

Renesa RA如何使用SPI来实现高速比特流的发送
描述
有些特殊的外设会使用基于SPI模式,发送连续比特流来传输数据。本文主要介绍对于Renesa RA,如何使用SPI来实现高速比特流的发送。
注意,此方式仅针对搭载了支持该工作模式SPI外设的RA产品,使用前请在硬件手册中确认这一点。
灵活的Renesas Advanced(RA)32位MCU是采用Arm Cortex-M33、-M23、-M4和-M85处理器内核,并经过PSA认证的、行业领先的32位MCU。RA可提供更为强大的嵌入式安全功能、卓越的CoreMark性能和超低的运行功率,相比竞争对手的Arm Cortex-M MCU具有重大优势。PSA认证可为客户提供信心和保障,帮助其快速部署安全的物联网端点和边缘设备,以及适用于工业4.0的智能工厂设备。
RSPI在正常的配置模式下,如果发送4个字节,总线上波形如下图所示。在每两个字节之间都有delay的插入。
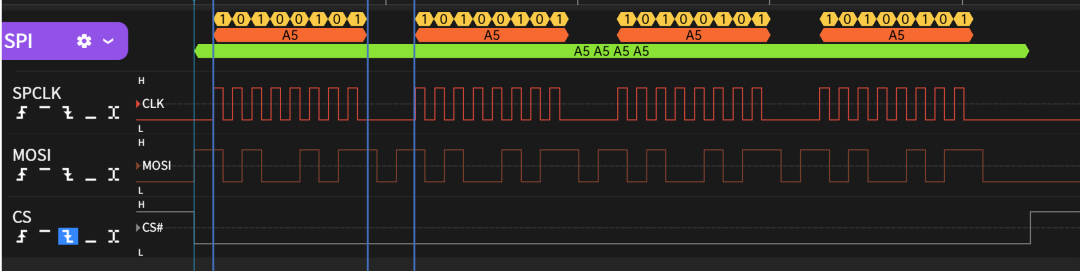
点击可查看大图
手册上关于这部分的描述如下:
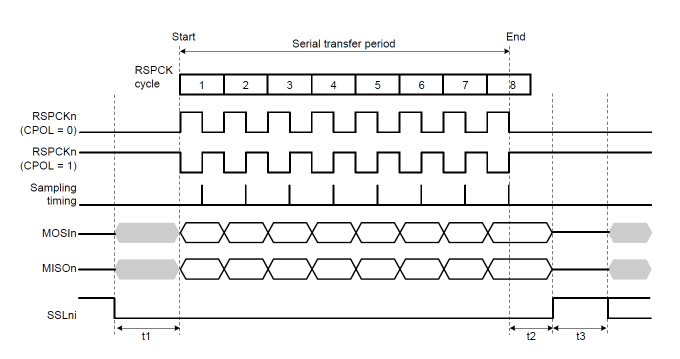
t1是从SSLn生效到第一个clock的延时
t2是最近一个CLK结束到SSLn失效的延时
t3是SSLn再次使能之前的延时
但是这样会造成比特流不连续,无法满足某些特定应用的要求。
SPI实际上还提供了Burst功能,用于产生连续的比特流,该功能尚未在FSP界面中支持,当前可通过手动修改R_SPI代码实现,把寄存器位SSLKP和BFDS置位。更新代码如下所示:

点击可查看大图
修改代码后,测试波形结果如下图:
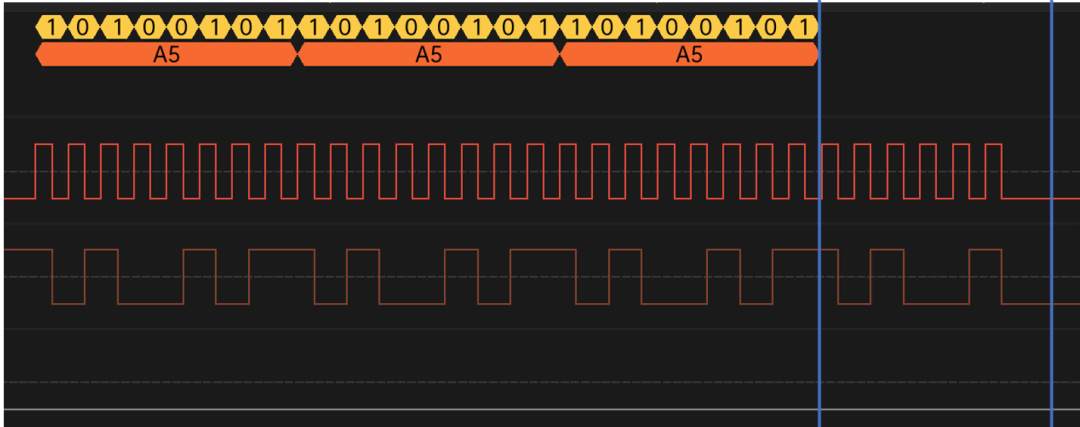
点击可查看大图
细心的小伙伴会发现,最后一个字节没有发送完成。仔细检查发现,在最后一个字节发送的过程中,RSPCK上缺少两个clock,实际上程序也没有进入发送完成中断。
所以光这样还不行,还需要在发送中断程序中做一下处理。
在rafspsrc _spi _spi.c的函数r_spi_transmit函数中增加一个判断,在发送最后一个字节前,重新把SSLKP清零:

点击可查看大图
这是修改后的时序,字节间已经没有插入delay,保证了比特流的连续性。
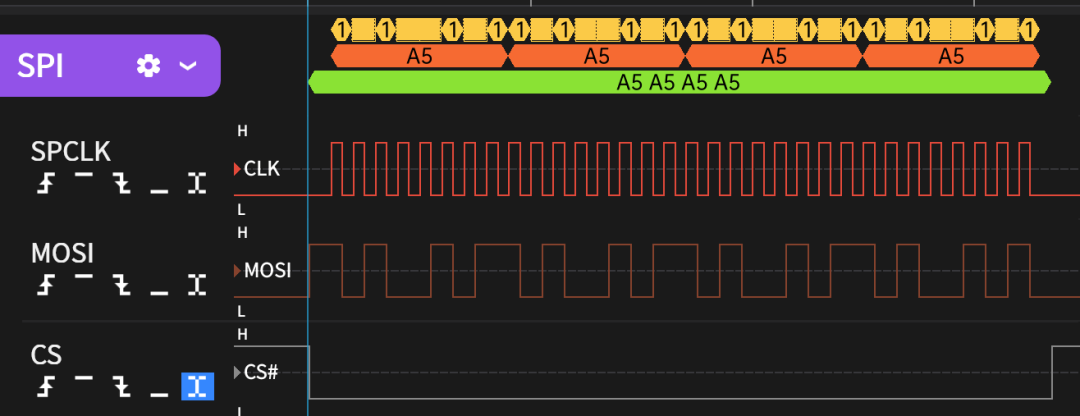
点击可查看大图
需特别注意的是,假如生成连续比特流,则不支持通过DMA/DTC进行SPI传输。
另外,如果不切换FSP的版本,对于源码的修改,RA文件夹中可以保留,但是ra_cfg和ra_gen文件夹中的内容会被FSP重写。如果切换FSP的版本,则三个文件夹(ra,ra_cfg和ra_gen)中的内容均会被FSP重写。
对该功能的支持已加入FSP的开发计划,届时无需手动修改,仅需在FSP Stack中配置即可。
-
DAC1280 TDATA引脚输入的比特流,怎么产生这个比特流,算法是什么?2025-01-06 491
-
使用加密和身份验证来保护UltraScale/UltraScale+ FPGA比特流2023-09-13 786
-
了解FPGA比特流结构2022-11-30 1880
-
如何从同一实现生成2种类型的比特流(SPI x4和SelectMAP x16)2020-06-09 2324
-
如何使用Vivado生成特定的部分比特流2020-05-05 4049
-
USRP解码的比特流错误2019-08-28 2161
-
比特流是什么2019-08-23 5464
-
怎么使用ISE Webpack生成比特流2019-07-04 2027
-
中途向ICAP中止写入部分比特流2019-02-14 1888
-
将时钟与输入比特流同步2018-12-17 2009
-
无法生成比特流2018-11-09 3835
-
英特尔压力比特流和编码器提高质量并加速比特流分析2018-11-01 4448
-
匹配位置对比特流随机性的影响研究2009-08-04 591
全部0条评论

快来发表一下你的评论吧 !
