

算法与数据结构——双向链表
电子说
描述
周立功教授数年之心血之作《程序设计与数据结构》以及《面向AMetal框架与接口的编程(上)》,书本内容公开后,在电子行业掀起一片学习热潮。经周立功教授授权,本公众号特对《程序设计与数据结构》一书内容进行连载,愿共勉之。
第三章为算法与数据结构,本文为3.3 双向链表。
>>> 3.3 双向链表
单向链表的添加、删除操作,都必须找到当前结点的上一个结点,以便修改上一个结点的p_next指针完成相应的操作。由于单向链表的结点没有指向其上一个结点的指针,因此只有从头结点开始遍历链表。当某一结点的p_next指向当前结点时,表明它为当前结点的上一个结点。显然每次都要从头开始遍历,其效率极为低下。在单向链表中,之所以可以直接获取单向链表中当前结点的下一个结点,是因为结点中包含了指向下一个结点的指针p_next。如果在双向链表的结点中再增加一个指向它的前一个结点的前向指针p_prev,则一切问题将迎刃而解。那么,既有指向下一个结点的指针,又有指向前一个结点的指针的链表称之为双向链表,示意图详见图3.15。

图3.15 双向链表示意图
与单向链表一样,双向链表也定义了一个头结点,基于单向链表将应用数据与链表结构相关数据完全分离的设计思想,则双向链表结点仅保留p_next和p_prev指针。其数据结构定义如下:

其中,dlist是double list 的缩写,表明该结点是双向链表结点。由此可见,虽然前向指针使得寻找链表的上一个结点变得非常容易,但由于结点中新增了一个指针,因此其内存开销将会是单向链表的两倍。在实际应用中,应该权衡效率与内存空间,在内存资源非常紧缺的场合,如果结点的添加、删除操作很少,一点效率的影响可以接受,则选择使用单向链表。而不是一味地追求效率,认为双向链表比单向链表好,始终选择使用双向链表。
在图3.15中,头结点的p_prev和尾结点的p_next直接被设置为了NULL,此时,如果要直接由头结点找到尾结点,或者由尾结点找到头结点,都必须遍历整个链表。可以对这两个指针稍加利用,使头结点的p_prev指向尾结点,尾结点的p_next指向头结点,此时,该双向链表就成了一个循环双向链表,示意图详见图3.16。
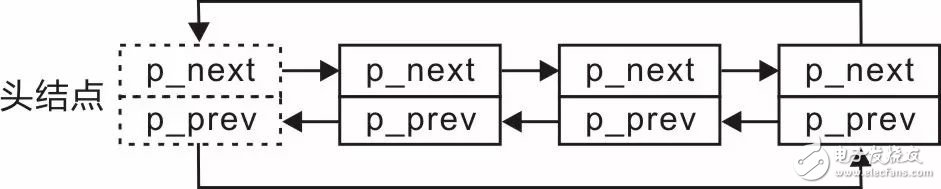
图3.16 循环双向链表示意图
由于循环双向链表的效率更高,可以直接从头结点找到尾结点,或者从尾结点找到头结点,且没有额外的内存空间消耗,仅仅是使用了两个不打算使用的指针,算是废物利用,因此下面介绍的双向链表均视为循环双向链表。
类似于单向链表,虽然头结点与普通结点的内容完全相同,但它们的含义却有所区别,头结点是链表的头,代表了整个链表,拥有此头结点,就表示其拥有了整个链表。为了便于区分头结点与普通结点,可以单独定义一个头结点类型。比如:
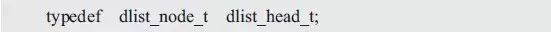
当需要使用双向链表时,首先需要使用该类型定义一个头结点。比如:

由于此时还没有添加其它任何结点,仅存在一个头结点,因此该头结点既是第一个结点(头结点),又是最后一个结点(尾结点)。按照循环链表的定义,尾结点的p_next指向头结点,头结点的p_prev指向尾结点,仅有一个结点的示意图详见图3.17。
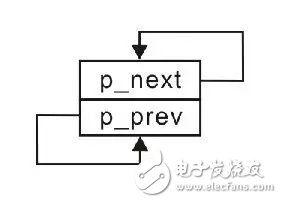
图3.17 空链表
显然,仅有头结点时,其p_next和p_prev都指向本身。即:

为了避免用户直接操作成员,需要定义一个初始化函数,专门用于初始化链表头结点中各个成员的值,其函数原型(dlist.h)为:

其中,p_head指向待初始化的链表头结点。其调用形式如下:

dlist_init()函数的实现详见程序清单3.33。
程序清单3.33 双向链表初始化函数

与单向链表类似,将提供一些基础的操作接口,它们的函数原型如下:

对于dlist_prev_get()和dlist_next_get(),在链表结点中已经存在指向前驱后后继的指针,详见程序清单3.34。
程序清单3.34 得到结点前驱和后继的函数实现

dlist_tail_get()函数用于得到链表的尾结点,在循环双向链表中,头结点的p_reev即指向了尾结点,详见程序清单3.35。
程序清单3.35 dlist_tail_get()函数实现

dlist_begin_get()函数用于得到第一个用户结点,详见程序清单3.36。
程序清单3.36 dlist_begin_get()函数实现

dlist_end_get()用于得到链表的结束位置,当双向链表设计为循环双向链表时,则头结点的p_prev和尾结点的p_next都被有效地利用了,任何有效结点的p_next和p_prev都不再为NULL。显然,不能再以NULL作为结束位置了,当从第一个结点开始顺序访问链表的各个结点时,尾结点的下一个结点就是链表头结点(head),因此结束位置就是头结点本身。dlist_end_get()的实现详见程序清单3.37。
程序清单3.37 dlist_end_get()函数实现

3.3.1 添加结点
假定还是将结点添加到链表尾部,其函数原型为:

其中,p_head为指向链表头结点的指针,p_node为指向待添加结点的指针,其使用范例详见程序清单3.38。
程序清单3.38 dlist_add_tail()函数使用范例

为了实现该函数,可以先查看添加结点前后链表的变化,详见图3.18。
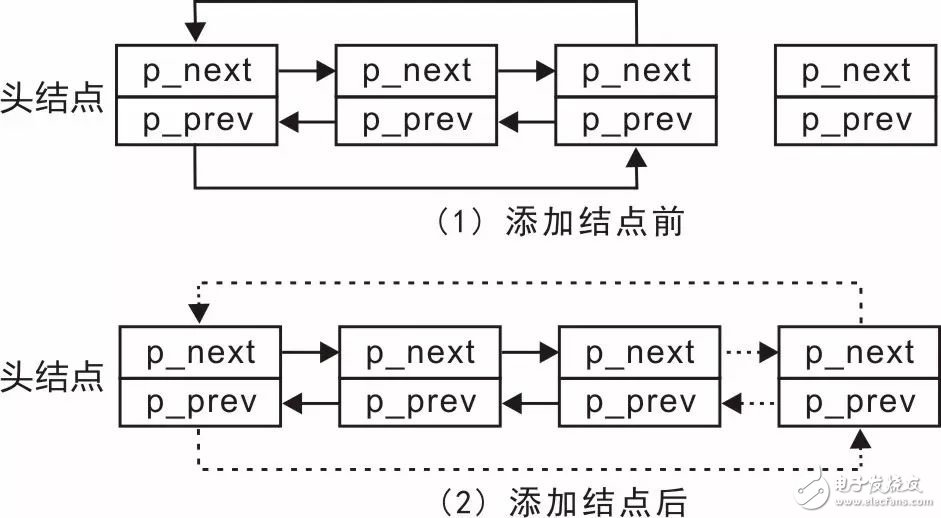
图3.18 添加结点示意图
由此可见,添加一个结点至链表尾部,需要4个指针(图中虚线箭头):
-
新结点的p_prev指向尾结点;
-
新结点的p_next指向头结点;
-
尾结点的p_next由指向头结点变为指向新结点;
-
头结点的p_prev由指向尾结点修改为指向新结点。
通过这些操作后,当结点添加到链表尾部后,就成为了新的尾结点,详见程序清单3.39。
程序清单3.39 dlist_add_tail()函数实现

实际上循环链表,无论是头结点、尾结点还是普通结点,其本质上都是一样的,均为p_next成员指向下一个结点,p_prev成员指向其上一个结点。因此,对于添加结点而言,无论将结点添加到链表头、链表尾还是其它任意位置,其操作方法完全相同。为此,需要提供一个更加通用的函数,可以将结点添加到任意结点之后,其函数原型为:
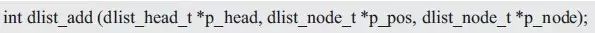
其中,p_head为指向链表头结点的指针,p_pos指定了添加的位置,新结点即添加在该指针指向的结点之后;p_node为指向待添加结点的指针。比如,同样将结点添加到链表尾部,其使用范例详见程序清单3.40。
程序清单3.40 dlist_add()函数使用范例

由此可见,将尾结点作为结点添加的位置,同样可以将结点添加至尾结点之后,即添加到链表尾部。显然,也就没有必要再编写dlist_add_tail()实现代码了,使用dlisd_add()即可,修改dlist_add_tail()函数的实现,详见程序清单3.41。
程序清单3.41 dlist_add_tail()函数实现

为了实现dlist_add()函数,可以先查看添加一个结点到任意结点之后的情况,详见图3.19。图中展示的是一种通用的情况,由于结点的添加位置(头、尾或其它任意位置)与添加结点的方法没有关系,因此没有特别标明头结点和尾结点。
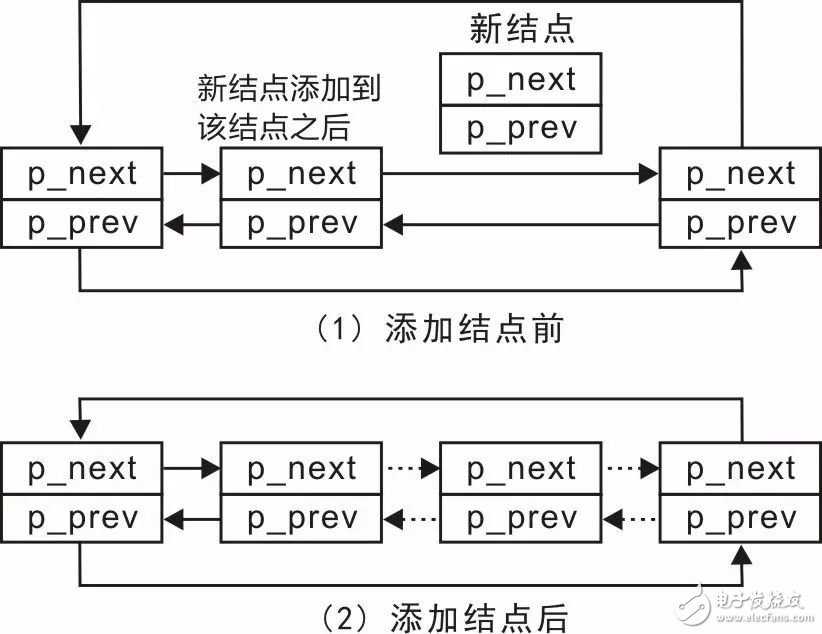
图3.19 添加结点示意图
其实,对比图3.18和图3.19可以发现,图3.18展示的只是图3.19的一个特例,即恰好图3.19中的新结点之前的结点就是尾结点,添加结点的过程同样需要修改4个指针的值。为便于描述,将新结点前的结点称之为前结点,新结点之后的结点称之为后结点。显然,在添加新结点之前,前结点的下一个结点即为后结点。对设置4个指针值的描述如下:
-
新结点的p_prev指向前结点;
-
新结点的p_next指向后结点;
-
前结点的p_next由指向后结点变为指向新结点;
-
后结点的p_prev由指向前结点修改为指向新结点。
对比将结点添加到链表尾部的描述,只要将描述中的“前结点”换为“尾结点”,“后结点”换为“头结点”,它们的含义则完全一样,显然将结点添加到链表尾部只是这里的一个特例,添加结点的函数实现详见程序清单3.42。
程序清单3.42 dlist_add()函数实现

尽管上面的函数在实现时并没有用到参数p_head,但还是将p_head参数传进来了,因为实现其它的功能时将会用到p_head参数,比如,判断p_pos是否在链表中。
有了该函数,添加结点到任意位置就非常灵活了,比如,提供一个添加结点到链表的头部,使其作为链表的第一个结点的函数,其函数原型为:
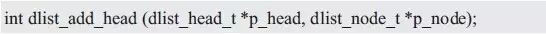
此时,头结点即为新添加结点的前结点,直接调用dlist_add()即可实现,其实现范例详见程序清单3.43。
程序清单3.43 dlist_add_head()函数实现

3.3.2 删除结点
基于添加结点到任意位置的思想,需要实现一个删除任意结点的函数。其函数原型为:

其中,p_head为指向链表头结点的指针, p_node为指向待删除结点的指针,使用范例详见程序清单3.44。
程序清单3.44 dlist_del()使用范例程序

为了实现dlisd_del()函数,可以先查看删除任意结点的示意图,图 3.20(1)为删除节点前的示意图,图 3.20(2)为删除节点后的示意图。
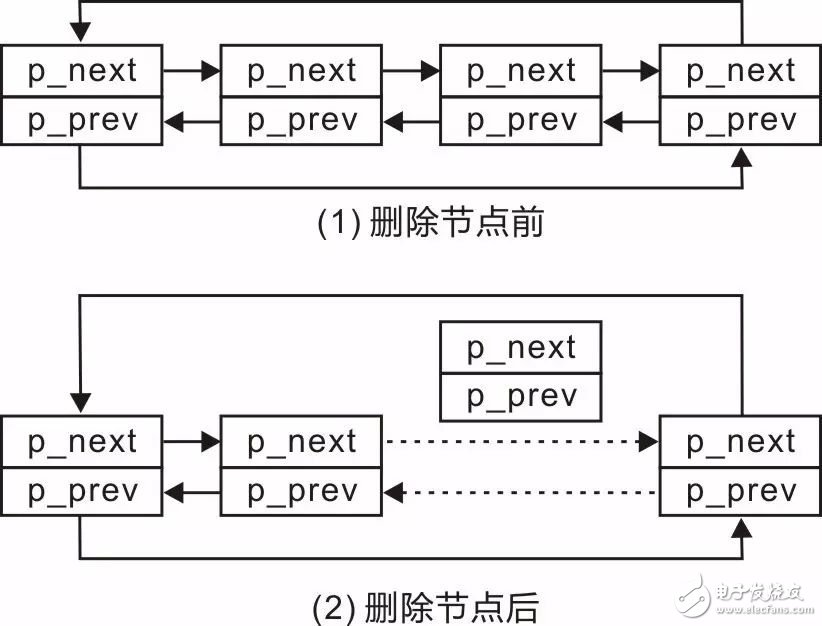
图 3.20添加结点示意图
由此可见,仅需要修改两个指针的值:
-
将“删除结点”的前结点的p_next修改为指向“删除结点”的后结点;
-
将“删除结点”的后结点的p_prev修改为指向“删除结点”的前结点。
删除结点函数的实现详见程序清单3.45。
程序清单3.45 dlist_del()函数实现

为了防止删除头结点,程序中对p_head与p_node进行了比较,当p_node为头结点时,则直接返回错误。
3.3.3 遍历链表
与单向链表类似,需要一个遍历链表各个结点的函数,其函数原型(dlist.h)为:

其中,p_head指向链表头结点,pfn_node_process为结点处理回调函数,每遍历到一个结点时,均会调用该函数,便于用户处理结点。dlist_node_process_t类型定义如下:

dlist_node_process_t类型参数为一个p_arg指针和一个结点指针,返回值为int类型的函数指针。每遍历到一个结点均会调用pfn_node_process指向的函数,便于用户根据需要自行处理结点数据。当调用该回调函数时,传递给p_arg的值即为用户参数,其值与dlist_traverse()函数的第3个参数一样,即该参数的值完全是由用户决定的;传递给p_node 的值即为指向当前遍历到的结点的指针。当遍历到某个结点时,如果用户希望终止遍历,此时,只要在回调函数中返回负值即可终止继续遍历。一般地,若要继续遍历,则函数执行结束后返回0即可。dlist_foreach()函数的实现详见程序清单3.46。
程序清单3.46 链表遍历函数的实现

为了便于查阅,如程序清单3.47所示展示了dlist.h文件的内容。
程序清单3.47 dlist.h文件内容

同样以int类型数据为例,来展示这些接口的使用方法。为了使用链表,首先应该定义一个结构体,将链表结点作为其一个成员,此外,再添加一些应用相关的数据,如定义如下包含链表结点和int型数据的结构体:

综合范例程序详见程序清单3.48。
程序清单3.48 综合范例程序

与单向链表的综合范例程序比较可以发现,程序主体是完全一样的,仅仅是各个结点的类型发生了改变。对于实际的应用,如果由使用单向链表升级为双向链表,虽然程序主体没有发生改变,但由于类型的变化,则不得不修改所有程序代码。这是由于应用与具体数据结构没有分离造成的,因此可以进一步将实际应用与具体的数据结构分离,将链表等数据结构抽象为“容器”的概念。
-
数据结构中最简单的链表2023-06-13 768
-
数据结构与算法分析(Java版)(pdf)2008-12-20 4730
-
数据结构与算法分析2012-06-05 3418
-
Linux Kernel数据结构:链表2018-09-25 2075
-
常见的数据结构2020-05-10 2750
-
数据结构链表的基本操作2021-12-22 1592
-
Linux内核中的数据结构的一点认识2022-04-20 4089
-
数据结构与算法习题2016-03-03 785
-
数据结构与算法2016-03-30 675
-
java数据结构学习2017-11-29 1149
-
大牛分享平时如何学习数据结构与算法2018-11-02 3741
-
区块链的基本数据结构解析2019-01-03 8180
-
你知道Linux内核数据结构中双向链表的作用?2019-05-14 2235
-
Linux内核的链表数据结构2023-03-24 1641
-
Linux内核中使用的数据结构2023-11-09 1397
全部0条评论

快来发表一下你的评论吧 !
