

设计出优化性能的实时控制系统关键
伺服与控制
描述
设计实时控制系统的工程师不断面临优化性能的挑战。这些系统需要最小的延迟,其中采样、处理和输出之间的时间延迟必须处在紧凑的时间窗口内,以便满足性能规格。控制系统的核心是用于计算控制信号的数学密集算法。利用可快速有效地执行数学运算的微控制器(MCU)是实现这一目标的关键。理想情况下,该MCU将能够在中央处理单元(CPU)执行其它所需任务的同时执行实时控制回路。一些系统甚至可能需要支持使用相同MCU的电力线通信(PLC)。
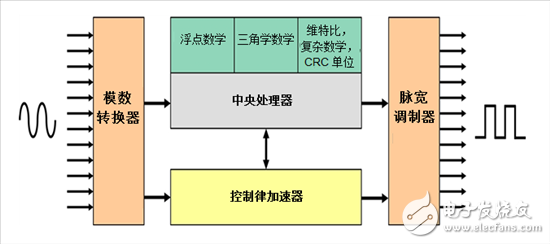
为此,TI C2000™MCU集成了多达四个集成的片上硬件加速器,可在许多实时应用中显著提高设备性能。四个加速器包括浮点单元(FPU)、实时协处理器控制律加速器(CLA)、三角计算单元(TMU)和维特比、复数数学、CRC单元(VCU)。
每个C2000 MCU设计围绕快速32位定点C28x CPU内核,其利用数字信号处理器和微控制器架构的最佳特性。将FPU添加到C28x定点内核(C28x + FPU)使设备能够无缝支持硬件IEEE-754单精度浮点格式操作。由于浮点数学与定点数学相比提供了大的动态范围,因此开发代码变得更容易,且编程器不再需要关心缩放和饱和。另一个优点是其提高了鲁棒性,因为值不会在溢出或下溢时缠绕数字线,就像在定点数学上。使用编译器工具可轻松编写软件,并移植现有代码。FPU指令是标准C28x指令集的扩展,因此大多数指令将在一个或两个流水线周期中运行,有些指令可并行完成。平均来说,与定点数学相比,使用浮点数学可让性能提高多于2.5倍。
CLA是独立的32位浮点硬件加速器,专为数学密集型计算而设计。它与C28x CPU并行执行实时控制算法,有效地将设备的计算性能提高了一倍。通常,使用CLA的设备在执行各种控制应用时,其性能改进与C28x CPU相比,提高了约1.3倍。此外,通过使用CLA来检修时间关键功能,C28x CPU可释放其他任务,例如通信和诊断。由于CLA可直接访问诸如ADC和PWM模块等各种控制外设,因此它能够最小化延迟并具有快速触发响应。 CLA能够在ADC采样转换完成的相同周期读取ADC结果寄存器,从而提供ADC的“即时”读数,及减少采样到输出延迟,并让系统更快地响应频率控制环路。凭借CLA的性能和效率优势,可在单个设备上实现完整的复杂实时控制应用。
TMU是FPU的扩展,通过有效地执行控制系统应用中常用的三角和算术运算,进一步增强了C28x + FPU的指令集。与FPU一样,TMU是一个与C28x CPU紧密耦合的IEEE-754浮点加速器,但在FPU提供通用浮点数学支持的情况下,TMU专注于加速几个特定的三角数学运算,否则周期相当密集。这些三角运算包括正弦、余弦、反正切、除法和平方根。编译器工具内置支持自动生成TMU指令,从而显著减少了周期,并显著提高了三角运算的性能。TMU的一个关键优点是现有的C28x设计可实现即时优势,而无需重写任何代码,同时可移植性得以保持,因为相同的代码可用于具有和不具有TMU支持的TI MCU。
VCU是一个紧密耦合的定点加速器,将通信应用程序的性能提高了约七倍。此外,将VCU用于这些类型的应用时,可无需单独处理器即可节省成本。除了通信,VCU对于通用的信号处理应用(例如滤波和频谱分析)非常有用。当使用典型的MCU来支持各种通信技术时,存在消耗大部分处理能力的四个关键操作:维特比解码、复杂的快速傅里叶变换(FFT)、复杂的滤波器和循环冗余校验(CRC)。使用VCU的硬件功能,通过提高软件实现的性能,可让应用程序大大受益。
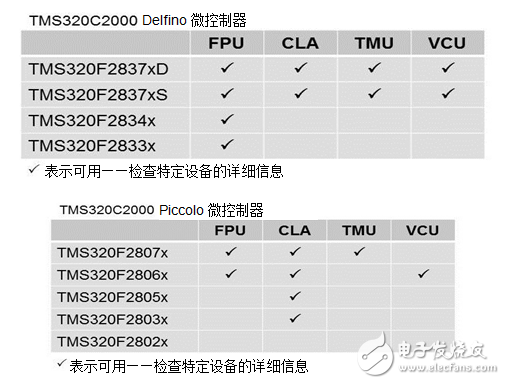
结合高性能C28x CPU内核与各种高级硬件加速器,可实现复杂的实时控制系统所需的快速和高效的处理能力。
了解有关C2000 MCU加速器的更多信息:
订购C2000 Delfino MCU F28379D LaunchPad开发套件
阅读更多内容:“加速器:增强C2000 MCU系列的功能”
观看C2000 Delfino F28377S LaunchPad开发套件培训
观看C2000 F28379D双核LaunchPad技术概述
- 相关推荐
- m
-
单片机控制系统的抗干扰优化设计2011-04-13 0
-
Linux和Android系统故障和优化性能的方法和流程探讨2019-07-22 0
-
实时控制系统需要不断优化性能2019-07-23 0
-
隔离器件怎么助力工业电机控制性能优化?2019-08-01 0
-
通过特定传感器参数优化实时控制系统的三个技巧2022-11-03 0
-
实时控制系统的功能块解读2022-11-03 0
-
增强型MCU支持快速实时控制系统2022-08-22 604
-
实时控制系统中传感器的选择技巧2022-09-05 449
-
在实时控制系统中使用传感器优化数据可靠性的3个技巧2022-10-28 282
-
使用STM32高速缓存优化性能和能效2022-11-21 189
-
优化实时控制系统数据捕获的三个技巧2022-12-22 585
-
云优化性能:使用基于闪存的存储的I/O密集型工作负载2023-08-28 81
全部0条评论

快来发表一下你的评论吧 !
