

堆栈和内存的基本知识
描述
本文主要聊聊关于堆栈的内容。包括堆栈和内存的基本知识。常见和堆栈相关的 bug,如栈溢出,内存泄漏,堆内存分配失败等。后面介绍软件中堆栈统计的重要性,以及如何使用工具工具软件中堆栈使用的范围,并给出在软件开发中,如何降低堆栈问题,优化堆栈的一些实践。
随着代码行数从几千增长到百万甚至更多,嵌入式软件变得日益复杂,但总体目标依然是实现软件的需求,达到稳健、正确且快速执行。快速执行需要以最优方式管理可用的 CPU 和内存资源,这对内存空间(尤其是 RAM)有限的嵌入式系统来说是一项挑战。
为此,必须通过执行堆栈和堆分析对 RAM 的使用情况进行详细了解。开发人员手动估计堆栈和堆负载是一项艰巨的任务,哪怕对于小程序来说也是这样。如果估计不正确,则可能会导致堆栈溢出和一些未定义的行为。因此,常见的编码规范要求强制执行内存分配使用最佳实践来避免不必要的开销。但是,堆栈仍是 RAM 的必要组成部分,需要得到优化利用。
堆栈和内存
先简单聊聊内存,内存是计算机中重要的单元,而堆栈是内存中最重要的应用组成。
C 语言的内存分配
在嵌入式系统中,内存通常被分为几个主要区域,每个区域存储不同类型的数据,这些区域在使用方式、性能以及目的上各不相同。
下面主要说说堆区和栈区
1. 堆区
堆区用于动态内存分配,程序运行时可以从堆区动态地分配和释放内存。其管理通常由程序的内存管理子系统(如 C 语言的 malloc 和 free 函数)负责。堆的大小和使用效率直接影响程序的性能和稳定性。而内存管理子系统通常都是程序员主动调用申请和释放的。堆区位于 RAM 中,因此其内容在断电后会丢失。
2. 栈区
栈区主要用于存储局部变量、函数参数和返回地址等。栈具有后进先出(LIFO)的特性,每当调用新的函数时,函数的局部变量和返回地址就会被压入栈中,函数返回时这些数据又会被弹出。栈区的系统自动管理的。栈区虽然高效但空间有限,这也导致栈溢出成为嵌入式系统中常见的问题之一。
堆区(Heap Memory)和栈区(Stack Memory)有以下几个主要的区别:
1. 管理方式:
栈是自动管理的,由编译器控制。当函数调用时,栈帧(Stack Frame)被自动创建和销毁。
堆是手动管理的,需要程序员使用特定的函数(如malloc、free在C中)来分配和释放内存。
2. 分配和释放速度:
栈的分配和释放速度通常较快,因为它们是连续分配的,并且不需要复杂的内存管理。
堆的分配和释放速度较慢。差距的时间主要用在操作系统查找空闲内存块,并可能涉及将内存块从非连续的区域移动到连续的区域。
3. 内存碎片:
栈内存是连续分配的,通常不会产生内存碎片。
堆内存是动态分配的,每次大小不同,这导致堆上分配内存不连续,从而出现内存的碎片化。这需要定期进行内存整理(Memory Compaction)来优化性能。
堆栈统计为什么如此重要?
从上面关于堆栈的知识,我们知道堆栈的大小是有限的,堆栈对于程序运行极为重要。
当可用堆栈小于代码需求时,就会发生堆栈溢出。然而,当为系统配置的堆栈大于需求时,内存又会被浪费。开发人员必须持续一致地估计安全关键型应用中最差情形下的堆栈使用量,以防止软件运行时发生 RAM 不足的情况。
在设计嵌入式系统时,合理规划和管理内存区域对于确保系统的性能、稳定性和可靠性十分重要。开发者需要根据应用的具体需求和硬件资源,做出恰当的内存使用决策。合理分配堆栈大小,通过堆栈统计来优化堆栈使用,对于确保系统的可靠性和安全性至关重要。
内存管理不当,会导致内存泄露(堆泄露)。而内存泄漏可能会堆栈的不足,进而出现堆栈溢出,这些是编程中常见的错误之一,而且极其严重。对于常规的桌面级应用,这些错误发生会导致程序卡顿或重启崩溃。而对于涉及生命安全和重大财产安全的关键应用系统和软件,堆栈不足可能导致数据损坏,系统不稳定和崩溃,进而导致人员伤亡和财产损失。
典型的内存问题
Memory Leak (内存泄漏)
内存泄漏更准确的说法是,堆内存泄漏 (heap leak),是程序员在分配一段内存后,分配的内存未被释放且无法再次访问时发生。
#includevoid leakMemory() { int *leak = (int*)malloc(sizeof(int) * 100); // 漏掉了释放操作 } int main() { leakMemory(); return 0; }
例子中,指针 leak 作为局部变量,在退出 leakMemory 函数后,没有释放且找不到地址无法再次访问。
Stack Leak (栈泄漏)
当程序中的局部变量大量消耗栈资源,而又没有退出该函数,导致 stack 溢出,大量的溢出可能会导致栈的不足,从而发生 overflow 的情况。这种一般发生在递归函数或者函数中有大循环,其有定义局部变量,比如下面的代码
void stackLeak(int n) {
char buffer[1024];
printf("Leaking stack memory %d,%p\n", n, (void *)buffer);
if(n>1)
stackLeak(n - 1);
}
int main() {
stackLeak(500);
return 0;
}
在 32G 内存的笔记本上,运行到 373 次就栈溢出了。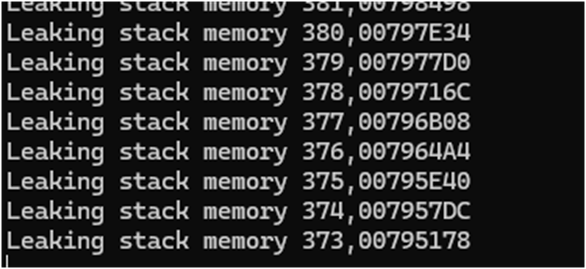

Buffer overflow(缓冲区溢出)
Buffer overflow(缓冲区溢出)是一种常见的安全漏洞,通常发生在当程序试图向一个固定长度的缓冲区写入过多数据时,一般发生在字符操作的时候。尽管缓冲区溢出通常与堆栈溢出有所区别——前者涉及对固定大小缓冲区的写操作超出其边界,后者是函数调用和局部变量使用过多堆栈空间——但在实践中,缓冲区溢出经常导致堆栈上的数据被覆盖,因此可以视为一种堆栈不足引发的问题。
以下是一个使用C语言的示例,展示了一个简单的缓冲区溢出漏洞:
#include#include void vulnerableFunction(char *str) { char buffer[10]; strcpy(buffer, str); // 不安全的拷贝,拷贝应该指定大小 printf("Buffer content: %s ", buffer); } int main() { char largeData[] = "这是一个超长的字符串,远远超过了buffer的容量"; vulnerableFunction(largeData); return 0; }
在这个例子中,vulnerableFunction 函数定义了一个长度为 10 的字符数组 buffer 作为缓冲区。然后,它使用 strcpy 函数将传入的字符串 str 拷贝到 buffer 中。如果 str 的长度超过了buffer的容量(在这个例子中是 10 个字符),就会发生缓冲区溢出。strcpy 不会检查目标缓冲区的大小,所以它会继续写入数据,直到遇到源字符串的结束符 \0。
这种溢出可能会覆盖堆栈上的其他重要数据,比如其他局部变量、函数返回地址等,导致程序行为异常,甚至允许黑客执行任意代码。
为了避免这种安全漏洞,应该使用更安全的函数,如 strncpy,它允许指定目标缓冲区的最大长度,从而避免溢出:
strncpy(buffer, str, sizeof(buffer) - 1); buffer[sizeof(buffer) - 1] = '�'; // 确保字符串以 null 结束
这样就可以显著减少因缓冲区溢出导致的安全风险。
Stack Frame Corruption (栈帧破坏)
栈帧中是函数的局部变量和函数调用时候的相关开销。当我们对局部变量进行错误的操作时候,可能会破坏栈帧,导致函数的返回地址或其他重要数据被覆盖。举例如下。 #include
上面的例子中,有明显的数组越界的问题。同时,由于该数组是局部变量,对数组外的数进行操作,可能会导致周边的栈帧给改写,从而导致系统崩溃。
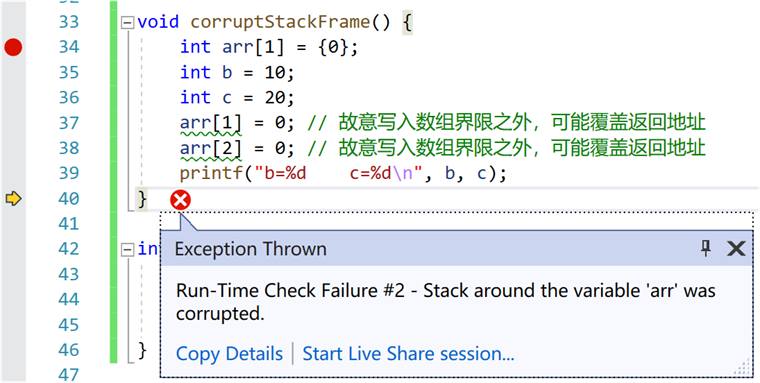
当然栈帧是否被改写可能涉及很多系统的很多方面。这里不详细讨论。
Memory Allocation Failed
当请求的内存无法被分配时发生。当请求大量内存时,可能会因为内存不足或者没有足够的连续内存导致分配内存失败。
#includeint main() { //分配大量内存 int *bigArray = (int*)malloc(sizeof(int) * 1000000000); if (bigArray == NULL) { printf("Memory allocation failed ") //内存分配失败 } free(bigArray); return 0; }
其他内存管理方面的问题还包括重复分配内存,野指针问题等,都会直接或间接的导致可用堆栈的减少。
历史上,许多著名的软件漏洞,如 Heartbleed、Spectre 等,都与堆栈管理不当有关。通过对堆栈进行统计,我们可以提前发现潜在的安全隐患,避免类似问题的发生。
Heartbleed 漏洞是由于 OpenSSL 库中的堆栈管理错误导致的。该漏洞允许攻击者读取内存中的敏感信息,甚至可以修改内存内容。通过对堆栈进行统计和分析,可以发现 OpenSSL 库中的堆栈使用不当,从而避免 Heartbleed 漏洞的产生。
堆栈统计促进软件开发和性能优化
堆栈统计不仅可以帮助开发者确定程序在运行时堆栈的使用情况,还可以指导开发者进行性能优化。通过准确的堆栈使用数据,开发者可以合理分配堆栈大小,既避免了堆栈溢出的风险,也确保了系统资源的高效利用。
性能瓶颈定位:堆栈统计可以帮助开发者快速定位应用程序中的性能瓶颈。通过分析哪些函数调用最频繁或哪些调用耗时最长,开发者可以集中优化这些热点区域,从而提高整体应用性能。
资源使用分析:它可以帮助开发者理解应用程序如何使用系统资源,例如CPU和内存。这对于识别和修复内存泄漏、过度的CPU使用等问题非常重要。
代码质量改进:通过堆栈统计,开发者可以识别代码中的不良实践或设计模式,如不必要的递归、过度复杂的函数调用等,进而重构代码以提高其可读性和可维护性。
优化决策依据:堆栈统计提供了量化数据,帮助开发团队做出基于数据的决策。这些数据可以用来确定优化的优先级,决定哪些优化措施可以带来最大的性能提升。
性能回归检测:在软件开发周期中,新的代码提交可能会引入性能回归。定期进行堆栈统计可以帮助及时发现性能下降,确保软件性能持续稳定。
用户体验提升:应用程序的响应速度直接影响用户体验。通过优化那些影响性能的关键部分,可以显著提升应用的响应速度和流畅度,从而提高用户满意度。
成本效益分析:对于需要大量计算资源的应用程序,堆栈统计可以帮助识别和优化资源密集型操作,从而减少对硬件资源的需求,降低运营成本。
总之,堆栈统计是理解和优化软件性能的强大工具。通过定期进行堆栈统计和分析,开发团队可以确保他们的应用程序运行高效,提供优秀的用户体验,并以最佳的资源使用效率运作。
人工 VS 工具统计
在有相关统计工具之前,嵌入式系统的堆栈都是人工统计。此举虽然可行,但是实际操作中存在许多问题和不足。
耗时耗力烧脑。人工统计需要彻底了解函数调用的深度、所有局部变量的细节,以及执行过程中随时发生的中断帧的大小对于复杂的嵌入式系统而言几乎是不可行的。
漫长而又容易出错的过程
没法保证准确性,特别是在面对大量并发执行的任务和复杂的函数调用关系时,更是这样。
实时更新,则更是无法做到,每一次代码的变更,可能都需要做大量的重新统计。
工具分析能够详细分析出函数调用深度、局部变量和返回参数的堆栈估计、嵌套中断以及执行期间发生的中断帧的大小,解决人工统计的上述问题之外,还有另外两个优势。
动态分析:一些高级的堆栈统计工具支持运行时分析,能够实时监控堆栈的使用情况,及时发现潜在的堆栈溢出风险。这种一般是芯片厂家或者合作厂家提供的调试工具中。
能够对目标机进行测试和测量。对战统计最好在真实硬件上获得实际的堆栈使用量数据。许多开发环境都具有硬件模拟功能,并提供实时堆栈分析功能。在实际硬件上执行堆栈分析,并创建溢出场景来测试故障安全例程
可视化效果好。许多工具提供图形化界面,直观展示堆栈的使用情况,函数调用情况以及随着函数调用,堆栈使用的变化,帮助开发者更容易理解和分析数据。
市面上常见的堆栈统计软件
堆栈统计工具有以下几类
一类是由编译和 调试工具,有芯片厂商提供的,也有第三方的。比如 ARM Keil MDK,IAR Embedded Workbench 等等
第二类是第三方的调试工具,GNU 项目,如 GNU Debugger,Lauterbach Trace32
第三类是开源堆栈工具,如 Valgrind,FreeRTOS 中的 vTaskList
最后一类是静态分析工具。这一类以 polyspace code prover 为代表。
以上就是关于内存、堆栈方面的一些介绍,以及常见的一些内存泄露相关的例子,这些例子会直接或间接到导致内存泄露,进而导致可用堆栈的减少,软件长时间运行会导致性能下降,甚至崩溃等问题。处理好这些问题是解决堆栈问题的前提。
另外并介绍了堆栈统计的收益。
下一篇我们看看,如何使用形式化工具进行堆栈统计。
-
堆栈内存和堆内存之间的区别2023-08-07 1284
-
电工基本知识2009-09-21 1601
-
LDO基本知识2010-02-09 725
-
MIMO 的基本知识介绍2010-06-25 598
-
功率MOSFET的基本知识2006-04-16 2898
-
继电器基本知识2006-06-30 2267
-
网络基本知识教程2010-01-13 1914
-
HFC网络基本知识2011-11-08 1605
-
LED基本知识2012-05-30 704
-
安全用电基本知识2016-01-14 1150
-
UPS电源的基本知识2016-09-13 1032
-
光纤基本知识2016-12-15 1099
-
线程的基本知识2020-02-04 4632
-
CPLD/FPGA的基本知识2021-03-30 1518
-
电气基本知识科普2023-09-09 7211
全部0条评论

快来发表一下你的评论吧 !
