

算法与数据结构——哈希表
电子说
描述
周立功教授数年之心血之作《程序设计与数据结构》以及《面向AMetal框架与接口的编程(上)》,书本内容公开后,在电子行业掀起一片学习热潮。经周立功教授授权,本公众号特对《程序设计与数据结构》一书内容进行连载,愿共勉之。
第三章为算法与数据结构,本文为3.5 哈希表。
>>>3.5.1 问题
假设需要设计一个信息管理系统,用于管理大约一万个学生的相关信息,可以通过学号查找到对应学生的信息,每条学生记录包含学号、姓名、性别、身高、体重等信息。即:

作为信息管理系统,首先要能够存储学生记录,这上万条记录如何存储呢?简单地,可以使用一段连续的内存存储学生记录,比如,使用一个大数组存储,每个数组元素都可以存储一条学生记录:
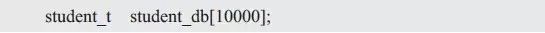
当使用数组存储学生信息时,如何通过学号查找相应的信息呢?如果学号编排是一种非常理想的情况,10000个学生的学号按照 0 ~ 9999顺序排列,则可以直接将学号作为数组的索引值查找相应的数组元素,其存储和查找的效率都非常高。但实际上学号往往不是如此简单编排的,一种常见的编排方法是“年级+专业代码+班级+班级内序号”,比如,6字节学号为0x20, 0x16, 0x44, 0x70, 0x02, 0x39,即:201644700239,表示2016年入学,专业代码为4470(即计算机专业),2班的39号同学。
此时,通过学号查找学生信息的方法也很简单,直接从第一个学生记录开始,顺序遍历各个学生记录,将记录中的学号与期望查找的学生学号相比较,学号相同即查找到了相应学生的信息,详见程序清单3.61。
程序清单3.61 顺序查找范例程序

显然,如果采用顺序查找法,学生记录越多,则查找时需要比较的次数越多,效率也就越低。当学生记录的条数上万时,则可能需要比较上万次才能找到相应的学生信息。
如何以更高的效率实现查找呢?在理想情况下,若将学号作为数组索引存储数据,则查找的效率非常高。既然如此,如果扩大数组容量至学号的最大值加1(以包含学号0),则可以直接以学号作为数组的索引值。由于学号是由6字节组成的,因此数组必须能够容纳248条记录,需要占用多少存储空间呢?就算一条记录只占用一个字节,也需要262144 G存储空间,何况电脑硬盘没这么大!如果只使用其中的10000条记录,则剩下的(248-10000)空间就会造成极大的浪费,显然这种方式是不可取的。
在查找算法中,非常经典高效的算法是“二分法查找”,按10000条记录算,最多也只需要比较14次(log210000)。但使用“二分法查找”的前提是信息必须有序排列,即要求学生记录必须按照学号的顺序存储,这就导致在添加或删除学生信息时,数据库存储的信息需要进行大量的移动操作。比如,数组中已经按照学号从小到大的顺序存储了9999条记录,现在写入第10000条记录,若该记录的学号最小,需要写入到所有记录的前面,这就需要将之前存储的9999条记录全部向后移动一次,以预留出首元素的空间,然后将新的学生记录写入首元素对应的空间中。由此可见,虽然使用这种方法可以提高查找效率,却牺牲了添加信息时的效率。
为了在添加信息时不进行大量的数据移动,能否换一种存储方式呢?比如,使用存储空间不连续的“单向链表”结构,将各个学生记录“链”起来,其示意图详见图3.23。
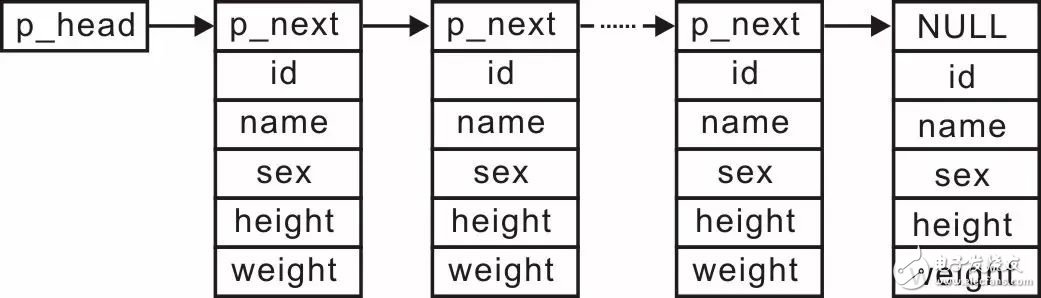
图3.23 使用单向链表管理学生记录
当使用链表管理学生记录时,实现有序排列只需每次插入新结点时,找到正确的插入位置,无需进行大量数据的移动。由于存储空间不连续,因此无法使用“二分法”查找学生信息,则实现有序排列也没有解决查找效率低下的问题,无论是否有序,查找时都需要从头开始顺序查找。
由此可见,使用“二分法查找”必须牺牲记录写入的效率以实现所有记录有序排列,使得写入记录的效率非常低。虽然基础的“顺序查找”对写入记录的效率完全不影响,但查找效率极为低下。因此,这两种情况都太极端了,要么选择极低的写入效率,要么选择极低的查找效率。何不将二者结合一下,以折中写入的效率和查找的效率呢?比如,将记录“二分”为两部分,使用两个数组来存储:
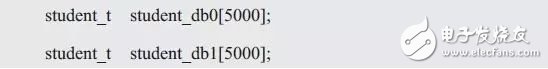
假设规定,学号小于某值(即201044700239)时,记录存储在student_db0中,反之,记录存储在student_db1中。如此一来,在写入记录时,只需要多一条判断语句,对性能并没太大影响。而在查找时,只要根据学号判断记录在哪一个数组中,即可按照顺序查找的方式查找。此时,查找需要比较的次数就从最大的10000次降低到了5000次。由此可见,通过一个简单的方法,将信息分别存储在两个数组中,就可以明显地提高查找效率。为了继续提高查找的效率,还可以继续分组,比如,分成250组,每组的大小为40:

显然,采用这种定义方式太繁琐了,由于每个数组的大小是相同的,因此可以直接将存储40个学生记录的数组定义为一个类型:

此时,每个分组的大小为40,从而使得查找记录时,最多只需要比较40次。接下来,需要定义分组规则,以通过学号找到该记录属于哪个组。在定义规则时,应尽可能地使所有记录平均地分布在各个组中,不应该出现一些组存储的记录非常多,而一些组存储的记录非常少的情况。但这并不是一件容易的事情,需要对学号的数据分布进行精确的分析。
如果分成250组,假定学号是均匀分布的,则可以将6字节学号数求和除以250(分组数目)所得的余数(取余法)作为分组的索引,由于写入和查找时,都需要通过学号找到该记录应该属于哪个组,因此可以根据学号分组的依据,编写一个通过学号找到对应分组索引的函数,详见程序清单3.62。
程序清单3.62 通过学号分组范例程序

即将分组数为250看作一个大小为250的表格,每个表项可以存储40个学生记录的数组,通过db_id_to_idx()函数找到关键字学号ID对应在该表中的位置。其中,大小为250的表格就是“哈希表”,详见图3.24。db_id_to_idx()函数就是“哈希函数”,哈希函数的结果(分组索引)称之为“哈希值”。
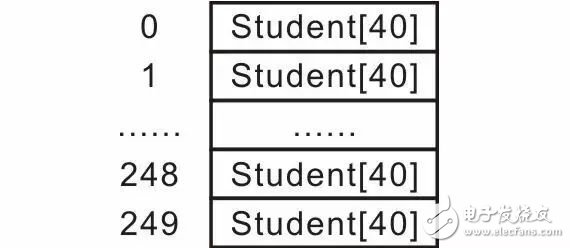
图3.24 哈希表
哈希表的核心工作在于哈希函数的选择,将查找的关键字送给哈希函数产生一个哈希值,哈希函数的选择直接决定了记录的分布,必须尽可能地确保所有记录均匀地分布在各个组中。在上面的示例中,每个分组中都定义了大小相同的数组作为记录存储的空间。如果按照分组规则,能够确保恰好均匀地分布在各个分组中,这是最佳的。
而实际上学生记录是会变动的,可能增加或删除,则很难保证按照现在定义的分组规则,保证100%的完全平均。如果每个分组都使用大小相同的数组作为记录存储的空间,则可能会导致部分数组未存满,部分数组却存不下的情况,就会导致部分学生记录无处可存,造成严重的数据管理问题。
由于数组都是提前定义好大小的,动态性能差,而链表的动态性能更好,可以根据需要增加、删除结点,改变链表长度,因此可以使用链表管理学生记录,就算分布不均匀,也只存在链表长度的差异,不会出现数据存储不了的问题,其示意图详见图3.25。
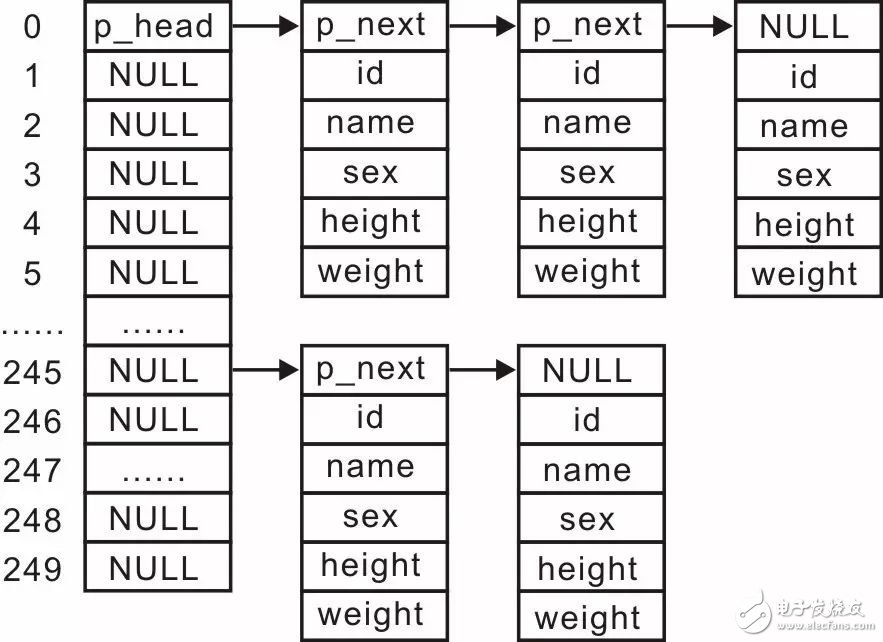
图3.25 链式哈希表
当使用链表管理学生记录时,哈希表每个表项的实际内容就是该组链表的表头。链表头结点的类型slist_head_t(slist.h)的定义如下:

基于此,在哈希表的每个表项中存储一个slist_head_t类型的链表头结点即可,哈希表的定义如下:

根据对链式哈希表结构的分析,编写一个基于链式哈希表的信息管理系统,作为示例仅提供增加、删除、查找三种功能。当然,在使用这些功能前,还必须定义一个哈希表对象的类型,以便使用该类型定义具体的哈希表实例,进而使用各个功能接口对该实例进行操作。
>>> 3.5.2 哈希表的类型
哈希表类型struct _hash_db定义如下:
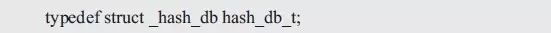
在结构体中,需要包含哪些哈希表的相关信息呢?链式哈希表的核心是一个slist_head_t类型的数组,其大小与分组数目相关。为了通用,分组数目应由用户根据实际情况确定。slist_head_t类型的数组信息由一个指向数组首地址的slist_head_t*类型的指针和一个指定数组大小的size构成,哈希表结构体类型的定义如下:

在实际的应用中,信息可以是任意数据类型(void *),其次还需要知道该void *指针指向的记录的长度,比如,学生记录的长度是sizeof(student_t),因此更新哈希表结构体类型的定义如下:

在存储或查找记录时,可以通过与关键字(比如,学号ID)比较找到哈希表中的索引值,然后在对应的表项中添加或查找记录。在存储记录时,需要提供关键字和记录;而在查找记录时,仅需提供关键字。由此可见,关键字和记录是两个不同的概念,关键字具有特殊的作用,因此关键字和记录应该分别对待。对于学生信息管理系统来说,其关键字为学号,长度是6字节,记录包含姓名、性别、身高、体重等信息。因此,在学生记录结构体的定义中,将关键字ID分离出来。学生记录的定义如下:

同理,关键字的长度也是由用户决定的,在存储一条记录时,需要分配内存存储关键字,以便查询时读取该关键字与查询使用的关键字进行比较。因此在哈希表的结构体类型中,需要包含关键字长度信息,更新哈希表结构体类型的定义如下:

特别地,在前面的分析中,哈希表最重要的一个概念就是“哈希函数”,哈希函数的作用是通过关键字(如学号ID)得到其对应记录在哈希表中的索引值,哈希函数要尽可能确保记录均分地分布在哈希表的各个表项中。对于不同的数据,用户可能选择不同的哈希函数,因此哈希函数应该由用户指定。基于此,在哈希表结构体中新增一个函数指针,用于指向用户自定义的哈希函数。完整的哈希表结构体类型定义如下(hash_db.h):

在使用哈希表的各个接口函数前,首先需要使用该类型定义一个哈希表实例:

如果系统中需要使用多张哈希表,则只需要使用该类型定义多个哈希表实例即可:

>>> 3.5.3 哈希表的实现
1、初始化
hash_db_init()接口用于哈希表实例的初始化,在定义哈希表结构体类型时,哈希表数组大小、记录长度、关键字长度和哈希函数都需要由用户根据实际情况确定,其函数原型定义如下(hash_db.h):

在这里,以学生记录为例,创建一个大小为250组的哈希表:

在初始化函数的实现中,需要按照size指定的大小分配内存,用于存储哈希表的各个表项(链表头),接着需要完成各个链表头和结构体成员的初始化,初始化函数的实现范例详见程序清单3.63。
程序清单3.63 初始化函数范例程序

2、添加记录
hash_db_add()接口用于向已经初始化的哈希表中添加一条记录,添加一条记录时,需要指定关键字信息和记录值信息,其函数原型定义(hash_db.h):
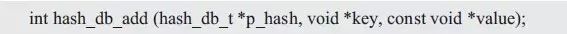
其中,p_hash为指向哈希表实例的指针,key为指向关键字的指针,value为指向记录值的指针。特别地,由于在添加记录时,程序不会修改key和value指针所指向的值,因此,指针都加了const修饰符。以添加一条学生记录为例,使用范例如下:

在添加记录函数的实现中,首先需要使用哈希函数找到关键字对应的记录在哈希表中的索引,以确定该条记录所在链表的表头,然后分配一个存储记录的结点空间,将关键字、记录等信息存储在该空间中,然后将结点添加到对应链表的头部(由于记录在链表中的具体位置不重要,因此直接添加在链表头部,效率更高)。函数实现的范例详见程序清单3.64。
程序清单3.64 添加记录函数范例程序

程序分配了一个结点的空间,该结点的空间需要存储一个slist_node_t类型链表结点,便于添加结点到链表中,存储长度为p_hash->key_len的关键字,存储长度为p_hash->value_len的记录值,详见图3.26,其内存的大小为:
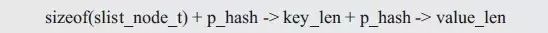

图3.26 结点存储空间分布
由于结点空间的首部用于存储结点slist_node_t的值以组织链表。因此需要将结点添加到链表中时,直接将p_mem转换为slist_node_t*类型使用即可,通用链式哈希表的结构示意图详见图3.27。
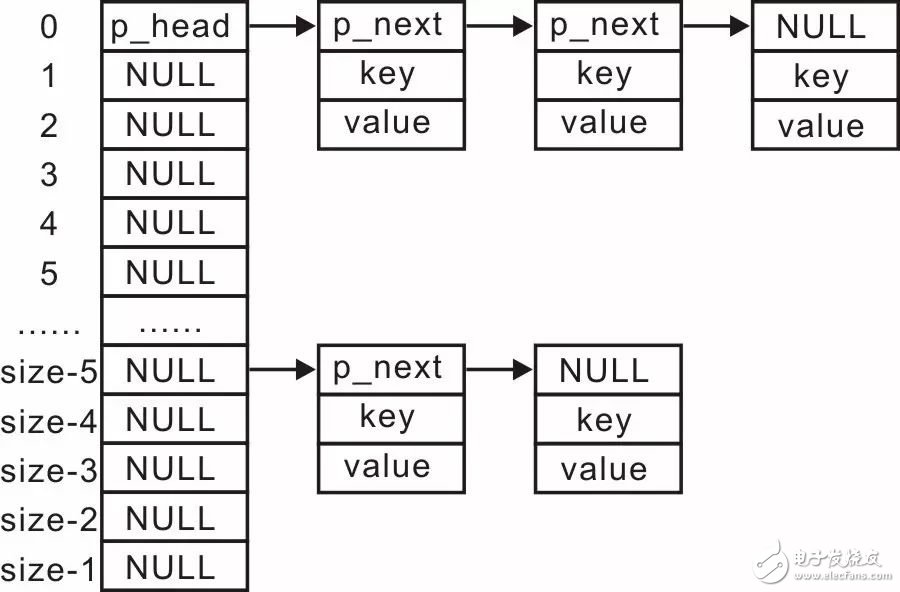
图3.27 通用的链式哈希表结构示意图
与图3.25中管理学生记录的链式哈希表结构示意图对比发现,它们表达的含义是完全一致的,仅仅是具体类型变为了更加通用的void *类型。
3、查找记录
hash_db_search()接口通过关键字查找与之对应的记录,查找记录时,需要指定关键字信息,同时还需要使用一个指向记录的指针获取查找到的记录值,其函数原型(hash_db.h)如下:

虽然参数与添加记录是完全一样的,但value表示的含义却不一样,此处的value是输出参数,用于得到查找到的记录值。而添加记录函数中的value是输入参数,提供需要存储的记录值。由于此处的value指向指向的值是需要被改变的(改变为查找到的记录值),因此,其不能增加const修饰符。以查找ID为201444700239的学生记录为例,使用范例如下:

在该函数的实现中,首先需要使用哈希函数找到关键字对应的记录在哈希表中的索引,以确定该条记录所在链表的表头,然后遍历链表的各个结点,将提供的关键字与结点中存储的关键字比对,直到找到关键字完全一致的记录(查找成功)或链表遍历结束(查找失败)。找到该记录对应的结点后,将结点中存储的value值拷贝到参数value指针指向的空间中即可。函数实现的范例详见程序清单3.65。
程序清单3.65 查找记录函数范例程序

程序中,由于查找结点时需要遍历链表,关键字比对的操作需要在遍历函数的回调函数中完成,因此,需要将用户查找记录使用的关键字信息(关键字及其长度)提供给回调函数,同时,当查找到记录时,需要将查找到的结点反馈给调用遍历函数的主程序。为此,定义了一个内部使用的用于寻找一个结点的上下文结构体:

调用遍历函数时,需要提供一个设置好关键字信息的结构体作为回调函数的用户参数。遍历函数结束时,可以通过该结构体中的p_result成员获取遍历结果。
4、删除记录
该接口用于删除指定关键字对应的记录,可以定义其函数名为:hash_db_del()。删除记录时,需要指定关键字信息。可以定义函数的原型为:

以删除学号为201444700239的学生记录为例,使用范例如下:
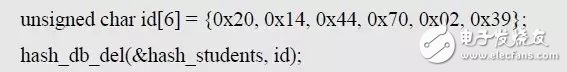
在该函数的实现中,绝大部分操作与查找记录是相同的,唯一的不同是,当找到关键字对应的结点时,不再需要将记录值提取出来,直接将该结点删除即可。函数实现的范例详见程序清单3.66。
程序清单3.66 删除记录函数范例程序

5、解初始化
对应于哈希表的初始化,用于当不再使用哈希表时,释放相关的空间。可以定义其函数名为:hash_db_deinit()。需要通过参数指定需要解初始化的哈希表实例,可以定义函数的原型为(hash_db.h):
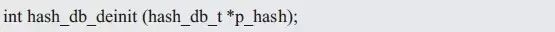
如不再使用学生信息管理系统,则需使用解初始化函数释放哈希表的相关资源,使用范例如下:
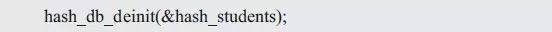
在该函数的实现中,需要释放程序中分配的所有空间,主要包括添加记录时分配的结点空间,链表头结点数组空间。函数实现详见程序清单3.67。
程序清单3.67 解初始化函数范例程序

为便于查阅,如程序清单3.29所示展示了hash_db.h文件的内容。
程序清单3.68 hash_db.h文件内容

以使用该链式哈希表管理系统来管理学生记录为例,综合范例程序详见程序清单3.30。
程序清单3.69 哈希表综合范例程序

在这里,首先创建了一个哈希表,然后向其中添加了100个学生信息(以随机数的方式产生的),接着查找了ID对应的学生信息(这里的ID没有特别设置,即查找最后添加的学生记录),最后释放哈希表。
- 相关推荐
- 热点推荐
- 哈希表
-
算法和数据结构基础知识分享(中)2023-04-06 1423
-
JavaScrit数据结构与算法(第2版)2021-06-01 885
-
哈希表是什么?为什么需要使用哈希表2020-04-06 12745
-
大牛分享平时如何学习数据结构与算法2018-11-02 3776
-
哈希表是什么?哈希表数据结构详细资料分析2018-09-24 10763
-
java数据结构学习2017-11-29 1166
-
算法与数据结构——接口2017-09-19 9596
-
数据结构与算法2016-03-30 688
-
数据结构与算法习题2016-03-03 792
-
数据结构与算法分析2012-06-05 3459
-
C#数据结构和算法分析_ 魏宝刚2011-12-15 1778
-
数据结构概述及线性表2010-12-05 3312
-
数据结构教程,下载2009-05-14 901
-
数据结构与算法分析(Java版)(pdf)2008-12-20 4738
全部0条评论

快来发表一下你的评论吧 !
