

在多FPGA集群上实现高级并行编程
描述
今天我们看的这篇论文介绍了在多FPGA集群上实现高级并行编程的研究,其主要目标是为非FPGA专家提供一个成熟且易于使用的环境,以便在多个并行运行的设备上扩展高性能计算(HPC)应用。
背景
该论文的研究背景集中在解决高性能计算(HPC)领域中利用现场可编程门阵列(FPGA)进行并行计算的挑战。由于FPGA在HPC领域相对新颖,尚未形成一个成熟的生态系统,能够方便非FPGA专家在多个FPGA设备上扩展并行应用程序。论文指出,尽管FPGA具备高性能计算潜力,但在实际应用中,缺乏一种有效的方法让非专业人士能够轻松地利用FPGA的并行处理能力。
FPGA在HPC领域的新兴地位:FPGA技术在HPC中尚未得到充分开发,尤其是在构建大规模并行计算环境方面。
并行编程的复杂性:直接编程FPGA通常需要深入的硬件知识,这对非FPGA工程师来说是一个重大障碍。
缺乏成熟的工具和平台:与传统的CPU或GPU相比,用于FPGA的编程工具和平台不够成熟,难以支持大规模的并行应用开发。
基于上述背景,论文旨在开发一种更友好的编程模型和平台,使得非FPGA工程师也能利用FPGA的并行计算能力,特别是在多FPGA集群的环境下。这涉及到创建一个支持消息传递接口(MPI)风格通信的软件堆栈,以及一个能够跨多台FPGA设备进行高效并行计算的编程环境。此外,论文还提到了评估这一新环境的性能和效率,特别是在与传统超级计算机的比较中,特别是在能耗比方面。
FPGA design
论文中关于FPGA设计的部分描述了一个高度优化的架构,旨在促进高级并行编程在多FPGA集群上的实现。
设计组成:
用户应用:这部分包含High-Level Synthesis (HLS) 加速器和运行时,它们与FPGA的High Bandwidth Memory (HBM) 和以太网开关接口进行交互。
以太网子系统:这个子系统负责处理以太网头信息和寻址系统,为应用程序提供一个简单的流式接口,用于发送和接收网络消息。
用户应用与内存互联:
设计中包括POM运行时(Pico OmpSs Manager),HLS加速器,以及与内存的互联机制。
OMPIF运行时被添加到设计中,它连接到以太网接口,允许消息发送者接收来自POM的任务,并处理用户传递的参数。
通信架构:
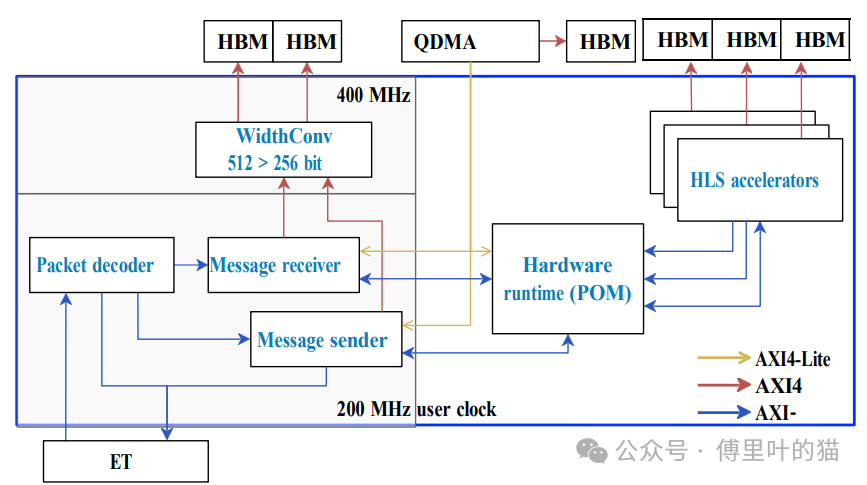
每个FPGA有两个QSFP28端口,其中一个连接到以太网交换机,另一个连接到邻近的FPGA,但设计依赖于与交换机相连的端口,以实现整个集群的完全连通性。
自动化设计生成:
FPGA设计和架构可以自动由Accelerator Integrator Tool (AIT)生成,该工具只需用户HLS代码作为输入。
AIT是OmpSs@FPGA框架的一部分,框架还包括Xtasks库和Nanos6运行时,用于处理FPGA设置、管理和通信。
以太网接口的抽象层:
为了使用以太网接口,设计中加入了一个抽象层,它简化了网络消息的发送和接收,使应用程序无需关心底层以太网协议细节。
HBM使用:
FPGA设计充分利用HBM,这是现代FPGA提供的一种高速存储解决方案,可以显著提高数据吞吐量和访问速度。
硬件与软件协同:
硬件设计与软件栈紧密配合,使得用户可以专注于编写基于任务和消息传递的高级并行代码,而低级别的细节(如以太网、PCIe和JTAG管理)则对程序员透明。
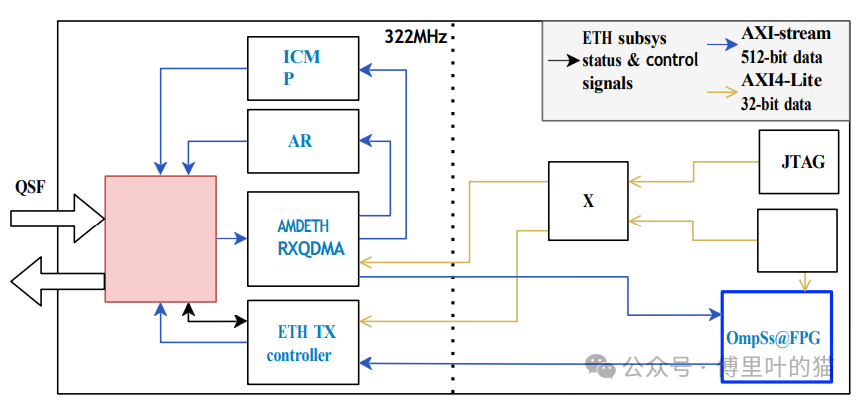
SOFTWARE STACK
论文中描述的软件堆栈是为了使多FPGA集群的管理与使用更加高效和便捷,特别是对于那些基于高级并行编程模型的应用程序。
Xtasks远程支持:
Xtasks库是OmpSs@FPGA框架的一部分,用于卸载任务到FPGA加速器,并在FPGA和主机内存之间复制数据。
新增了对远程FPGA节点的支持,这通过Xtasks远程实现,它能描述集群中所有FPGA节点,无论本地还是远程,以及一个名为Xtasks服务器的应用程序。
这种改进使得从单个CPU服务器可以管理整个FPGA集群,无论是通过本地PCIe还是通过网络。
Nanos6运行时:
Nanos6运行时用于分析任务依赖性和调度可并行执行的任务,它是OmpSs-2任务基础编程模型的核心。
在FPGA上下文中,Nanos6运行时通过Xtasks库管理FPGA的设置、任务调度和通信。
OMPIF集成:
OMPIF(Open MPI over FPGA)是一种通信协议,允许类似MPI(Message Passing Interface)的通信模式在FPGA上运行。
这一集成使得C/C++代码能够在FPGA上运行,并且能够调用类似于MPI_Send/Recv的功能,通过MEEP集群的100Gb以太网网络进行消息传递。
MEEP Manager:
提供了一个统一的界面来管理FPGA集群,包括加载位流、配置设备和传输数据到远程CPU节点所托管的FPGAs。
自动化工具:
Accelerator Integrator Tool (AIT)用于自动生成FPGA设计和架构,只需要用户提供的HLS代码作为输入。
整体而言,软件堆栈提供了一套完整的解决方案,使得非FPGA工程师也能够利用多FPGA集群来扩展他们的应用,同时避免了与低级别硬件交互相关的复杂性。通过这一堆栈,程序员可以专注于编写基于任务和消息传递的高级并行代码,而无需担心底层的以太网、PCIe或JTAG管理等技术细节。此外,堆栈还提供了对远程FPGA节点的管理能力,从而增强了集群的灵活性和可扩展性。
EVALUATION
在论文的评估(Evaluation)部分,作者们展示了他们构建的多FPGA集群——Marenostrum Exascale Emulation Platform (MEEP)的性能,特别是在高带宽通信和高性能计算(HPC)应用方面。
带宽测量:
使用OMPIF (Open MPI over FPGA)在两个FPGA之间测得的带宽最高可达约4.5GB/s,当数据量约为100MB时。
主机到FPGA以及反向的通信,包括本地(仅PCIe)和远程(PCIe+网络)的组合,显示了不同的带宽特性。在远程情况下,由于数据需要通过网络传输,因此带宽会受到显著影响。
性能评估:
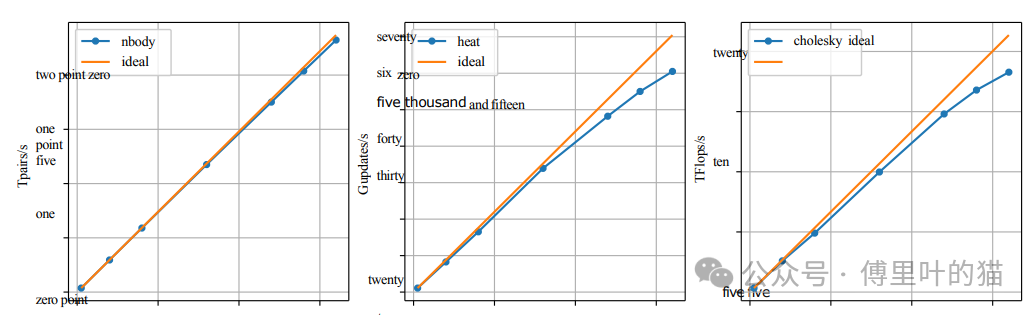
对三个基准测试进行了评估:N-body模拟、Heat扩散模拟(使用Gauss-Seidel求解器)和Cholesky分解。
N-body基准测试使用了4194304个粒子和16个步骤,在64个FPGA上的表现接近理想,效率达到98%,达到每秒2.3G对力的计算。
Heat基准测试展示了热传导在二维矩阵上的模拟,使用Gauss-Seidel方法计算每个位置的平均值。结果显示,该应用能够有效利用FPGA资源,处理大量的依赖关系。
与HPC的比较:
将MEEP集群的性能与MareNostrum 4超级计算机进行了对比,发现在N-body和Heat基准测试中,MEEP的性能功耗比分别提高了2.3倍和3.5倍。
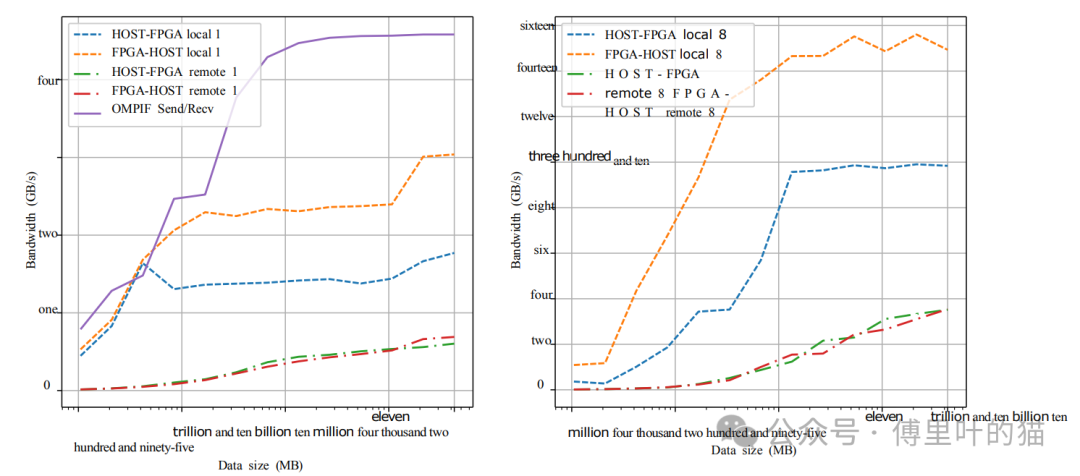
这些结果表明,MEEP集群在处理大规模并行计算任务时具有显著的优势,尤其是在功耗效率方面。同时,该评估证明了使用OMPIF和100Gb以太网网络在FPGA集群间实现高速通信的可行性。通过使用先进的硬件和优化的软件堆栈,研究人员能够展示出FPGA集群在HPC领域的潜力,尤其是在要求高性能和高效率的应用场景中。
-
FPGA的并行多通道激励信号产生模块2012-08-11 2014
-
FPGA高级编程的书籍2013-10-16 2899
-
基于FPGA控制的多DSP并行处理系统2019-05-21 2317
-
怎么实现以FPGA为核心器件的并行多通道信号产生模块?2021-04-29 1658
-
基于SMP集群的混合并行编程模型研究2009-03-30 975
-
MPI并行程序设计的负载平衡实现方法2009-07-30 1122
-
并行CRC在FPGA上的实现研究2011-08-15 660
-
在FPGA上实现CRC算法的程序2016-06-07 1190
-
基于FPGA和多DSP的多总线并行处理器设计2017-10-19 1016
-
如何在工程应用中合理采用并行编程技术2017-12-02 754
-
如何使用OpenCL轻松实现FPGA应用编程2020-07-16 7552
-
如何使用FPGA实现HDLC协议控制器2020-11-04 1510
-
基于FPGA集群的NEST脉冲神经网络仿真器2021-03-19 1813
-
多通道可编程并行通信接口芯片XDC05的设计实现2021-09-15 851
-
怎么用FPGA做算法 如何在FPGA上实现最大公约数算法2023-08-16 4567
全部0条评论

快来发表一下你的评论吧 !
