

不可不知的机器学习之线性模型
人工智能
描述
本系列文章中,我想先介绍成功实施LTR背后的关键算法,从线性回归开始,逐步到梯度 boosting(不同种类的boosting算法一起)、RankSVM和随机森林等算法。
LTR首先是一个回归问题
对于本系列的文章,正如你在前一篇及文档中了解到的,我想把LTR映射为一个更加通用的问题:回归。回归问题需要训练一个模型,从而把一组数值特征映射到一个预测数值。
举个例子:你需要什么样的数据才能预测一家公司的利润?可能会有,手边的历史公共财务数据,包括雇员数量、股票价格、收益及现金流等。假设已知某些公司的数据,你的模型经过训练后用于预测这些变量(或其子集)的函数即利润。对于一家新公司,你可以使用这个函数来预测该公司的利润。
LTR同样是一个回归问题。你手头上有一系列评价数据,来衡量一个文档与某个查询的相关度等级。我们的相关度等级取值从A到F,更常见的情况是取值从0(完全不相关)到4(非常相关)。如果我们先考虑一个关键词搜索的查询,如下示例:

当构建一个模型来预测作为一个时间信号排序函数的等级时,LTR就成为一个回归问题。 相关度搜索中的召回,即我们所说的信号,表示查询和文档间关系的任意度量;更通用的名称叫做特征,但我个人更建议叫长期信号。原因之一是,信号是典型的独立于查询的——即该结果是通过度量某个关键词(或查询的某个部分)与文档的相关程度;某些是度量它们的关系。因此我们可以引入其他信号,包括查询特有的或者文档特有的,比如一篇文章的发表日期,或者一些从查询抽取出的实体(如“公司名称”)。
来看看上面的电影示例。你可能怀疑有2个依赖查询的信号能帮助预测相关度:
一个搜索关键词在标题属性中出现过多少次
一个搜索关键词在摘要属性中出现过多少次
扩展上面的评价,可能会得到如下CSV文件所示的回归训练集,把具体的信号值映射为等级:
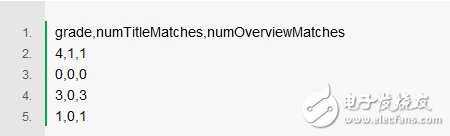
你可以像线性回归一样应用回归流程,从而通过其他列来预测第一列。也可以在已有的搜索引擎像Solr或Elasticsearch之上来构建这样一个系统。
我回避了一个复杂问题,那就是:如何获得这些评价?如何知道一个文档对一个查询来说是好还是坏?理解用户分析?专家人工分析?这通常是最难解决的——而且是跟特定领域非常相关的!提出假设数据来建立模型虽然挺好的,但纯属做无用功!
线性回归LTR
如果你学过一些统计学,可能已经很熟悉线性回归了。线性回归把回归问题定义为一个简单的线性函数。比如,在LTR中我们把上文的第一信号(一个搜索关键词在标题属性中出现过多少次)叫做t,第二信号(一个搜索关键词在摘要属性中出现过多少次)叫做o,我们的


模型能生成一个函数s,像下面这样对相关度来打分:
我们能评估出最佳拟合系数c0,c1,c2等,并使用最小二乘拟合的方法来预测我们的训练数据。这里就不赘述了,重点是我们能找到c0,c1,c2等来最小化实际等级g与预测值s(t,o)之间的误差。如果温习下线性代数,会发现这就像简单的矩阵数学。
使用线性回归你会更满意,包括决策确实是又一个排序信号,我们定义为t*o。或者另一个信号t2,实践中一般定义为t^2或者log(t),或者其他你认为有利于相关度预测的最佳公式。接下来只需要把这些值作为额外的列,用于线性回归学习系数。
任何模型的设计、测试和评估是一个更深的艺术,如果希望了解更多,强烈推荐统计学习概论。
使用sklearn实现线性回归LTR
为了更直观地体验,使用Python的sklearn类库来实现回归是一个便捷的方式。如果想使用上文数据通过线性回归尝试下简单的LTR训练集,可以把我们尝试的相关度等级预测值记为S,我们看到的信号将预测该得分并记为X。
我们将使用一些电影相关度数据尝试点有趣的事情。这里有一个搜索关键词“Rocky”的相关度等级数据集。召回我们上面的评判表,转换为一个训练集。一起来体验下真实的训练集(注释会帮助我们了解具体过程)。我们将检查的三个排序信号,包括标题的TF*IDF得分、简介的TF*IDF得分以及电影观众的评分。
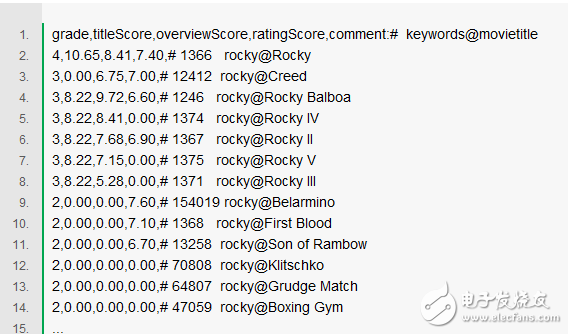
所以接下来直接来到代码的部分!下面的代码从一个CSV文件读取数据到一个numpy数组;该数组是二维的,第一维作为行,第二维作为列。在下面的注释中可以看到很新潮的数组切片是如何进行的:
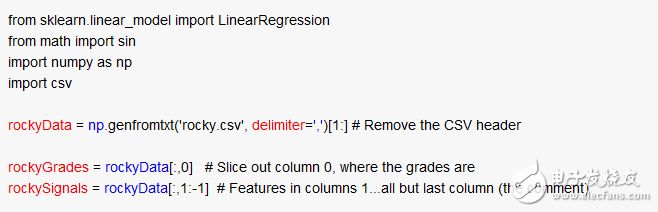
不错!我们已准备好进行一个简单线性回归了。这里我们使用一个经典的判断方法:方程比未知数多!因此我们需要使用常最小二乘法来估算特征rockySignals和等级rockyGrades间的关系。很简单,这就是numpy线性回归所做的:

漂亮!相关度解决了!(真的吗?)我们可以使用这些来建立一个排序函数。我们已经学习到了分别使用什么样的权重到标题和简介属性。
截至目前,我忽略了一部分事项,即我们需要考量如何评价模型和数据的匹配度。在本文的结尾,我们只是想看看一般情况下这些模型是如何工作。但不只是假设该模型非常适合训练集数据是个不错的想法,总是需要回退一些数据来测试的。接下来的博文会分别介绍这些话题。
使用模型对查询打分
我们通过这些系数可以建立自己的排序函数。做这些只是为了描述目的,sk-learn的线性回归带有预测方法,能评估作为输入的模型,但是构建我们自己的更有意思:

结果得分分别是Rambo 3.670以及First Blood 3.671。
非常接近!First Blood稍微高于Rambo一点儿获胜。原因是这样——Rambo是一个精确匹配,而First Blood是Rambo电影前传!因此我们不应该真的让模型如此可信,并没有那么多的例子达到那个水平。更有趣的是简介得分的系数比标题得分的系数大。所以至少在这个例子中我们的模型显示,简介中提到的关键字越多,最终的相关度往往越高。至此我们已经学习到一个不错的处理策略,用来解决用户眼里的相关度!
把这个模型加进来会更有意思,这很好理解,并且产生了很合理的结果;但是特征的直接线性组合通常会因为相关度应用而达不到预期。由于缺乏这样的理由,正如Flax的同行所言,直接加权boosting也达不到预期。
为什么?细节决定成败!
从前述例子中可以发现,一些非常相关的电影确实有很高的TF*IDF相关度得分,但是模型却倾向于概要字段与相关度更加密切。实际上何时标题匹配以及何时概要匹配还依赖于其他因素。
在很多问题中,相关度等级与标题和摘要属性的得分并不是一个简单的线性关系,而是与上下文有关。如果就想直接搜索一个标题,那么标题肯定会更加匹配;但是对于并不太确定想要搜索标题,还是类别,或者电影的演员,甚至其他属性的情形,就不太好办了。
换句话说,相关度问题看起来并非是一个纯粹的最优化问题:
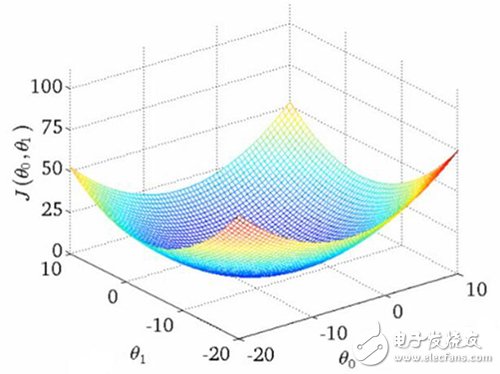
实践中的相关度要更加复杂。并没有一个神奇的最优解,宁可说很多局部最优依赖于很多其他因子的! 为什么呢?换句话说,相关度看起来如图所示:
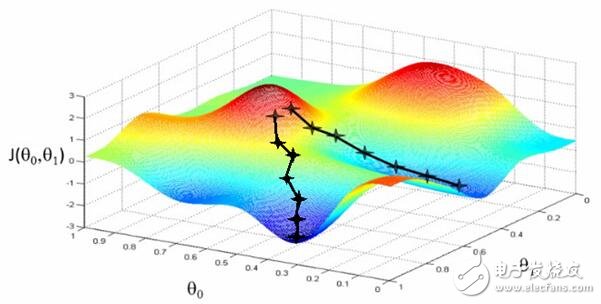
可以想象这些图(吴恩达机器学习课程中的干货)用于展示“相关度错误” —— 离我们正在学习的分数还有多远。两个θ变量的映射表示标题和摘要的相关度得分。第一张图中有一个单一的最优值,该处的“相关度错误”最小 —— 一个理想的权重设置应用这两个查询。第二个更加实际一些:波浪起伏、上下文相关的局部最小。有时与一个非常高的标题权重值有关,或者是一个非常低的标题权重!
-
MOSFET基础电路不可不知2022-05-10 2623
-
PCB板工艺不可不知的五大小原则2018-10-05 6932
-
电源常见的拓扑结构精华汇总工程师不可不知的电源11种拓扑结构2018-04-22 42160
-
微软Azure大放异彩 Azure术语不可不知2016-11-10 1634
-
写好LabVIEW程序不可不知的利器——汇总篇2014-11-20 6732
-
不可不知的ARM技术学习诀窍2012-08-20 18385
-
工程师不可不知的开关电源关键设计(五)2012-03-09 7198
-
工程师不可不知的开关电源关键设计(四)2012-02-28 14398
-
电脑木马识别的三个小命令(不可不知)2010-02-23 1461
-
不可不知的投影幕选购常识2010-02-10 967
-
显示卡不可不知15大参数2010-01-12 1299
-
手机使用常识及手机电池不可不知的小常识2009-11-23 2372
-
七则不可不知的电池常识2009-11-14 1163
全部0条评论

快来发表一下你的评论吧 !
