

借助Arm Neoverse加速Hugging Face模型
描述
作者:Arm 基础设施事业部高级产品经理 Ashok Bhat
人工智能 (AI) 有望触及并改变我们生活的方方面面。如今,包括医疗保健、金融、制造、教育、媒体和运输等在内的各行各业都在利用 AI 进行创新。它们通过运行复杂的 AI 工作负载来提高生产力,改善消费者决策,提升教育体验等,而这些都需要消耗大量算力和数据中心电力。
如今,数据中心已经非常耗电,而随着 AI 部署的扩大和底层基础模型规模的扩展,耗电量只会继续增加。面对这一挑战,Arm 力求在不增加能耗的情况下提高 AI 能力。随着生成式 AI 和基础模型的普及,专用计算硬件的可用性及其高成本给部署带来了困难。与此同时,大模型需要消耗大量资源,加剧了原有的问题。随着小语言模型和量化等技术的兴起,开发者开始考虑针对机器学习 (ML) 使用 CPU。规模较小的模型不仅效率高,而且可以针对特定应用进行定制,因此部署起来更切合实际,成本效益也更高。
Arm 基于 Neoverse 的最新 CPU 平台为云数据中心提供高性能、高能效的处理器。借助 Arm Neoverse,云服务提供商能够灵活地定制芯片并优化软件与系统,以应对要求苛刻的工作负载,同时获得出色的性能和能效。正因如此,所有主要的云服务提供商均采用了 Neoverse 技术来设计其计算平台,从而满足开发者对 AI 和 ML 等各种云工作负载的需求。
Hugging Face 中的热门开源模型可在 CPU 上高效、高性能地运行。模型的部署是一项耗时且极具挑战性的任务,通常需要精通 ML 和底层模型代码的专业知识。Hugging Face Pipeline 将复杂的代码抽象化,使开发者能够使用 Hugging Face Hub 中的任何模型进行推理。开发者在构建 AI 应用和项目时,借助 Arm 平台赋能的云实例,可受益于云基础设施资源的便利性,实现高能效并节省成本。
面向 ML 的 Neoverse CPU 的关键特性
长期以来,CPU 得益于只需使用单指令就能同时处理多个数据点,进而能够实现数据级并行和性能提升,这种技术被称为单指令流多数据流 (SIMD)。Arm Neoverse CPU 支持 Neon 和可伸缩矢量扩展 (SVE) 等先进的 SIMD 技术,能够加速 HPC 和 ML 中的常见算法。
通用矩阵乘法 (GEMM) 是 ML 中的一种基本算法,它对两个输入矩阵进行复杂的乘法运算,得到一个输出。Armv8.6-A 架构新增了 SMMLA 和 FMMLA 指令,可在宽度为二或四的阵列上同时执行这些乘法运算,从而将取指周期缩短 2 至 4 倍,将计算周期缩短 4 至 16 倍。诸多基于 Arm 架构的服务器处理器均含有这些指令,包括 AWS Graviton3、Graviton4、NVIDIA Grace、Google Axion 和 Microsoft Cobalt。
在许多用例中,这些关键特性可为 ML 带来诸多优势,其中包括:
图像分类:这是监督学习的一种形式,可将特定标签或类别分配给整个图像。
对象检测:这是在图像或视频中定位对象实例的计算机视觉技术。
自然语言处理:这是一种 AI 形式,可赋予机器阅读、理解和推导人类语言含义的能力。
自动语音识别:这是一种 ML 形式,可将人们的语音内容转换为文本。
推荐系统:这是利用数据向用户推荐项目或内容的 ML 算法。
小语言模型 (SLM):这是大语言模型 (LLM) 的精简版,其架构更简单、参数更少,训练所需的数据和时间也更少。
凭借这些 ML 推理能力,基于 Arm Neoverse 平台的 AWS Graviton3 处理器在性能方面比上一代 AWS Graviton2 处理器提高了三倍。下面来看一个情感分析用例。
利用 Hugging Face Pipeline 进行情感分析
情感分析是一项重要的 AI 技术,它能找出文本中的情绪和观点。企业可以利用该技术来理解客户的想法,评估用户对品牌的看法,并制定营销决策。但是,要想高效运行情感分析模型,对计算资源的要求非常高。本文将深入探讨 Arm Neoverse CPU 如何加快情感分析,带来更快且更有成效的 AI 驱动的洞察。
具体来说,我们将着重于如何在 Arm Neoverse CPU 上使用 pytorch.org 提供的默认 PyTorch 软件包来加速 NLP PyTorch 模型(BERT、DistilBERT 和 RoBERTa)。我们将使用 Hugging Face Transformer 情感分析 Pipeline 来运行这些模型
Hugging Face Transformer 通过 Pipeline 这一强大工具来简化预训练模型的使用。这些 Pipeline 可在后台处理复杂问题,让开发者能够专注于解决实际问题。例如,如果你想要分析一段文本的情感,只需将该文本输入 Pipeline。它将进行正面或负面的情感分类,你无需担心模型的加载、分词等其他技术细节。
这段代码使用 Pipeline 来检查用户所输入文本的情感。它在后台使用 Hugging Face Model Hub 中的现成模型。
代码

输出

你还可以使用模型参数来指定所选模型。
pipe = pipeline("sentiment-analysis", model=”distilbert-base-uncased”)
在现有应用中添加情感分析时,需要考虑延迟问题。对于实时用例而言,响应时间少于 100ms 通常被视为瞬时响应。但对于具体需求而言,更长的延迟有时也可接受。
AWS Graviton 处理器的性能
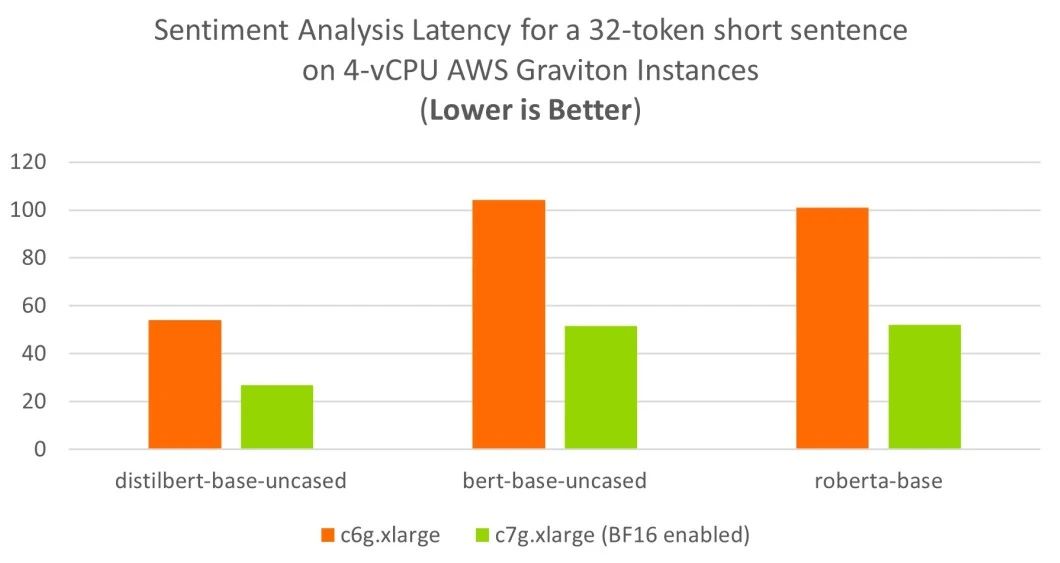
我们选取了两篇评论,一篇较短(使用 BertTokenizer 分词后,有 32 个词元),另一篇较长(使用 BertTokenizer 分词后,有 128 个词元),并在 AWS Graviton2 (c6g) 和 AWS Graviton3 (c7g) 上进行了基准测试。
如下图所示,对于短篇评论的情感分析,AWS Graviton2 (c6g) 和 AWS Graviton3 (c7g) 仅使用四个虚拟 CPU (vCPU) 就达到了理想的 100ms 实时延迟目标。
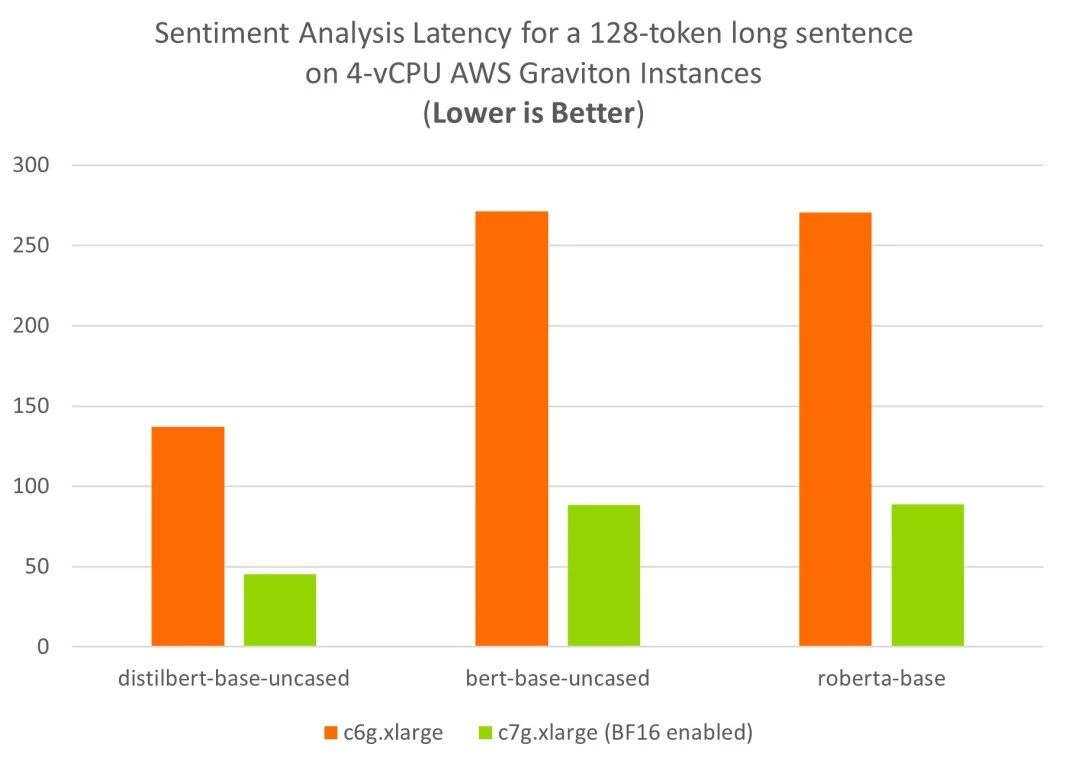
对于较长评论的情感分析,启用了 BF16 的 AWS Graviton3 (c7g) 可使用四个 vCPU 达到理想的实时延迟目标。与使用 Arm Neoverse N1 CPU 的上一代 c6g 实例相比,基于 Neoverse V1 的 c7g 实例性能可提升三倍之多。
基准测试设置
我们对以下 AWS EC2 实例进行了基准测试:
使用 Arm Neoverse N1 CPU 的 c6g.xlarge 实例
使用 Arm Neoverse V1 CPU 的 c7g.xlarge 实例
各实例均有四个 vCPU。我们通过以下软件对实例进行设置:
Ubuntu Server 22.04 LTS (HVM) - ami-0c1c30571d2dae5c9(64 位 (x86))和 ami-0c5789c17ae99a2fa(64 位 (Arm))
PyTorch 2.2.2
Transformers 4.39.1
并按照以下设置步骤操作:
1.sudo apt-get update
2.sudo apt-get install python3 python3-pip
3.pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
4.pip3 install transformers
有关安装过程的详细信息,请参阅《Arm PyTorch 安装指南》。除了该指南外,《在 AWS Graviton 处理器上实现 PyTorch 推理性能调优》中也提供了一些针对 Arm 平台的调优参数。(链接见文末)
为了进行基准测试,我们在所有平台上启用了 BF16 快速数学内核,如下所示。在 AWS Graviton3 上,这使得 GEMM 内核能够使用硬件中提供的 BF16 MMLA 指令。
export DNNL_DEFAULT_FPMATH_MODE=BF16
我们使用了两篇评论,分别是一篇短评论和一篇长评论。
短评论原文:“I'm extremely satisfied with my new Ikea Kallax; It's an excellent storage solution for our kids. A definite must have.”
长评论原文:“We were in search of a storage solution for our kids, and their desire to personalize their storage units led us to explore various options. After careful consideration, we decided on the Ikea Kallax system. It has proven to be an ideal choice for our needs. The flexibility of the Kallax design allows for extensive customization. Whether it’s choosing vibrant colors, adding inserts for specific items, or selecting different finishes, the possibilities are endless. We appreciate that it caters to our kids’ preferences and encourages their creativity. Overall, the boys are thrilled with the outcome. A great value for money.”
我们使用情感分析 Pipeline 对三个 NLP 模型(distilbert-base-uncased、bert-base-uncased 和 roberta-base)进行了评估
对于每个模型,我们均测量短句和长句的执行时间。在基准测试函数中,我们进行了运行 Pipeline 100 次的热身,以确保结果的一致性。接着,我们测量每次运行的执行时间,并计算平均值和第 99 百分位值。
结 论
通过 AWS Graviton3,你只需使用四个 vCPU,就能将情感分析添加到现有应用中,并可满足严格的实时延迟要求。
AWS Graviton3 搭载的 Arm Neoverse V1 CPU 具有 BF16 MMLA 扩展等 ML 特定功能,为 Hugging Face 情感分析 PyTorch 模型提供了出色的推理性能。
欢迎各位开发者使用自己的模型进行尝试。友情提示,根据模型的不同,你可能需要对性能进行微调。
-
NVIDIA Alpamayo 1模型在Hugging Face平台下载量已突破10万次2026-03-04 1183
-
Hugging Face推出最小AI视觉语言模型2025-01-24 1806
-
Arm Neoverse如何加速实现AI数据中心2024-11-26 1206
-
Hugging Face科技公司推出SmolLM系列语言模型2024-07-23 1539
-
亚马逊云携手AI新创企业Hugging Face,提升AI模型在定制芯片计算性能2024-05-23 1047
-
Hugging Face推出开源机器人代码库LeRobot2024-05-09 1597
-
Arm新Arm Neoverse计算子系统(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N32024-04-24 3393
-
Hugging Face LLM部署大语言模型到亚马逊云科技Amazon SageMaker推理示例2023-11-01 2097
-
Hugging Face被限制访问2023-10-22 3484
-
Arm Neoverse™ N1 PMU指南2023-08-12 918
-
NVIDIA 与 Hugging Face 将连接数百万开发者与生成式 AI 超级计算2023-08-09 3967
-
NASA 携手 IBM 发布 Hugging Face 平台最大开源地理空间 AI 基础模型2023-08-08 1839
-
Hugging Face更改文本推理软件许可证,不再“开源”2023-07-31 1573
-
Arm Neoverse V1的AWS Graviton3在深度学习推理工作负载方面的作用2022-08-31 3947
全部0条评论

快来发表一下你的评论吧 !
