

ARM发布最新Compute Library
电子说
描述
开心了这么多天,该“收心”好好干活了,正好Arm有一个好消息要告诉大家,最新一季的 Compute Library 公开发行版(版本 17.9)现已推出,让我们一起来看看重点新增的一些特性和函数吧。

此发行版主要增添了以下特性:
-
多个新的面向 Arm CPU 和 Mali GPU 的机器学习函数
-
支持新的数据类型和精度(重点支持低精度数据类型)
-
支持利用 Arm-v8.2 CPU 架构的新指令实现 FP16 加速
-
针对关键的机器学习函数进行微架构优化
-
降低复杂网络内存开销的内存管理工具
-
用于基本测试的基础结构框架
我们添加了许多新的函数,满足以 Arm 型平台为目标的开发人员的需求。这些新例程采用 OpenCL C 和 C(利用 NEON Intrinsics)编写。
OpenCL C(针对 Mali GPU):
-
Bounded ReLu
-
Depth wise卷积(在 mobileNet 中使用)
-
反量化
-
Direct卷积 1x1
-
Direct卷积 3x3
-
Direct卷积 5x5
-
3D 张量展平
-
向下取整
-
全局池化(在 SqueezeNet 中使用)
-
Leaky ReLu
-
量化
-
Reduction 运算
-
ROI 池化
CPU (NEON):
-
Bounded ReLu
-
Direct卷积 5x5
-
反量化
-
向下取整
-
Leaky ReLu
-
量化
-
具有定点加速的新函数
Direct卷积是在经典滑动窗口基础上执行卷积层的一种替代方法。在 Mali GPU Bifrost 架构的实现中,使用Direct卷积对于改进我们 CNN 的性能很有帮助(我们观察到,对 AlexNet 使用Direct卷积时性能最多可提升 1.5 倍)。
支持低精度在许多机器学习应用场景中,可以通过降低计算精度来提升效率和性能。这是我们工程师上一季度的重点关注领域。我们利用低精度实施了现有函数的新版本,如 8 位和 16 位定点,这同时适用于 CPU 和 GPU。
GPU (OpenCL) - 8 位定点
-
Direct卷积 1x1
-
Direct卷积 3x3
-
Direct卷积 5x5
GPU (OpenCL) - 16 位定点
-
算术加法、减法和乘法
-
深度转换
-
深度连接(concatenate)
-
深度卷积
-
GEMM
-
卷积层
-
全连接层
-
池化层
-
Softmax 层
NEON - 16 位定点
-
算术加法、减法和乘法
-
卷积层
-
深度连接(concatenate)
-
深度转换
-
Direct卷积 1x1
-
全连接层
-
GEMM
-
Softmax 层
在 Compute Library 项目启动之初,我们的宗旨主要是共享计算机视觉和机器学习的一整套底层函数,要保障性能良好,最为重要的是要可靠且可移植。Compute Library 能够为着眼于 Arm 处理器的开发人员和合作伙伴节省时间和成本;同时,Compute Library 在我们合作伙伴实施的许多系统配置中也有出色的表现。这也是我们将NEONintrinsic和 OpenCL C 作为目标语言的原因。但在某些情形中,必须要充分发挥硬件的所有性能。因此,我们也着眼于在 Compute Library 中增加底层原语,这些底层原语利用专为目标 CPU 微架构定制的手工汇编进行了优化。
在决定我们应将重点放在哪些函数时,我们的研发团队研究了利用 Caffe 框架的机器学习工作负载。
所用的三种工作负载为:
-
AlexNet,将图像目标分类到1000个可能类别的 大型网络
-
LeNet,将手写数字分类到10个可能类别的 中型网络
-
ConvNet,将图像分类到10个可能类别的 小型网络
下图显示了这些工作负载的指令使用情况:

我们的团队发现,这些网络大约有 50-80% 的计算在 SGEMM 函数内发生,这个函数是将两个浮点矩阵相乘。还有其他几个函数也比较突出,例如幂函数和转换矩阵维度的函数。其余的计算则分散在一个长尾分布中。
您可以发现这样的一个趋势,SGEMM 所占的比例随着网络规模变大而升高,但这种趋势更有可能是因为层的配置所致,而不是与大小相关。从中我们可以意识到,矩阵乘法对神经网络确实非常重要。如果说哪个目标函数最需要优化,应该就是它了。
在此发行版的库中,我们增加了面向 Cortex-A53 和 Cortex-A72 处理器的 CPU 汇编优化版 SGEMM (FP32)。这些例程的性能视平台而异,但我们在测试中看到总体性能有大幅提升。例如,我们对 Firefly 开发板(64 位,多线程)进行了 AlexNet 基准测试,在 Cortex-A72 上测量到性能提升了约 1.6 倍。
下表显示了我们在相同平台上使用新的优化例程的一组基准测试结果。

在关于 17.6 发行版的介绍中(Arm计算库第二个公开版本正式发布,这些厂商一直在用其进行开发!),Arm计划在 CPU 中支持用于机器学习的新架构功能,而第一步就是在 Armv8.2 CPU 中支持 FP16。目前,库中增加了面向 Armv8.2 FP16 的新函数:
-
激活层
-
算术加法、减法和乘法
-
批量归一化(Batch Normalization)
-
卷积层(基于 GEMM)
-
卷积层(Direct卷积)
-
局部连接
-
归一化
-
池化层
-
Softmax 层
虽然我们没有对这些函数做一些激进的优化(这些函数采用 NEON intrinsic而非手工优化的汇编语言编写),但与使用 FP32 且必须在不同格式之间转换相比,性能有了大幅提升。下表比较了一些工作负载,从中可以看出,借助 v8.2 CPU 指令,可以减少计算所需的周期数。

如今,许多移动合作伙伴正在利用 Mali GPU 来加快机器学习工作负载的速度。根据这些合作伙伴的反馈,我们在这个领域做了针对性的优化。
新的Direct卷积 3x3 和 5x5 函数针对 Bifrost 架构进行了优化,性能与上一发行版 (17.06) 中的例程相比有了显著提升。在部分测试平台上使用这些新例程时,我们发现性能普遍提高约 2.5 倍。此外,在 AlexNet 的多批量工作负载中,GEMM 中引入的新优化帮助我们获得了 3.5 倍的性能提升。性能因平台和实现方法而异,但总体而言,我们预计这些优化能够在 Bifrost GPU 上显著提升性能。
下图显示了在华为 Mate 9 智能手机上的一些测试结果,测试中禁用了 DVFS,取 10 次运行中最短的执行时间作为结果。由此可见,新例程在性能上优于旧版本。

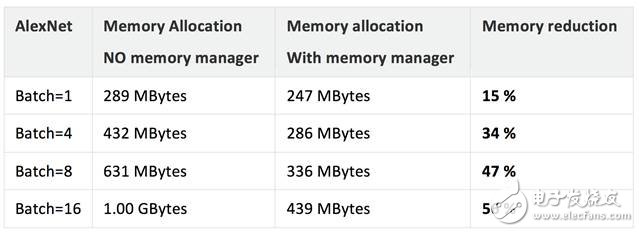
复杂工作负载(大型网络)会需要大量内存,对于嵌入式平台和移动平台而言,这正是影响性能的症结所在。我们听取了合作伙伴的反馈,决定在库的运行时组件中添加一个“内存管理器”功能。内存管理器通过循环利用临时缓冲区降低通用算法/模型的内存要求。
内存管理器包含一个生命周期管理器(用于跟踪注册对象的生命周期)和一个池管理器(用于管理内存池)。当开发人员配置函数时,运行时组件会跟踪内存要求。例如,一些张量可能仅仅是暂时的,所以只分配所需的内存。内存管理器的配置应从单一线程循序执行,以便提高内存利用率。
下表显示了在使用内存管理器时在我们测试平台上测量到的内存节省情况。结果因平台、工作负载和配置而异。总体而言,我们认为内存管理器能够帮助开发人员节省内存。

接下来,我们计划继续根据合作伙伴和开发人员的需求,进行具体的优化。此外,我们还将重视与机器学习框架的集成,并与 Google Android NN 等新的 API 保持同步。
我们的目标不是涵盖所有数据类型和函数,而是根据开发人员和合作伙伴的反馈,精选出最需要实施的函数。所以,我们期待着听到您的声音!
- 相关推荐
- A
-
W5500 ARM mbed 库发布2014-06-24 0
-
PRI Compute Module – 树莓派的继任者2014-09-30 0
-
请问C2000支持IEC60730的library发布了吗?2018-08-19 0
-
使用CRL“ARM CMSIS SIN COS”和SW4STM32发布构建simulink项目代码报错怎么解决?2023-01-16 0
-
VHDL Library of Arithmetic Uni2009-06-14 386
-
ADS_FSL_LIBRARY2013-09-13 1533
-
C28x Signal Generator Library2016-05-24 575
-
FX3 Wrapper Library2021-01-29 584
-
ADM1266 Python Library2021-02-02 420
-
使用新的Nsight Compute改进导航和性能可视化2022-06-21 2748
-
ARM系列—机密计算2023-05-24 1030
-
Arm RAN 加速库(RAN Acceleration Library, RAL)通过采用 BSD 开源许可证将代码库正式开源2023-07-20 1372
-
树莓派基金会发布Compute Module2023-10-09 514
全部0条评论

快来发表一下你的评论吧 !
