

 供应链场景使用ClickHouse最佳实践
供应链场景使用ClickHouse最佳实践
电子说
描述
关于ClickHouse的基础概念这里就不做太多的赘述了,ClickHouse官网都有很详细说明。结合供应链数字化团队在使用ClickHouse时总结出的一些注意事项,尤其在命名方面要求研发严格遵守约定,对日常运维有很大的帮助,也希望对读者有启发。
目前供应链数字化ck集群用来存储实时数据,先通过下面这张图表了解下ClickHouse数据来源。
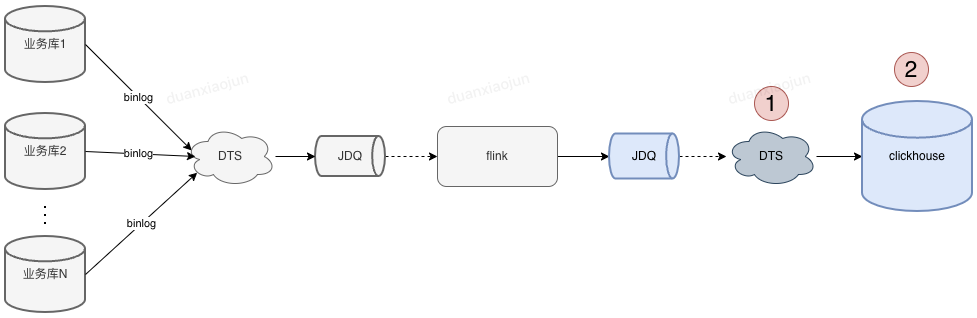
图中标注1和2的位置是供应链数字化研发在开发业务功能时改动量比较多的部分,随着需求变多,DTS任务和数据库表也越来越多。 通过定义研发使用约定,使我们的DTS任务、表、表字段看起来很整洁。
有哪些好处呢?
1、根据ck表名快速找到对应的DTS任务及消费jdq topic / 当然通过jdq也可快速找到对应的ck表(对不了解业务的人帮助很大)。
2、通过ck表字段即可知道该字段来自哪个业务表哪个字段(字段数据不对,联系业务值班先排查业务库的字段是否正确)。
3、快速统计到团队 或 某个ck集群有多少DTS任务(运维时不会遗漏,一目了然)
一 建表约定
1.1 表命名约定
表命名要求: 1、本地表命名必须_local结尾 2、分布式表命名必须以_all结尾;
--创建本地表, 使用on cluster default 在每个节点上都创建一张本地表
CREATE TABLE 本地表名 on cluster 集群名称
(
...
ts DateTime Default now() COMMENT '时间搓',
version UInt64 COMMENT '版本号'
) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/{shard}/test_local',
'{replica}',version)
[PARTITION BY expr] -- 数据分区规则
[ORDER BY expr] -- 排序键
[SAMPLE BY expr] -- 采样键
[SETTINGS index_granularity = 8192, ...] -- 额外参数
参数解释说明:
PARTITION BY toYYYYMM(tmsCreateTime) 按照月份分
ReplicatedReplacingMergeTree(参数1,参数2,参数3)
ORDER BY (参数1,参数2, ....); 参数1,参数2,参数3....等组成业务主键
----创建分布式表
CREATE TABLE IF NOT EXISTS 库名.分布式表名 on cluster default AS 本地表名
ENGINE = Distributed (default,库名,本地表名,sipHash64(分片键));
建表示例脚本:
CREATE TABLE reports_prestore_outbound_fulltrace_local on cluster `default`
(
`sm_so_no` String COMMENT '订单号',
`sm_waybill_code` String COMMENT '青龙运单号',
`sm_so_type` Int64 DEFAULT 0 COMMENT '订单类型',
`st_so_status` Int64 DEFAULT 0 COMMENT '订单状态(1初始、2定位完成、3定位失败、5拣货中、6出库完成、7取消、8转病单、9站点已收货、10已妥投、11再投中、12已拒收)',
⋮
`st_delivery_time` DateTime COMMENT '妥投时间',
`st_redeliver_time` DateTime COMMENT '再投时间',
`st_reject_time` DateTime COMMENT '拒收时间',
`version` UInt64 COMMENT '更新版本号',
`ts` DateTime DEFAULT now() COMMENT '时间戳'
)
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/{shard}/waybill_data_center/reports_prestore_outbound_fulltrace_local',
'{replica}', version)
PARTITION BY toYYYYMM(so_create_time)
ORDER BY (sm_so_no,sm_waybill_code)
TTL so_create_time + toIntervalMonth(1)
SETTINGS index_granularity = 8192;
CREATE TABLE IF NOT EXISTS `reports_prestore_outbound_fulltrace_all` on cluster default AS `reports_prestore_outbound_fulltrace_local`
ENGINE = Distributed (default,waybill_data_center,reports_prestore_outbound_fulltrace_local,sipHash64(sm_so_no));
1.2 分区键设置
视情况大表按天分区,小表按月分区。分区键尽量使用date和datetime字段,避免string类型的分区键
分区粒度根据业务特点决定,不宜过粗或过细。 建议使用toYYYYMMDD()按天分区,如果数据量很少,100w左右,建议使用toYYYYMM()按月分区,过多的分区会占用大量的资源,会因为文件系统中的文件数量过多和需要打开的文件描述符过多,导致 SELECT 查询效率不佳。
1.3 分片键设置
分布式表分片键需要采用hash函数,应避免数据热点,集中写入某个分片;
分片键尽量使用表中区分粒度较细的字段,可以时多个字段的组合,如:id / order_no
1.4 排序键/主键设置
1、有序可以保证很高的压缩比及加速查询,写入数据建议提前排序再写入数据;
2、若未指定默认为排序建,主键不保证唯一性。主键过长会拖慢写入性能,并且会造成过多的内存占用(主键常驻内存)。
1.5 字段使用约定
1、字段类型能用数字型的字段尽量用数字型,避免使用string
2、表字段命名:${业务表缩写}_${业务表字段},如: 业务表ob_shipment_m 缩写:osm, ck表字段则以osm_开头。 注意:业务表的缩写需要使用字典方式管理
3、日期字段建议默认值为1970-01-01,时间字段默认值为1970-01-01 08:00:00,使用到的地方排除掉默认值即可
4、表中必须包含:ts(时间搓)、version(flink写入jdq的时间,单位:)字段。
version— 版本列。类型为 UInt*, Date 或 DateTime。可选参数。 在数据合并的时候,ReplacingMergeTree 从所有具有相同排序键的行中选择一行留下: 如果 version 列未指定,保留最后一条。 如果 version 列已指定,保留 version 值最大的版本
5、尽量不使用Nullable类型
可以非NUll的尽量非NUll并在代码中赋予默认值,数量字段默认值为0,状态字段默认值建议使用有符号int时为-127、无符号int时为0,字符串建议默认值为空字符串。
设置成Nullable对性能影响也没有多大,可能是因为我们数据量比较小。不过官方已经明确指出尽量不要使用Nullable类型,因为Nullable字段不能被索引,而且Nullable列除了有一个存储正常值的文件,还会有一个额外的文件来存储Null标记。
1.6 新增列操作方式
本地表的修改直接执行即可。如果要对分布式表进行修改,需分如下情况进行:
•如果没有数据写入,您可以先修改本地表,然后修改分布式表。
•如果数据正在写入,您需要区分不同的类型进行操作。
| 修改类型 | 操作步骤 |
| 增加Nullable的列 | 1.修改本地表。 2.修改分布式表。 |
| 修改列的数据类型(类型可以相互转换) | |
| 删除Nullable列 | 1.修改分布式表。 2.修改本地表。 |
| 增加非Nullable的列 | 1.停止数据的写入。 2.执行 SYSTEM FLUSH DISTRIBUTED dbName.distributedTableName 3.修改本地表。 4.修改分布式表。 5.重新进行数据的写入。 |
| 删除非Nullable的列 | |
| 修改列的名称 |
添加表字段SQL示例参考:
ALTER TABLE reports_prestore_outbound_fulltrace_local on cluster default ADD COLUMN st_redeliver_time DateTime COMMENT '再投时间'; ALTER TABLE reports_prestore_outbound_fulltrace_all on cluster default ADD COLUMN st_redeliver_time DateTime COMMENT '再投时间';
1.7 DDL执行注意事项
1.mutation(delete,update)操作比较重,尽量避免执行此类操作;
2.清理过期数据,应使用TTL,或者drop partition;
3.分布式DDL,分片副本节点串行执行,出现阻塞会导致后面所有DDL无法正常执行,建议轮询各分片执行DDL,尤其是变更字段类型,不建议直接on cluster default进行变更;
4.optimize table table_name final手动触发合并慎用,尽量按分区操作。
二 数据写入约定
结合供应链的使用场景,这里在flink层加工完数据后没有直接将数据写入ClickHouse集群,而是发送到JDQ队列中。这样做的优势 1、加工和存储解藕 2、JDQ消息共享;
若数据需要做主备存储,我们只需要创建新的DTS任务订阅JDQ消息,将消息写入到备用的ClickHouse集群即可。
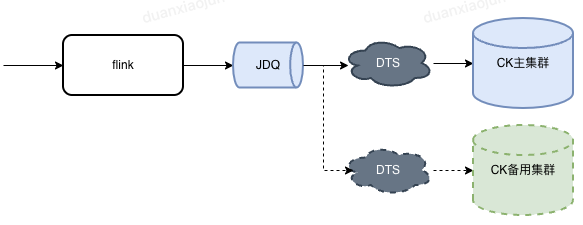
2.1 DTS任务命名约定
任务名规则:sc_digital_${集群ID}_${分布式表名}
使用"sc_digital_"前缀加分布式模型名称,如:sc_digital_c4omjd8fl7_reports_prestore_outbound_fulltrace_all
2.2 DTS所属项目空间
创建DTS任务时,任务需要放在《数字化-DTS任务空间》下。
2.3 DTS写入批次设置
DTS任务批次写入默认值“40W/1分钟”。这里需要根据实际情况适当调下。
建议:每次插入50W行左右数据, 最多不可超过100W行. 总之CK不像MySQL要小事务. 比如1000W行数据, MySQL建议一次插入1W左右, 使用小事务, 执行1000次. CK建议20次,每次50W. 这是MergeTree引擎原理决定的, 频繁少量插入会导致data part过多, 合并不过来.
2.4 DTS消费JDQ的等级
默认消费JDQ的等级为L3。消费等级要根据业务实际使用场景做相应调整。以下等级划分标准(来源于JDQ等级调整说明):

三 数据查询约定
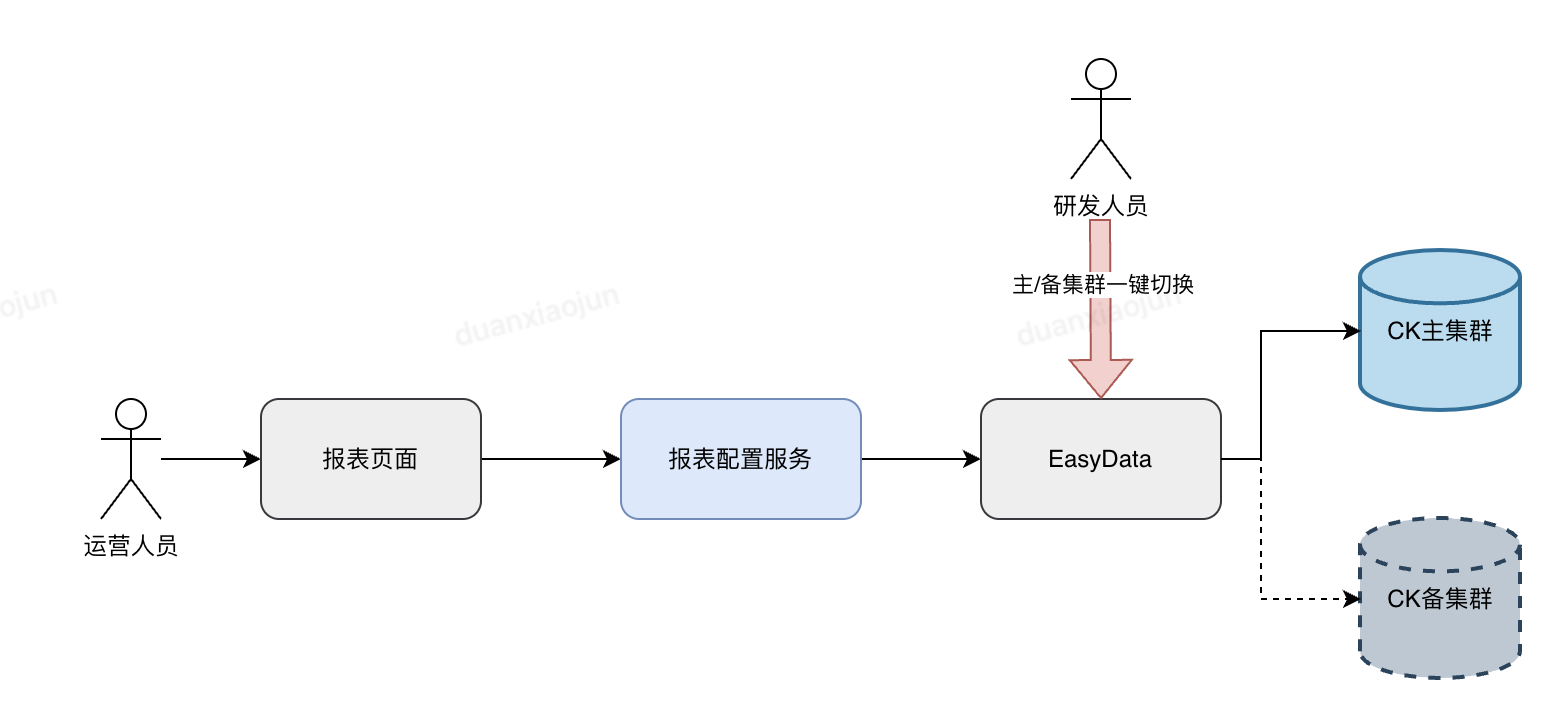
针对易出问题的flink-CK链路进行双流,物理隔离,遇到问题可将查询请求一键切换至备用CK集群。
3.1 尽量prewhere替代where
值不变得字段必须使用prewhere特性提升查询性能
注意:prewhere目前只能用于MergeTree系列的表引擎
3.2 where条件,尽量包含分区键,和主键索引前缀字段
尽量遵循最左原则,如果跳过最左前缀字段,使用其他字段查询,也会走索引过滤一些数据,但是效果不好;
3.3 避免使用Select *
避免使用 SELECT * 操作,这是一个非常影响的操作。应当对列进行裁剪,只选择你需要的列,因为字段越少,消耗的 IO 资源就越少,从而性能就越高。
3.4 where、group by 顺序
where和group by中的列顺序,要和建表语句中order by的列顺序统一,并且放在最前面使得它们有连续不间断的公共前缀,否则会影响查询性能。
3.5 JOIN 性能不是很好,应避免使用
替代方案:业务设计使用大宽表,或使用in替代多变关联,或使用字典,但需注意内存占用;如必须使用join,右表选小表(hash join 右表会全部加载到内存);
3.6 使用final去重
使用final去重查询,尽量不要用argMax
3.7 二级索引
1、可变值字段不能添加二级索引。按此字段做条件查询会先走索引在合并数据,查出而外的中间态数据。
2、 增加二级索引只对后续新增数据生效。如需对历史数据也走索引,需要按分区刷新数据
创建二级索引示例
Alter table reports_prestore_outbound_fulltrace_local ON cluster default
ADD INDEX idx_belong_province_code belong_province_code TYPE set(0) GRANULARITY 5;
Alter table reports_prestore_outbound_fulltrace_local ON cluster default
ADD INDEX idx_st_delivery_time st_delivery_time TYPE minmax GRANULARITY 5;
审核编辑 黄宇
-
基于实物期权的供应链能力柔性决策研究2009-06-14 3345
-
供应链成本管理将是2012年企业关注的一大热点2011-12-19 3146
-
华为的研发流程和供应链管理2012-02-02 14478
-
基于电子商务的供应链金融研究2012-10-25 2812
-
手机供应链管理协会群 1728417882014-11-02 5209
-
手机供应链管理2014-11-24 5213
-
区块链将改革供应链2018-08-08 3872
-
区块链软件开发公司谈区块链在供应链金融场景中的应用2018-11-21 2914
-
如何使用RFID建立绿色供应链系统2019-05-29 2268
-
RFID技术对供应链管理有什么影响2019-07-29 2358
-
电子元器件供应链有哪些?2021-11-02 3023
-
地缘政治、产业链外迁,供应链安全对策2023-03-14 1223
-
区块链+供应链金融是区块链在银行风险管理领域的最佳应用场景2018-12-03 4615
-
供应链大屏设计实践2024-07-03 1287
-
活动回顾 艾体宝 开源软件供应链安全的最佳实践 线下研讨会圆满落幕!2024-10-30 1387
全部0条评论

快来发表一下你的评论吧 !
