

一文读懂深度学习中的语音分离技术
人工智能
描述
由于语音分离已经变成分类问题,所以语音分离也变得非常重要,已经在信号处理领域被研究了几十年,数据驱动的方法在语音处理领域也得到了广泛研究。
语音分离的目标是把目标语音从背景干扰中分离出来。在信号处理中,语音分离属于很基本的任务类型,应用范围很广泛,包括听力假体、移动通信、鲁棒的自动语音以及说话人识别。人类听觉系统能轻易地将一个人的声音和另一个人的分离开来。即使在鸡尾酒会那样的声音环境中,我们似乎也能毫不费力地在其他人的说话声和环境噪声的包围中听到一个人的说话内容。因此语音分离问题通常也被叫做「鸡尾酒会问题」(cocktail party problem),该术语由 Cherry 在他 1953 年那篇著名论文中提出。
人类最重要的交流方式就是语言,对我们来说,从背景干扰中分离出语音是至关重要的。感兴趣的演讲或者目标谈话经常被其它来源的多余噪声和表面反射产生的混响所干扰。虽然人类能轻易地分离语音,但事实证明,在这项基本任务中,构建一个能够媲美人类听觉系统的自动化系统是很有挑战性的。在 Cherry 1953 年出版的书 中,他观察到:「目前为止没有任何机器能解决『鸡尾酒会问题』。」很不幸的是,虽然本文提到的近期研究进展已经开始解决这个问题,但在我们这个领域中,他的结论一直保持了60 多年的正确性。
语音分离非常重要,已经在信号处理领域被研究了几十年。根据传感器或麦克风的数量,分离方法可分为单声道方法(单个麦克风)和阵列方法(多个麦克风)。单声道分离的两个传统方法是语音增强 和计算听觉场景分析(CASA)。语音增强方法分析语音和噪声的全部数据,然后经过带噪语音的噪声估计,进而对清晰语音进行估计。最简单以及应用最广泛的增强方法是频谱相减法(spectral subtraction),其中估计噪声的功率谱会从带噪语音中删去。为了估计背景噪声,语音增强技术一般假定背景噪音是稳定的,也就是说,其频谱特性不会随时间变化,或者至少比语音稳定一些。CASA 建立在听觉场景分析的感知理论基础上,利用聚类约束(grouping cue)如基音频率(pitch)和起音(onset)。例如,tandem 算法通过交换 pitch 估计和基于 pitch 的聚类进行语音分离 。
由两个或更多的麦克风组成的阵列使用不同的语音分离方法。波束成形,或者说空间滤波器,通过恰当的阵列结构增强从特定的方向到达的信号,进而削减来自其它方向的干扰 。最简单的波束成形是一种延迟-叠加技术,能将来自目标方向的多个麦克风的信号以相同的相位相加,并根据相差削减来自其它方向的信号。噪声的削减量取决于阵列的间隔、尺寸和结构,通常随着麦克风数量和阵列长度的增加,削减量也会增加。显然,当目标源和干扰源被共置,或者很靠近的时候,空间滤波器是无法应用的。此外,在回声场景中,波束成形的效用大幅降低,对声源方向的判定变得模糊不清。
一种最近提出的方法将语音分离当作一个监督学习问题。监督语音分离的最初形成受 CASA 中时频掩膜(time-frequency (T-F) masking)概念的启发。CASA 的主要目标是理想二值掩膜(ideal binary mask,IBM),表示目标信号是否控制混合信号时频表示中的一个 T-F 单元。听力研究显示,理想二值掩膜能够显著提高正常听力者(NH)和听力受损者(HI)在嘈杂环境中的语音理解能力。以 IBM 作为计算目标,则语音分离变成了二值分类问题,这正是监督学习的一种基本形式。在这种情况下,IBM 被当做训练中的目标信号或目标函数。在测试中,学习机器的目的就是估计 IBM,这也是监督语音分离的第一训练目标。
由于语音分离已经变成分类问题,因此数据驱动的方法在语音处理领域得到了广泛研究。在过去的十年内,通过运用大型训练数据和增加计算资源,监督语音分离大幅提高了最先进性能。监督分离从深度学习的发展中受益良多,这也是本文的主题。监督语音分离算法可以大体上分为以下几个部分:学习机器、训练目标和声学特征。本文,我们首先回顾这三个部分。然后介绍代表性算法,包括单声道方法和基于阵列的算法。泛化作为监督语音分离的特有议题,也将在本文中进行讨论。
为避免混淆,我们需要厘清本文使用的几个相关术语。speech separation 或 speech segregation(语音分离)都指从背景干扰(可能包括非语音噪声、干扰语音,或者都有,以及室内混响)中分离目标语音的任务。此外,「鸡尾酒会问题」(cocktail party problem)也指语音分离(speech separation)。语音增强或去噪(speech enhancement or denoising)指语音和非语音噪声的分离。如果是多个说话人的语音分离问题,我们使用术语「多说话人分离」(speaker separation)。
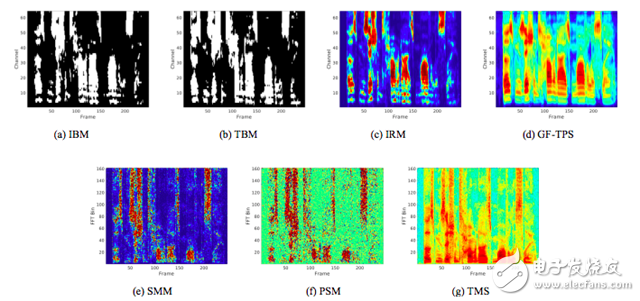
图 1. 对混合了 -5 dB SNR 工厂噪声的 TIMIT 音频数据使用不同训练目标图示。
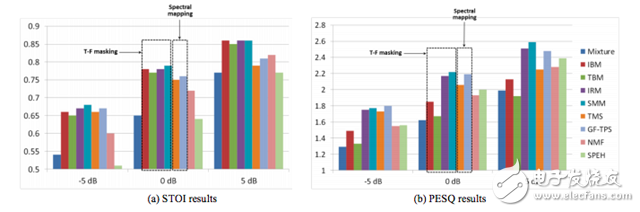
图 2. 使用不同训练目标的训练结果比较。(a)STOI。(b)PESQ。分别用清晰语音混合信噪比为-5dB、0dB、5dB 的工厂噪声。
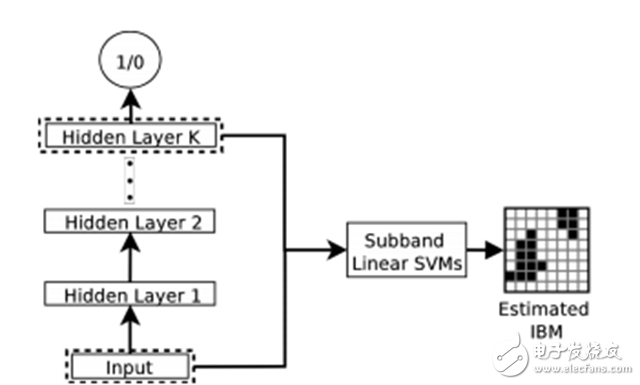
图 3. DNN 进行特征学习的图示,使用线性 SVM 对学得的特征进行 IBM 值估计 。

图 4. 用于语音分离的二阶 DNN(two-stage DNN)的图示 。
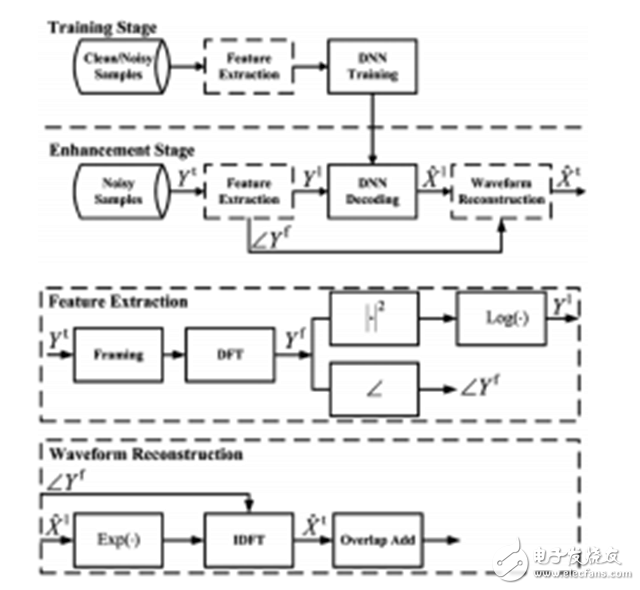
图 5. 语音增强中基于 DNN 的频谱映射方法图示 。
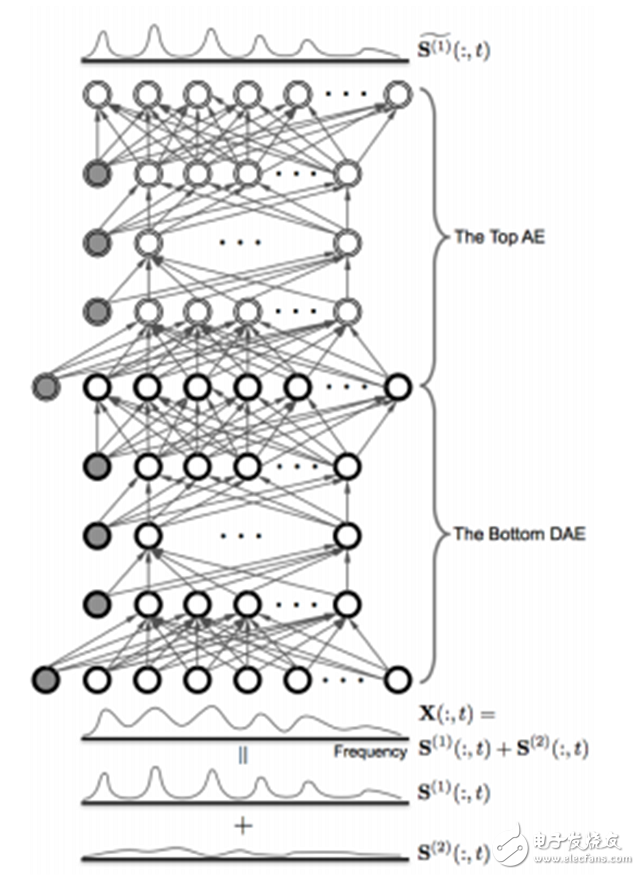
图 6. 配置自动编码器以进行无监督调试的语音增强 DNN 架构。AE 堆叠在 DNN 的顶部作为纯度检测器,估计来自 DNN 的清晰语音。
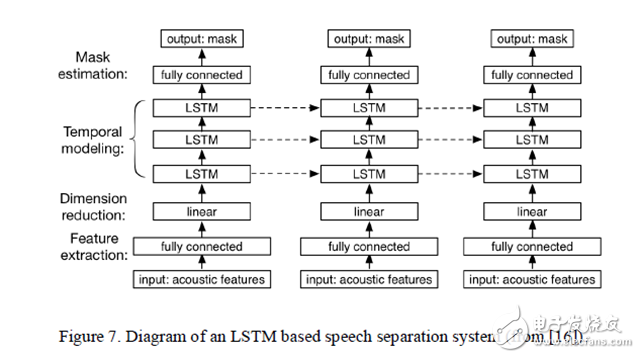
图 7. 基于 LSTM 的语音分离系统的结构展示 。
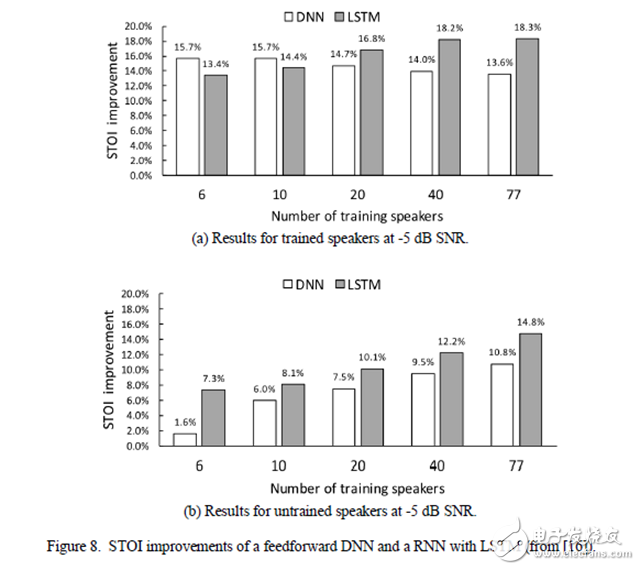
图 8. 前馈 DNN 和基于 LSTM 的 RNN 的 STOI 改进。(a)信噪比为-5dB 的经训练说话人的结果。(b)信噪比为-5dB 的未训练说话人的结果。
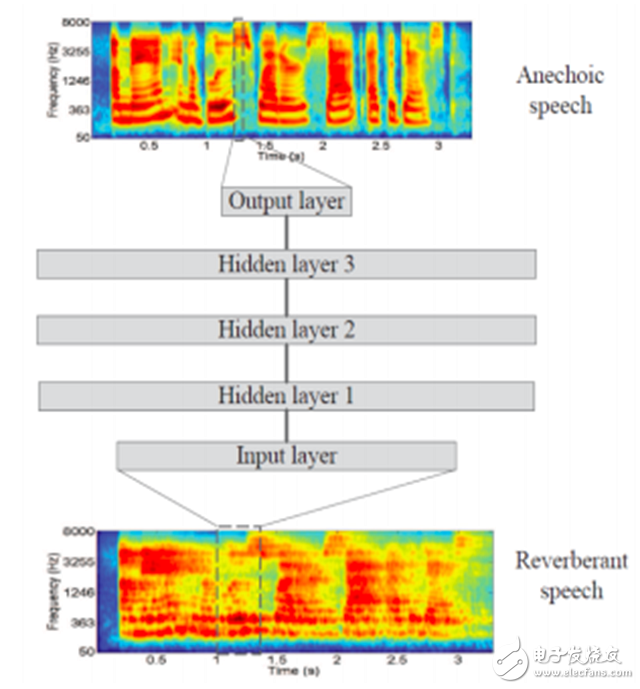
图 9. 基于频谱映射的语音混响削减 DNN 图示 [45]。
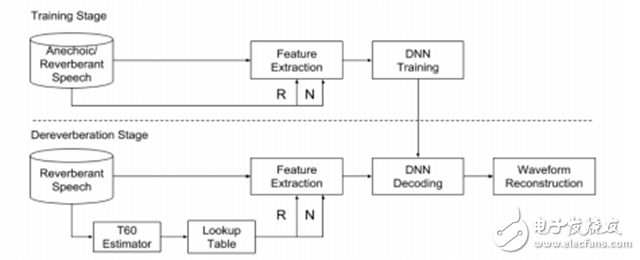
图 10. 语音混响削减的混响时间响应 DNN 结构图示 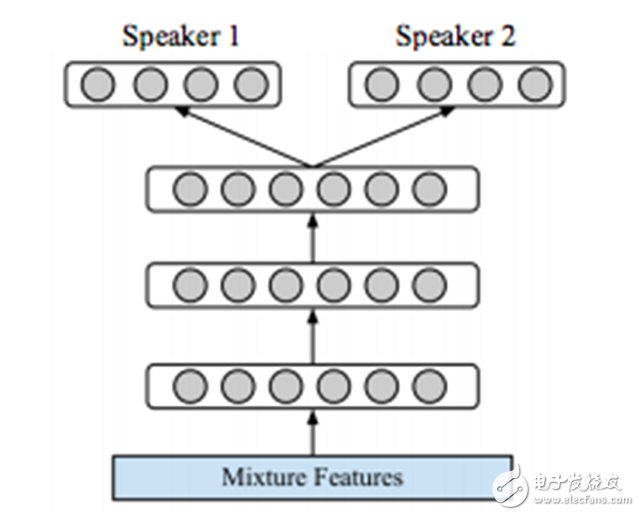
图 11. 基于 DNN 的两个说话人分离方法图示。
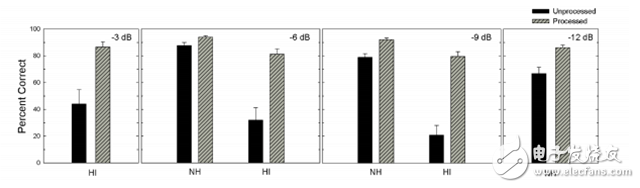
图 12. 听力正常者和听力受损者倾听混合干扰语句的目标语句并将目标语句从中分离出来时的平均清晰度得分和标准偏差 。图中展示了四种不同目标-干扰比率的正确率百分比结果。
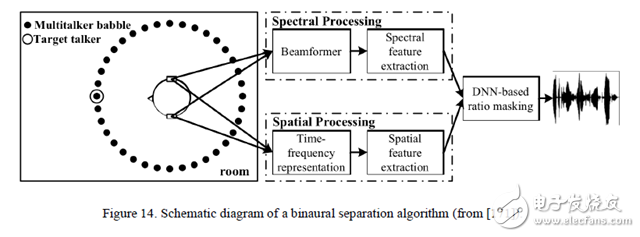
图 14. 双声道分离算法的结构图示。
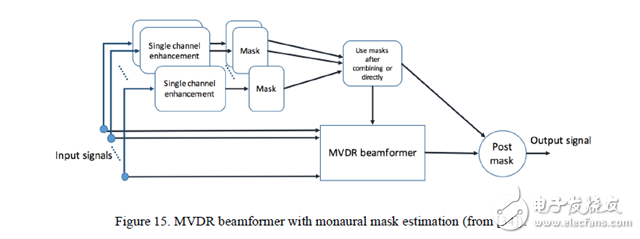
图 15. 单声道掩膜估计的 MVDR 波束成形器。
- 相关推荐
- 深度学习
-
基于labview的语音分析系统2013-05-11 0
-
求语音分离器详细参数2014-06-02 0
-
一文读懂语言识别技术原理12018-06-28 0
-
ADSL数据语音分离器电路原理资料推荐2021-05-07 0
-
一文读懂接口模块的组合应用有哪些?2021-05-17 0
-
一文读懂什么是NEC协议2021-10-15 0
-
ADSL数据语音分离器2012-04-06 4630
-
ADSL数据语音分离器,ADSL Voice separator2018-09-20 722
-
使用双麦克风进行室内语音分离与声源定位系统2018-12-20 1401
-
层叠与深度神经网络在语音分离中有什么样的应用2020-04-01 495
-
基于DSP的语音分析系统附录2021-04-26 540
-
基于生成对抗网络的语音信号分离方法2021-05-13 669
-
科大讯飞获国际多通道语音分离与识别大赛CHiME-7冠军2023-08-28 1180
-
基于深度学习的语音合成技术的进展与未来趋势2023-09-16 534
-
深度学习在语音识别中的应用及挑战2023-10-10 502
全部0条评论

快来发表一下你的评论吧 !
