

2016年的AI,一场史无前例的技术营销
人工智能
描述
2016年12月29日,大概又是一个会被载入史册的日子。名叫SkyNet,哦不,是”Master”的围棋AI,开始了第一次对人类的血洗。
在奕城的第一晚,Master十战全胜;第二日,横扫韩国第一人朴廷桓九段、世界第一人柯洁,比分都是2比0;第三日,陈耀烨九段、金庭贤五段、范廷钰九段、芈昱廷九段和唐韦星九段依次落马;再之后是古力、时越、金志锡、井山裕太;到了1月4日,聂卫平老先生以7目半落败。最终战绩,Master 60胜0负1平(平的那局是因为掉线)
自此,Artificial Intelligence(AI),这个在2016年已经如日中天的buzzword,再一次传遍大街小巷。人们沉浸在对AI的崇拜、慌乱与恐惧之中,然而作为吃瓜群众的笔者却在想一个问题:如果DeepMind没有事先与各国棋院通气,整个事件如何能进行得如此顺利,在时间上如此紧凑?所有重要的世界高手,都在短短几天的时间窗口内腾出了时间,如果说没有提前策划和组织,实在有点难以置信。掐指一算自从3月份AlphaGo的横空出世,DeepMind已有9个月时间没有在圈外露脸,大概它也感受到了营销的压力吧。
其实纵观2016年,在阿尔法狗狗的带领之下,AI界隔三差五地在圈内外制造着骚动:3月,除了人尽皆知的AlphaGo事件,李开复关于人工智能博士200w+美金年薪的文章刷屏;4月,Google著名的深度学习框架TensorFlow发布分布式版本;6月,Prisma上线,红极一时;8月,Google发布基于深度学习的NLU框架SyntaxNet; 9月,Google上线基于深度学习的机器翻译,索尼用人工智能写了两首歌;10月,微软宣布语音识别达到人类水平;11月,计算机视觉学术大牛李飞飞老师下海进入工业界;12月,DeepMind在NIPS16会议上宣布DeepMind Lab开源。一切的一切,都在各大媒体冠以【重磅】开头的新闻标题之下,一次次地牵动着广大吃瓜群众的神经——然而这些成就实际上离我们的生活又是那么的遥远。
在科技的历史上,从未有任何一项科技,在它的大规模真实应用之前,有持续一年甚至几年的营销运动。在这个风口之上,在这个AI几年的造势运动把人们的期望与恐惧推上一个历史顶点,而其真正落地应用又遥遥无期的一个尴尬节点,是时候冷静下来回顾一下AI的营销史了。
一、一些概念和历史
有几个概念需要先明确一下,因为我发现在今日媒体的狂轰滥炸之下,有大批AI民科是分不清像“人工智能”、“机器学习”、“深度学习”这些概念的关系的(例如我认识的非科班出身的人有90%认为机器学习=深度学习)。当然这些概念的含义也一直在“与时俱进”,不过学界还是有一个相对统一且合理的认知,可以帮助我们阐述问题。下面这张图描述了其中最重要的几个概念之间的关系
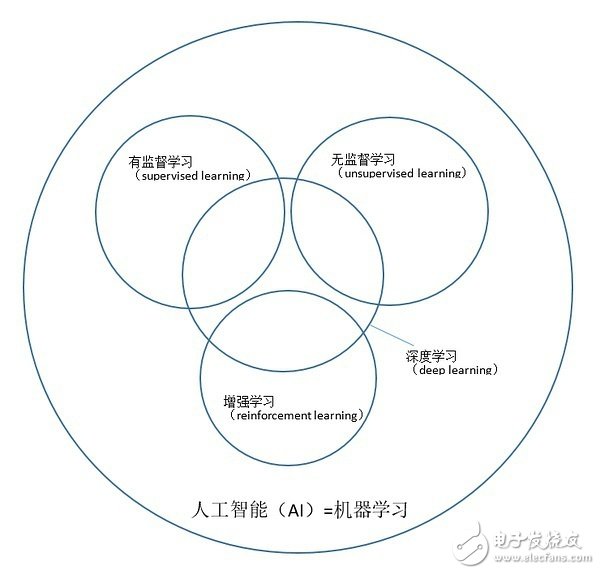
“人工智能”这个buzzword,常常会因为营销或者新闻报道的需求而被赋予不同的含义,其外延有时等同于“机器学习”,有时不等同,所以最外圈的这个等号并不完全准确。不过在2016年被大家普遍讨论的这些“AI”,可以认为基本上就是机器学习。内部的四个小圈则是学术上有确定外延的四个概念,代表了当前最重要的四个问题领域,是需要明确的重点概念。
有监督学习(supervised learning)——让机器观测到一些输入,并告诉机器在这些输入下应该产生什么样的输出。机器通过这些数据学习出一个模型,之后给它新输入的时候,它能够根据模型预测应该产生什么样的输出。比如机器看到一个图片,可以判断图片中的物体属于哪一个分类。
无监督学习(unsupervised learning)——让机器观测到一些输入,而没有标准输出,让机器自行去总结这些输入数据有什么统计特征,并生成有意义的产出。例如自动把大批文章聚成相似的几类,又例如给计算机看一些小狗小猫的照片,让计算机自动生成一些新的(与看过的相似但又不同的)小狗小猫的照片。
增强学习(reinforcement learning)——让机器观测到一些输入,并让机器根据输入做特定动作(action)。这些动作导致机器获得收益或者惩罚(reward)。机器通过增强学习优化它的动作策略(strategy),使得它的长期收益最大化。下棋就是这一类典型的问题,strategy就是行棋策略,reward就是赢棋。
深度学习(deep learning)——事实上不是一类问题,而只是一种方法,一种通过多层神经网络来构建上述三种问题所需要的模型的方法。
回到历史。这一波的AI热,最早应归功于Hinton老头子的文章《A fast learning algorithm for deep belief nets》这篇文章是2005年写的,截至2017年1月14日已有5000+的引用,足见其影响力)这篇文章实际上是用一种无监督学习的方法实现了对原始数据逐层抽取深度特征,而这些深度特征可以被用为有监督学习的特征来提高有监督学习的准确率。这解决了长久以来神经网络“无法做深”的痛点(原因是训练信号会随着深度增加而被稀释,有兴趣的读者可查阅相关资料),算是一个比较大的贡献。不过当时这个文章传达的大方向是用无监督学习的方法抽取特征(这个过程叫做pre-training),并没有把重点放在有监督学习本身的模型上,所以当时的同学们对于有监督/无监督在方向选择上是有点迷茫的。
这种迷茫直到2012年还存在。这一年的一件大事是Andrew NG等人的Google Brain团队,搞了一个庞大的分布式深度学习,在ImageNet图片物体分类竞赛中把对手远远甩在了身后(《Building High-level Features Using Large Scale Unsupervised Learning》)前面已经说过,物体分类是一个有监督学习任务,但是由于Hinton老爷子定下的无监督学习基调,Andrew NG等人还是把重心放在了无监督学习生成特征上面,并且做出了那幅著名的“机器学习出来的猫”。有趣的是,在2012年的NIPS上,Hinton和NG的团队同时放弃了pre-training。失去了pre-training的帮助,就需要其他方法解决训练信号被稀释的问题,Hinton团队的方法是换了一种叫做ReLU的激活函数( 《ImageNet Classification with Deep Convolutional Neural Networks》),NG团队的方法则是怼机器,大量的机器(《Large Scale Distributed Deep Networks》)。Hinton团队同时还抛出了CNN应用到ImageNet上的表现,CNN和ReLU这两个东西非常重要,成为此后深度学习研究的标配。结果Hinton团队这篇文章的引用数有8000多,而NG团队的两篇分别是700多和1000多。NG的营销能力强,学术创新上却总是比Hinton老爷子慢半拍。Anyway,自从12年NIPS这两篇文章之后的一段时间,大家对无监督学习就不怎么感冒了。
2012年Andrew NG团队无监督学习生成的猫脸图片。图片来源:New York Times
也是从2012年的ImageNet竞赛开始,AI进入第一个营销高潮。当时的人们对于计算机识别小猫小狗这种事情还觉得很新鲜,于是接下来科研圈的开始对此类事情趋之若鹜。几乎每个做机器学习的实验室都会尝试一把在State-of-the-art的模型上做一点哪怕是很小的微创新,希望能产生ImageNet准确率上一点哪怕是很小的提升,一旦成功了,就可以说自己是新的State-of-the-art。从那以后,大家开始只关心实验的准确率,越来越少的人关心模型本身的理论价值。AI研究的方法论,从传统科学的重视推理论证,变成了快速尝试+总结相关性(也就是所谓的“大数据思维”)。毕竟准确率数字是很好拿出去说的,理论价值却很难讲清楚。 AI自此进入营销时代。
在AI学术界这一翻天覆地的变化背后,Andrew NG功不可没。深度学习理论上的重要突破大多都不是归属于他的,然而他做了几件重要的事情:2008年发起“Stanford Engineering Everywhere”(SEE)项目,把自己的机器学习课程曝光给全世界人民;2011年组建了Google Brain项目,这个项目初期的最主要产出之一就是后来被媒体大书特书的那张无监督学习出来的猫脸,并且这个结果在报道的时候给人一种“机器有了自主学习能力”的认知;2012年创立Coursera,在MOOC社区中进一步营造出一种AI大繁荣的景象。NG大概是这几年媒体出镜率最高的AI学术圈人士。与其说是一位科学家,Andrew NG的角色更像是一位优秀的AI产品经理及营销人员,他的营销能力在圈内早已得到公认。关于NG的营销能力,在NIPS 2016会议上还有一个有趣的小细节,将会在后面提到。
回到我们的时间线,鉴于2012年底深度学习在有监督学习上的巨大成功,一段时间内大家忙于把这项技术推广到各个应用领域跑马圈地(其实主要还是图像和语音),暂时忘掉了无监督学习和生成猫脸的事情。到了2014年,当各个领域都被圈的差不多了,学术界在苦苦寻找下一个噱头的时候,大神Ian Goodfellow通过一个叫做“干”的东西(GAN,Generative Adversarial Network)把无监督学习重新带回了人们的视线。“干”干的就是“给计算机看一些小狗小猫的照片,让计算机自动生成一些新的(与看过的相似但又不同的)小狗小猫的照片”这样一件事情,不同点在于,它干的非常不错。一时间,AI学术界迅速高潮了,纷纷竞争起生成图片(以及语音、音乐等各种其他东西)的生意来。大家也并不关心我们为什么需要生成这些图片(相比之下语音合成和自动生成音乐反而更容易理解一些),大概只是觉得“能干这件事情看起来就很牛逼”,于是就做了,而且做的越来越好。下图是Ian Goodfellow在NIPS 2016上讲GAN的Tutorial里展示的一个生成小动物的demo(《NIPS 2016 Tutorial: Generative Adversarial Networks》)。
GAN生成的小动物图片。图片来源:Ian Goodfellow, NIPS 2016 Tutorial: Generative Adversarial
与此同时,DeepMind在增强学习上的努力,则一直在相对低调地进行。增强学习在很长一段时间内被认为是“仅停留在学术研究”的存在,因其难以降下来的巨大状态空间和动作空间,很难做出一个可展示又足够吸引吃瓜群众的demo。因而在AlphaGo诞生之前,增强学习的研究一直处于一个不温不火的状态。一个叫做“DQN”的东西的出现打破了这个局面。通过把深度学习应用在strategy的学习更新上,巧妙避开大状态空间和动作空间,DQN使得在一个相对小的多的参数空间内训练成为可能(《Playing Atari with Deep Reinforcement Learning》)。这是一个了不起的成就,为后来的AlphaGo奠定了基础。这个伟大想法产生的时间在2013年以前(前述文章在2013年发表),而直到2015年AlphaGo问世之后才被广为传颂。可见一个漂亮的demo是多么重要。
再然后,就是大家都知道的事情了。
二、一些奇怪的现象
AI围棋战胜人类,本身是一个伟大的成就。然而在这个伟大浪潮推动下的AI学术大跃进与创业热中,却出现了很多奇怪的现象。
理性地分析AI这个事情,至少应该提三个问题:1. 这玩意到底做不做的出来;2. 假如这玩意能做出来,那么它做出来以后到底有没有应用前景;3. 假如这玩意能做出来且有应用前景,它会不会毁灭人类。这三个问题是层层递进的关系,对1的答案是肯定的讨论2才有意义,对2的答案是肯定的讨论3才有意义。于是有了第一个奇怪的现象:大部分的吃瓜群众,直接跳过了1、2而去关注3。甚至他们中的乐观主义者,直接跳过123,开始充满自信地迎接这个“未来趋势”了。是Alpha狗狗给我们的信心过于足了吗?
要知道,真正的AI工作者甚至对问题1都没有足够的自信。不错,AlphaGo毫无疑问“已经做出来了”,但不要忘了,围棋再复杂,它仍然是一个游戏;从一个两页纸即可将规则全部讲明的游戏到一个充斥着复杂场景的现实世界,有着巨大的鸿沟需要跨越。在NIPS 2016上,可以明确地感受到,DeepMind已经处在一个深陷游戏之中无法自拔的尴尬状态——不仅几乎所有的paper都是以游戏为demo的,甚至有些研究的目标都是奔着游戏而去的(例如有的工作研究人类玩游戏时是否用到了先验知识,有的工作研究人类玩游戏时的学习曲线,分的很细)。游戏在这些的研究中并不只是一个用来展示的demo,而就是研究的核心。DeepMind在AlphaGo之后一直宣称的进军医疗这件事,却在NIPS 2016上几乎不被人提起。
有意思的是,擅长营销的Andrew NG在NIPS 2016的演讲还趁机轻踩了一下他不太涉足的无监督学习和增强学习。他在白板上画了这样三条曲线。
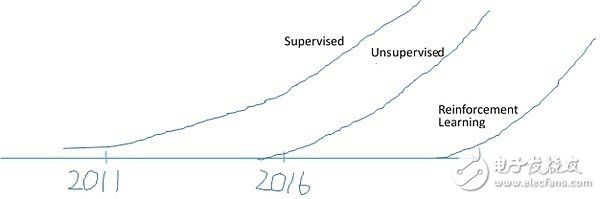
意思是说,有监督学习的应用在2011年起步,到现在已经比较成熟了;无监督学习刚刚起步;增强学习的真实应用则还是遥远的未来。虽然脱不开为自己营销之嫌,这个说法本身还是比较靠谱的。连李开复也在几天前发的一篇长文《AI创业的十个真想》中,白纸黑字地说到“AlphaGo本身没有商业价值”。像下围棋这样的增强学习技术应用到真实的生活生产,产生游戏之外的价值,不说是一个遥远的未来,至少还是一个技术上比较不确定的事情。
第二个奇怪是没有人问问题2。普通人并不奇怪,奇怪的是产品经理这样一群人,他们在平日工作中对一个产品的应用前景的拷问,可以苛责到极致;而到了AI这件事上,却看不到一篇在产品技术层面客观剖析应用前景的文章。一个最明显的例子是最近大热的聊天机器人。不知道“聊天机器人将是下一代的操作系统”这样一个牛皮是如何在业界传播开来的?再重复一遍,“聊天机器人将是下一代的操作系统”,这话听上去就需要很多解释和论证吧?反正每当我在一个网站正常服务点不进去,不得不求助在线客服或者是电话客服(指人工客服)的时候,就已经很不爽了。当然不是说别人想法都和我一样,但是对于一个与用户直接交互的界面,是不是至少应该做个用户调研,再说“聊天机器人将是下一代的操作系统”这样的话?
第三个奇怪有关成本。Facebook围棋项目负责人田渊栋前日在自乎专栏上写过这样一段文字:
“在八月份美国围棋大会上,我有幸见到了AlphaGo的主要贡献者黄士杰(AjaHuang)和樊麾。我问他们,我们用了大概80到90块GPU来训练模型,我是否可以在演讲时说我们用了AlphaGo百分之一的GPU?那时Aja神秘地笑了笑说:具体数字不能讲。不过,也许小于百分之一吧。”
一块GPU大约两万人民币,算算总共要花多少钱吧。这还远不是全部,还有以月记的计算时间、电力/带宽消耗,以及那么多份200w美金的工资。
当然这样估算成本未必科学。我想表达的是,唯独在AI这件事上,人们似乎表达出了对于成本问题前所未有的宽容。这宽容体现在除了真正在一线做AI的工程师,极少有人关注成本问题。另外需要澄清的是这里疑问的点是“人们不关注”,并不是想表达“AlphaGo劳民伤财了”这个意思。个人内心里其实是把AlphaGo当做一件伟大的艺术品来看待的,而艺术品是无价的——只有在讨论艺术品的时候可以用“无价”这个度量,对于商业产品不行。
三、该怎么看待这件事情
不要预期过高,不要预期过高,不要预期过高。泡沫时代的我们已经习惯了对未来事物预期过高。被透支的预期甚至成了维持经济的重要支柱。只是每一次泡沫破灭都会很疼。很怀念曾经那个时代,在那个时代里,科学技术的进步源于对真理的信仰与热爱,而不是为了填补预期与现实的反差。然而那个时代已经回不去了。
勤奋一些,学习真相。巴菲特从来不投资自己不熟悉的业务。如果不能判断一件事情,那么就应该真正学习它,知道它是什么东西,在积累了足够知识之后做出判断。如果少一些分不清“深度学习”和“机器学习”的关系的人,或许这个世界也会少一些错误的风向。接受无知而被营销者和媒体的观点摆布,是一件非常可怕的事情。就像我们有时不能从政府那里得到真相,在AI这个学界和工业界各种势力利益关系已经非常庞大复杂的领域内,仅凭我们听到的,恐怕很难得到真相。
如果AlphaGo仅仅是AlphaGo,那该多好啊。
-
郁闷发泄专家(史无前例版)2009-06-12 5250
-
双11,为梦想,周立功Linux开发板i.MX280A史无前例梦想价仅49元2015-11-11 5547
-
史无前例,详细视频讲解开发Android端APP开发!!2017-07-13 4591
-
嵌入式技术究竟是什么?2019-10-17 3028
-
云计算巨头纷纷降价,腾讯云幅度史无前例2016-11-12 1010
-
Thred:对增强现实功能的Sweep应用程序进行独立的、史无前例的测试2018-01-17 4328
-
华为将史无前例地向客户开放其计算机源代码2018-02-14 1159
-
在科技领域中奥迪A8L将ABB推向了史无前例的高峰2018-04-17 1282
-
中国移动史无前例出现4G用户流失,现阶段努力发展固网宽带2018-05-23 1799
-
小米新无线充电技术曝光 电功率达到了史无前例的50W2018-10-13 5545
-
福特,准备启动一轮史无前例的大规模裁员2019-03-11 1351
-
一场史无前例的芯片人才争夺战正在上演2020-09-28 2704
-
华秋SMT全面降价 推出史无前例的三弹重磅福利2021-11-17 2326
-
华秋SMT决定全面降价 推出史无前例的三弹重磅福利2021-11-18 2390
全部0条评论

快来发表一下你的评论吧 !
