

地平线科研论文入选国际计算机视觉顶会ECCV 2024
描述
近日,地平线两篇论文入选国际计算机视觉顶会ECCV 2024,自动驾驶算法技术再有新突破。
ECCV(European Conference on Computer Vision,即欧洲计算机视觉国际会议),是计算机视觉领域中最顶级的会议之一,与ICCV(International Conference on Computer Vision)和CVPR(Conference on Computer Vision and Pattern Recognition)并称为计算机视觉领域的“三大顶会”。ECCV每两年举行一次,吸引了全球顶尖的研究人员、学者和业界专家,分享最新的研究成果与技术创新。
聚创新之力 答智驾课题
本次地平线被录用的2篇论文是:
1、Lane Graph as Path: Continuity-preserving Path-wise Modeling for Online Lane Graph Construction
(《LaneGAP:用于在线车道图构建的连续性路径建模》)
论文链接:https://arxiv.org/abs/2303.08815
2、Occupancy as Set of Points
(《OSP:基于点集表征的占据网格预测》)
论文链接:https://arxiv.org/abs/2407.04049
车道图构建新方案:
端到端学习路径,大幅提升预测规划性能
在线车道图构建是自动驾驶领域一项有前途但具有挑战性的任务。LaneGAP 是一种车道图构建新方法,将端到端矢量地图在线构建方法 MapTR(入选深度学习顶会ICLR spotlight论文)拓展到道路拓扑建模,能够大幅提升预测规划性能,应对各种复杂交通状况。LaneGAP 和 MapTR 相关工作已经在地平线高阶智驾系统SuperDrive中落地应用。
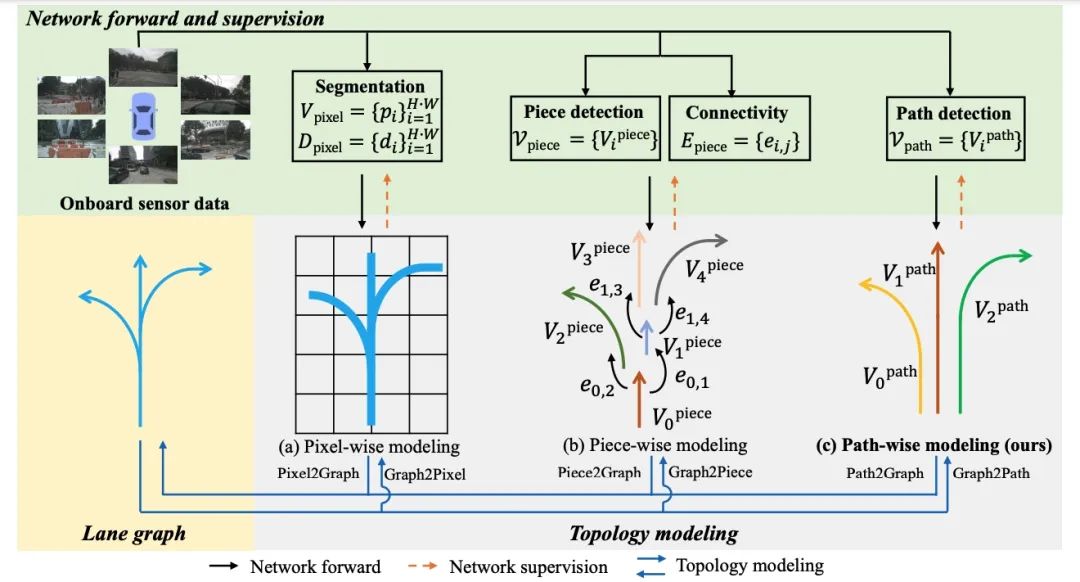
具体而言,以前的方法通常在像素或片段级别对车道图进行建模,并通过逐像素或分段连接恢复车道图,这会破坏车道的连续性。作者提出一种基于路径的在线车道图构建方法—— LaneGAP,它采用了端到端学习路径,并通过 Path2Graph 算法恢复车道图。LaneGAP在具有挑战性的 nuScenes 和 Argoverse2 数据集上定性和定量地证明了 LaneGAP 优于传统的基于像素和基于片段的方法。丰富的可视化效果显示 LaneGAP 可以应对各种复杂交通状况。
Occupancy新突破:
全新视角,性能更强大,计算更灵活
OSP提出了全新视角下的自动驾驶场景建模算法——稀疏点集占据网格预测方法,通过与2D图像特征交互的点查询,建立了一种新的基于点的占用表示,可以全面理解3D场景,并且框架更灵活,性能更强大。
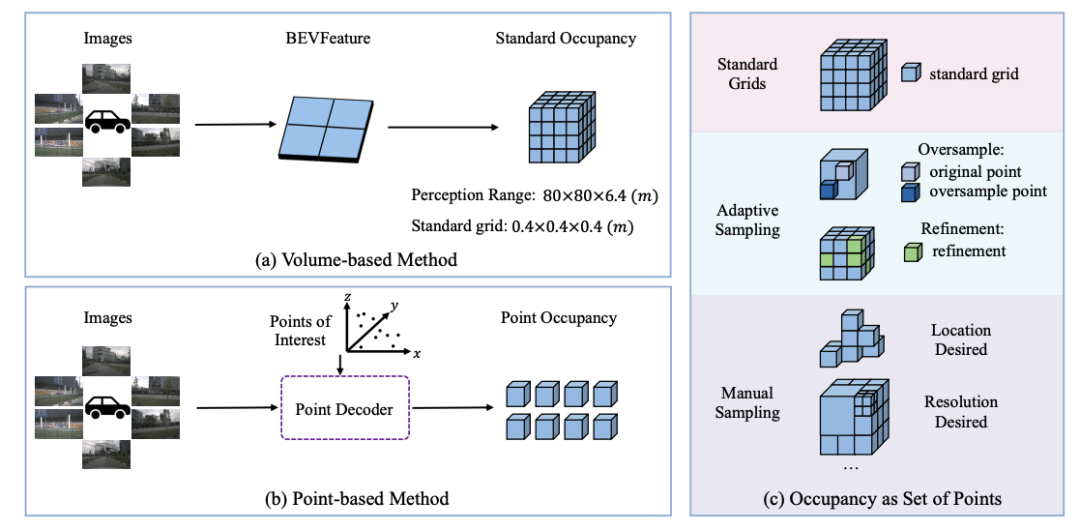
本文探索了利用多视角图像进行3D占据网格预测的新方法,称为“点集占据网格”。现有方法倾向于利用BEV表征进行占据网格预测,因此很难将注意力集中在特殊区域或感知范围之外的区域。相比之下,本文提出了Points of Interest (PoIs) 来表示场景,并提出了 OSP,一种基于点的 3D 占用预测的新框架。得益于点集表征的灵活性,OSP 与现有方法相比实现了强大的性能,并且在训练和推理适应性方面表现出色:可以预测感知边界外的范围;可以与基于体特征的方法集成以提升性能。在Occ3D nuScenes占用基准上的实验表明,OSP具有强大的性能和灵活性。
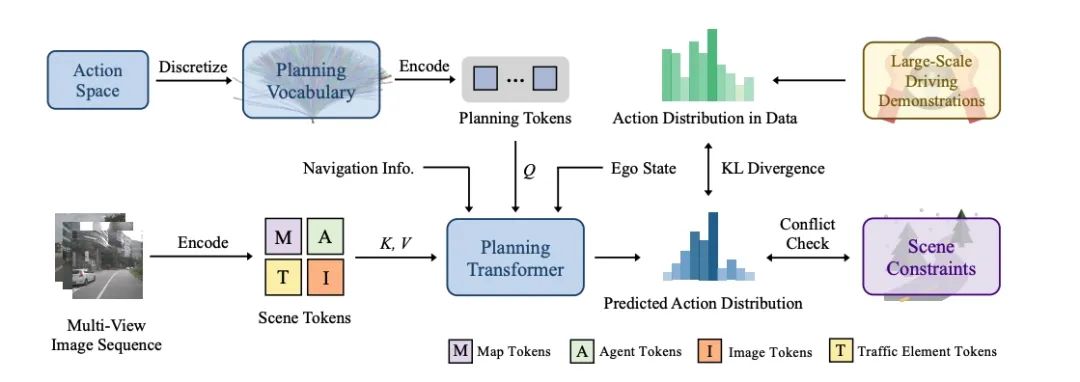
除了这两篇斩获ECCV 2024的最新成果,地平线在ICCV 2023上提出的VAD也有创新进展。VADv2首次提出基于概率建模的多模态决策端到端自动驾驶大模型,在闭环榜单Carla Town05 Benchmark上达到SOTA的端到端自动驾驶规划性能。
此前,VAD初步探索了基于矢量化场景表征的端到端自动驾驶算法框架,在此基础上,VADv2首次将多模态概率规划引入端到端自动驾驶,用于解决判决式模型无法建模决策的天然多模态特性的问题,从而有效提升决策的准确率。VADv2以数据驱动的范式从大量驾驶数据中端到端学习驾驶策略,在Carla闭环榜单上,相比于此前的方案,VADv2大幅提升驾驶评分,实现SOTA性能,在无需规则后处理的情况下也能有良好的驾驶表现。
于7月21日-27日,正在奥地利维也纳举办的2024国际机器学习大会(ICML 2024)上,地平线被ICML 2024接收的最新工作Vision Mamba(简称Vim)也受邀做了分享。Vision Mamba是一种新的通用视觉主干模型,相比现有的视觉Transformer,在性能上有显著提升,是接替Transformer的下一代视觉基础模型。
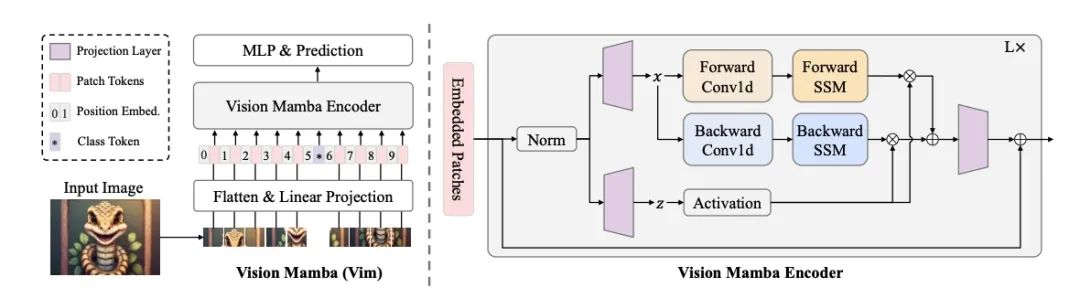
Vision Mamba使用双向状态空间模型(SSM)对图像序列进行位置嵌入,并利用双向SSM压缩视觉表示。在ImageNet分类、COCO目标检测和ADE20k语义分割任务中,Vim相比现有的视觉Transformer(如DeiT)在性能上有大幅提升,同时在计算和内存效率上也有显著改进。例如,在进行分辨率为1248×1248的批量推理时,Vim比DeiT快2.8倍,GPU内存节省86.8%。这些结果表明,Vim能够克服在高分辨率图像理解中执行Transformer样式的计算和内存限制,具有成为下一代视觉基础模型主干的潜力。
地平线「你好,开发者」直播预告
为了让智驾开发者更深入地了解这些最新的研究成果与算法创新,地平线策划推出2024年「你好,开发者」自动驾驶技术专场,邀请到地平线各位技术专家进行直播分享。敬请关注!
-
计算机视觉论文速览2021-08-31 1945
-
地平线发布中国首款嵌入式人工智能视觉芯片2017-12-21 5549
-
最新的计算机科学实力排名来了!2018-05-13 7660
-
地平线XForce边缘AI计算平台与密集人群人体分析方案亮相安博会2018-10-26 6770
-
AI芯片及产品矩阵获国际认可,地平线入选EETimes Silicon 602018-12-05 700
-
计算机视觉研究将为推动AI行业发展作出贡献2020-06-15 2347
-
Nullmax视觉感知能力再获国际顶级学术会议认可2024-09-02 1371
-
NVIDIA Research在ECCV 2024上展示多项创新成果2024-11-19 1679
-
后摩智能四篇论文入选三大国际顶会2025-05-29 1603
-
理想汽车八篇论文入选ICCV 20252025-07-03 1422
-
地平线五篇论文入选NeurIPS 2025与AAAI 20262025-11-27 1511
-
地平线11篇论文强势入选CVPR 20262026-03-18 1058
-
奕行智能论文入选国际计算机体系结构顶级会议 ISCA 20262026-04-01 712
-
传音相关研究成果入选计算机视觉顶会CVPR 20262026-04-03 3131
-
理想汽车12篇论文强势入选CVPR 20262026-06-09 1286
全部0条评论

快来发表一下你的评论吧 !
