

深度解读分布式存储技术之分布式剪枝系统
存储技术
描述
分布式存储简单的来说,就是将数据分散存储到多个数据存储存储服务器上。分布式存储目前多借鉴Google的经验,在众多的服务器搭建一个分布式文件系统,再在这个分布式文件系统上实现相关的数据存储业务,甚至是再实现二级存储业务如Bigtable。
分布式文件系统存储目标以非结构化数据为主,但在实际应用中,存在大量的结构化和半结构化的数据存储需求。分布式键值系统是一种有别于我们所熟悉的分布式数据库系统的,用于存储关系简单的半结构化数据的存储应用。
在分布式键值系统中,半结构化数据被封装成由《key,value,timestamp》键值对组成的对象,其中key为唯一标示符;value为属性值,可以为任何类型,如文字、图片,也可以为空;timestamp为时间戳,可以提供数据的多版本支持。分布式键值系统以键值对存储,它的结构不固定,每一元组可以有不一样的字段,可根据需要增加键值对,从而不局限于固定的结构,适用面更大,可扩展性更好。
分布式键值系统支持针对单个《key,value,timestamp》键值对的增、删、查、改操作,可以运行在PC服务器集群上,并实现集群按需扩展,从而处理大规模数据,并通过数据备份保障容错性,避免了分割数据带来的复杂性和成本。
总体来说,分布式键值系统从存储数据结构的角度看,分布式键值系统与传统的哈希表比较类似,不同的是,分布式键值系统支持将数据分布到集群中的多个存储节点。分布式键值系统可以配置数据的备份数目,可以将一份数据的所有副本存储到不同的节点上,当有节点发生异常无法正常提供服务时,其余的节点会继续提供服务。
下面,我们来看看业界主流的分布式键值系统的架构模式。
Amazon Dynamo
Dynamo是AWS上最基础的分布式存储应用之一,也是AWS最早推出的云服务之一,它构建在AWS的S3基础之上,采用去中心节点化的P2P方式,采用这种模式的,还有Facebook推出的Cassandra。
1、数据分布
Dynamo使用了改进的一致性哈希算法:每个物理节点根据其性能的差异分配多个token,每个token对应一个“虚拟节点”。所有节点每隔固定时间(比如1s)通过Gossip协议的方式从其他节点中任意选择一个与之通信的节点。如果连接成功,双方交换各自保存的集群信息。
Gossip协议用于P2P系统中自治的节点协调对整个集群的认识,比如集群的节点状态、负载情况。由于种子节点的存在,新节点加入可以做得比较简单:新节点加入时首先与种子节点交换集群信息,从而了解整个集群。
2、一致性与复制
一般来说,从机器K+i宕机开始到被认定为永久失效的时间不会太长,积累的写操作也不会太多,可以利用Merkle树对机器的数据文件进行快速同步。Dynamo引入向量时钟(Vector lock)的技术手段来尝试解决冲突,这个策略依赖集群内节点之间的时钟同步算法,但不能完全保证准确性。Dynamo只保证最终一致性,如果多个节点之间的更新顺序不一致,客户端可能读取不到期望的结果。
3、容错
核心机制就是:数据回传+Merkle树同步+读取修复
Dynamo在数据读写中采用了一种称为弱quorum (Sloppy quorum)的机制,涉及三个参数W、R、N,见其中W代表一次成功的写操作至少需要写入的副本数,R代表一次成功读操作需由服务器返回给用户的最小副本数,N是每个数据存储的副本数。Dynamo要求R+W〉N,满足这个要求,保证用户读取数据时,始终可以获得一个最新的数据版本。
针对临时故障,一旦某个节点出现问题,则将这个节点值传送给“同组”中的下一个正常节点,并在这个数据副本的元数据中记录失效的节点位置,便于数据回传;然后,由这个节点上一个临时空间进行存储和处理数据,同时该节点还对失效的节点进行监测,一旦失效的节点重新可用,则将自己所保存的最新数据回传给它,然后删除自己开辟的临时空间数据。
针对永久性故障,Dynamo必须检査和保持数据的同步 ,Dynamo采用一种称为反熵协议的手段来保证数据的同步。为了减少数据同步检测中需要传输的数据量,加快检测速度,Dynamo使用了Merkle哈希树技术,每个虚拟节点保存三颗Merkle树,即每个键值区间建立一个Merkle树。Dynamo中Merkle哈希树的叶子节点是存储每个数据分区内所有数据对应的哈希值,父节点是其所有子节点的哈希值。
4、负载均衡
采用改进的一致性Hash+虚拟节点模式。
在传统的一致性哈希算法上,服务节点跟哈希环上的点是一一对应的。这里会存在一个问题,就是每一个节点的负载最后是不均匀的,而我们也无法进行调整。Dynamo通过一个服务节点可以有多个哈希环上的虚拟节点的方法,使得每一个服务节点的负载都是均匀的。并且假如发现了某一个节点的负载过高,少分配虚拟节点给它便可以降低该服务节点的负载,从而实现了自动地负载均衡。
5、读写流程
由于采用了去中心化的模式,因此,需要采用较复杂的模式来控制并发,Dynamo使用Paxos协议结合Gossip来进行并发处理。具体处理模式如图1所示。
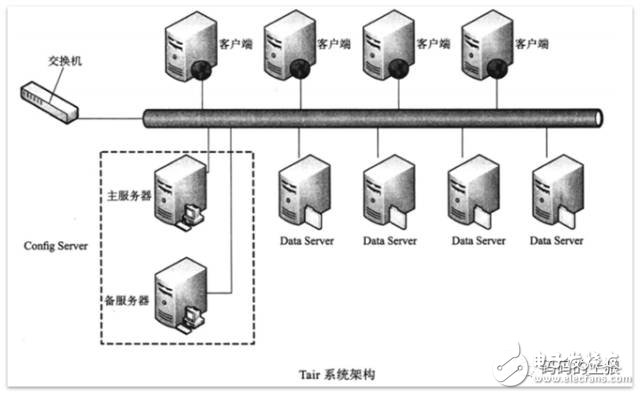
图1 Dynamo 写入和读取流程
Dynamo采用去中心节点的P2P设计,增加了系统可扩展性,但同时带来了一致性问题,影响上层应用。一致性问题使得异常情况下的测试变得更加困难,由于Dynamo只保证最基本的最终一致性,多客户端并发操作的时候很难预测操作结果,也很难预测不一致的时间窗口,影响测试用例设计。
由于去中心化模式所导致的复杂性和不确定性。目前主流的分布式系统一般都带有中心节点,这样能够简化设计,而且中心节点只维护少量元数据,一般不会成为性能瓶颈。
淘宝Tair
Tair是阿里巴巴推出的一个高性能,分布式,可扩展,高可靠的key/value结构存储系统,它专门针对小文件的存储做了优化,并提供简单易用的接口(类似Map)。
1、整体架构
Tair作为一个分布式系统,是由一个中心控制节点和若干个服务节点组成。Config Server是控制点,而且是单点,目前采用一主一备的形式来保证可靠性,所有的Data Server地位都是等价的。
图2 Tair系统架构
2、数据分布
Tair根据数据的主键计算哈希值后,分布到Q个桶中,根据Dynamo论文中的实验结论,Q取值需要远大于集群的物理机器数,例如Q取值102400。
3、容错
如果是备副本,则直接迁移;如果是主副本,则先切换再迁移。
4、数据迁移
机器加入或者负载不均衡可能导致桶迁移,迁移的过程中需要保证对外服务。当迁移发生时,假设Data Server A要把桶1、2、3迁移到Data Server B。迁移完成前,客户端的路由表没有变化,客户端对1、2、3的访问请求都会路由到A。现在假设1还没开始迁移,2正在迁移中,3已经迁移完成。那么如果对1访问,A直接服务;如果对3访问,A会把请求转发给B,并且将B的返回结果返回给用户;如果对2访问,由A处理,同时如果是对2的修改操作,会记录修改日志,等到桶2迁移完成时,还要把修改日志发送到B,在B上应用这些修改操作,直到A和B之间数据完全一致迁移才真正完成。
5、配置服务器(Config Server)
客户端缓存路由表,大多数情况下,客户端不需要访问配置服务器(Config Server),Config Server宕机也不影响客户端正常访问。如果Data Server发现客户端的版本号过旧,则会通知客户端去Config Server获取一份新的路由表。如果客户端访问某台Data Server发生了不可达的情况(该Data Server可能宕机了),客户端会主动去Config Server获取新的路由表。
6、数据服务器(Data Server)
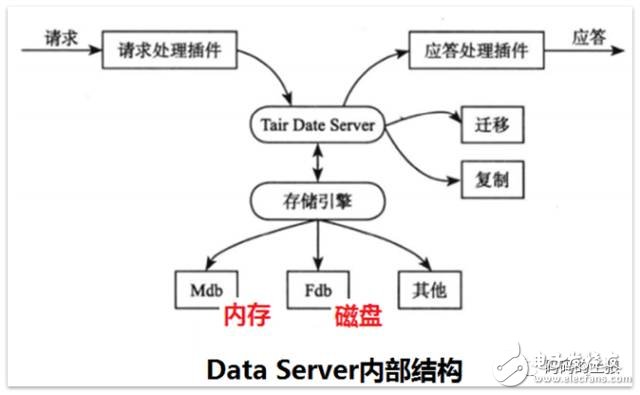
Tair存储引擎有一个抽象层,只要满足存储引擎需要的接口,就可以很方便地替换Tair底层的存储引擎。
Tair最主要的用途在于分布式缓存,持久化存储起步比较晚,在实现细节上也有一些不尽如人意的地方。例如,Tair持久化存储通过复制技术来提高可靠性,然而,这种复制是异步的。因此,当有Data Server发生故障时,客户有可能在一定时间内读不到最新的数据,甚至发生最新修改的数据丢失的情况。
-
分布式软件系统2009-07-22 5425
-
分布式控制系统2010-03-01 3424
-
分布式发电技术与微型电网2011-03-11 2554
-
分布式能源系统当微型电网技术应用2011-06-13 4154
-
如何设计分布式干扰系统?2019-08-08 2610
-
分布式系统的优势是什么?2020-03-31 3163
-
HarmonyOS应用开发-分布式设计2020-09-22 2622
-
HarmonyOS分布式应用框架深入解读2021-11-22 4793
-
如何高效完成HarmonyOS分布式应用测试?2021-12-13 2394
-
分布式电源分布式电源装置是指什么?有何特点2021-12-29 2098
-
常见的分布式供电技术有哪些?2023-04-10 1507
-
浅谈分布式块存储的元数据服务设计2018-05-31 5664
-
盘点分布式存储系统的主流框架2020-08-06 3191
-
分布式文件存储系统GFS的基础知识2020-08-25 6877
-
分布式存储的7个特征2023-07-18 1925
全部0条评论

快来发表一下你的评论吧 !
