

算法与数据结构——迭代器模式
电子说
描述
周立功教授数年之心血之作《程序设计与数据结构》以及《面向AMetal框架与接口的编程(上)》,书本内容公开后,在电子行业掀起一片学习热潮。经周立功教授授权,本公众号特对《程序设计与数据结构》一书内容进行连载,愿共勉之。
第三章为算法与数据结构,本文为3.4 迭代器模式。
>>> 3.4.1 迭代器与容器
在初始化数组中的元素时,通常使用下面这样的for循环语句遍历数组:

这段代码中的循环变量i,该变量的初始值为0,然后递增为1、2、3、...,程序在每次i递增后都将值赋给a[i]。数组中保存了许多元素,通过指定数组下标,即可从中选择任意一个元素。for语句中的i++的作用是让i的值在每次循环后自增1,这样就可以访问数组中的下一个元素,从而实现了从头到尾逐一遍历数组元素的功能。
由此可见,常用的循环结构就是一种迭代操作,在每一次迭代操作中,对迭代器的修改即等价于修改循环控制的标志或计数器。而容器是一种保存值的集合的数据结构,C有两种内建的容器:数组和结构体。虽然C没有提供更多的容器,但用户可以按需编写自己的容器,比如,链表、哈希表等。
将i的作用抽象化、通用化后形成的模式,在设计模式中i称为迭代器(Iterator)模式,Iterate的字面意思是重复、反复声明,其实就是重复做某件事,Iterator模式用于遍历数组中的元素。迭代器的基本思想是迭代器变量存储了容器的某个元素的位置,因此能够遍历该位置的元素。通过迭代器提供的方法,可以继续遍历容器的下一个元素。
显而易见,迭代器是一种抽象的设计概念,因为在程序设计语言中并没有直接对应于这个概念的实物。《设计模式》一书提供了23种设计模式的完整描述,其中iterator模式的定义为:在遍历一个容器对象时,提供一种方法顺序访问一个容器对象中的各个元素,而又不暴露该对象的内部表示方式。其中心思想是将数据容器和算法分开且彼此独立,最后再用黏合剂将它们撮合在一起。
>>> 3.4.2 迭代器接口
为什么一定要考虑引入Iterator这种复杂的设计模式呢?如果是数组,直接使用for循环语句进行遍历处理不就可以了吗?为什么要在集合之外引入Iterator这个角色呢?一个重要的理由是,引入Iterator后可以将遍历与实现分离。
实际上无论是单向链表还是双向链表,其查找算法与遍历算法的实现没有多少差别,基本上都是重复劳动。如果代码中有bug,则需要修改所有相关的代码。为什么会出现这样的情况呢?主要是接口设计不合理所造成的,其最大的问题就是将容器和算法放在了一起,且算法的实现又依赖于容器的实现,因而必须为每一个容器开发一套与之匹配的算法。
假设要在2种容器(双向链表、动态数组)中分别实现6种算法(交换、排序、求最大值、求最小值、遍历、查找),显然需要2×6=12个接口函数才能实现目标。随着算法数量的不断增多,势必导致函数的数量成倍增加,重复劳动的工作量也越大。如果将容器和算法单独设计,则只需要实现6个算法函数就行了。即算法不依赖容器的特定实现,算法不会直接在容器中进行操作。比如,排序算法无需关心元素是存放在数组或线性表中。
在正式引入迭代器之前,不妨分析一下如程序清单 3.49所示的冒泡排序算法。
程序清单 3.49 冒泡排序算法

如果任何一次遍历没有执行任何交换,则说明记录是有序的且终止排序。其中,p1指向数组的首元素,pNext指向p1所指向的元素的下一个元素,p2指向数组的尾元素(图 3.21(a))。

图 3.21 内部循环执行过程示意图
如果*p1>*pNext,则交换指针所指向的内容,p1与pNext后移(图 3.21(b)),反之指针所指向的内容不变,p1与pNext后移,经过一轮排序之后,直到p1 = p2为止,最大元素移到数组尾部。
当最大元素移到数组的尾部时,则退出内部循环。p2前移后程序跳转到程序清单 3.49(15),p1再次指向数组的首元素,pNext指向p1所指向的元素的下一个元素(图 3.22(a))。此时,图 3.22(a)与图 3.21(a)的差别在于p2指向a[3]。经过一轮循环之后,直到p1 = p2,此时整数4移到a[3]所在的位置,剩余的排序详见图 3.22。当p1与p2重合在数组首元素所在的位置时,表示排序结束(图 3.22(d))。

图 3.22 外部循环执行过程示意图
由此可见,冒泡排序算法的核心是指针的操作,其主要行为如下:
-
比较指针所指向的值的大小;
-
交换指针所指向的内容;
-
指针后移,即指针指向下一个元素;
-
指针前移,即指针指向前面一个元素。
由于这里是以int类型数据为例实现冒泡排序的,因此用户知道如何比较数据和如何交换指针所指向的内容,以及指针的前后移动。当使用支持任意类型数据的void *时,虽然算法程序不知道传入什么类型的数据,但调用者知道,因此在调用排序算法函数时,可以由用户传递参数通过回调函数实现。修改后的冒泡排序函数原型如下:

其中,compare用于比较两个指针所指向的值的大小,compare_t类型定义如下:

swap函数用于交换两个指针指向的内容,swap_t类型定义如下:

显然无法通过++或--移动指针,因为不知道传入的是什么类型的数据。如果知道数据占用4个字节,则可以通过指针的值加4或减4实现指针的移动。虽然使用这种方式可以实现指针的移动,但始终要求数据必须以数组的形式存储,一旦离开了这个特定的容器,则无法确定指针的行为。如果将算法与链表结合起来使用,显然代码中的p1++和p2--不适合链表。
基于此,“不妨对指针进行抽象,让它针对不同的容器有不同的实现,而算法只关心它的指针接口”。显然,需要容器提供相应的接口函数,才能实现指针前移和后移,通常将这样的指针称为“迭代器”。从某种意义上来说,迭代器作为算法的接口是广义指针,而指针满足所有迭代器的要求。其优势在于对任何种类的容器都可以用同样的方法顺序遍历容器中的元素,而又不暴露容器的内部细节,迭代器接口的声明详见程序清单3.50。
程序清单3.50 迭代器接口的声明

其中,p_iter指向的内容是由容器决定的,它既可以指向结点,也可以指向数据。无论是链表还是其它容器实现的pfn_next函数,其意义是一样的,其它函数同理。如果将迭代器理解为指向数据的指针变量,则pfn_next函数让迭代器指向容器的下一个数据,pfn_prev函数让迭代器指向容器的上一个数据。
此时,应该针对接口编写一些获取或设置数值的方法。用于读取变量的方法通常称为“获取方法(getter)”,用于写入变量的方法通常称为“设置方法(setter)”。下面以双向链表为例,使用结构体指针作为dlist_iterator_if_get()的返回值,详见程序清单3.51。
程序清单3.51 获取双向链表的迭代器接口(1)

其调用形式如下:

注意,如果省略static,则iterator_if就成了一个局部变量。由于它将在函数执行完后失效,因此返回它的地址毫无意义。这里采用了直接访问结构体成员的方式对iterator_if_t类型的结构体赋值,显然不同模块之间应该尽可能避免这种方式,取而代之的是提供相应的接口,详见程序清单 3.52。
程序清单 3.52 获取双向链表的迭代器接口(2)

其调用形式如下:
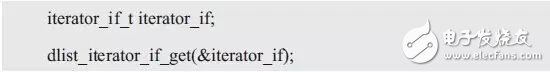
由于iterator_if_t类型的结构体中只有两个函数指针,因此对函数指针的访问仅包含设置和调用,详见程序清单 3.53。
程序清单 3.53 迭代器接口(iterator.h)

这些函数的具体实现详见程序清单3.54。
程序清单3.54 迭代器接口的实现

现在可以直接调用iterator_if_init()实现dlist_iterator_if_get(),详见程序清单 3.55。
程序清单 3.55 获取双向链表的迭代器接口(3)

>>> 3.4.3 算法的接口
由于使用迭代器可以轻松地实现指针的前移或后移,因此可以使用迭代器接口实现冒泡排序算法。其函数原型为:

其中,p_if表示算法使用的迭代器接口。begin与end是一对迭代器,表示算法的操作范围,但不一定是容器的首尾迭代器,因此算法可以处理任何范围的数据。为了判定范围的有效性,习惯采用前闭后开范围表示法,即使用begin和end表示的范围为[begin,end),表示范围涵盖bigen到end(不含end)之间的所有元素。当begin==end时,上述所表现的便是一个空范围。
compare同样也是比较函数,但比较的类型发生了变化,用于比较两个迭代器所对应的值。其类型compare_t定义如下:
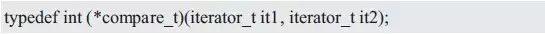
swap函数用于交换两个迭代器所对应的数据,其类型swap_t定义如下:

由此可见,接口中只有迭代器,根本没有容器的踪影,从而做到了容器与冒泡排序算法彻底分离,基于迭代器的冒泡排序算法详见程序清单3.56。
程序清单3.56 冒泡排序算法函数

下面以一个简单的例子来测试验证基于迭代器的冒泡排序算法,详见程序清单3.57。将整数存放到双向链表中,首先将5、4、3、2、1分别加在链表的尾部,接着调用dlist_foreach()遍历链表,看是否符合预期,然后再调用算法库的iter_sort()排序。当排序完毕后链表的元素应该是从小到大排列的,再次调用算法库的dilst_foreach()遍历链表,看是否符合预期。
程序清单3.57 使用双向链表、算法和迭代器

在这里,使用了dlist_foreach()遍历函数,既然通过迭代器能够实现冒泡排序,那么也能通过迭代器实现简单的遍历算法,此时遍历算法与具体容器无关。遍历函数的原型如下:
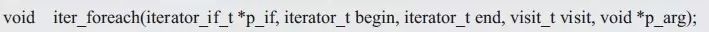
其中,p_if表示算法使用的迭代器接口,begin与end表示算法需要处理的迭代器范围,visit是用户自定义的遍历迭代器的函数。其类型visit_t定义如下:

visit_t的参数是p_arg指针和it迭代器,其返回值为int类型的函数指针。每遍历一个结点均会调用visit指向的函数,传递给p_arg的值即为用户参数,其值为iter_foreach()函数的p_arg参数,p_arg的值完全是由用户决定的,传递给it迭代器的值即为指向当前遍历的迭代器,iter_foreach()函数的实现详见程序清单3.58。
程序清单3.58 遍历算法函数

现在可以将程序清单3.57中的第43行和第48行中的dlist_foreach()函数修改为使用iter_foreach()函数,看能否得到相同的效果?
如果将数据保存在数组变量中,那么将如何使用已有的冒泡排序算法呢?由于数组也是容器,因此只要实现基于数组的迭代器即可,详见程序清单3.59。
程序清单3.59 使用数组实现迭代器接口

基于新的迭代器,同样可以直接使用冒泡排序算法实现排序,详见程序清单3.60。
程序清单3.60 使用数组、算法和迭代器

由此可见,通过迭代器冒泡排序算法也得到了复用。如果算法库里有几百个函数,那么只要实现迭代器接口的2个函数即可,从而达到复用代码的目的。显然,迭代器是一种更灵活的遍历行为,它可以按任意顺序访问容器中的元素,而且不会暴露容器的内部结构。
-
算法和数据结构基础知识分享(上)2023-04-06 1646
-
JavaScrit数据结构与算法(第2版)2021-06-01 885
-
大牛分享平时如何学习数据结构与算法2018-11-02 3772
-
了解Python数据结构迭代对象、迭代器、生成器的概念2017-11-15 1486
-
算法与数据结构——接口2017-09-19 9593
-
数据结构与算法2016-03-30 687
-
数据结构与算法习题2016-03-03 792
-
数据结构与算法分析2012-06-05 3458
-
C#数据结构和算法分析_ 魏宝刚2011-12-15 1774
-
数据结构教程,下载2009-05-14 901
-
数据结构与算法分析(Java版)(pdf)2008-12-20 4738
全部0条评论

快来发表一下你的评论吧 !
