿色植物含水量的影响,吸收率增大,反射率大大下降,在水的吸收带形成低谷。在部分波段范围内,3种地物的光谱曲线存在一些差异,例如波长范围在450~650nm内,水稻的光谱反射率最低,这是由于测量的水稻光谱为叶片和水体的混合光谱,水的反射率较低。大豆和玉米在整个波段范围内光谱反射率相近,二者难以区分。裸土的光谱曲线比较平滑,没有明显的峰值和谷值,但在整个波段范围内,裸土的反射率与其他3种地物有较大部分的重合,容易出现混淆的现象。
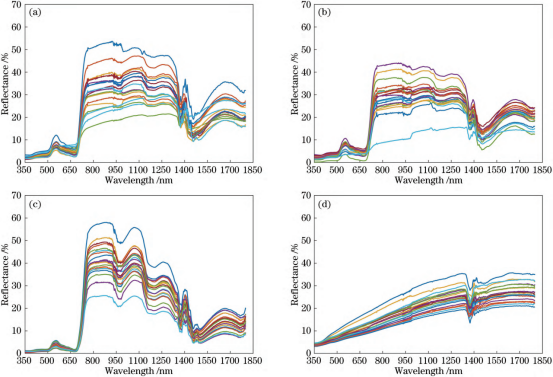
图3 350~1800nm四类地物部分样本光谱曲线(20条)。(a)大豆;(b)玉米;(c)水稻;(d)裸土
结果与讨论
3.1数据集划分
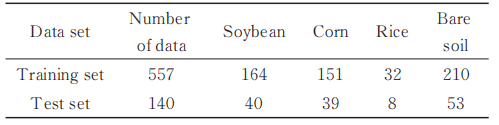
本次实验将数据集按8∶2划分为训练集和测试集,如表1所示,各个样本随机选样。
表 1 数据集统计
3.2特征波段选取
高光谱数据一些相邻波段之间存在着较强的相关性,导致光谱数据包含大量的冗余信息,如果直接将原始光谱数据输入到深度学习模型,可能会导致模型出现过拟合现象,严重影响模型的处理速度。因此,选择使用SPA对原始光谱数据进行特征波段筛选,通过筛选后的少量波段信息承载原始高维信息。
3.3 SPA原理
SPA是前向特征变量选择方法。SPA利用向量的投影分析,通过将波长投影到其他波长上,比较投影向量大小,以投影向量最大的波长为待选波长,然后基于矫正模型选择最终的特征波长。SPA选择的是含有最少冗余信息及最小共线性的变量组合。该算法简要步骤如下:记初始迭代向量为xk()0,需提取的变量个数为N,光谱矩阵为J列。
1)任选光谱矩阵的1列(第j列),将建模集的第j列赋值给xj,记为xk()0。
2)将未选入的列向量位置的集合记为s:
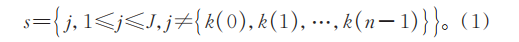
3)分别计算xj对剩余列向量的投影:
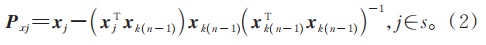
4)提取最大投影向量的光谱波长:
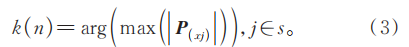
5)令xj=Px,j∈s。6)n=n+1,若n
最后,提取出的变量为{xk( )n=0,1,⋯,N-1}。对应每一次循环中的k(0)和N,其中最小的均方根误差(RMSE)对应的k(0)和N就是最优值。一般SPA选择的特征波长分数N不能很大。
3.4 特征波段集合
利用SPA,根据RMSE最小化原则,选出最能有效区分不同地物类型的特征波段,如图4所示。
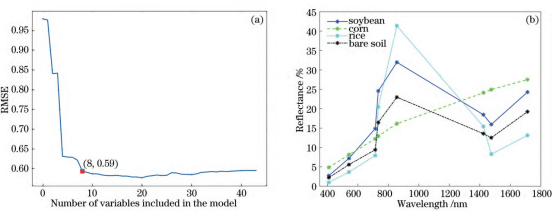
图4SPA特征波段选择结果。(a)RMSE;(b)平均光谱反射率
共选择8个波段,分别为410nm、542nm、714nm、734nm、856nm、1423nm、1475nm、1712nm。各类地物样本点在不同特征波段组合方式下的分布情况能够反映出各类地物在不同波段上的特征,可以初步判断所筛选的特征波段能有效区分各类地物。以4类地物在410nm波段和其他波段相互组合为例,如图5所示,4类地物都表现出了不同特征:其中大豆和玉米的样本点在各个波段上分布都较为分散,且出现大量交集,说明这两种地物的光谱特征相近,仅凭筛选特征波段无法实现有效区分;水稻和裸土的样本点出现聚集现象,其中水稻的样本点与玉米的样本点有小部分重合,裸土的样本点与大豆的样本点有小部分重合,在分类时容易混淆。总体来看,筛选出的特征波段能够有效代表4类地物的特征信息,可以初步区分部分地物样本,但效果并不理想,尤其是难以区分大豆和玉米。因此,需利用不同分类识别方法开展进一步研究。
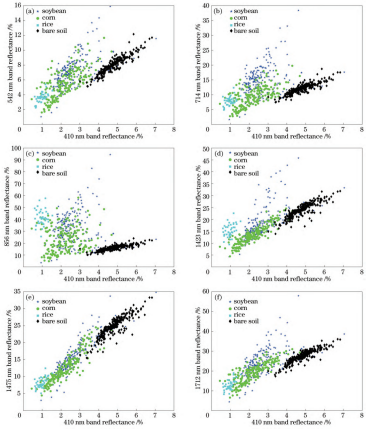
图5地物样本点分布。(a)410nm和542nm;(b)410nm和714nm;(c)410nm和856nm;(d)410nm和1423nm;(e)410nm和1475nm;(f)410nm和1712nm
推荐:
地物光谱仪iSpecField-HH/NIR/WNIR
地物光谱仪是莱森光学专门用于野外遥感测量、土壤环境、矿物地质勘探等领域的最新明星产品,独有的光路设计,噪声校准技术、可以实时自动校准暗电流,采用了固定全息光栅一次性分光,测试速度快,最短积分时间最短可达20μs,操作灵活、便携方便、光谱测试速度快、光谱数据准确,广泛应用于遥感测量、农作物监测、森林研究、海洋学研究和矿物勘察等各领域。

审核编辑 黄宇
-
基于贝叶斯分类研究肌肉动作模式识别方法2010-02-22 1233
-
基于最小l_1稀疏图表学习分类的图像识别方法研究2017-01-07 782
-
基于无人机高光谱不同高度的地物快速识别研究2021-09-16 2487
-
高光谱成像技术如何进行地物识别?2022-01-05 2134
-
高光谱压缩成像方法研究2022-12-28 1534
-
地物光谱仪在地物分类中的应用2023-03-09 741
-
地物光谱匹配模型研究2023-07-07 1442
-
地物光谱仪在树种识别和草原研究中的应用2023-07-25 1253
-
地物光谱仪:地物的反射光谱与地物波谱特性2023-08-22 2070
-
基于特征谱带的高光谱遥感矿物谱系识别2023-10-13 3176
-
不同地物分类方法在长江中下游典型湖区应用对比分析2024-05-31 1217
-
基于无人机高光谱遥感的荒漠化草原地物分类研究1.02024-06-12 1333
-
基于无人机高光谱遥感的荒漠化草原地物分类研究2.02024-06-17 1875
-
一种混合颜料光谱分区间识别方法2024-12-02 1118
-
基于地物光谱仪的稻田秧苗及稗草的早期识别2025-02-10 1062
全部0条评论

快来发表一下你的评论吧 !
