

借助NVIDIA NIM加速AI应用部署
描述
大语言模型(LLM)在企业组织中的应用日益广泛,许多企业都将其整合到 AI 应用中。虽然从基础模型着手十分高效,但需要花费一定的精力才能将它们整合到生产就绪型环境中。NVIDIA NIM简化了这一过程,使企业能够在数据中心、云、工作站和 PC 等任何位置运行 AI 模型。
专为企业设计的 NIM 提供一整套预构建云原生微服务,这些微服务能够被轻松地整合到现有基础设施中。这些微服务经过精心的维护和持续的更新,具有开箱即用的性能,并确保您能够获得 AI 推理技术的最新进展。
适用于大语言模型的全新 NVIDIA NIM
基础模型的增长源于其能够满足各种企业需求的能力,但没有任何一个单一的模型能够完全满足企业的需求,企业通常会根据特定的数据需求和 AI 应用工作流,在其用例中使用不同的基础模型。
考虑到企业需求的多样化,我们扩大了 NIM 的阵容,涵盖了Mistral-7B、Mixtral-8x7B和Mixtral-8x22B,这三个基础模型在特定任务中的表现都十分出色。
图 1. 新的 Mixtral 8x7B Instruct NIM
可从 NVIDIA API 中获取
Mistral 7B NIM
Mistral 7B Instruct 模型在文本生成和语言理解任务中表现出色。该模型可在单个 GPU 上运行,非常适合语言翻译、内容生成和聊天机器人等应用。将 Mistral 7B NIM 部署至 NVIDIA 数据中心 GPU 后,开发者在内容生成任务中可实现的开箱即用性能(token/秒),其性能最多可提升至没有使用 NIM 时的 2.3 倍。
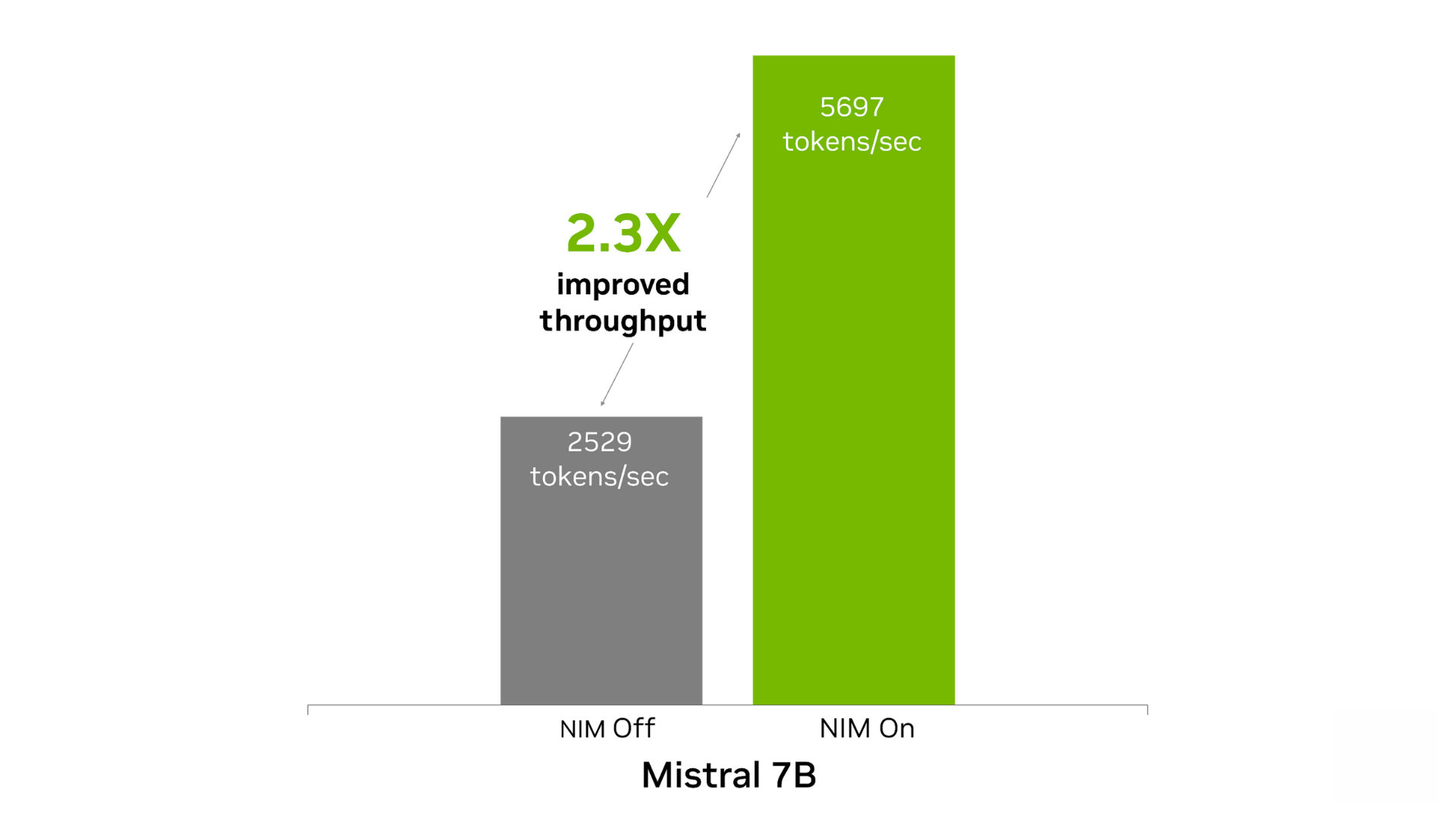
图 2. Mistral 7B NIM 提高了内容生成的吞吐量
基于 1 个 NVIDIA Tensor Core GPU,输入 500 个 token,输出 2,000 个 token。NIM 开启时:FP8。吞吐量为 5,697 token/秒,TTFT 为 0.6 秒,ITL 为 26 毫秒。NIM 关闭时:FP16。吞吐量为 2,529 token/秒,TTFT 为 1.4 秒,ITL 为 60 毫秒。
Mixtral-8x7B 和
Mixtral-8x22B NIM
Mixtral-8x7B 和 Mixtral-8x22B 模型采用混合专家(MoE)架构提供快速且经济高效的推理。这两个模型在总结、问题解答和代码生成等任务中表现出色,非常适合需要实时响应的应用。
相较无 NIM 运行的情况,NIM 可以提高这两种模型的开箱即用性能。当用于内容生成且在 1 个 NVIDIA Tensor Core GPU 上运行时,Mixtral-8x7B NIM 的吞吐量最多可提高 4.1 倍。在内容生成和翻译用例中,Mixtral-8x22B NIM 的吞吐量最多可提高 2.9 倍。
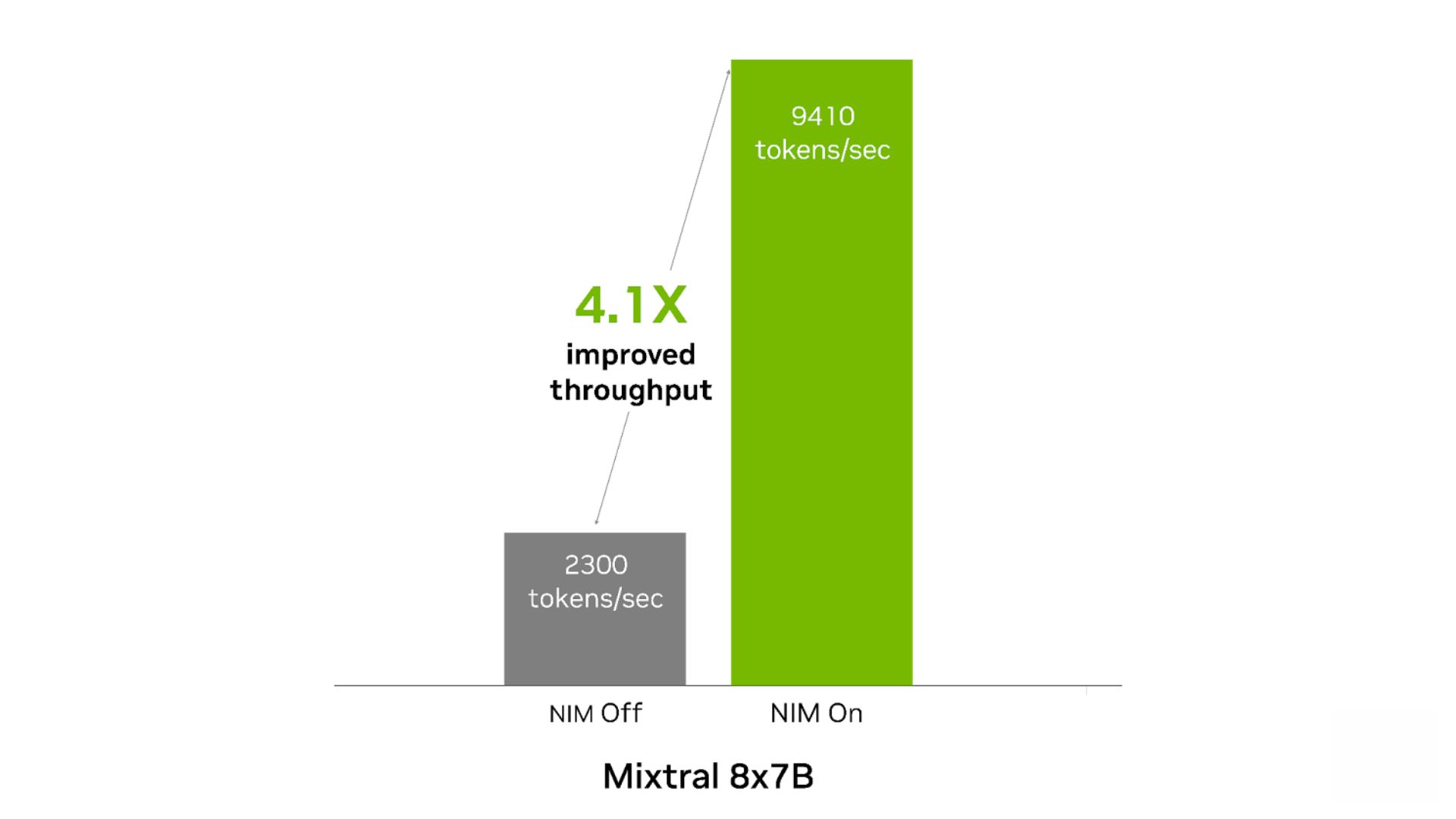
图 3. Mixtral 8x7B NIM
提高了内容生成的吞吐量
输入 500 个 token,输出 2,000 个 token。200 个并发请求。NIM 开启时:FP8。吞吐量为 9,410 token/秒。TTFT 为 740 毫秒,ITL 为 21 毫秒。NIM 关闭时:FP16。吞吐量为 2,300 token/秒,TTFT 为 1,321 毫秒,ITL 为 86 毫秒。
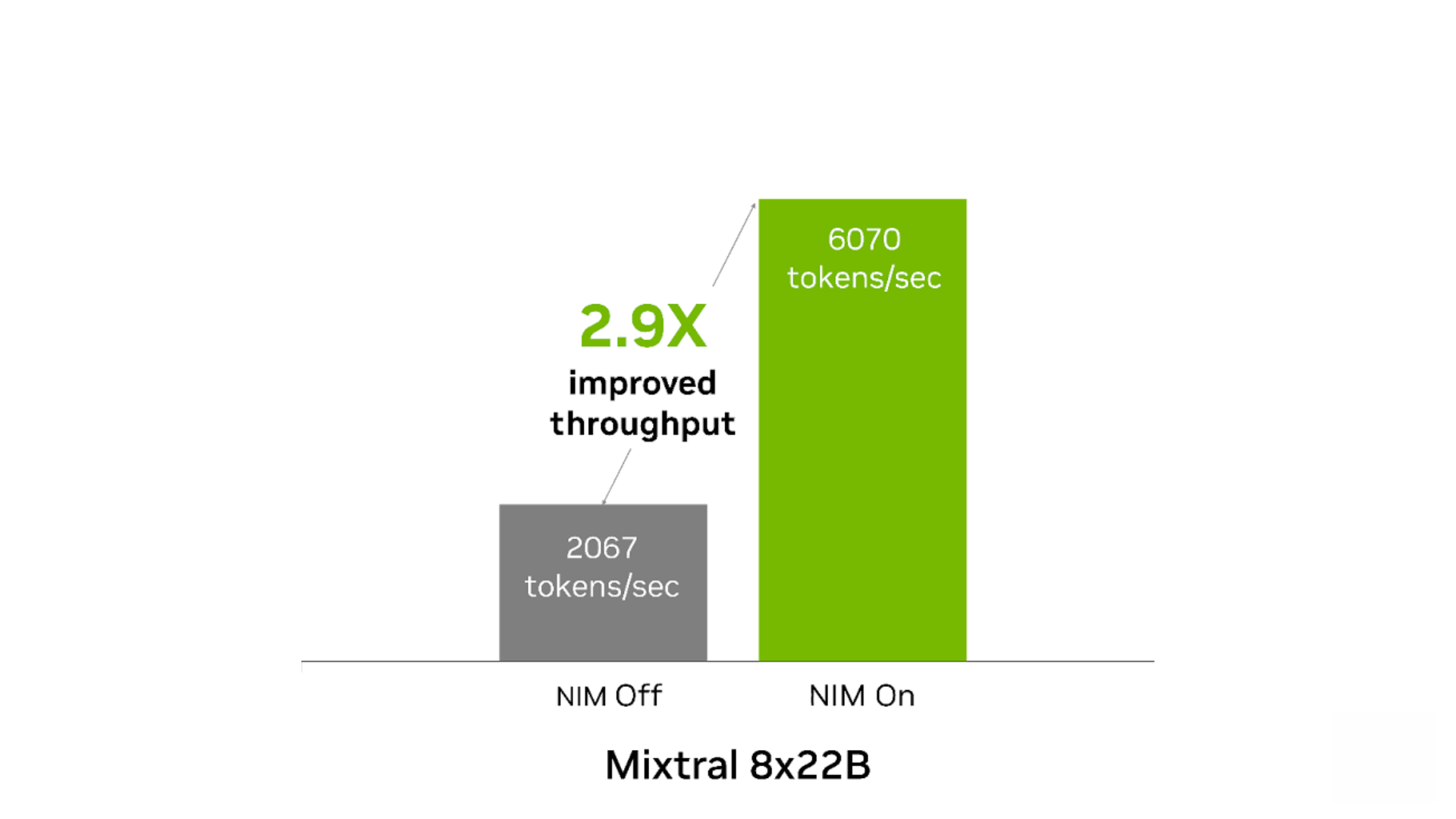
图 4. Mixtral 8x22B NIM
提高了内容生成和翻译的吞吐量
输入 1,000 个 token,输出 1,000 个 token。250 个并发请求。NIM 开启时:吞吐量为 6,070 token/秒,TTFT 为 3 秒,ITL 为 38 毫秒。NIM 关闭时:吞吐量为 2,067 token/秒,TTFT 为 5 秒,ITL 为 116 毫秒。
借助 NVIDIA NIM 加速 AI 应用部署
开发者可以使用 NIM 缩短构建适用于生产部署的 AI 应用所需的时间,同时还能提高 AI 推理效率,并降低运营成本。借助 NIM,经过优化的 AI 模型实现了容器化,为开发者带来了以下优势:
性能和规模
这些云驱动的微服务可提供低延迟、高吞吐量并可以轻松扩展的 AI 推理,使用 Llama 3 70B NIM,最多可将吞吐量提高 5 倍。NIM 还支持精确的微调模型,无需从头开始构建即可实现超高的准确性,进一步提高了 AI 推理性能。
易于使用
通过简化与现有系统的整合来加快进入市场的速度,并在 NVIDIA 加速基础设施上提供最佳性能。借助专为企业使用而设计的 API 和工具,开发者可以实现其 AI 能力的最大化。
安全性和易管理性
确保您的 AI 应用和数据具有强大的可控性和安全性。通过NVIDIA AI Enterprise,NIM 支持在任何基础设施上的灵活自托管部署,提供企业级软件、严格的验证以及与 NVIDIA AI 专家的直接连线。
AI 推理的前景:
NVIDIA NIM 及其他延伸
NVIDIA NIM 代表了 AI 推理领域的重大进步。随着各行各业对 AI 应用需求的日益增长,高效部署这些应用变得至关重要。想要利用 AI 变革力量的企业可以使用 NVIDIA NIM,将预构建的云原生微服务轻松整合到现有系统中,以此加快产品推出速度,保持在创新领域的领先地位。
未来的 AI 推理将超越单个 NVIDIA NIM。随着对先进 AI 应用的需求不断增长,连接多个 NVIDIA NIM 将变得至关重要。这种微服务网络将带来能够协同工作和适应各种任务的高度智能化应用,从而深入改变我们使用技术的方式。如要在您的基础设施上部署 NIM 推理微服务,请查看“使用 NVIDIA NIM 部署生成式 AI 的简单指南”:
NVIDIA 定期发布新的 NIM,为企业提供最强大的 AI 模型,助企业应用一臂之力。请访问API 目录,查找适用于 LLM、视觉、检索、3D 和数字生物学模型的最新 NVIDIA NIM。
-
NVIDIA AI微服务现已与AWS集成,加速药物研发和数字医疗2024-05-09 2710
-
NVIDIA NIM 革命性地改变模型部署,将全球数百万开发者转变为生成式 AI 开发者2024-06-03 720
-
英伟达推出AI模型推理服务NVIDIA NIM2024-06-04 1718
-
英伟达推出全新NVIDIA AI Foundry服务和NVIDIA NIM推理微服务2024-07-25 1763
-
NVIDIA NIM:打造AI领域的AI-in-a-Box,提高AI开发与部署的高效性2024-07-30 2030
-
借助NVIDIA NIM微服务助力可口可乐公司扩展生成式AI内容2024-08-13 1526
-
NVIDIA 携手全球合作伙伴推出 NIM Agent Blueprints,助力企业打造属于自己的 AI2024-08-28 739
-
NVIDIA NIM助力企业高效部署生成式AI模型2024-10-10 1712
-
日本企业借助NVIDIA产品加速AI创新2024-11-19 2271
-
NVIDIA推出适用于网络安全的NIM Blueprint2024-11-20 1831
-
全新NVIDIA NIM微服务实现突破性进展2024-11-21 1675
-
NVIDIA 发布保障代理式 AI 应用安全的 NIM 微服务2025-01-17 434
-
英伟达GTC2025亮点:Oracle与NVIDIA合作助力企业加速代理式AI推理2025-03-21 1910
-
NVIDIA携手诺和诺德借助AI加速药物研发2025-06-12 1755
-
Cadence 借助 NVIDIA DGX SuperPOD 模型扩展数字孪生平台库,加速 AI 数据中心部署与运营2025-09-15 1843
全部0条评论

快来发表一下你的评论吧 !
