

人工智能处理器三强Intel/NVIDIA/AMD谁称霸?
人工智能
描述
英特尔在旧金山IDF16上除了核心亮点融合现实(MR)Alloy项目之外,新一代至强融核(XEON PHI)处理器也一同发布。Intel、NIVIDIA、AMD作为PC时代的老对手,在人工智能时代,它们的竞争又会碰撞出怎么样的火花?
借着IDF16的余温还未褪去,我们在文章中将首先谈一谈错失移动互联网红利的英特尔在人工智能方面做了哪些努力,接下来将会通过英特尔、英伟达、AMD在2016年最新发布的XEON PHI、NVIDIA Tesla、AMD FirePro S处理器来探究究竟谁能够成为人工智能领域的霸主。
英特尔积极布局人工智能
数据显示,2015年全球人工智能市场规模到达1683.9亿元,预计2020年将达到近3700亿元,年复合增长率达到17%。谷歌、Facebook、微软等科技巨头纷纷押注人工智能领域,PC芯片霸主英特尔在错过移动互联网的红利之后也开始了在人工智能领域的布局。
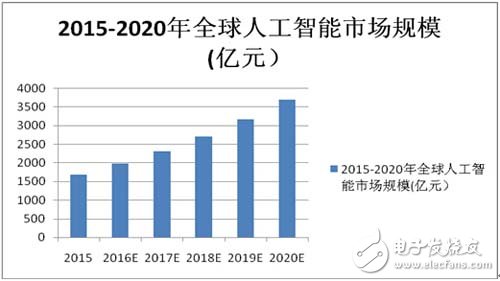
2015-2020年全球人工智能市场规模
2015年,Intel以167亿美元收购了年收入不足20亿美元的全球第二大FPGA厂商Altera。由于FPGA 是具有一定的可编程性,介于专用芯片和通用芯片之间,可同时进行数据并行和任务并行计算,在图像识别、信号处理等特定场景中具有比 GPU、CPU 更高的性价比。因此此举被认为是这是英特尔布局人工智能的一个重要战略。
IDF16之前,英特尔宣布收购深度学习创业公司 Nervana System,该公司是一家在芯片领域具有自主知识产权的公司,旗下的 Engine 芯片在深度学习训练时有着比传统 GPU 的能耗和性能优势。
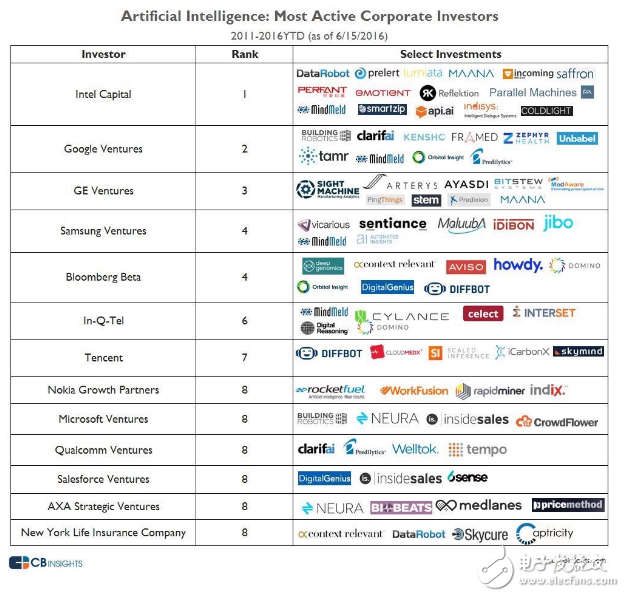
凭借着两大收购,英特尔基本补齐了在人工智能,尤其是机器学习领域的两大短板,同时也进一步延伸了处理器的业务体系。更重要的是,英特尔旗下的风险投资机构过去几年在人工智能领域也十分活跃。
英特尔XEON PHI处理器
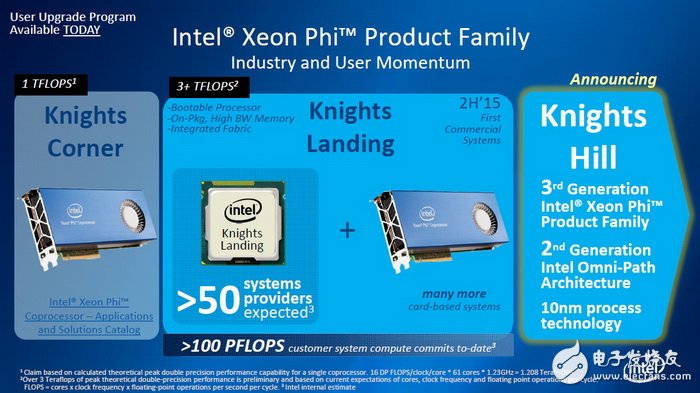
IDF16上,Intel发布第三代Xeon Phi处理器,代号Knights Mil。它将是2011年代号Knigts Corner,22nm工艺,最多61个核心,浮点性能1TFLOPS,和2013年代号Knights Landing,14nm工艺,最多72核心,浮点性能3+TFLOPS之后的继任者。
Knights Mill架构是第三代,目前只知道它会在2017年问世,制程工艺升级到10nm,同时会支持Intel第二代Omni-path网络架构,但是Intel并没有公布太多细节,具体的性能等级也未知。不过Knights Mill除了继续提高能效、优化并行性能、增强各种运行精度、搭配高弹性大容量内存之外,DL深度学习也会是重点。

Xeon Phi是Intel针对高性能计算市场推出的处理器,与主要竞争产品有NVIDIA的Tesla、AMD的FirePro S相比,后两者是基于GPU的,Xeon Phi是X86众核架构的。
NVIDIA Tesla
在深度学习芯片领域,Nvidia的GPU 具备统治性的地位,在2016年国际超级计算大会上,NVIDIA发布了PCI-E版本的Tesla P100。
Tesla P100是帕斯卡家族的首款产品,也是迄今唯一基于GP100大核心的产品,不过此前发布的版本是面向NVLink总线服务器的,而今天的新款则用于传统PCI-E环境。二者核心规格完全相同,都有3584个流处理器,只不过核心加速频率从1480MHz降至1300MHz(基础频率未公布),因此计算性能损失了大约22%,半精度浮点18.7TFlops(每秒18.7万亿次计算)、单精度浮点9.3TFlops、双精度浮点4.7TFlops。
显存继续搭载HBM2,频率也保持在1.4GHz,但除了4096-bit 16GB的完整版,还有个3072-bit 12GB的精简版,带宽分别为720GB/s、540GB/s。
由于频率降低,新卡的功耗也从300W降到了250W,和上一代Tesla M10相同,可以无缝升级,继续配合服务器采用被动散热。


Tesla P100和配套软件将在今年第四季度出货,具体价格未公布。

AMD FirePro
AMD在今年早些时候发布了号称世界最强VR显卡Radeon Pro Duo,双芯Fiji,随后AMD又推出了面向HPC、数据中心等高性能加速卡FirePro S9300 X2,该处理器是双芯Fiji专业版,浮点性能13.9TFLOPS,8GB HBM显存,TDP为300W,号称世界单精度性能最高的专业卡,售价5999美元。
AMD的FirePro S系列主要面向HPC市场,与前面介绍的Intel Xeon Phi及NVIDIA Tesla K系列形成竞争关系。它们在HPC领域多是用作加速卡,所以浮点性能非常强大。

AMD宣称S9300 X2是世界最快的单精度加速卡
FirePro S9300这次使用的是2个Fiji完整核心,每个GPU有4096个流处理器单元,跟之前发布的Radeon Pro Duo差不多,不过因为被动散热,所以其频率肯定会降低一些,13.9TFLOPS的浮点性能与后者的16TFLOPS有所下降,但它在GPU加速卡中其性能依然是拔尖的,AMD宣称S9300 X2是世界最快的单精度加速卡。
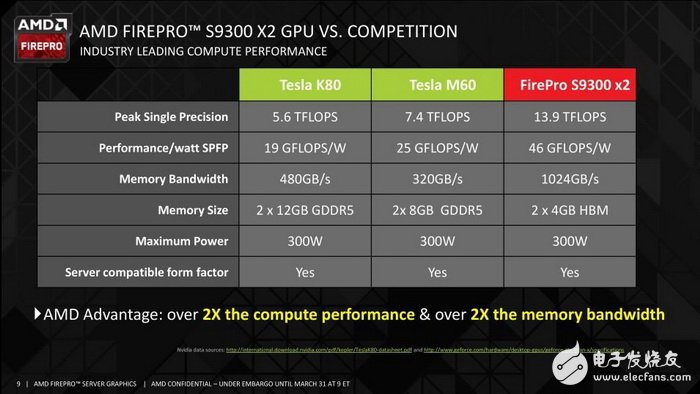
竞品的对比
NVIDIA同级别的对手是Tesla K80,浮点性能只有5.6TFLOPS,带宽480GB/s,显存容量24GB,TDP为300W,而FirePro S9300 X2在同为300W TDP下浮点性能翻倍,带宽更是高达1TB/s,虽然8GB的显存容量不够看,不过别忘了它使用的是HBM显存,跟普通GDDR5显存不一样。
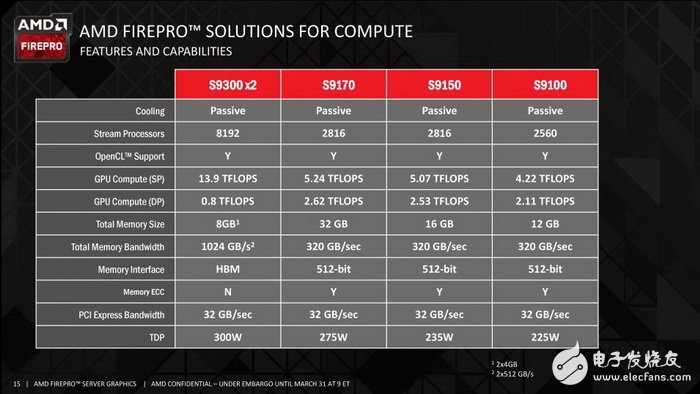
FirePro S系列解决方案
FirePro S9300 X2专业卡售价为5999美元,折合人民币38682元左右,而NVIDIA的K80发布时售价为5000美元,后来降到4000美元。
谁能称霸?
通过上面的详细介绍,想必你对XEON PHI、NVIDIA Tesla、AMD FirePro S最新人工智能处理器都有了一定的认识。目前来看NVIDIA占据一定的优势,AMD在追赶,借助收购补齐短板的英特尔未来可期。
随着三大厂商此产品的上市,在未来的人工智能、深度学习领域,谁能笑到最后还很难预测,我们只能拭目以待。
-
看Intel_AMD_NVIDIA三分天下2012-02-23 1538
-
risc-v在人工智能图像处理应用前景分析2024-09-28 1187
-
【硅谷恩怨录】Intel与AMD的权力游戏2016-07-08 3658
-
人工智能:超越炒作2019-05-29 5079
-
人工智能芯片是人工智能发展的2021-07-27 6759
-
Arm Neoverse NVIDIA Grace CPU 超级芯片:为人工智能的未来设定步伐2022-03-29 5179
-
AMD Zen处理器威胁Intel?他们的10nm处理器更强劲2016-12-06 1944
-
AMD、Intel处理器搞“核战”2017-04-24 1359
-
Intel携手AMD研发PC处理器,死磕NVIDIA2017-11-07 999
-
人工智能激化高效运算市场战争,英特尔高通等调整战略切入服务器处理器市场2017-12-01 1176
-
amd处理器与intel区别对比_amd处理器与intel哪个好2018-01-09 103809
-
一文分析Intel、AMD、NVIDIA芯片巨头的角逐形式2020-10-15 2279
-
AMD和Intel谁的散热器更好?2020-11-20 8892
-
处理器amd和intel哪个好2021-10-09 23436
-
Fujitsu、NVIDIA、AMD和Intel高性能处理器架构分析2023-06-30 1913
全部0条评论

快来发表一下你的评论吧 !
