

周立功教你学程序设计技术:做好软件模块的分层设计,回调函数要这样写
电子说
描述
第二章为程序设计技术,本文为2.1.3 回调函数。
>>>> 2.1.3 回调函数
>>> 1. 分层设计
分层设计就是将软件分成具有某种上下级关系的模块,由于每一层都是相对独立的,因此只要定义好层与层之间的接口,从而每层都可以单独实现。比如,设计一个保险箱电子密码锁,其硬件部分大致包括键盘、显示器、蜂鸣器、锁与存储器等驱动电路,因此根据需求将软件划分为硬件驱动层、虚拟层与应用层三大模块,当然每个大模块又可以划分为几个小模块,下面将以键盘扫描为例予以说明。
(1)硬件驱动层
硬件驱动层处于模块的最底层,直接与硬件打交道。其任务是识别哪个键按下了,实现与硬件电路紧密相关的部分软件,更高级的功能将在其它层实现。虽然通过硬件驱动层可以直达应用层,由于硬件电路变化多样,如果应用层直接操作硬件驱动层,则应用层势必依赖于硬件层,则最好的方法是增加一个虚拟层应对硬件的变化。显然,只要键盘扫描的方法不变,则产生的键值始终保持不变,那么虚拟层的软件也永远不会改变。
(2)虚拟层
它是依据应用层的需求划分的,主要用于屏蔽对象的细节和变化,则应用层就可以用统一的方法来实现了。即便控制方法改变了,也无需重新编写应用层的代码。
(3)应用层
应用层处于模块的最上层,直接用于功能的实现,比如,应用层对外只有一个“人机交互”模块,当然内部还可以划分几个模块供自己使用。三层之间数据传递的关系非常清晰,即应用层->虚拟层->硬件驱动层,详见图 2.2,图中的实线代表依赖关系,即应用层依赖于虚拟层,虚拟层依赖于硬件驱动层。基于分层的架构具有以下优点:
-
降低系统的复杂度:由于每层都是相对独立的,层与层之间通过定义良好接口交互,每层都可以单独实现,从而降低了模块之间的耦合度;
-
隔离变化:软件的变化通常发生在最上层与最下层,最上层是图形用户界面,需求的变化通常直接影响用户界面,大部分软件的新老版本在用户界面上都会有很大差异。最下层是硬件,硬件的变化比软件的发展更快,通过分层设计可以将这些变化的部分独立开来,让它们的变化不会给其它部分带来大的影响;
-
有利于自动测试:由于每一层具有独立的功能,则更易于编写测试用例;
-
有利于提高程序的可移植性:通过分层设计将各种平台不同的部分放在独立的层里。比如,下层模块是对操作系统提供的接口进行包装的包装层,上层是针对不同平台所实现的图形用户界面。当移植到不同的平台时,只需要实现不同的部分,而中间层都可以重用。
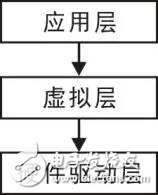
图 2.2 三层结构示意
应用层处于模块的最上层,直接用于功能的实现,比如,应用层对外只有一个“人机交互”模块,当然内部还可以划分几个模块供自己使用。三层之间数据传递的关系非常清晰,即应用层->虚拟层->硬件驱动层,详见图 2.2,图中的实线代表依赖关系,即应用层依赖于虚拟层,虚拟层依赖于硬件驱动层。基于分层的架构具有以下优点:
-
降低系统的复杂度:由于每层都是相对独立的,层与层之间通过定义良好接口交互,每层都可以单独实现,从而降低了模块之间的耦合度;
-
隔离变化:软件的变化通常发生在最上层与最下层,最上层是图形用户界面,需求的变化通常直接影响用户界面,大部分软件的新老版本在用户界面上都会有很大差异。最下层是硬件,硬件的变化比软件的发展更快,通过分层设计可以将这些变化的部分独立开来,让它们的变化不会给其它部分带来大的影响;
-
有利于自动测试:由于每一层具有独立的功能,则更易于编写测试用例;
-
有利于提高程序的可移植性:通过分层设计将各种平台不同的部分放在独立的层里。比如,下层模块是对操作系统提供的接口进行包装的包装层,上层是针对不同平台所实现的图形用户界面。当移植到不同的平台时,只需要实现不同的部分,而中间层都可以重用。
>>> 2. 隔离变化
(1)好莱坞原则(Hollywood)
类似键盘扫描这样的模块,其共性是各层之间的调用关系,不可能随着时间而改变,即便上下层之间形成依赖关系,采用直接调用方式是最简单的。为了降低层与层之间的耦合,层与层之间的通信必须按照一定的规则进行。即上层可以直接调用下层提供的函数,但下层不能直接调用上层提供的函数,且层与层之间绝对不能循环调用。因为层与层之间的循环依赖会严重妨碍软件的复用性和可扩展性,使得系统中的每一层都无法独立构成一个可复用的组件。虽然上层也可以调用相邻下层提供的函数,但不能跨层调用。即下层模块实现了在上层模块中声明并被高层模块调用的接口,这就是著名的好莱坞(Hollywood)扩展原则:“不要调用我,让我调用你。”当下层需要传递数据给上层时,则采用回调函数指针接口隔离变化。通过倒置依赖的接口所有权,创建了一个更灵活、更持久和更易于修改的结构。
实际上,由上层模块(即调用者)提供的回调函数的表现形式就是在下层模块中通过函数指针调用另一个函数,即将回调函数的地址作为实参初始化下层模块的形参,由下层模块在某个时刻调用这个函数,这个函数就是回调函数,详见图 2.3。其调用方式有两种:
-
在上层模块A调用下层模块B的函数中,直接调用回调函数C;
-
使用注册的方式,当某个事件发生时,下层模块调用回调函数。
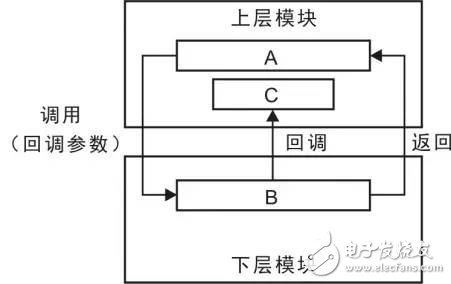
图 2.3 回调函数的使用
在初始化时,上层模块A将回调函数C的地址作为实参传递给下层模块B。在运行中,当下层模块需要与上层模块通信时,调用这个回调函数。其调用方式为A→B→C,上层模块A调用下层模块B,在B的执行过程中,调用回调函数将信息返回给上层模块。对于上层模块来说,C不仅监视B的运行状态,而且干预B的运行,其本质上依然是上层模块调用下层模块。由于增加了回调函数,即可在运行中实现动态绑定,下面将以标准的冒泡排序函数对一个任意类型的数据进行排序为例予以说明。
(2)数据比较函数
假设待排序的数据为int型,即可通过比较相邻数据的大小,做出是否交换数据的处理。当给定两个指向int型变量的指针e1和e2时,则比较函数返回一个数。如果*e1小于*e2,那么返回的数为负数;如果*e1大于*e2,那么返回的数为正数;如果*e1等于*e2,那么返回的数为0,详见程序清单 2.4。
程序清单 2.4 compare_int()数据比较函数
1 int compare_int(const int *e1, const int *e2)
2 {
3 return *e1 - *e2; // 升序比较
4 }
5
6 int compare_int(const int *e1, const int *e2)
7 {
8 return *e2 - *e1; // 降序比较
9 }
由于任何数据类型的指针都可以给void*指针赋值,因此可以利用这一特性,将void*指针作为数据比较函数的形参。当函数的形参声明为void *类型时,虽然bubbleSort()冒泡排序函数内部不知道调用者会传递什么类型的数据过来,但调用者知道数据的类型和对数据的操作方法,那就由调用者编写数据比较函数。
由于在运行时调用者要根据实际情况才能决定调用哪个数据比较函数,因此根据比较操作的要求,其函数原型如下:
typedef int (*COMPARE)(const void *e1, const void *e2);
其中的e1、e2是指向2个需要进行比较的值的指针。当返回值< 0时,表示e1 < e2;当返回值= 0时,表示e1 = e2;当返回值> 0时,表示e1 > e2。
当用typedef声明后,COMPARE就成了函数指针类型,有了类型就可以定义该类型的函数指针变量。比如:
COMPARE compare;
此时,只要将函数名(比如,compare_int)作为实参初始化函数的形参,即可调用相应的数据比较函数。比如:
COMPARE compare=compare_int;
虽然编译器看到的是一个compare,但调用者实现了多种不同类型的compare,即可根据接口函数中的类型改变函数的行为方式,通用数据比较函数的实现详见程序清单 2.5。
程序清单 2.5 compare数据比较函数的实现
1 int compare_int(const void *e1, const void *e2)
2 {
3 return (*((int *)e1) - *((int *)e2)); // 升序比较
4 }
5
6 int compare_int_invert(const void *e1, const void *e2)
7 {
8 return *(int *)e2 - *(int *)e1; // 降序比较
9 }
10
11 int compare_vstrcmp(const void *e1, const void *e2)
12 {
13 return strcmp(*(char**)e1, *(char**)e2); // 字符串比较
14 }
注意,如果e1是很大的正数,而e2是大负数,或者相反,则计算结果可能会溢出。由于这里假设它们都是正整数,从而避免了风险。
由于该函数的参数声明为void *类型,因此数据比较函数不再依赖于具体的数据类型。即可将算法的变化部分独立出来,无论是升序还是降序或字符串比较完全取决于回调函数。注意,之所以不能直接用strcmp()作为字符串的比较,因为bubbleSort()传递的是类型为char **的数组元素的地址&array[i],而不是类型为char*的array[i]。
(3)bubbleSort()冒泡排序函数
标准函数bubbleSort()是C中使用函数指针的经典示例,该函数是对一个具有任意类型的数组进行排序,其中单个元素的大小和要比较的元素的函数都是给定的。其原型初定如下:
bubbleSort(参数列表);
既然bubbleSort()是对数组中的数据排序,那么bubbleSort()必须有一个参数保存数组的起始地址,且还有一个参数保存数组中元素的个数。为了通用还是在数组中存放void *类型的元素,这样一来就可以用数组存储用户传入的任意类型的数据,因此用void *类型参数保存数组的起始地址。其函数原型如下:
bubbleSort(void *base, size_t nmemb);
由于数组的类型是未知的,那么数组中元素的长度也是未知的,同样也需要一个参数来保存。其函数原型进化为:
bubbleSort(void *base, size_t nmemb, size_t size);
其中,size_t是C标准库中预定义的类型,专门用于保存变量的大小。参数base和nmemb标识了这个数组,分别用于保存数组的起始地址和数组中元素的个数,size存储的是打包时单个元素的大小。
此时,如果将指向compare()的指针作为参数传递给bubbleSort(),即可“回调”compare()进行值的比较。由于排序是对数据的操作,因此bubbleSort()没有返回值,其类型为void,bubbleSort()函数接口详见程序清单 2.6。
程序清单 2.6 bubbleSort()冒泡排序函数接口(bubbleSort.h)
1 #pragma once;
2 void bubbleSort(void *base, size_t nmemb, size_t size, COMPARE compare);
虽然大多数初学者也会选择回调函数,但又经常用全局变量保存中间数据。这里提出的解决方法就是给回调函数传递一个称为“回调函数上下文”的参数,其变量名为base。为了能接受任何数据类型,选择void *表示这个上下文。“上下文”的意思就是说,如果传进来的是int类型值,则回调int型数据比较函数;如果传进来的是字符串,则回调字符串比较函数。
当bubbleSort()将base声明为一个void *类型时,即允许bubbleSort()用相同的代码支持不同类型的数据比较实现排序,其关键之处是type类型域,它允许在运行时根据数据的类型调用不同的函数。这种在运行时根据数据的类型将函数体与函数调用相关联的行为称为动态绑定,因此将一个函数的绑定发生在运行时而非编译期,就称该函数是多态的。显然,多态是一种运行时绑定机制,其目的是将函数名绑定到函数的实现代码。一个函数的名字与其入口地址是紧密相连的,入口地址是该函数在内存中的起始地址,因此多态就是将函数名动态地绑定到函数入口地址的运行时绑定机制,bubbleSort()的接口与实现详见程序清单 2.7和程序清单 2.8。
程序清单 2.7 bubbleSort()接口(bubbleSort.h)
1 #pragma once
2 #include
3
4 typedef int(*COMPARE)(const void * e1, const void *e2);
5 void bubbleSort(void * base, size_t nmemb, size_t size, COMPARE compare);
程序清单 2.8 bubbleSort()接口的实现(bubbleSort.c)
1 #include"bubbleSort.h"
2
3 void byte_swap(void *pData1, void *pData2, size_t stSize)
4 {
5 unsigned char *pcData1 = pData1;
6 unsigned char *pcData2 = pData2;
7 unsigned char ucTemp;
8
9 while (stSize--){
10 ucTemp = *pcData1; *pcData1 = *pcData2; *pcData2 = ucTemp;
11 pcData1++; pcData2++;
12 }
13 }
14
15 void bubbleSort(void * base, size_t nmemb, size_t size, COMPARE compare)
16 {
17 int hasSwap=1;
18
19 for (size_t i = 1; hasSwap&&i < nmemb; i++) {
20 hasSwap = 0;
21 for (size_t j = 0; j < numData - 1; j++) {
22 void *pThis = ((unsigned char *)base) + size*j;
23 void *pNext = ((unsigned char *)base) + size*(j+1);
24 if (compare(pThis, pNext) > 0) {
25 hasSwap = 1;
26 byte_swap(pThis, pNext, size);
27 }
28 }
29 }
30 }
静态类型和动态类型
类型的静态和动态指的是名字与类型绑定的时间,如果所有的变量和表达式的类型在编译时就固定了,则称之为静态绑定;如果所有的变量和表达式的类型直到运行时才知道,则称之为动态绑定。
假设要实现一个用于任意数据类型的冒泡排序函数并简单测试,其要求是同一个函数既可以从大到小排列,也可以从小到大排列,且同时支持多种数据类型。比如:
int array[] = {39, 33, 18, 64, 73, 30, 49, 51, 81};
显然,只要将比较函数的入口地址compare_int传递给compare,即可调用bubbleSort():
int array[] = {39, 33, 18, 64, 73, 30, 49, 51, 81};
bubbleSort(array, numArray , sizeof(array[0]), compare_int);
在数量不大时,所有排序算法性能差别不大,因为高级算法只有在元素个数多于1000时,性能才出现显著提升。其实90%以上的情况下,我们存储的元素个数只有几十到几百个,冒泡排序可能是更好的选择,bubbleSort()的实现与使用范例程序详见程序清单 2.9。
程序清单 2.9 bubbleSort()冒泡排序范例程序
1 #include
2 #include
3 #include"bubbleSort.h"
4
5 int compare_int(const void * e1, const void * e2)
6 {
7 return *(int *)e1 - *(int *)e2;
8 }
9
10 int compare_int_r(const void * e1, const void * e2)
11 {
12 return *(int *)e2 - *(int *)e1 ;
13 }
14
15 int compare_str(const void * e1, const void *e2)
16 {
17 return strcmp(*(char **)e1, *(char **)e2);
18 }
19
20 void main()
21 {
22 int arrayInt[] = { 39, 33, 18, 64, 73, 30, 49, 51, 81 };
23 int numArray = sizeof(arrayInt) / sizeof(arrayInt[0]);
24 bubbleSort(arrayInt, numArray, sizeof(arrayInt[0]), compare_int);
25 for (int i = 0; i
26 printf("%d ", arrayInt[i]);
27 }
28 printf("\n");
29
30 bubbleSort(arrayInt, numArray, sizeof(arrayInt[0]), compare_int_r);
31 for (int i = 0; i
32 printf("%d ", arrayInt[i]);
33 }
34 printf("\n");
35
36 char * arrayStr[] = { "Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday" };
37 numArray = sizeof(arrayStr) / sizeof(arrayStr[0]);
38 bubbleSort(arrayStr, numArray, sizeof(arrayStr[0]), compare_str);
39 for (int i = 0; i < numArray; i++) {
40 printf("%s\n", arrayStr[i]);
41 }
42 }
由此可见,调用者main()与compare_int()回调函数都同属于上层模块,bubbleSort()属于下层模块。当上层模块调用下层模块bubbleSort()时,将回调函数的地址compare_int作为参数传递给bubbleSort(),进而调用compare_int()。显然,使用参数传递回调函数的方式,下层模块不必知道需要调用上层模块的哪个函数,从而减少了上下层之间的联系,这样上下层可以独立修改,而不影响另一层代码的实现。这样一来,在每次调用bubbleSort()时,只要给出不同的函数名作为实参,则bubbleSort()不必做任何修改。
使用回调函数的最大优点就是便于软件模块的分层设计,降低软件模块之间的耦合度。即回调函数可以将调用者与被调用者隔离,调用者无需关心谁是被调用者。当特定的事件或条件发生时,调用者将使用函数指针调用回调函数对事件进行处理。
-
《程序设计与数据结构》周立功数十年心血力作2017-05-26 45
-
周立功“程序设计与数据结构”:深度解剖动态分布内存的free()函数与realloc()函数2017-08-25 15716
-
周立功教你学C语言编程与程序设计:这样写函数指针数组最好用2017-08-31 7582
-
算法的泛化问题,这些坑你可能都经历过!|周立功教你学软件设计2017-09-01 6508
-
μCOS-II程序设计基础 周立功公司编着2012-08-20 29483
-
新书创作谈:周立功教授数十年之心血力作《程序设计与数据结构》2017-05-15 3664
-
【完整资料】《程序设计与数据结构》周立功数十年心血力作2017-05-16 183095
-
回调函数在程序开发中有何作用呢2022-03-01 996
-
μCOS-II程序设计基础_周立功公司编着2015-12-28 811
-
周立功:动态分布内存——malloc()函数与calloc()函数2017-08-22 5273
-
LabWindows/CVI 程序 回调函数设计2018-05-03 12134
-
回调函数的详细资料说明2019-02-28 887
-
C语言函数的回调函数2020-09-11 4731
-
c语言回调函数的使用及实际作用详解2021-11-20 708
-
函数指针和回调函数的使用方法2023-04-10 1779
全部0条评论

快来发表一下你的评论吧 !
