

IB Verbs和NVIDIA DOCA GPUNetIO性能测试
描述
NVIDIA DOCA GPUNetIO 是 NVIDIA DOCA SDK 中的一个库,专门为实时在线 GPU 数据包处理而设计。它结合了 GPUDirect RDMA 和 GPUDirect Async 等技术,能够创建以 GPU 为中心的应用程序,其中 CUDA 内核可以直接与网卡(NIC)通信,从而绕过 CPU 发送和接收数据包,并将 CPU 排除在关键路径之外。
此前,DOCA GPUNetIO 与 DOCA Ethernet 和 DOCA Flow 仅限于处理以太网传输层上的数据包传输。随着 DOCA 2.7 的推出,现在有一组扩展的 API 使 DOCA GPUNetIO 能够从 GPU CUDA 内核使用 RoCE 或 InfiniBand 传输层来直接支持 RDMA 通信。
本文探讨了由支持 DOCA GPUNetIO 的 GPU CUDA 内核控制的全新远程直接内存访问(RDMA)功能,并与性能测试(perftest)微基准测试进行了性能比较。
请注意,RDMA 缩写描述的协议允许从一台计算机的内存到另一台计算机的内存进行远程直接内存访问,而无需任何一台计算机的操作系统介入。操作示例包括 RDMA 写入和 RDMA 读取。它不能将与 GPUDirect RDMA 混淆,后者与 RDMA 协议无关。GPUDirect RDMA 是 NVIDIA 在 GPUDirect 技术系列中启用的技术之一,使网卡能够绕过 CPU 内存副本和操作系统例程,直接访问 GPU 内存发送或接收数据。任何使用以太网、InfiniBand 或 RoCE 的网络框架都可以启用 GPUDirect RDMA。
具有 GPUNetIO 的 RDMA GPU 数据路径
RDMA 可以在两台主机的主内存之间提供直接访问,而无需操作系统、缓存或存储的介入。这可实现高吞吐量、低延迟和低 CPU 利用率的数据传输。这是通过向远程主机(或对等主机)注册并共享本地内存区域来实现的,以便远程主机知道如何访问它。
两个对等主机需要通过 RDMA 交换数据的应用程序通常遵循三个基本步骤:
步骤 1–本地配置:每个对等主机在本地创建 RDMA 队列和内存缓冲区,以便与其他对等主机共享。
步骤 2–交换信息:使用带外(OOB)机制(例如,Linux 套接字),对等主机交换有关要远程访问的 RDMA 队列和内存缓冲区的信息。
步骤 3–数据路径:两个对等主机执行 RDMA 读取、写入、发送和接收,以使用远程内存地址来交换数据。
DOCA RDMA 库支持按照上面列出的三个步骤通过 InfiniBand 或 RoCE 实现 RDMA 通信,所有这些步骤均由 CPU 执行。通过引入全新的 GPUNetIO RDMA 功能,应用程序可以使用在 GPU 上的 CUDA 内核执行这 3 个步骤从而代替 CPU 来管理 RDMA 应用程序的数据路径,而步骤 1 和 2 保持不变,因为它们与 GPU 数据路径无关。
将 RDMA 数据路径移到 GPU 上的好处与以太网用例中的好处相同。在数据处理发生在 GPU 上的网络应用程序中,将网络通信从 CPU 卸载到 GPU,使其能够成为应用程序的主控制器,消除与 CPU 交互所需的额外延迟,以及了解数据何时准备就绪及数据位于何处,这也释放了 CPU 资源。此外,GPU 可以同时并行管理多个 RDMA 队列,例如,每个 CUDA 块都可以在不同的 RDMA 队列上发布 RDMA 操作。
IB Verbs 和 DOCA GPUNetIO 性能测试
在 DOCA 2.7 中,引入了一个新的 DOCA GPUNetIO RDMA 客户端——服务器代码示例,以展示新 API 的使用并评估其正确性。本文分析了 GPUNetIO RDMA 功能与 IB Verbs RDMA 功能之间的性能比较,重现了众所周知的 perftest 套件中的一个微基准测试。
简而言之,perftest 是一组微基准测试,用于使用基本的 RDMA 操作测量两个对等主机(服务器和客户端)之间的 RDMA 带宽(BW)和延迟。尽管网络控制部分发生在 CPU 中,但可以通过使用 --use_cuda 标志启用 GPUDirect RDMA 来指定数据是否驻留在 GPU 内存中。
一般来说,RDMA 写入单向带宽基准测试(即 ib_write_bw)在每个 RDMA 队列上发布一系列相同大小消息的写入请求,用于固定迭代次数,并命令网卡执行已发布的写入,这就是所谓的“按门铃”程序。为了确保所有写入都已发出,在进入下一次迭代之前,它会轮询完成队列,等待确认每个写入都已正确执行。然后,对于每个消息大小,都可以检索发布和轮询所花费的总时间,并以 MB/s 为单位计算带宽。
图 1 显示了 IB Verbs ib_write_bw perftest 主循环。在每次迭代中,CPU 都会发布一个 RDMA 写入请求列表,命令网卡执行这些请求(按门铃),然后等待完成后再进行下一次迭代。启用 CUDA 标志后,要写入的数据包将从 GPU 内存本地获取,而不是从 CPU 内存。
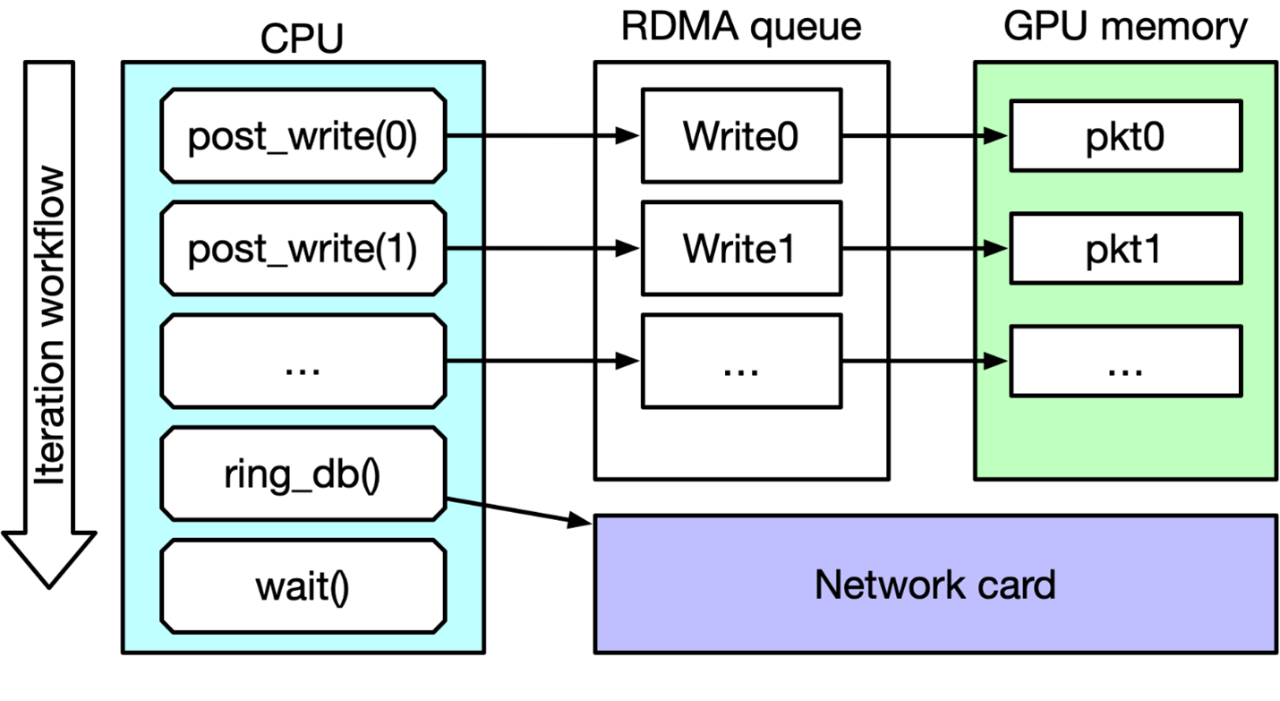
图 1:IB Verbs ib_write_bw perftest 主循环
实验是使用 DOCA 库重现 ib_write_bw 微基准测试,使用 DOCA RDMA 作为 CPU 上的控制路径以建立客户端-服务器连接,并使用 DOCA GPUNetIO RDMA 作为数据路径,在 CUDA 内核中发布写入。这种比较不是同类比较,因为 perftest 使用 GPUDirect RDMA 来传输数据,但网络通信由 CPU 控制,而 DOCA GPUNetIO 同时使用 GPUDirect RDMA 和 GPUDirect Async 来控制网络通信和来自 GPU 的数据传输。目标是证明 DOCA GPUNetIO RDMA 性能与被视为基准的 IB Verbs perftest 相当。
为了重现 ib_write_bw 数据路径并测量发布每种消息大小的 RDMA 写入操作所需的时间,CPU 会记录一个 CUDA 事件,启动 rdma_write_bw CUDA 内核,然后记录第二个 CUDA 事件。这应该可以很好地近似 CUDA 内核使用 DOCA GPUNetIO 功能发布 RDMA 写入所需的时间(以毫秒为单位),如下面的代码段 1 所示。
Int msg_sizes[MAX_MSG] = {....};
for (int msg_idx = 0; msg_idx < MAX_MSG; msg_idx++) {
do_warmup();
cuEventRecord(start_event, stream);
rdma_write_bw<<>>(msg_sizes[msg_idx], …);
cuEventRecord(end_event, stream);
cuEventSynchronize(end_event);
cuEventElapsedTime(&total_ms, start_event, end_event);
calculate_result(total_ms, msg_sizes[msg_idx], …)
}
在下面的代码段 2 中,对于给定的迭代次数,CUDA 内核 rdma_write_bw 使用按照弱模式的 DOCA GPUNetIO 设备功能并行发布一系列 RDMA 写入,CUDA 块中的每个 CUDA 线程都会发布一个写操作。
__global__ void rdma_write_bw(struct doca_gpu_dev_rdma *rdma_gpu,
const int num_iter, const size_t msg_size,
const struct doca_gpu_buf_arr *server_local_buf_arr,
const struct doca_gpu_buf_arr *server_remote_buf_arr)
{
struct doca_gpu_buf *remote_buf;
struct doca_gpu_buf *local_buf;
uint32_t curr_position;
uint32_t mask_max_position;
doca_gpu_dev_buf_get_buf(server_local_buf_arr, threadIdx.x, &local_buf);
doca_gpu_dev_buf_get_buf(server_remote_buf_arr, threadIdx.x, &remote_buf);
for (int iter_idx = 0; iter_idx < num_iter; iter_idx++) {
doca_gpu_dev_rdma_get_info(rdma_gpu, &curr_position, &mask_max_position);
doca_gpu_dev_rdma_write_weak(rdma_gpu,
remote_buf, 0,
local_buf, 0,
msg_size, 0,
DOCA_GPU_RDMA_WRITE_FLAG_NONE,
(curr_position + threadIdx.x) & mask_max_position);
/* Wait all CUDA threads to post their RDMA Write */
__syncthreads();
if (threadIdx.x == 0) {
/* Only 1 CUDA thread can commit the writes in the queue to execute them */
doca_gpu_dev_rdma_commit_weak(rdma_gpu, blockDim.x);
/* Only 1 CUDA thread can flush the RDMA queue waiting for the actual execution of the writes */
doca_gpu_dev_rdma_flush(rdma_gpu);
}
__syncthreads();
}
return;
}
图 2 描述了代码段 2。在每次迭代时,GPU CUDA 内核都会并行发布一系列 RDMA 写入请求,CUDA 块中的每个 CUDA 线程一个。在同步所有 CUDA 线程后,只有线程 0 命令网卡执行写入并等待完成,然后刷新队列,最后再进行下一次迭代。
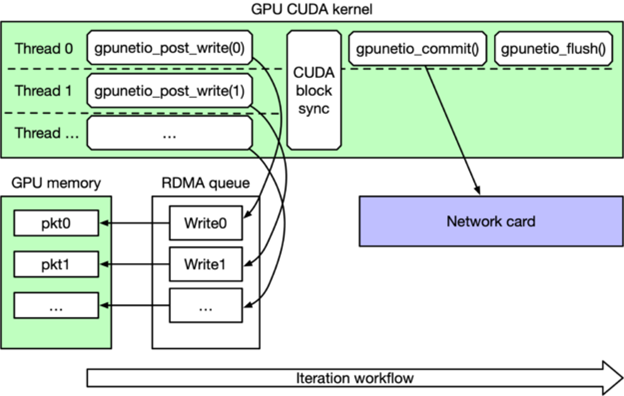
图 2:DOCA GPUNetIO RDMA 写入性能测试主循环
为了比较性能,为 IB Verbs perftest 和 DOCA GPUNetIO perftest 设置了相同的参数:1 个 RDMA 队列,2048 次迭代,每次迭代执行 512 次 RDMA 写入,测试消息大小从 64 字节到 4096 字节。
RoCE 基准测试已在具有不同 PCIe 拓扑的两个系统上执行:
系统 1:HPE ProLiant DL380 Gen11 系统,配备 NVIDIA GPU L40S 和运行在 NIC 模式的 BlueField-3 卡、Intel Xeon Silver 4410Y CPU。GPU 和网卡连接到同一 NUMA 节点上的两个不同 PCIe 插槽(无专用 PCIe 交换机)。
系统 2:Dell R750 系统,配备 NVIDIA H100 GPU 和 ConnectX-7 网卡、Intel Xeon Silver 4314 CPU。GPU 和网卡连接到不同 NUMA 节点上的两个不同 PCIe 插槽(GPUDirect 应用程序的最坏情况)。
如下图所示,两种 perftest 在两个系统上实现了完全可比较的峰值带宽(图 3 和图 4),报告以 MB/s 为单位。
具体来说,在图 3 中,DOCA GPUNetIO perftest 带宽优于图 4 中报告的 DOCA GPUNetIO perftest 带宽,因为系统上的拓扑不同,这不仅影响从 GPU 内存到网络的数据移动(GPUDirect RDMA),而且影响 GPU 和网卡之间的内部通信控制 RDMA 通信(GPUDirect Async)。
由于代码中不同逻辑的性质,时间和带宽采用不同的方法来测量,IB Verbs perftest 使用系统时钟,而 DOCA GPUNetIO perftest 则依赖于 CUDA 事件,后者可能具有不同的内部时间测量开销。
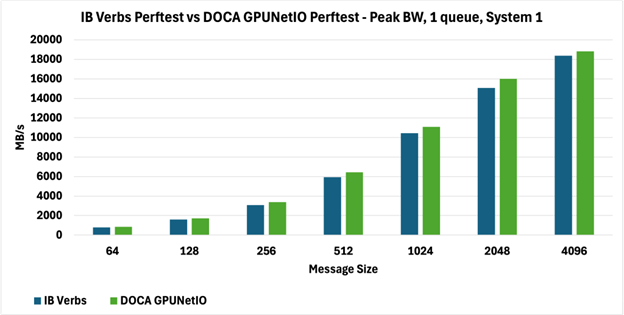
图 3:Perftest 对系统 1 上 1 个队列的峰值带宽(MB/s)进行 IB Verbs 与 DOCA GPUNetIO 的比较
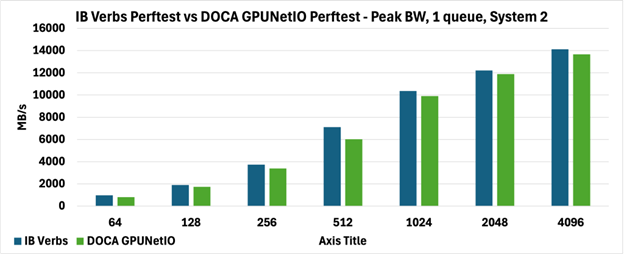
图 4:Perftest 对系统 2 上 1 个队列的峰值带宽(MB/s)进行 IB Verbs 与 DOCA GPUNetIO 的比较
请注意,像 perftest 这样的应用程序并不是展示 GPU 利用率优势的最佳工具,因为可实现的并行化程度非常低。DOCA GPUNetIO perftest 进行 RDMA 写入是以并行方式发布在队列中的(512 次写入,每次写入由不同的 CUDA 线程执行),但发布所需的时间非常短(约 4 微秒)。大部分 perftest 时间都花在网卡实际执行 RDMA 写入、通过网络发送数据和返回上。
这项实验可以被认为是成功的,因为它证明了使用 DOCA GPUNetIO RDMA API 与使用常规 IB Verbs 相比不会引入任何相关开销,并且在运行相同类型的工作负载和工作流程时可以满足性能目标。ISV 开发者和最终用户可以使用 DOCA GPUNetIO RDMA,获得 GPUDirect 异步技术的优势,将通信控制卸载到 GPU。
这种架构选择提供了以下优势:
更具可扩展性的应用程序,能够同时并行管理多个 RDMA 队列(通常每个 CUDA 块一个队列)。
能够利用 GPU 提供的高度并行性,使多个 CUDA 线程并行处理不同的数据,并以尽可能低的延迟在同一队列上发布 RDMA 操作。
更低的 CPU 利用率,使解决方案独立于平台(不同的 CPU 架构不会导致显著的性能差异)。
更少的内部总线事务(例如 PCIe),因为不需要将 GPU 上的工作与 CPU 活动同步。CPU 不再负责发送或接收 GPU 必须处理的数据。
-
NVIDIA DOCA 1.5长期支持版本发布2022-11-10 1844
-
使用 NVIDIA DOCA GPUNetIO 进行内联 GPU 数据包处理2023-01-13 1959
-
NVIDIA DOCA 应用代码分享活动开启注册!2023-04-11 1208
-
利用 NVIDIA DOCA 2.0 改变 IPsec 的部署2023-05-15 1121
-
《揭秘 NVIDIA DPU & DOCA》 开讲啦!2023-06-08 1254
-
《揭秘 NVIDIA DPU & DOCA》 第二讲上线!2023-06-16 1626
-
《揭秘 NVIDIA DPU & DOCA》 第三讲上线!2023-06-29 1072
-
《揭秘 NVIDIA DPU & DOCA》 第五讲上线!2023-07-12 1509
-
《揭秘 NVIDIA DPU & DOCA》 第六讲上线!2023-07-20 1196
-
《揭秘 NVIDIA DPU & DOCA》 第七讲上线!2023-07-27 1129
-
《揭秘 NVIDIA DPU & DOCA》 第八讲上线!2023-08-03 1276
-
使用 NVIDIA DOCA GPUNetIO 实现实时网络处理功能2023-08-16 1699
-
NVIDIA DOCA 2.5 长期支持版本发布2023-12-26 1209
-
基于NVIDIA DOCA 2.6实现高性能和安全的AI云设计2024-02-23 1789
-
NVIDIA DOCA-OFED的主要特性2024-11-09 2209
全部0条评论

快来发表一下你的评论吧 !
