

FP8模型训练中Debug优化思路
描述
目前,市场上许多公司都积极开展基于 FP8 的大模型训练,以提高计算效率和性能。在此,我们整理并总结了客户及 NVIDIA 技术团队在 FP8 模型训练过程中的 debug 思路和方法,供大家参考。
在讨论之前,建议大家使用我们推荐的 FP8 训练的 Recipe,即使用 Delayed scaling,在 History length 为 1024 的窗口中选取最大的 amax 数值作为计算 scaling factor 的方法。当然,我们也在不断优化这个 Recipe,未来随着更多 FP8 的实践案例,将继续为大家总结和分享,期待共同探索和优化 debug 的思路和方案。
在收集和整理了大量 FP8 训练的案例后,我们发现,FP8 训练中遇到的问题一般可以分成以下三类。
第一类问题:Spike Issue
Spike Issue 其实并不是 FP8 训练所特有的,在 BF16 中也可能会遇到此类问题,并且实际上根据 NVIDIA 技术团队内部训练的一些曲线,可以看到 FP8 的 Spike Issue 要比 BF16 还要小一些。所以,如果遇到了 Spike Issue,很多情况下可以暂时不用特别关注 FP8。另外,这里推荐两篇关于 Spike 的研究,供大家参考。
关于 Adam Optimizer 对 Spike 的影响。
关于使用 SWA 增强训练的稳定性,减少 Spike 出现的情况。
整体上,如果我们遇到的 Spike 和曾经在 BF16 上遇到的差不多,这种情况很可能不是 FP8 的问题。当然,也有例外的情况,比如我们遇到的 Spike 需要很多迭代步才能够恢复正常,那这种情况下可以说明这个 loss 和 BF16 有本质上的差异, 可以考虑是第二类问题。
第二类问题:
FP8 loss 和 BF16 不匹配或者发散
在 Validation loss 曲线上,不论是预训练还是 SFT,如果有 BF16 作为 Baseline,并且可以看到 FP8 和 BF16 有差距,这种情况下应该如何处理?
一般这类问题可以分成两种情况,包括:
情况 1:在训练的初始阶段,不论是 Train from scratch 还是 Continue train,如果刚切换到 FP8 进行训练,一开始就出现了 loss 比较大或者直接跑飞,这种情况下大概率是软件问题造成的,因此建议大家使用 NVIDIA 最新的 Transformer Engine 和 Megatron Core 的软件栈,这样很多软件的问题可以及时被修复,从而让大家少跑一些弯路。同时还有另外一种情况,在软件不断的更新过程中,为了性能的优化会增加很多新的特性。如果一些特性是刚刚加入的,可能在 FP8 上暂时还没有遇到特殊情况,因此建议,大家如果使用了一些很新的特性,届时可以先尝试关闭掉这些新特性,检查是否是由于这些新特性的实现不够完善造成 loss 的问题。
情况 2:我们已经训练了一段时间,比如已经训练了几百 Billion 的 Tokens,loss 出现了差距,这种情况一般就不是软件问题了。问题可能是给大家推荐的这个 Recipe 并不适用于某些数据集或某些模型结构。这种情况下,可以通过下面的案例去进行拆解。
第三类问题:FP8 loss 非常吻合,
但是 Downstream tasks 会有一些差异
训练中,我们的 Validation loss 曲线吻合的非常好,比如 loss 差距的量级大概是在十的负三次方,但是在一些下游任务上打分的方面可能会出现问题,那应该如何处理?这样的问题一般分为两种情况,包括:
情况 1:进行下游任务打分的时候,会进行多任务打分。如果所有的任务和 BF16 baseline 对比,或者和当时上一代的模型对比,打分结果差异很大,这种情况大概率是评估过程中出现了问题。比如,Checkpoint 导出来的格式不对,或者 Scale 没有取对等评估流程的问题。因此我们还需要进行排除,确认是否是导出模型和评估流程出现了问题。
情况 2:另一种情况,如前文提到的“在训练了几百 Billion 的 Token 之后,loss 出现了差距”,和这种情况很相似,此时大部分任务都没问题,只有个别的一两个任务发现跟 BF16 的 Baseline 有明显差距,如 3% 或者 5% 的掉点。这种情况下,建议改变 FP8 训练的 Recipe,默认的 Recipe 是 Delayed scaling,即选用先前迭代步存下来的 scale 值,我们可以替换成 Current scaling,即选用当前迭代步的 scale 值,或者把部分的矩阵做一些回退到 BF16 的操作,具体方法下文会进行介绍。
以下是一个案例,通过这个案例,可以初步了解哪些方法在现阶段可以进行尝试。
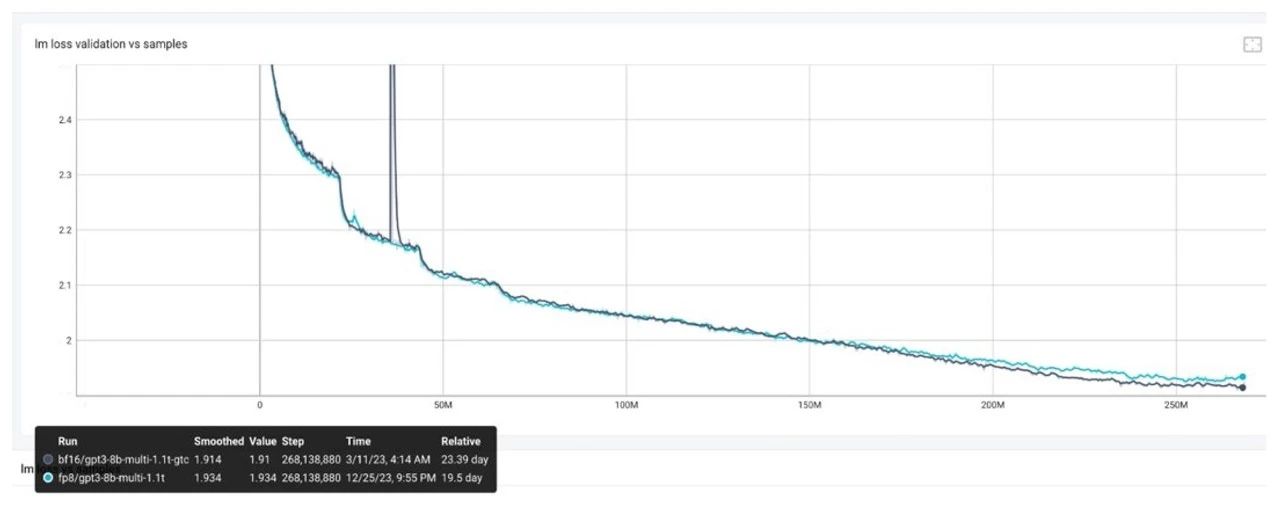
这是一个类似于 Llama 2 的模型,虽然模型规模较小,但已经训练了 1.1T 个 Tokens,使用了如下推荐的配置,包括:
Pytorch 23.10 版本
TE Commit 为 d76118d
FP8 format:hybird
History Length:1024
Algo:Max
FP8 Wgrad Override:True
我们发现,比较接近 loss 末尾的时候,差异就会随之出现,并且显然已经不是十的负三次方的量级,这种情况下,可以考虑以下的步骤进行问题的排查。

第一步:Sequence Parallel off
在软件前期的时候,首先尽可能尝试关闭一些根据经验判断可能有问题的特性。比如在引入 FP8 初期,软件上的 Sequence Paralleism(SP)经常会引起一些问题,因此可以先尝试进行关闭,如果发现关闭后并没有问题,可以初步判断 loss 不是由软件引起的,从而大概率可以推断是 Recipe 不够完善造成的。
第二步:我们可以做一个恢复性实验
尝试看一下当前训练出现问题的 FP8 的 Checkpoint,比如最后一个点,把这个 Checkpoint 切换到 BF16 训练,查看是否可以恢复到 BF16 的 Baseline。我们目前遇到的大多数情况都是可以恢复的。因此在这个基础的情况下,可以继续尝试下一步 debug 的方法。
第三步:三类矩阵的问题排查
大多数情况下,整个模型跑在 FP8 上并不多见。对于 Transformer layer 的每个 Gemm 来说,整个训练过程中,有三类矩阵跑在 FP8 上,包括它的前向 Fprop,以及反向 Wgrad 和 Dgrad,因此现在需要判断三类矩阵的哪个矩阵出了问题,当然,更细致一些应该判断具体是哪一个 Transformer layer 的矩阵出了问题。不过,这个特性还在开发过程中,目前还是一个比较初步的判断,需要检查是前向的矩阵还是反向的两个矩阵其中之一出现了差错。因此这一步中,可以首先把这三类矩阵全部转成 BF16 训练。不过,我们做的是一个 Fake quantization,通俗的解释就是使用 BF16 进行训练,但是在做 BF16 计算之前,会先把它的输入 Cast 成 FP8,然后再 Cast back 回到 BF16。这个时候,其实数据表示它已经是 FP8 表示范围内的值了, 自然这个 scaling 使用的就是 Current scaling,或者说没有 Scaling。这种情况下,会发现把三类矩阵全部都切回 Fake quantization 进行训练的时候,此时的 loss 曲线是可以贴近 BF16 Baseline 的。因此,下面需要一个矩阵一个矩阵的进行排除。

三类矩阵包括前向的 Fprop,以及反向的 Wgrad 和 Dgrad。因此我们可以遵循一个相对简单的思路——逐一尝试,就是每次训练把其中一个矩阵设置为 BF16 计算, 经我们尝试后,可以看到:
在 Fprop 矩阵上面做 BF16 计算,会发现对 loss 的影响并不是很大。
在 Wgrad 矩阵上面做 BF16 计算,影响也非常小。
在 Dgrad 矩阵上面做 BF16 计算,即只有 Dgrad 计算执行在 BF16,而 Fprop 和 Wgrad 全部执行在 FP8,此时会发现 loss 会回到 BF16 的 Baseline。
现在我们已经定位到了有问题的矩阵是 Dgrad,是否还有方法再做进一步的挽救从而避免性能损失太多?这种情况下,可以去进行以下尝试。

在 Transformer Engine (TE) 的后续版本中,计划支持用户使用 Current scaling,即还是使用 FP8 去做 Gemm 的运算。但是我们不用前面给大家推荐的这个 Delayed scaling recipe,而是使用当前输入的 scale 值,虽然会损失一点性能,但是相比于把整个 Gemm 回退到 BF16 做计算,它的性能损失会小很多。
当对 Dgrad 使用了 Current scaling 之后,会发现 loss 曲线已经和 BF16 的 Baseline 吻合了。
以上就是一个相对完整的 debug 的思路,供大家参考和讨论。
关于作者
高慧怡
NVIDIA 深度学习解决方案架构师,2020 年加入 NVIDIA 解决方案架构团队,从事深度学习应用在异构系统的加速工作,目前主要支持国内 CSP 客户在大语言模型的训练加速工作。
-
燧原科技L600 FP8原生适配DeepSeek-V4-Pro/Flash模型2026-04-28 750
-
低精度浮点数定义——什么是 FP8、FP6、FP4?2026-04-23 326
-
在Ubuntu20.04系统中训练神经网络模型的一些经验2025-10-22 317
-
摩尔线程发布Torch-MUSA v2.0.0版本 支持原生FP8和PyTorch 2.5.02025-05-11 2014
-
摩尔线程GPU原生FP8计算助力AI训练2025-03-17 1751
-
FP8在大模型训练中的应用2025-01-23 2573
-
如何使用FP8新技术加速大模型训练2024-12-09 2801
-
TensorRT-LLM低精度推理优化2024-11-19 3006
-
NVIDIA GPU架构下的FP8训练与推理2024-04-25 4801
-
【AI简报20231103期】ChatGPT参数揭秘,中文最强开源大模型来了!2023-11-03 3114
-
介绍几篇EMNLP'22的语言模型训练方法优化工作2022-12-22 1842
-
小米在预训练模型的探索与优化2020-12-31 4047
-
Pytorch模型训练实用PDF教程【中文】2018-12-21 5202
全部0条评论

快来发表一下你的评论吧 !
