

算法与数据结构——接口
电子说
描述
周立功教授数年之心血之作《程序设计与数据结构》以及《面向AMetal框架与接口的编程(上)》,书本内容公开后,在电子行业掀起一片学习热潮。经周立功教授授权,本公众号特对《程序设计与数据结构》一书内容进行连载,愿共勉之。
第三章为算法与数据结构,本文为3.2.3 接口。
>>> 3.2.3 接口
在实际使用中,仅有添加到链表尾部、遍历链表这些接口函数是不够的。如在结点添加函数中,当前只是按照人们的习惯,将结点添加到链表尾部,使后添加的结点处在先添加的结点后面。而在编写函数时知道,将一个结点添加至尾部的实现过程,需要修改原链表尾结点中p_next值,将其从NULL修改为指向新结点的指针。
虽然操作简单,但执行该操作的前提是要找到添加结点前链表的尾结点,则需要从指向头结点的p_head指针开始,依次遍历每个结点,直到找到结点中p_next值为NULL(尾结点)时为止。可想而知,添加一个结点的效率将随着链表长度的增加逐渐降低,如果链表很长,则效率将变得十分低下,因为每次添加结点前都要遍历一次链表。
既然将结点添加到链表尾部会由于需要寻找尾结点而导致效率低下,何不换个思路,将结点添加到链表头部。由于链表存在一个p_head指针指向头结点,头结点可以拿来就用,根本不要寻找,则效率将大大提高。将一个结点添加至链表头部时,链表的变化详见图 3.11。
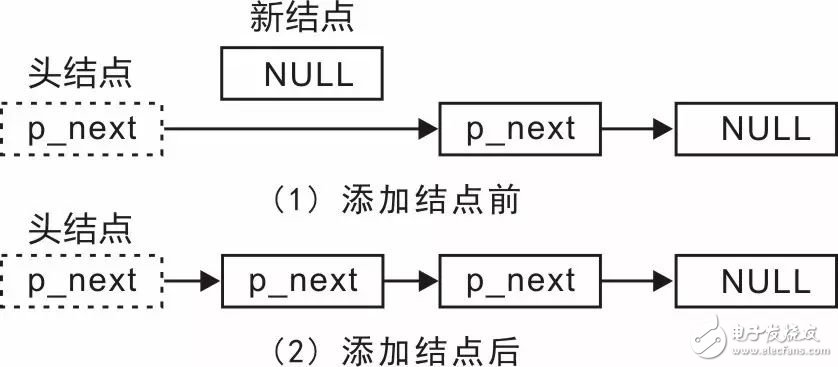
图 3.11添加一个结点至链表头部
在其实现过程中,需要完成两个指针的修改:(1)修改新结点中的p_next,使其指向头结点中p_next指向的结点;(2)修改头结点的p_next,使其指向新的结点。
与添加结点至链表尾部的过程进行对比发现,其不再需要寻找尾结点的过程,无论链表多长,都可以通过这两步完成结点的添加。加结点到链表头部的函数原型(slist.h)为:

其中,p_head指向链表头结点,p_node为待添加的结点,其实现详见程序清单3.21。
程序清单3.21 新增结点至链表头部的范例程序

由此可见,插入结点至链表头部的程序非常简单,无需查找且效率高,因此在实际使用时,若对位置没有要求,则优先选择将结点添加至链表头部。
修改程序清单3.20中的一行代码作为测试,比如,将第26行改为:

将node3添加到链表头部,查看修改后的最终输出结果发生了什么变化?
既然可以将结点添加至头部和尾部,何不更加灵活一点,提供一个将结点至任意位置的接口函数呢?当结点添加至p_pos指向的结点之后,则链表的变化详见图 3.12。
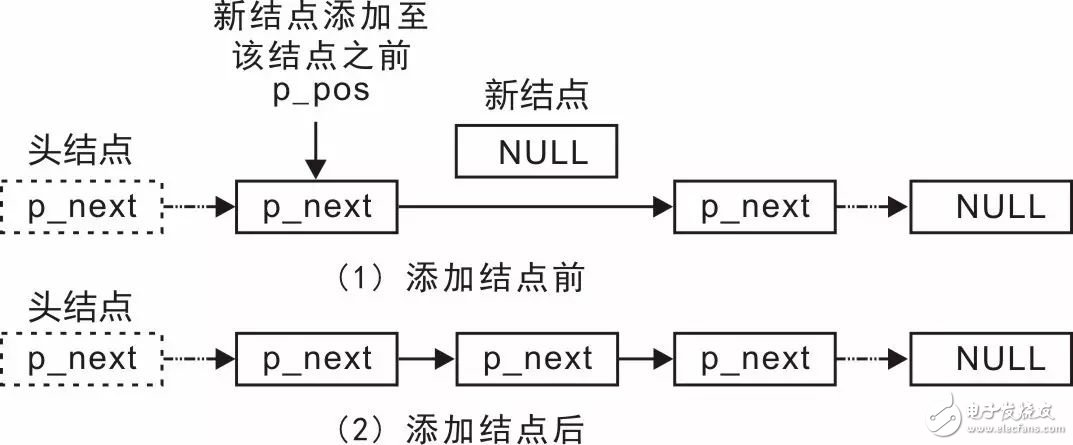
图 3.12 添加结点至任意位置示意图
在其实现过程中,需要修改两个指针:(1)修改新结点中的p_next,使其指向p_pos指向结点的下一个结点;(2)修改p_pos指向结点的p_next,使其指向新结点。通过这两步即可添加结点,添加结点至链表任意位置的函数原型(slist.h)为:

其中,p_head指向链表头结点,p_node指向待添加的结点,p_pos指向的结点表明新结点添加的位置,新结点即添加在p_pos指向的结点后面,其实现详见程序清单3.22。
程序清单3.22 新增结点至链表任意位置的范例程序

尽管此函数在实现时没有用到参数p_head,但还是将p_head参数传进来了,因为实现其它功能时将会用到p_head参数,比如,判断p_pos是否在链表中。
通过前面的介绍已经知道,直接将结点添加至链表尾部的效率很低,有了该新增结点至任意位置的函数后,如果每次都将结点添加到上一次添加的结点后面,同样可以实现将结点添加至链表尾部。详见程序清单3.23。
程序清单3.23 管理int型数据的范例程序

显然,添加结点至链表头部和尾部,仅仅是添加结点至任意位置的特殊情况:
-
添加结点至链表头部,即添加结点至头结点之后;
-
添加结点至链表尾部,即添加结点至链表尾结点之后。
slist_add_head()函数和slist_add_tail()函数的实现详见程序清单3.24。
程序清单3.24 基于slist_add()实现添加结点至头部和尾部

如果要将一个结点添加至某一结点之前呢?实际上,添加结点至某一结点之前同样也只是添加结点至某一结点之后的一种变形,即添加至该结点前一个结点的后面,详见图3.13。
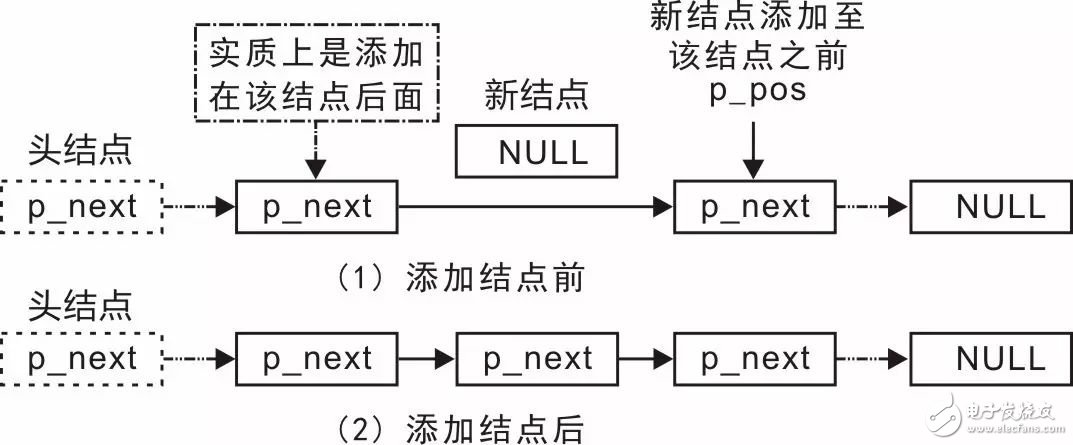
图3.13 添加结点至任意位置前示意图
显然,只要获得某一结点的前驱,即可使用slist_add()函数添加结点至某一结点前面。为此,需要提供一个获得某一结点前驱的函数,其函数原型(slist.h)为:

其中,p_head指向链表头结点,p_pos指向的结点表明查找结点的位置,返回值即为p_pos指向结点的前一个结点。由于在单向链表的结点中没有指向其上一个结点的指针,因此,只有从头结点开始遍历链表,当某一结点的p_next指向当前结点时,表明其为当前结点的上一个结点,函数实现详见程序清单3.25。
程序清单3.25 获取某一结点前驱的范例程序

由此可见,若p_pos的值为NULL,则当某一结点的p_next为NULL时就会返回,此时返回的结点实际上就是尾结点。为了便于用户理解,可以简单封装一个查找尾结点的函数,其函数原型为:

其函数实现详见程序清单3.26。
程序清单3.26 查找尾结点

由于可以直接通过该函数得到尾结点,因此当需要将结添加点至链表尾部时,也就无需再自行查找尾结点了,修改slist_add_tail()函数的实现详见程序清单3.27。
程序清单3.27 查找尾结点

与添加一个结点对应,也可以从链表中删除某一结点。假定链表中已经存在3个结点,现在要删除中间的结点,则删除前后的链表变化详见图3.14。
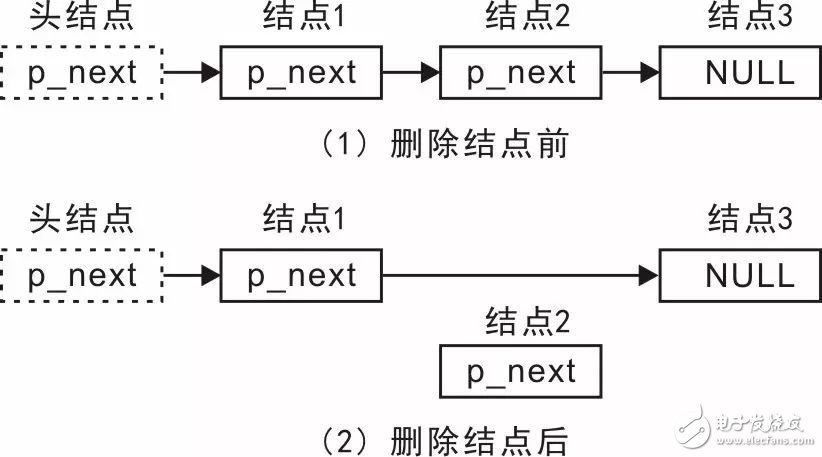
图3.14 删除结点示意图
显然,删除一个结点也需要修改两个指针的值:既要修改其上一个结点的p_next,使其指向待删除结点的下一个结点,还要将删除结点的p_next设置为NULL。
删除结点的函数原型(slist.h)为:

其中,p_head指向链表头结点,p_node为待删除的结点,slist_del()函数的实现详见程序清单3.28。
程序清单3.28 删除结点范例程序

为便于查阅,如程序清单3.29所示展示了slist.h文件的内容。
程序清单3.29 slist.h文件内容

综合范例程序详见程序清单3.30。
程序清单3.30 综合范例程序

程序中所有的结点都是按照静态内存分配的方式定义的,即程序在运行前,各个结点占用的内存就已经被分配好了,而不同的是动态内存分配需要在运行时使用malloc()等函数完成内存的分配。
由于静态内存不会出现内存泄漏,且在编译完成后,各个结点的内存就已经分配好了,不需要再花时间去分配内存,也不需要添加额外的对内存分配失败的处理代码。因此,在嵌入式系统中,往往多使用静态内存分配的方式。但其致命的缺点是不能释放内存,有时候用户希望在删除链表的结点时,释放掉其占用内存,这就需要使用动态内存分配。
实际上,链表的核心代码只是负责完成链表的操作,仅需传递结点的地址(p_node)即可,链表程序并不关心结点的内存从何而来。基于此,若要实现动态内存分配,只要在应用中使用malloc()等动态内存分配函数即可,详见程序清单3.31。
程序清单3.31 综合范例程序(使用动态内存)

如果按照int型数据的示例,使用链表管理学生记录,则需要在学生记录中添加一个链表结点数据。比如:

虽然这样定义使得学生信息可以使用链表来管理,但却存在一个很严重的问题,因为修改了学生记录类型的定义,就会影响所有使用该记录结构体类型的程序模块。在实际的应用上,学生记录可以用链表管理,也可以用数组管理,当使用数组管理时,则又要重新修改学生记录的类型。而node仅仅是链表的结点,与学生记录没有任何关系。不能将node直接放在学生记录结构体中,应该使它们分离。基于此,需要定义一个新的结构体类型,将学生记录和node关联起来,使得可以用链表来管理学生记录。比如:

使用范例详见程序清单3.32。
程序清单3.32 综合程序范例

综上所述,虽然链表比数组更灵活,很容易在链表中插入和删除结点,但也失去了数组的“随机访问”能力。如果结点距离链表的开始处很近,那么访问它就会很快;如果结点靠近链表的结尾处,则访问它就会很慢。但单向链表也存在不能“回溯”的缺点,即在向链表中插入结点时,必须知道插入结点前面的结点;从链表中删除结点时,必须知道被删除结点前面的结点;很难逆向遍历链表。如果是双向链表,就可以解决这些问题。
-
算法和数据结构基础知识分享(上)2023-04-06 1609
-
JavaScrit数据结构与算法(第2版)2021-06-01 864
-
大牛分享平时如何学习数据结构与算法2018-11-02 3741
-
算法与数据结构——哈希表2017-09-25 6313
-
算法与数据结构——迭代器模式2017-09-20 5616
-
算法与数据结构——双向链表2017-09-19 8028
-
数据结构与算法2016-03-30 675
-
数据结构与算法习题2016-03-03 785
-
数据结构与算法分析2012-06-05 3419
-
C#数据结构和算法分析_ 魏宝刚2011-12-15 1736
-
数据结构教程,下载2009-05-14 892
-
数据结构与算法分析(Java版)(pdf)2008-12-20 4730
全部0条评论

快来发表一下你的评论吧 !
