

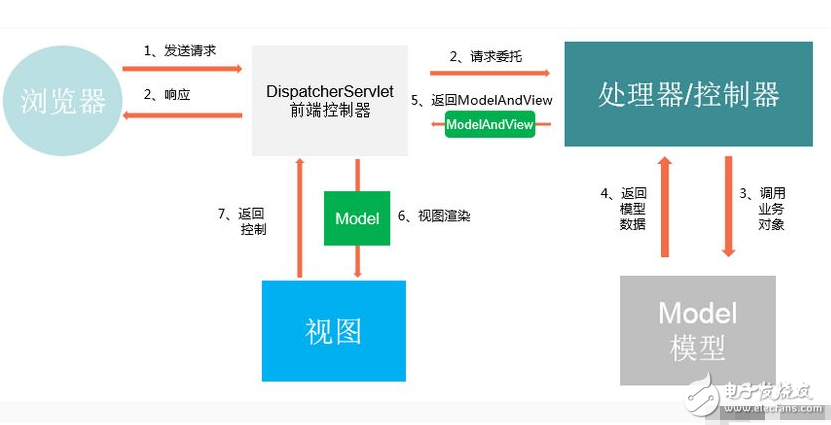
spring工作原理与机制
编程语言及工具
描述
Spring是一个开放源代码的设计层面框架,他解决的是业务逻辑层和其他各层的松耦合问题,因此它将面向接口的编程思想贯穿整个系统应用。Spring是于2003 年兴起的一个轻量级的Java 开发框架,由Rod Johnson创建。简单来说,Spring是一个分层的JavaSE/EEfull-stack(一站式) 轻量级开源框架。
spring特点
1.方便解耦,简化开发
通过Spring提供的IoC容器,我们可以将对象之间的依赖关系交由Spring进行控制,避免硬编码所造成的过度程序耦合。有了Spring,用户不必再为单实例模式类、属性文件解析等这些很底层的需求编写代码,可以更专注于上层的应用。
2.AOP编程的支持
通过Spring提供的AOP功能,方便进行面向切面的编程,许多不容易用传统OOP实现的功能可以通过AOP轻松应付。
3.声明式事务的支持
在Spring中,我们可以从单调烦闷的事务管理代码中解脱出来,通过声明式方式灵活地进行事务的管理,提高开发效率和质量。
4.方便程序的测试
可以用非容器依赖的编程方式进行几乎所有的测试工作,在Spring里,测试不再是昂贵的操作,而是随手可做的事情。例如:Spring对Junit4支持,可以通过注解方便的测试Spring程序。
5.方便集成各种优秀框架
Spring不排斥各种优秀的开源框架,相反,Spring可以降低各种框架的使用难度,Spring提供了对各种优秀框架(如Struts,Hibernate、Hessian、Quartz)等的直接支持。
6.降低Java EE API的使用难度
Spring对很多难用的Java EE API(如JDBC,JavaMail,远程调用等)提供了一个薄薄的封装层,通过Spring的简易封装,这些Java EE API的使用难度大为降低。
7.Java 源码是经典学习范例
Spring的源码设计精妙、结构清晰、匠心独运,处处体现着大师对Java设计模式灵活运用以及对Java技术的高深造诣。Spring框架源码无疑是Java技术的最佳实践范例。如果想在短时间内迅速提高自己的Java技术水平和应用开发水平,学习和研究Spring源码将会使你收到意想不到的效果。
spring原理机制
1,关于spring容器:
spring容器是Spring的核心,该 容器负责管理spring中的java组件,
ApplicationContext ctx = new ClassPathXmlApplicationContext(“bean.xml”);//这种方式实例化容器,容器会自动预初始化所有Bean实例
ctx.getBean(“beanName”);
ApplicationContext 实例正是Spring容器。
ApplicationContext容器默认会实例化所有的singleton Bean
Spring容器并不强制要求被管理组件是标准的javabean。
2,Spring的核心机制:依赖注入。
不管是依赖注入(Dependency Injection)还是控制反转(Inversion of Conctrol),其含义完全相同:
当某个java实例(调用者)需要调用另一个java实例(被调用者)时,传统情况下,通过调用者来创建被调用者的实例,通常通过new来创建,
而在依赖注入的模式下创建被调用者的工作不再由调用者来完成,因此称之为“控制反转”;创建被调用者实例的工作通常由Spring来完成,然后注入调用者,所以也称之为“依赖注入”。
3,依赖注入一般有2中方式:
设置注入:IoC容器使用属性的setter方式注入被依赖的实例。《property name=“” ref=“”》
构造注入:IoC容器使用构造器来注入被依赖的实例。《constructor-arg ref=“”》
配置构造注入的时候《constructor-arg》可以配置index属性,用于指定该构造参数值作为第几个构造参数值。下表从0开始。
4,Spring容器和被管理的bean:
Spring有两个核心接口:BeanFactory和ApplicationContext,其中ApplicationContext是BeanFactory的子接口。他们都可以代表Spring容器。
Spring容器是生成Bean实例的工厂,并管理Spring中的bean,bean是Spring中的基本单位,在基于Spring的java EE工程,所有的组件都被当成bean处理。
包括数据源、Hibernate的SessionFactory、事务管理器。
①Spring容器:Spring最基本的接口就是BeanFactory,
BeanFactory有很多实现类,通常使用XmlBeanFactory,但是对于大部分的javaEE应用而言,推荐使用ApplictionContext,它是BeanFactory的子接口,
ApplictionContext的实现类为FileSystemXmlApplicationContext和ClassPathXmlApplicationContext
FileSystemXmlApplicationContext:基于文件系统的XML配置文件创建ApplicationContext;
ClassPathXmlApplicationContext:基于类加载路径下的xml配置文件创建ApplicationContext。
②ApplicationContext的事件机制,
ApplicationContext事件机制是基于观察者设计模式实现的。通过ApplicationEvent类和ApplicationListener接口,
其中ApplicationEvent:容器事件,必须由ApplicationContext发布;
ApplicationListener:监听器,可有容器内的任何监听器Bean担任。
③容器中bean的作用域:
singleton:单例模式,在整个Spring IoC容器中,使用singleton定义的bean将只有一个实例;
prototype:原型模式,每次通过容器的getBean方法获取prototype定义的Bean时,都将产生一个新实例;
request:对于每次HTTP请求中,使用request定义的bean都将产生一个新实例,只有在web应用程序使用Spring时,该作用域才有效;
session:同理
global session:同理
注意:request和session作用域只在web应用中才生效,并且必须在web应用中增加额外的配置才会生效,为了让request,session两个作用域生效,必须将HTTP请求对象绑定到为该请求提供服务的线程上,这使得具有request和session作用域的Bean实例能够在后面的调用链中被访问。
当支持Servlet2.4及以上规范的web容器时,我们可以在web应用的web.xml增加如下Listener配置,该Listener负责为request作用域生效:
《listener》
《listener-class》org.springframework.web.context.request.RequestContextListener《/listener-class》
《/listener》
如果仅使用了支持Servlet2.4以前规范的web容器,则该容器不支持Listener规范,故无法使用这种配置,可以使用Filter配置方式,我们可以在web应用的web.xml增加如下Filter配置:
《filter》
《filter-name》requestContextFilter《/filter-name》
《filter-class》org.springframework.web.filter.RequestContextFilter《/filter-class》
《/filter》
《filter-mapping》
《filter-name》requestContextFilter《/filter-name》
《url-pattern》/*《/url-pattern》
《/filter-mapping》
再如下面的代码:
《bean id=“p” class=“lee.Person” scope=“request”/》
这样容器就会为每次HTTP请求生成一个lee.Person的实例当该请求响应结束时,该实例也随之消失。
如果Web应用直接使用Spring MVC作为MVC框架,即使用SpringDispatchServlet或DispatchPortlet来拦截所有用户请求,则无需这些额外的配置,因为SpringDispatchServlet或DispatchPortlet已经处理了所有和请求有关的状态处理。
④获取容器的引用:
通常情况下:
Bean无需访问Spring容器,而是通过Spring容器访问的,即使 需要手动访问Spring容器,程序也已通过类似下面的代码获取Spring容器 的引用。
ApllicationContext cts = ClassPathApplalicationContext(“bean.xml”);
但在一些极端的情况下,可能Bean需要访问Spring容器。Spring提供另一种方法访问Spring容器:
实现BeanFactoryAware接口的Bean,拥有访问Spring容器的能力,实现BeanFactoryAware的Bean被容器实例化后,会拥有一个引用指向创建他的BeanFactory。BeanFactoryAware只有一个方法setBeanFactory(BeanFactory beanFactory)该参数指向创建他的BeanFactory。
缺点:污染了代码,使代码与Spring接口耦合在一起,因此没有特别的必要,建议不要直接访问容器。
5,Bean实例的创建方式及对应配置:
创建Bean的方法:
①调用构造器创建Bean实例;
②调用静态工厂方法创建Bean;
③调用实例工厂创建Bean。
调用静态工厂方法创建Bean:
class属性是必须的,但此时的class并不是指定Bean实例的实现类而是静态工厂类。采用静态工厂类需要配置如下两个属性:
class静态工厂类的名字;
factory-method工厂方法(必须是静态的)。
如果静态工厂的方法有参数通过《constructor-arg/》元素知道。
调用实例工厂方法创建Bean:
使用实例工厂Bean时class属性无需指定,因Spring容器不会直接实例化该Bean,
创建Bean时需要如下属性:
factory-bean:该属性为工厂Bean的ID;
factory-method:该属性是定实例工厂的工厂方法。
6,入理解Spring容器中的Bean:
抽象Bean:
所有的抽象Bean,就是是定abstract属性为true的Bean,抽象Bean不能被实例化,抽象Bean的价值在于被继承
使用子Bean:
随着应用规模的增大,Spring配置文件的增长速度更快。当应用中的组件越来越多,,Spring中的Bean配置也随之大幅度增加。
就会出现一中现象:有一批配置Bean的信息完全相同,只有少量 的配置不同。怎么解决呢?
这时候就可以用Bean的继承来解决。
注意:子Bean无法从父Bean继承如下属性:
depends-on,aotuwirwe,dependency-check,singleton,scope,lazy-iniyt这些属性总是子Bean定义,或采用默认值。
通过 为一个《bean.。。/》 元素指定parent属性,即可指定该Bean是一个子Bean。
Bean继承与java中继承的区别:
Spring中的子bean和父Bean可以是不同类型,但java中的继承则可保证子类是一种特殊的父类;
Spring中的Bean的继承是实例之间的关系,因此只要表现在参数值的延续,而java中的继承是类之间的关系,主要表现为方法、属性之间的延续;
Spring中的子Bean不可以作为父Bean使用,不具备多态性,java中的子类完全可以当成父类使用。
Bean的生命周期:
①singleton与prototype的区别:
singleton:Spring可以精确的知道该Bean何时被创建、初始化、销毁。对于singleton作用域的Bean,每次客户端请求Spring容器总会返回一个共享的实例。
prototype:Spring容器仅仅负责创建Bean,当容器创建了Bean的实例后,Bean实例完全交给客户端代码管理,容器不在跟踪其生命周期。
每次客户端请求prototype作用域的Bean,都会为他创建一个新的实例,
②依赖关系注入后的行为:
Spring提供两种方法在Bean全部属性设置成功后执行特定的行为:
使用init-method属性;
该Bean实现InitializingBean接口
第一种方法:使用init-method属性指定某个方法在Bean全部属性依赖关系设置结束后自动执行。使用这种方法不需要将代码与Spring的接口耦合在一起,代码污染少;
第二种方法:实现Initializing接口,该接口有一个方法void afterPropertiesSet() throws Exception,虽然实现次接口一样可以在Bean全部属性设置成功后执行特定的行为,但是污染了代码,是侵入式设计,因此不推荐使用。
注意:如果即采用init-method属性指定初始化方法,又实现InitializingBean接口来指定初始化方法,先执行initializingBean接口中定义的方法,再执行init-method属性指定的方法。
③Bean销毁之前行为:
与定制初始化相似,Spring也提供两种方式定制Bean实例销毁之前的特定行为,如下:
使用destroy-method属性:
实现DisposableBean接口:
注意:如果即采用destroy-method属性指定销毁之前的方法,又实现DisposableBean接口来指定指定销毁之前的方法,与②类似。
④default-init-method与default-destroy-method属性,指定了所有的Bean都会执行此方法,而不是单个的Bean。
协调作用域不同步的Bean:
描述:
当Spring容器中作用域不同的Bean相互依赖时,可能出现一些问题:
当两个singleton作用域Bean存在依赖关系时,或当prototype作用依赖singleton作用域的Bean时,通过属性定义依赖关系即可。、
但是,当singleton作用域的Bean依赖prototype作用域Bean时,singleton作用域的Bean只有一次初始化的机会,他的依赖关系也只有在初始化阶段被设置,而他所依赖的prototype作用域的Bean则会不断的产生新的Bean实例。
解决方案:
第一种:部分放弃依赖注入:singleton作用域的Bean每次需要prototype作用域的Bean,则主动向容器请求新的Bean实例。
第二种:利用方法注入。
第一种方案肯定是不好的,代码主动请求新的Bean实例,必然会导致与Spring API耦合,造成代码严重污染。
通常情况下采用第二中方式。
方法注入通常使用lookup方法注入,利用lookup方法注入可以让Spring容器重写容器中Bean的抽象方法或具体方法,返回查找容器中的其他 Bean,被查找的Bean通常是non-singleton Bean(尽管也可以是singleton)。
如:public class SteelAxe implements Axe{
//每执行一次加一
private int count;
public String chop(){
return ++count;
}
}
public abstract class Chinese implements Perosom{
private Axe axe;
//定义一个抽象方法,该方法将由Spring负责实现
public abstract Axe createAxe();
public voidsetAxe(Axe axe){
this axe = axe;
}
public Axe getAxe(){
return axe;
}
}
在Spring配置文件中配置:
《bean id=“steelAxe” class=“。。.SteelAxe” scope=“prototype”》《/bean》
《bean id=“chinese” class=“。.Chinese” 》
《 lookup-mehtod name=“createAxe” bean=“steelAxe”》
《property name=“axe” ref=“steelAxe”/》
《/bean》
容器中的工厂Bean:
此处的工厂Bean与前面介绍的实例工厂方法创建Bean、静态工厂创建Bean有所区别:
前面的那些工厂是标准的工厂模式,Spring只是负责调用工厂方法来创建Bean实例;
此处工厂Bean是Spring的一种特殊Bean,这种工厂Bean必须实现FactoryBean接口。
FactoryBean接口是工厂Bean标准的工厂Bean的接口,实现该接口的Bean只能当工厂Bean使用,当我们将工厂Bean部署在容器中,并通过getBean()方法来获取工厂Bean,容器不会返回FactoryBean实例而是FactoryBean的产品。
FactoryBean提供了三个方法:
Object getObject();
Class getObjectType();
boolean isSingleton();
如:
public class PersonFactory implements FactoryBean{
Person p = null;
public Object getObject() throws Exception{
if(p==null){
p = new Chinense();
return p;
}
}
public Class getObjectType(){
return Chinese.class;
}
public boolean isSingleton(){
return true;
}
}
《!--配置一个FactoryBean,和普通的Bean一样--》
《bean id=“chinese” class=“”/》
public static void main(String args[]){
//以classpth下的bean.xml创建Reource对象
ClassPathResource re = new ClasspathResource(“bean.xml”);
//创建BeanFactory
XmlBeanFactory factory = new XmlBeanFactory(re);
Person p = (Person)factory.getBean(“chinese”);
//如需要获取FactoryBean本身则应该在bean id前加&
Person p = (Person)factory.getBean(“&chinese”);
}
对于初学者可能无法体会到工厂bean的作用,实际上,FactoryBean是Spring中非常有用的接口。例如:TransationProxyFactroyBean,这个工厂转为目标Bean创建事务代理。
7,深入理解依赖关系配置
组件与组件之间的耦合,采用依赖注入管理,但是普通的javabean属性值,应直接在代码里设置。
对于singleton作用域的bean,如果没有强制取消其预初始化行为,系统会在创建Spring容器时预初始化所有的singleton作用域的bean,与此同时,该bean依赖的bean也一起被实例化。
BeanFactory与ApplicationContext实例化容器中的bean的时机不同,前者等到程序需要Bean实例才创建Bean
后者会预初始化容器中的所有Bean。
因为采用ApplicationContext作为Spring的容器,创建容器时,会创建容器中所有singleton作用域的所有bean,因此可能需要更多的系统资源,但是一旦创建成功。应用后面的 响应速度会很快,因此,对于普通的javaEE而言 ,建议使用ApplicationContext作为Spring的容器。
Bean实例4中属性值的设置:
value;ref;bean;list、set、map、props
①设置普通属性值value,略;
②配置合作者Bean ref
可以为ref元素指定两个属性:bena、Local
bean:引用在不同一份XML配置文件中的其他Bean实例的ID属性值;
Local:引用同一份XML配置文件的其他Beanid属性值。
也可以不配置以上两个属性。
③组合属性名称:
public class A{
private Person p = new Person();
set/get.。。.
}
Spring配置文件
《bean id=“a” class=“A”》
《property name=“p.name” value=“aaa”/》
《/bean》
④注入嵌套Bean:
《bean id=“” class=“”》
《 property name=“”》
//属性为嵌套Bean 不能由Spring容器直接访问,因此没有id属性
《bean class=“。。.”/》
《/property》
《/bean》
⑤注入集合值:
《list》
《value》《/value》
《value》《/value》
《/list》
《map》
//每一个entry配置一个key-value对
《entry》
《key》
《value》。《/value》
《/key》
《value》《/value》
《/entry》
《/map》
《set》
《value》《/value》
《bean》《/bean》
《ref local=“”/》
《/set》
《props》
《prop key=“”》。。.。。《/prop》
《prop key=“”》。。.。。《/prop》
《/props》
⑥注入方法返回值:
public class ValueGenrator{
public int getValue(){
return 6;
}
public static int getStaticValue(){
return 9;
}
}
《bean id=“valueGenrator” class=“lee.ValueGenrator”/》
《bean id=“son1” class=“Son”》
《property name=“age”》
《bean class=“org.springframework.bean.factory.congfig.MethodInvokignFactoryBean”》
//配置非静态方法
《property name=“targetObject” ref=“valueGenrator”/》
//配置静态方法
《!--
《property name=“targetClass” value=“lee.ValueGenrator”/》
--》
《property name=“targetMehtod” value=“getStaticValue/》
《/property》
《/bean》
8,强制初始化Bean:
Spring有一个默认的规则,总是先初始化主调Bean,然后在初始化依赖Bean。
为了指定Bean在目标Bean之前初始化,可以使用depends-on属性
9,自动装配:
Spring能自动装配Bean与Bean之间的依赖关系,即使无需使用ref显式指定依赖Bean。
Spring的自动装配使用autowire属性指定,每一个《bean/》元素都可以指定autowire属性,也就是说在Spring容器中完全可以让某些Bean自动装配,而某些Bean不没使用自动装配。
自动装配可以减少配置文件的工作量,但是降低了依赖关系的透明性和依赖性。
使用autowire属性自动装配,autowire属性可以接受如下几个值 :
no:不使用自动装配。这是默认配置。
byName:根据属性自动装配,BeanFactory会查找容器中所有的Bean,找出id属性与属性名同名的Bean来完成注入。如果没有找到匹配的Bean,Spring则不会进行任何注入。
byType:根据属性类型自动装配,BeanFactroy会查找容器中所有的 Bean,如果一个正好与依赖属性类型相同的Bean,就会自动注入这个属性。
如果有多个这样的Bean则会抛出异常。如果没有这样 的Bean则什么也不会发生,属性不会被设置。
constructor:与byType类似,区别是用于构造注入的参数,如果BeanFactory中不是恰好有一个Bean与构造器参数类型相同。则会抛出异常。
autodetect:BeanFactory会根据Bean内部的结构,决定使用constructor或byType,如果找到一个缺省的构造器,就会应用byType。
注意:对于大型的应用而言,不鼓励使用自动装配,
10,依赖检查:
Spring提供一种依赖检查的功能,可以防止出现配置手误,或者其他情况的错误。
使用依赖检查可以让系统判断配置文件的依赖关系注入是否完全有效。
使用依赖检查,可以保证Bean的属性得到了正确的设置,有时候,某个Bean的特定属性并不需要设置值,或者某些属性已有默认值,此时采用依赖检查就会出现错误,该Bean就不应该采用依赖检查,幸好Spring可以为不同的Bean单独指定依赖检查的行为,Spring提供dependency-chech属性来配置依赖检查,当然也可以指定不同的检查依赖策略。
该属性有如下值:
none:不进行依赖检查,没有指定值的Bean属性仅仅是没有设置值,这是默认值。
simple:对基本类型和集合(除了合作者Bean)进行依赖检查。
objects:仅对合作者Bean进行依赖检查。
all:对合作者Bean、基本数据类型全部进行依赖检查。
public class Chinese implements Person{
private Axe axe;
private int age = 30;
//implements method
public void setAge(int age){
this.age = age;
}
public int getAge(){
return age
}
}
《bean id=”axe“ class=”StoneAxe“/》
《bean id=”chinese“ class=”Chinese“ dependency-check=”all“》
《property name=”axe“ ref=”axe“/》
《/bean》
以上程序将会抛出异常,虽然Chinese类的age属性已经有了默认值,但配置dependency-check=”all“则要求配置文件为所有的属性都提供正确的值。
而age属性没有提供值。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
二:深入Spring:
1,利用后处理器扩展Spring容器:
Spring容器提供了很好的扩展性,除了可以与各种第三方框架良好的整合外,其IoC容器也允许开发者进行扩展,这种扩展甚至无需实现BeanFactory或ApplicationContext接口,允许两个后处理器对IoC容器进行扩展:
Bean后处理器:这种处理器会对容器中的Bean进行后处理,对Bean的功能进行额外的加强。
容器后处理器:这种处理器对IoC容器进行后处理,用于增强容器的功能。
①Bean后处理器:
Bean后处理器是一种特殊的Bean,这种特殊的Bean并不对外提供服务,它甚至可以没有id属性。它主要负责对容器中的其他Bean执行后处理。
后处理器必须实现BeanPostProcessor接口。此接口有两个方法:Object postProcessorBeforeInitialization(Object object,String name) Object postProcessorAfterInitialization(Object object,String name)
第一个参数是系统即将后处理的Bean的实例,第二个参数是该Bean实例的名称。
public class MyBeanPostProcessor implements BeanPostProcessor{
public Object postProcessorBeforeInitialization(Object object,String name) throws Beanexception{
System.out.println(”后处理器在初始化之前对“+”name“+”进行增强处理“);
return object;
}
public Object postProcessorAfterInitialization(Object object,String name) throws Beanexception{
System.out.println(”后处理器在初始化之后对“+”name“+”进行增强处理“);
if(object intanceof Chinese ){
Chinese c = (Chinese)bean;
bean.setName=”张三“;
}
return object;
}
}
public class Chinese implements Person{
private Axe axe;
private String name;
public void setName(String name){
System.out.println(”Spring执行注入。。.。。.。“);
this.name=name;
}
//set/get.。。.
public void init(){
System.out.println(”初始化工作init“);
}
。。.。。.。。.。。.。。.。。.。。.。。.。。.。。.。
}
《bean id=”steelAxe“ class=”。。.“/》
《bean id=”chinese“ class=”Chinese“》
《property name=”axe“ ref=”steelAxe“/》
《prperty name=”name“ value=”李四“/》
《/bean》
《!--配置后处理器--》
《bean id=”beanPostProcessor“ class=”MyBeanPostProcessor“/》
public static void mian(String args[]){
ClassPathResource rs = new ClasspathReource(bean.xml);
XmlBeanFactory factory = new XmlBeanfactory(rs);
MyBeanPostProcessor processor = (MyBeanPostProcessor)factory.getBean(”beanPostProcessor“)
//注册BeanPostProcessor
factory.addPostProcessor(processor )
Person p = (Person)factory.getBean(”chinese“);
p.useAxe();
}
程序输出name属性时,不会输出李四,而是张三,虽然注入的值是李四,但是Bean后处理器发生作用。
输出:
---------------------------------------------------------------
Spring执行注入依赖关系。。.。。.
后处理器在初始化之前对chinese进行增强处理
初始化工作init
后处理器在初始化之后对chinese进行增强处理
张三
----------------------------------------------------------------
如果使用BeanFactory作为Spring的容器。则必须手动注册Bean后处理器,容器中一旦注册了Bean后处理器,Bean后处理器就会自动启动,在容器中每个Bean创建时自动工作。
实现BeanPostProcessor接口的Bean后处理器可以对Bean进行任何操作,包括完全忽略这个回调,BeanPostProcessor通常用来检查标记接口,或者做将Bean包装成一个Proxy的事情。
如果不采用BeanFactory作为Spring的容器,采用ApplicationContext作为容器,则无需手动注册Bean后处理器,ApplicationContext可自动检测到容器中的Bean后处理器,自动注册。Bean后处理器会在创建Bean时自动启动。对于后处理器而言,ApplicationContext作为Spring容器更为方便。
②容器后处理器:
除了上面的提供的Bean后处理器外,Spring还提供了一种容器后处理器,,Bean后处理器负责容器中所有Bean实例的,而容器后处理器负责处理容器本身。
容器后处理器必须要实现BeanFactoryPostProcessor接口。
类似于Bean后处理器,采用ApplicationContext作为容器,则无需手动注册容器后处理器。如果使用BeanFactory作为Spring的容器。则必须手动注册容器后处理器。
2,Spring的“零配置”支持
①搜索Bean类
Spring提供如下几个Annotation来标注Spring Bean:
@Component标注一个普通的Spring Bean;
@Controller:标注一个控制器组件类;
@Service:标注一个业务逻辑组件类;
@Repository:标注一个Dao组件;
《context:component-scan base-package=”“/》
在默认的情况下,自动搜索所有以@Component、@Controller、@Service、@Repository注释的java类,当作Spring Bean处理。
还可以通过《context:component-scan base-package=”“/》子元素《include-filter》/《exclude-filter》
②指定Bean的作用域:
如:
@Scope(”prototype“)
@Component(”axe“)
public class SteelAxe implements Axe{
}
③使用@Resource配置依赖:
@Resource有一个name属性,在默认的情况下,Spring将这个值 解释为需要被注入的Bean的实例的名字,换句话说,使用@Resource与《property.。/》元素的ref属性具有相同的效果。
当使用@Resource修饰setter方法,如果省略name属性,则name属性默认是从该setter方法去掉set子串,首字母小写的到的子串。
当使用@Resource修饰Field时,如果mame,则默认与Field的相同。
④自动装配和精确装配:
Spring提供@Autowired来指定自动装配,使用@Autowired可以标志setter方法、普通方法、和构造器。如:
@Component
public class Chinese implements Person{
@Autowired
private Aex axe;
@Autowired
public Chinese(Axe axe){
this.axe = axe
}
@Autowired
private Axe [] axes;
}
当@Autowired标注Field时Spring会把容器中的与该Field类型匹配的Bean注入该属性,
如果Spring容器中有多个同类型的Bean与Field类型匹配,则会出现异常。
当@Autowired标注数组类时,在这种情况,Spring会自动搜索Spring容器中所有与数组类型相匹配的类型的Bean,并把这些Bean当作数组的元素来创建数组。
当@Autowired标注集合时,和标注数组类似,当时必须使用泛型。
⑤使用@Qualifier精确装配
正如上面的@Autowired总是采用byType的自动装配策略。在这种情况下,符合自动和装配的类型的Bean常常有多个这个时候就会引发异常了。
为了实现精确的配置,Spring提供@Qualifier,可以根据Bean标识来指定自动装配,
--- @Qualifier可以标注Field,如:
@Component
public class Chinese implements Person{
@Autowired
@Qualifier(”steelAxe“)
private Aex axe;
}
--- @Qualifier还可以标注方法的形参,如:
@Component
public class Chinese implements Person{
@Autowired
private Aex axe;
public void setAxe(@Qualifier(”steelAxe“) Axe axe )
this.axe=axe;
}
}
3,资源访问:
4,Spring的AOP:
①AspectJ
②AOP的基本概念:
AOP框架不与特定的代码耦合。下面是一些面向切面编程的术语:
切面(Aspect):业务流程运行到某个特定的步骤,也就是一个应用运行的关注点,关注点可能横切多个对象,所以常常也被称为横切关注点。
连接点(Joinpoint):程序执行过程明确的点,如方法的调用、异常的抛出,Spring AOP中连接点总是方法的调用。
增强处理(Advice):AOP框架在特定的切入点执行的增强处理,处理有around、before和After等类型。
切入点(Pointcut):可以插入增强处理的连接点,简而言之,当某个连接点满足指定要求时,该连接点将被添加增强处理,该连接点也就变成了切入点,
例如一下代码:
pointcut xxxPointcut(){
:execution(void H*.say*());
}
每个方法的调用都只是连接点,但如果该方法属于H开头的类,且方法名以say开头,按照方法的执行将变成切入点。
引入:将方法添加到被处理的类中,Spring允许引入新的接口到任何被处理的对象。例如:你可以使用一个引用,使任何对象实现IsModified接口,以此简化缓存。
目标对象:被AOP增强处理的对象,也被称为被增强的对象,如果AOP框架是通过运行时代理来实现的,那么这个对象将是一个被代理的对象。
AOP代理:AOP框架创建的 对象,简单的说,代理就是对目标对象的加强,Spring的AOP代理可以使JDK动态代理,也可以是CGLIB代理,前者为实现接口的目标对象的代理后者为不实现接口的目标对象的代理。
织入(Weaving):将增强处理增加到目标对象中,并创建一个被增强的对象(AOP代理)的过程就是织入。织入有两种实现方式:编译时增强(例如AspectJ)和运行时增强(例如CGLIB)
目前Spring只支持将方法调用作为连接点,如果需要把Field的访问和更新也作为增强处理的连接点,可以使用AspectJ。
一旦我们掌握了上面的AOP的相关概念,不难发现进行AOP的编程其实是一件很简单的事情,纵观AOP编程需要程序员参与的只有3个部分:
定义普通业务组件;
定义切入点,一个切入点横切多个业务组件;
定义增强处理,增强处理就是现在AOP框架为普通业务组件织入的处理动作。
③AOP,基于Annotation的零配置方式:
定义Before增强处理:
当我们在一个切面类里使用@Before来标注一个方法时,该方法将作为Before增强处理,使用@Before标注时通常要指定一个value属性值,用来指定一个切入点表达式(既可以是一个已有的切入点,也可以直接定义切入点表达式),用于指定该增强处理将被织入那些切入点。
注意:(”execution(* cn.huaxia.spring.*.*(。。))“)第一个星号后面一定要有一个空格。
//定义一个切面
@Aspect
publicclass BeforeAdviceTest {
// 执行cn.huaxia.spring包下的所有方法都做为切入点
@Before(”execution(* cn.huaxia.spring.*.*(。。))“)
publicvoid authority() {
System.out.println(”模拟执行权限检查。。.“);
}
}
上面@Aspect@标注BeforeAdviceTest 表明该类是一个切面类,在该切面里定义了一个authority()方法,这个方法本来没有什么特别之处,但是因为使用@Before来标注该方法,这就将该方法转换成一个增强处理。上面程序中使用@Before Annotation标注时,直接指定切入点表达式,指定cn.huaxia.spring下的所有方法都作为切入点。
@Component
publicclass Chineseimplements Person {
@Override
public String sayHello(String word) {
return word;
}
publicvoid eat(String food) {
System.out.println(”我正在吃“ + food);
}
}
从上面Chinese类的代码来看,他是一个如此纯净的Java类,他丝毫不知将被谁来进行增强处理,也不知道将被怎样增强处理---正式这种无知才是”AOP“最大的魅力:目标类可以被无限增强。
在Spring配置文件中配置自动搜索Bean组件,配置自动搜索切面类,Spring AOP自动对Bean组件进行增强。配置文件如下:
《?xmlversion=”1.0“encoding=”UTF-8“?》
《beansxmlns=”http://www.springframework.org/schema/beans“
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance“xmlns:aop=”http://www.springframework.org/schema/aop“
xmlns:tx=”http://www.springframework.org/schema/tx“xmlns:context=”http://www.springframework.org/schema/context“
xsi:schemaLocation=”http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd“》
《!-- 指定自定搜索Bean组件、自动搜索切面类--》
《context:component-scanbase-package=”cn.huaxia.spring“》
《context:include-filtertype=”annotation“
expression=”org.aspectj.lang.annotation.Aspect“/》
《/context:component-scan》
《!-- 启动AspectJ支持--》
《aop:aspectj-autoproxy/》
《/beans》
编写Junit类:
publicclass TestBefore {
static ApplicationContextac =null;
@BeforeClass
publicstaticvoid setUpBeforeClass() throws Exception {
ac =new ClassPathXmlApplicationContext(”beans.xml“);
}
@Test
publicvoid testBefore() {
//Chinese c = (Chinese)ac.getBean(”chinese“);//会出错,不能转换为Chinese
Person c = (Person)ac.getBean(”chinese“);
c.eat(”西瓜“);
System.out.println(c.sayHello(”你好--Before“));
}
}
定义AfterReturning增强处理:
AfterReturning增强处理在目标方法正常完成之后织入。
类似于使用@Before Annotation可标注Before增强处理,使用@AfterReturning Annation来标注@AfterRetuning增强处理。
使用@AfterReturning Annotation可以指定如下属性:
pointcut/value:这两个属性的作用是一样的,他们都是指定该切入点对应的切入表达式,当指定pointcut属性,value属性值将会被覆盖。
returning:指定一个返回值形参,增强处理的方法可以通过该形参名来访问目标方法的返回值。
@Aspect
publicclass AfterReturningAdviceTest {
@AfterReturning(pointcut=”execution(* cn.huaxia.spring.*.*(。。))“,returning=”obj“)
publicvoid log(Object obj){
System.out.println(”获取目标方法返回值“+obj);
System.out.println(”模拟日志记录功能。。.。“);
}
}
如果log有参数,returning属性一定要配置。如果参数不止一个,那么目标方法将不会执行必须要配置args表达式。
注意:使用returning属性还有另一个额外的作用:它可以限定切入点只匹配具有对应返回类型的方法。加入上面的log的参数是String类型,则该切入点只匹配cn.huaxia.spring包下的返回值类型为String的所有方法。虽然AfterReturning增强处理可以访问到目标方法的返回值,但不可以改变目标方法返回值。
定义AfterThrowing增强处理:
AfterThrowing增强处理主要用于程序中未处理的异常。
使用@AfterThrowing Annotation时可以指定如下两个属性:
pointcut/value
throwing:指定一个返回值形参名,增强处理定义的方法可以通过该形参名来访问目标方法中所抛出的异常对象。
@Aspect
publicclass AfterThrowingAdviceTest {
@AfterThrowing(pointcut =”execution(* cn.huaxia.spring.*.*(。。))“, throwing =”th“)
publicvoid doRecoveryActions(Throwable th) {
System.out.println(”目标方法中抛出的异常“ + th);
System.out.println(”模拟抛出异常的增强处理/。。.。。“);
}
}
@Component
publicclass Chineseimplements Person {
@Override
publicString sayHello(String word) {
try {
System.out.println(”sayHello方法开始执行。。.“);
new FileInputStream(”a.txt“);
}catch (FileNotFoundException e) {
e.printStackTrace();
}
return word;
}
publicvoid eat(String food) {
System.out.println(”我正在吃“ + food);
}
publicvoid divide(){
int a = 5/0;
System.out.println(”divide执行完毕/“+a);
}
}
//Chinese c = (Chinese)ac.getBean(”chinese“);//会出错,不能转换为Chinese
Person c = (Person)ac.getBean(”chinese“);
System.out.println(c.sayHello(”你好--Before“));
c.eat(”西瓜“);
c.divide();
}
输出的结果:
上面的程序的sayHello和divided两个方法都会抛出异常,但是sayHello方法中的异常将由该方法显示捕捉,所以Spring AOP不会处理该异常。
而divide方法将抛出算术异常,且该异常没有被任何程序所处理,故Spring AOP会对该异常进行处理。
使用throwing属性还有另一个作用:它可以用于限定切入点只匹配指定类型的异常。类似AfterRetuning的returning 属性。
Spring AOP的AfterThrowing处理虽然可以对目标方法的异常进行处理,但是这种处理与直接使用catch捕捉是不同的:
catch意味完全处理该异常,如果catch没有重新抛出一次异常,则方法可以正常结束,而AfterThrowing处理虽然处理了异常,但它不能完全处理异常,该异常依然会传播到上一级调用者。
定义After增强处理:
After增强处理与AfterReturning增强处理有点相似,但是也有不同:
AfterRetuning只在目标方法成功完成后才被织入。
After增强处理不管目标方法如何结束,都会被织入。
因为一个方法不管是如何结束,After增强处理它都会被织入,因此After增强处理必须处理正常返回和异常返回两种情况,这种增强处理通常用于资源释放。
使用@After Annotation标注一个方法,即可将该方法转成After增强处理,使用@After Annotation增强处理需要指定一个value属性,该属性值用于指定该增强处理被织入的切入点,既可以是一个已有的切入点也可以直接指定切入点表达式。
@Aspect
publicclass AfterAdviceTest {
@After(”execution(* cn.huaxia.spring.*.*(。。))“)
publicvoid release(){
System.out.println(”模拟方法结束后资源释放。。.。“);
}
}
结果:
从上面的输出结果可以看出,After增强处理非常类似于异常处理中的finally块的作用-----无论结果如何,它总在方法执行结束之后被织入,因此特别适合进行资源回收。
Around增强处理:
@Around Annotation用于标注Around的增强处理,Around的增强处理是比较强的增强处理,它近似等于Before和AfterRetuning增强处理的总和,Around增强处理既可以在目标方法之前执行,也可以在执行目标方法之后织入增强动作。
与Before增强处理和AfterReturning增强处理不同的是Around增强处理可以决定目标方法执行在什么时候执行,如何执行,甚至可以阻止目标方法执行。Around增强处理可以改变执行目标方法的参数值,还可以改变执行目标方法之后的返回值。
使用@Around Annotation时需要指定value属性,该属性用来指定该增强处理被织入的切入点。
当定义一个Around增强处理方法时,该方法的第一个形参必须是ProceedingJoinPoint类型(至少包含一个形参)。
在增强处理方法体内,调用ProceedingJoinPoint的process方法时,还可以传入一个Object[]对象,该数组中的值将被传入目标方法作为执行方法的的实参。
-------这就是Around增强处理可以完全控制目标方法执行时机、如何执行的关键。如果程序没有调用ProceedingJoinPoint的proceed方法则目标方法不会执行。
@Aspect
publicclass AroundAdviceTest {
@Around(”execution(* cn.huaxia.spring.*.*(。。))“)
public Object proceedTX(ProceedingJoinPoint pre)throws Throwable {
System.out.println(”开始事务。。.。。“);
Object obj = pre.proceed(new String[] {”被修改的参数“ });
System.out.println(”结束事务。。.。。“);
return obj +”,新增的内容“;
}
}
结果:
当调用ProceedingJoinPonint的proceed方法时,传入的Object[]参数值将作为目标方法的参数,如果传入的Object[]参数的长度和目标方法参数个数不匹配,或者Object[]数组元素与目标方法所需的参数不匹配,程序就会抛出异常。
为了能获取目标方法参数的个数和类型,这就需要增强处理方法能够访问执行目标方法的参数了。
访问目标方法的参数:
访问目标方法最简单的的做法是定义增强处理方法时将第一个参数定义为JoinPoint类型,当增强处理方法被调用时,该JoinPoint参数就代表了织入增强处理的连接点,JoinPoint包含如下几个常用的方法:
Object[] getArgs():返回执行目标方法的参数;
Signature getSignature():返回被增强的方法的相关信息;
Object getTarget():返回被织入增强处理的目标方法;
Object getThis():返回AOP框架为目标对象生成的代理对象。如:
package cn.huaxia.spring;
import java.util.Arrays;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.AfterReturning;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
@Aspect
public class FourAdviceTest {
@Around(”execution(* cn.huaxia.spring.service.*.*(。。))“)
public Object proceedTX(ProceedingJoinPoint pre) throws Throwable {
System.out.println(”Around增强处理:执行目标方法前,执行模拟开启事务。。.。。.。“);
Object[] objs = pre.getArgs();
if (objs != null && objs.length 》 0
&& objs[0].getClass() == String.class) {
objs[0] = ”被修改的参数“;
}
Object obj = pre.proceed(objs);
System.out.println(”Around增强处理:执行目标方法之后,模拟结束事务。。.。。“);
return obj + ”,新增加的内容“;
}
@Before(”execution(* cn.huaxia.spring.service.*.*(。。))“)
public void authority(JoinPoint jp) {
System.out.println(”Before增强:模拟权限检查“);
System.out.println(”Before增强:被织入增强处理的目标方法:“
+ jp.getSignature().getName());
System.out
.println(”Before增强:目标方法的参数为:“ + Arrays.toString(jp.getArgs()));
System.out.println(”Before增强:被注入增强的处理 的目标对象:“ + jp.getTarget());
}
@AfterReturning(pointcut=”execution(* cn.huaxia.spring.service.*.*(。。))“,returning=”obj“)
public void log(JoinPoint jp, Object obj) {
System.out.println(”AfterReturning增强:获取目标方法的返回值:“ + obj);
System.out.println(”AfterReturning增强:模拟日志记录功能。。.。。“);
System.out.println(”AfterReturning增强:被织入增强处理的目标方法:“
+ jp.getSignature().getName());
System.out.println(”AfterReturning增强:目标方法的参数为:“
+ Arrays.toString(jp.getArgs()));
System.out.println(”AfterReturning增强:被注入增强的处理 的目标对象:“ + jp.getTarget());
}
@After(”execution(* cn.huaxia.spring.service.*.*(。。))“)
public void release(JoinPoint jp) {
System.out.println(”After增强:模拟方法结束后,资源释放。。.。。“);
System.out.println(”After增强:被织入增强处理的目标方法:“
+ jp.getSignature().getName());
System.out.println(”After增强:目标方法的参数为:“ + Arrays.toString(jp.getArgs()));
System.out.println(”After增强:被注入增强的处理 的目标对象:“ + jp.getTarget());
}
}
输出结果:
Around增强处理:执行目标方法之后,模拟结束事务。。.。。
AfterReturning增强:获取目标方法的返回值:被修改的参数,新增加的内容
AfterReturning增强:模拟日志记录功能。。.。。
AfterReturning增强:被织入增强处理的目标方法:sayHello
AfterReturning增强:目标方法的参数为:[被修改的参数]
AfterReturning增强:被注入增强的处理的目标对象:cn.huaxia.spring.service.Chinese2@941db6
After增强:模拟方法结束后,资源释放。。.。。
After增强:被织入增强处理的目标方法:sayHello
After增强:目标方法的参数为:[被修改的参数]
After增强:被注入增强的处理的目标对象:cn.huaxia.spring.service.Chinese2@941db6
被修改的参数,新增加的内容
Around增强处理:执行目标方法前,执行模拟开启事务。。.。。.。
Before增强:模拟权限检查
Before增强:被织入增强处理的目标方法:eat
Before增强:目标方法的参数为:[被修改的参数]
Before增强:被注入增强的处理的目标对象:cn.huaxia.spring.service.Chinese2@941db6
我正在吃:被修改的参数
Around增强处理:执行目标方法之后,模拟结束事务。。.。。
AfterReturning增强:获取目标方法的返回值:null,新增加的内容
AfterReturning增强:模拟日志记录功能。。.。。
AfterReturning增强:被织入增强处理的目标方法:eat
AfterReturning增强:目标方法的参数为:[被修改的参数]
AfterReturning增强:被注入增强的处理的目标对象:cn.huaxia.spring.service.Chinese2@941db6
After增强:模拟方法结束后,资源释放。。.。。
After增强:被织入增强处理的目标方法:eat
After增强:目标方法的参数为:[被修改的参数]
After增强:被注入增强的处理的目标对象:cn.huaxia.spring.service.Chinese2@941db6
Around增强处理:执行目标方法前,执行模拟开启事务。。.。。.。
Before增强:模拟权限检查
Before增强:被织入增强处理的目标方法:divide
Before增强:目标方法的参数为:[]
Before增强:被注入增强的处理的目标对象:cn.huaxia.spring.service.Chinese2@941db6
After增强:模拟方法结束后,资源释放。。.。。
After增强:被织入增强处理的目标方法:divide
After增强:目标方法的参数为:[]
After增强:被注入增强的处理的目标对象:cn.huaxia.spring.service.Chinese2@941db6
Spring AOP采用和AsoectJ一样的优先顺序来织入增强:在”进入“连接点时,最高等级的增强处理将先织入(所以给定两个Before增强处理中,优先级高的那个会执行),在”退出“连接点时,最高优先等级的增强处理将会最后织入。
4个增强处理的优先等级如下(从低到高):
Before增强处理-------------》Around增强处理-------------》AfterReturning增强处理-------------》After增强处理
当两个不同的两个增强处理需要在同一个连接点被织入时,Spring AOP将以随机的顺序来织入这两个增强处理,如果应用需要指定不同切面里增强处理的优先级,Spring提供了两个解决方案:
让切面类实现org.springframework.core.Ordered接口,实现该接口提供的 int getOrder()方法,方法返回值越小,则优先级越高。
直接使用@Order Annotation 来标注一个切面类,使用@Order Annotation时可以指定一个int 型的value属性,该属性值越小,优先等级越高。
当相同的切面里的两个增强处理需要在相同的连接点被织入时,Spring AOP将以随机的方式来织入这两个增强处理,没有办法指定他们的顺序,如果一定要它们以特定的顺序被织入,则可以考虑把它们压缩到一个增强处理中,或者是把它们分别放在不同的切面,在通过切面的优先等级来排序
如果只要访问目标方法的参数,Spring还提供了一个更加简单的方式:我们可以在程序中使用args来绑定目标方法的参数,如果args表达是中指定一个或多个参数,则该切入点只匹配具有对应形参的方法,且目标方法的参数值将被出入增强处理方法。
如:
@Aspect
publicclass AccessArgsAspect {
@AfterReturning(pointcut =”execution(* cn.huaxia.spring.service1.*.*(。。))“
+”&&args(food,time)“, returning =”retValue“)
publicvoid access(String food, Date time, Object retValue) {
System.out.println(”目标方法中的String参数“ + food);
System.out.println(”目标方法的time参数“ + time);
System.out.println(”模拟日志记录功能。。.。。.“);
System.out.println(”目标参数的返回值:“+retValue);
}
}
@Component
publicclass Chinese3implements Person2 {
@Override
public String sayHello(String word) {
return word;
}
publicvoid eat(String food, Date time) {
System.out.println(”我正在吃:“ + food+”,现在的时间是:“ + time);
}
}
结果:
为什么目标方法的返回值是null,因为该切入点只匹配 publicvoid eat(String food, Date time)方法。
从上面可以得出,使用args表达式有如下两个作用:
--提供更简单的方式访问目标方法的参数;
--可用于对切入表达式增加额外限制。
除此之外,使用args表达式时还可以使用如下形式:args(name,age,。。),这表明增强处理方法中可通过name,age来访问目标方法的参数,上面表达式括号中的2点,它表示可匹配更多的参数,如:
public void doSomething(String name,int age)
这意味着只要目标方法第一个参数是String类型,第二个参数是int则该方法就可以匹配该切入点。
定义切入点:
正如前面的FourAdviceTest程序中看到的,这个切面类定义了4个增强处理,这4个增强处理分别指定了相同的切入点表达式,这种做法显然不符合软件设计的原则:我们将那个切入点表达式重复了4次,如果需要该这个切入点,那么就要修改4处。
Spring AOP只支持以Spring Bean的方法执行组作为连接点,
例如:
@Pointcut(”execution(* transfer(。。))“)
private void anyOldTransfer(){}一旦采用上面的代码片段定义了名为anyOldTrandser的切入点之后,程序就可以重复使用该切入点了,甚至可以在其他切面类、其他包的切面类里使用该切入点,不过这取决于该方法签名前的访问修饰符。
切入点指示符:
正如前面的execution就是一个切入点指示符,Spring AOP仅仅支持部分AspectJ切入点指示符,不仅如此Spring AOP只支持使用方法调用作为连接点,所以Spring AOP的切入点指示符仅匹配方法执行的连接点。
Spring AOP一共支持如下几种切入点指示符:
----execution:用于匹配执行方法的连接点,是Spring AOP最主要的切入点指示符,execution表达式的格式如下:
execution(modifies-pattern? ret-type-pattern declaring-type-parttern? name--pattern(parm-pattern) throws-pattern?)
以上打了问号的都可以省略。
上面格式中的execution是不变的,用于作为execution表达式的开头,整个表示式各个部分的解释为:
modifies-pattern:指定方法的修饰符,支持通配符,该部分可以省略。
ret-type-pattern:指定方法的返回值类型,支持通配符,可以使用“*”通配符来匹配所有返回值类型。
declaring-type-parttern:指定方法所属的类,支持通配符,该部分可以省略。
name--pattern:指定匹配指定方法名,支持通配符,可以使用“*”通配符来匹配所有方法。
parm-pattern:指定方法声明中的形参列表,支持两个通配符:“*”、“。。”,其中*表示一个任意类型的参数,而“。。”表示零个或多个任意类型的参数。
throws-pattern:指定方法声明抛出的异常,支持通配符,该部分可以省略。
例如下面几个execution表达式:
//匹配任意public方法的执行。
execution(public * * (。。))
//匹配任意方法名以set开始的方法只想能够。
execution(* set* (。。))
//匹配AccountService里定义的任意方法的执行。
execution(* org.huaxia.AccountService.* (。。))
//匹配Service包中任意类的任意方法的执行。
execution(* org.huaxia.service.*.*(。。))
----within:限定匹配特定类型的连接点,当使用Spring AOP的时候,只能匹配方法执行的连接点,
例如下面几个within表达式:
//在Service包中的任意连接点。
within(* org,huaxia.service.*)
//在Service包或者子包的任意连接点
within(* org.huaxia.service..*)
----this:用于限定AOP代理必须指定类型的实例,用于匹配该对象的所有连接点。当使用Spring AOP的时候,只能匹配方法执行的连接点。
例如:
//匹配实现了AccountService接口的代理对象的所有连接点
this(org.huaxia.service.AccountService)
----target:用于限定目标对象必须是指定类型的实例,用于匹配该对象的所有连接点,当使用Spring AOP只匹配执行方法的连接点。例如“”
//匹配实现了AccountService接口的目标对象的所有连接点
target(org.huaxia.service.AccountService)
----args:用于对连接点的参数类型进行限制,要求参数类型是指定类型的实例,例如:
//匹配只接受一个参数,且传入的参数类型是Serializable的所有连接点
args(java.io.Serializable)
注意:该例中给出的切入点表达式与execution(* *(java.io.Serializable))不同:args版本只匹配动态运行时传入参数值是Serializable类型的情况,而execution版本只匹配方法签名只包含一个Serializable类型的参数的方法。
----bean:用于指定只匹配指定Bean实例内连接点,实际上只能使用方法执行作为连接点,定义bean表达式需要传入id或name,表示只匹配Bean实例内连接点,支持“*”通配符。
例如:
//匹配tradeService Bean实例内方法执行的连接点
bean(tradeService)
//匹配名字以Service结尾的Bean实例内方法执行的连接点。
bean(*Service)
组合切入点表达式:
Spring支持3中逻辑运算符来组合切入点表达式:
&&:要求连接点同时匹配两个切入点表达式;
||:只要连接点匹配任意一个切入点表达式;
!:要求连接点不匹配指定切入点表达式。
⑤AOP 基于配置Xml文件的管理方式
除了前面介绍的基于JDK1.5的Annotation方式来定义切面、切入点和增强处理,Spring AOP也允许使用XML文件来定义管理它们。
实际上,使用XML定义AOP也是@AspectJ一样的同样需要指定相关数据:配置切面、切入点、增强处理所需要的信息完全一样,只是提供这些信息的位置不一样而已。使用XMLA文件配置AOPd的方式有很多优点但是也有一些缺点:
xml配置方式比@AspectJ方式有更多的限制:仅支持“singleton”切面的Bean,不能在xml中组合多个命名连接点的声明。
在Spring的配置文件中,所有的切面、切入点和增强处理都必须定义在《aop:config.。/》元素内部。《beans.。/》元素下可以包含多个《aop:config.。/》元素。
一个《aop:config.。/》可以包含多个pointcut、advisor和aspect元素,且这3个元素必须按照此顺序类定义。
注意:当我们使用《aop:config.。/》方式进行配置时,可能与Spring的自动代理方式冲突,例如我们使用BeanNameAutoProxyCreator或类似的方式显示启用了自动代理,则它可能导致问题(例如有些增请处理没有被织入)因此要么全部使用自动代理的方式,要么全部使用《aop:config.。/》配置方式。不要不两者混合使用。
————配置切面:
定义切面使用《aop:aspect.。/》元素,使用该元素来定义切面时,其实质是将一个已有的Spring Bean转换成切面Bean。
因为切面Bean可以当成一个普通的SpringBean来配置,所以可以为该切面Bean配置依赖注入。
配置《aop:aspect.。/》元素时可以指定如下3个属性:
id:定义该切面的标识名;
ref:指定以指定ref所引用的的普通Bean作为切面Bean。
order:指定该切面Bean的优先等级,数字越小,等级越大。
————配置增强处理:
《aop:before.。。/》:Before增强处理
《aop:after.。/》:After增强处理
《aop:after-returning.。。/》:afterReturning增强处理
《aop:after-throwing.。/》:afterThrowing增强处理
《aop:around.。。/》:Around增强处理
上面的元素不能配置子元素,但可以配置如下属性:
pointcut:该属性指定一个切入点表达式,Spring将在匹配该表达式的连接点时织入增强处理。
pointcut-ref:该属性指定一个已经存在的切入点的 名称,通常pointcut与pointcut-ref只需要使用其中的一个。
method:该属性指定一个方法名,指定切面Bean的该方法将作为增强处理。
throwing:该属性只对《aop:after-throwing.。/》起作用,用于指定一个形参名,afterThrowing增强处理方法可以通过该形参访问目标方法所抛出的异常。
returning:该属性只对《aop:after-returning.。。/》起作用,用于指定一个形参名,afterReturning增强处理方法可以通过该形参访问目标方法的返回值。
当定义切入点表达式时,XML文件配置方式和@AspectJ Annotation方式支持完全相同的切入点指示符,一样支持execution、within、args、this、target和bean等切入点指示符。
XML配置文件方式和@AspectJ Annotation方式一样支持组合切入点表达式,但XML配置方式不再使用简单的&&、||、!作为组合运算符,而是使用and(相当于&&)、or(||)和not(!)。
如:
//Spring配置文件:
《?xmlversion=”1.0“encoding=”UTF-8“?》
《beansxmlns=”http://www.springframework.org/schema/beans“
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance“xmlns:aop=”http://www.springframework.org/schema/aop“
xmlns:tx=”http://www.springframework.org/schema/tx“xmlns:context=”http://www.springframework.org/schema/context“
xsi:schemaLocation=”http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd“》
《aop:config》
《aop:aspectid=”fourAdviceAspect“ref=”fourAdviceBean“
order=”2“》
《aop:afterpointcut=”execution(* cn.huaxia.spring.lee.*.*(。。))“
method=”release“/》
《aop:beforepointcut=”execution(* cn.huaxia.spring.lee.*.*(。。))“
method=”authority“/》
《aop:after-returningpointcut=”execution(* cn.huaxia.spring.lee.*.*(。。))“
method=”log“returning=”obj“/》
《aop:aroundpointcut=”execution(* cn.huaxia.spring.lee.*.*(。。))“
method=”proceedTX“/》
《/aop:aspect》
《/aop:config》
《aop:config》
《aop:aspectid=”secondAspect“ref=”secondAdviceBean“order=”1“》
《aop:beforepointcut=”execution(* cn.huaxia.spring.lee.*.*(。。)) and args(aa)“
method=”authority“/》
《/aop:aspect》
《/aop:config》
《!-- 定义一个普通组件Bean --》
《beanid=”chinese“class=”cn.huaxia.spring.lee.Chinese“/》
《beanid=”fourAdviceBean“class=”cn.huaxia.spring.lee.FourAdviceTest“/》
《beanid=”secondAdviceBean“class=”cn.huaxia.spring.lee.SecondAdvice“/》
《/beans》
//业务类:
publicclass Chineseimplements Person {
public String sayHello(String word) {
System.out.println(”sayHello方法开始执行。。.“);
return word;
}
publicvoid eat(String food) {
System.out.println(”我正在吃:“ + food);
}
publicvoid divide() {
int a = 5 / 0;
System.out.println(”divide执行完毕/“ + a);
}
}
//切面Bean:
publicclass FourAdviceTest {
public Object proceedTX(ProceedingJoinPoint pre)throws Throwable {
System.out.println(”Around增强处理:执行目标方法前,执行模拟开启事务。。.。。.。“);
Object[] objs = pre.getArgs();
if (objs !=null && objs.length 》 0
&& objs[0].getClass() == String.class) {
objs[0] =”被修改的参数“;
}
Object obj = pre.proceed(objs);
System.out.println(”Around增强处理:执行目标方法之后,模拟结束事务。。.。。“);
return obj +”,新增加的内容“;
}
publicvoid authority(JoinPoint jp) {
System.out.println(”Before增强:模拟权限检查“);
System.out.println(”Before增强:被织入增强处理的目标方法:“
+ jp.getSignature().getName());
System.out.println(”Before增强:目标方法的参数为:“ + Arrays.toString(jp.getArgs()));
System.out.println(”Before增强:被注入增强的处理的目标对象:“ + jp.getTarget());
}
publicvoid log(JoinPoint jp, Object obj) {
System.out.println(”AfterReturning增强:获取目标方法的返回值:“ + obj);
System.out.println(”AfterReturning增强:模拟日志记录功能。。.。。“);
System.out.println(”AfterReturning增强:被织入增强处理的目标方法:“
+ jp.getSignature().getName());
System.out.println(”AfterReturning增强:目标方法的参数为:“
+ Arrays.toString(jp.getArgs()));
System.out.println(”AfterReturning增强:被注入增强的处理的目标对象:“ + jp.getTarget());
}
publicvoid release(JoinPoint jp) {
System.out.println(”After增强:模拟方法结束后,资源释放。。.。。“);
System.out.println(”After增强:被织入增强处理的目标方法:“
+ jp.getSignature().getName());
System.out.println(”After增强:目标方法的参数为:“ + Arrays.toString(jp.getArgs()));
System.out.println(”After增强:被注入增强的处理的目标对象:“ + jp.getTarget());
}
}
输出结果:
————配置切入点:
类似于@AspectJ方式,允许定义切入点来重用切入点表达式,XML配置方式也可以通过定义切入点来重用切入点表达式。
配置《aop:pointcut.。/》元素时通常需要指定如下两个属性:
id:指定该切入点的标识名;
expression:指定该切入点关联的切入点表达式。
如下面代码:
《aop:pointcut id=”myPointcut“ expression=”execution(* lee.*.*(。。))“/》
除此之外,如果程序已经使用Annotation定义了切入点,在《aop:pointcut 。。/》元素中指定切入点表达式时还有另一种用法:
《aop:pointcut expression=”org.huaxia.SystemArchitecture.myPointcut()“》
5,Spring的事务:
Spring事务管理不需要与任何特定事务API耦合,对不同的持久化层访问技术,编程式事务提供一致事务编程风格,通过模板化的操作一致性的管理事务。声明式事务基于Spring AOP实现,并不需要程序开发人员成为AOP专家,亦可以轻易使用Spring的声明式事务管理。
Spring支持的事务策略:
JavaEE应用程序的传统事务有两种策略,全局事务和局部事务。全局事务由应用服务器管理,需要底层的服务器的JTA支持,局部事务和底层采用的持久化技术有关,当采用JDBC持久化技术时,需要采用Connection对象来操作事务;而采用Hibernate持久化技术时,需要使用session操作失误。
当采用传统的事务编程策略时,程序代码必然和具体的事务操作代码耦合。这样的后果是:当应用程序需要在不同的的事务策略之间切换时,开发者必须手动修改程序代码。当改为Spring操作事务策略时,即可改变这种状况。
Spring事务策略是通过PlatformTransactionManager接口体现的,该接口是Spring事务策略的核心。
即使使用容器管理的JTA,代码依然不需要JNDI查找,无需与特定的JTA资源耦合在一起,通过配置文件,JTA资源传给PlatformTransactionManager的实现类,因此,程序的代码可以在JTA事务管理和非JTA事务管理之间轻松的切换。
Spring是否支持事务跨多个数据库资源?
答:Spring完全支持这种跨多个事务性资源的全局事务,前提是底层的应用服务器(如WebLogic、WebSphere等)支持JTA全局事务,可以这样说:Spring本身没有任何事务支持,它只是负责包装底层的事务————当我们在程序中面向PlatformTransactionManager接口编程时,Spring在底层负责将这些操作转换成具体的事务操作代码,所以应用底层支持什么样的事务策略,那么Spring就支持什么样的事务策略。Spring事务管理的优势是将应用从具体的事务API中分离出来,而不是真正提供事务管理的底层实现。
Spring的具体的事务管理由PlatformTransactionManager的不同实现类来完成,在Spring容器中配置PlatformTransactionManager时必须针对不同的环境提供不同的实现类,下面提供了不同的持久化访问环境,及其对应的PlatformTransactionManager实现类的配置。
1,BC数据源的局部事务策略的配置文件如下:
《!-- 定义数据源Bean,使用C3P0数据源实现 --》
《bean id=”dataSource“ class=”com.mchange.v2.c3p0.ComboPooledDataSource“
destroy-method=”close“》
《!-- 指定连接数据库的驱动 --》
《property name=”driverClass“ value=”com.mysql.jdbc.Driver“/》
《!-- 指定连接数据库的URL --》
《property name=”jdbcUrl“ value=”jdbc:mysql://localhost/javaee“/》
《!-- 指定连接数据库的用户名 --》
《property name=”user“ value=”root“/》
《!-- 指定连接数据库的密码 --》
《property name=”password“ value=”32147“/》
《!-- 指定连接数据库连接池的最大连接数 --》
《property name=”maxPoolSize“ value=”40“/》
《!-- 指定连接数据库连接池的最小连接数 --》
《property name=”minPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的初始化连接数 --》
《property name=”initialPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的连接的最大空闲时间 --》
《property name=”maxIdleTime“ value=”20“/》
《/bean》
《!-- 配置JDBC数据源的局部事务管理器,使用DataSourceTransactionManager 类 --》
《!-- 该类实现PlatformTransactionManager接口,是针对采用数据源连接的特定实现--》
《bean id=”transactionManager“
class=”org.springframework.jdbc.datasource.DataSourceTransactionManager“》
《!-- 配置DataSourceTransactionManager时需要依注入DataSource的引用 --》
《property name=”dataSource“ ref=”dataSource“/》
《/bean》
,2,器管理JTA全局事务的配置文件如下:
《!-- 配置JNDI数据源Bean--》
《bean id=”dateSource“ class=”org.springframework.jndi.JndiObjectFactoryBean“》
《!--容器管理数据源的JNDI--》
《property name=”jndiName“ value=”jdbc/jpetstore“/》
《/bean》
《!--使用JtaTransactionManager类,该类实现PlatformTransactionManager接口--》
《!--针对采用全局事务管理的特定实现--》
《bean id=”transactionManager“ class=”org.springframework.transaction.jta.JtaTransactionManager“/》
3,采用Hibernate持久层访问策略时,局部事务的策略的配置文件如下:
《!-- 定义数据源Bean,使用C3P0数据源实现 --》
《bean id=”dataSource“ class=”com.mchange.v2.c3p0.ComboPooledDataSource“
destroy-method=”close“》
《!-- 指定连接数据库的驱动 --》
《property name=”driverClass“ value=”com.mysql.jdbc.Driver“/》
《!-- 指定连接数据库的URL --》
《property name=”jdbcUrl“ value=”jdbc:mysql://localhost/javaee“/》
《!-- 指定连接数据库的用户名 --》
《property name=”user“ value=”root“/》
《!-- 指定连接数据库的密码 --》
《property name=”password“ value=”32147“/》
《!-- 指定连接数据库连接池的最大连接数 --》
《property name=”maxPoolSize“ value=”40“/》
《!-- 指定连接数据库连接池的最小连接数 --》
《property name=”minPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的初始化连接数 --》
《property name=”initialPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的连接的最大空闲时间 --》
《property name=”maxIdleTime“ value=”20“/》
《/bean》
《!-- 定义Hibernate的SessionFactory --》
《bean id=”sessionFactory“
class=”org.springframework.orm.hibernate3.LocalSessionFactoryBean“》
《!-- 依赖注入数据源,注入正是上面定义的dataSource --》
《property name=”dataSource“ ref=”dataSource“/》
《!-- mappingResouces属性用来列出全部映射文件 --》
《property name=”mappingResources“》
《list》
《!-- 以下用来列出Hibernate映射文件 --》
《value》Person.hbm.xml《/value》
《/list》
《/property》
《!-- 定义Hibernate的SessionFactory的属性 --》
《property name=”hibernateProperties“》
《props》
《!-- 指定数据库方言 --》
《prop key=”hibernate.dialect“》
org.hibernate.dialect.MySQLInnoDBDialect《/prop》
《!-- 是否根据需要每次自动创建数据库 --》
《prop key=”hibernate.hbm2ddl.auto“》update《/prop》
《!-- 显示Hibernate持久化操作所生成的SQL --》
《prop key=”hibernate.show_sql“》true《/prop》
《!-- 将SQL脚本进行格式化后再输出 --》
《prop key=”hibernate.format_sql“》true《/prop》
《/props》
《/property》
《/bean》
《!--配置Hibernate局部事务管理器,使用HibernateTransactionManager类--》
《!--该类是PlatformTransactionManager接口针对采用Hibernate的特定实现类--》
《bean id=”transactionManager“ class=”org.springframework.orm.hibernate3.HibernateTransactionManager“》
《property name=”sessionFactory“ ref=”sessionFactory“/》
《/bean》
4,底层采用Hibernate持久化技术,但事务依然采用JTA全局事务:
《!-- 定义数据源Bean,使用C3P0数据源实现 --》
《bean id=”dataSource“ class=”com.mchange.v2.c3p0.ComboPooledDataSource“
destroy-method=”close“》
《!-- 指定连接数据库的驱动 --》
《property name=”driverClass“ value=”com.mysql.jdbc.Driver“/》
《!-- 指定连接数据库的URL --》
《property name=”jdbcUrl“ value=”jdbc:mysql://localhost/javaee“/》
《!-- 指定连接数据库的用户名 --》
《property name=”user“ value=”root“/》
《!-- 指定连接数据库的密码 --》
《property name=”password“ value=”32147“/》
《!-- 指定连接数据库连接池的最大连接数 --》
《property name=”maxPoolSize“ value=”40“/》
《!-- 指定连接数据库连接池的最小连接数 --》
《property name=”minPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的初始化连接数 --》
《property name=”initialPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的连接的最大空闲时间 --》
《property name=”maxIdleTime“ value=”20“/》
《/bean》
《!-- 定义Hibernate的SessionFactory --》
《bean id=”sessionFactory“
class=”org.springframework.orm.hibernate3.LocalSessionFactoryBean“》
《!-- 依赖注入数据源,注入正是上面定义的dataSource --》
《property name=”dataSource“ ref=”dataSource“/》
《!-- mappingResouces属性用来列出全部映射文件 --》
《property name=”mappingResources“》
《list》
《!-- 以下用来列出Hibernate映射文件 --》
《value》Person.hbm.xml《/value》
《/list》
《/property》
《!-- 定义Hibernate的SessionFactory的属性 --》
《property name=”hibernateProperties“》
《props》
《!-- 指定数据库方言 --》
《prop key=”hibernate.dialect“》
org.hibernate.dialect.MySQLInnoDBDialect《/prop》
《!-- 是否根据需要每次自动创建数据库 --》
《prop key=”hibernate.hbm2ddl.auto“》update《/prop》
《!-- 显示Hibernate持久化操作所生成的SQL --》
《prop key=”hibernate.show_sql“》true《/prop》
《!-- 将SQL脚本进行格式化后再输出 --》
《prop key=”hibernate.format_sql“》true《/prop》
《/props》
《/property》
《/bean》
《!--使用JtaTransactionManager类,该类实现PlatformTransactionManager接口--》
《!--针对采用全局事务管理的特定实现--》
《bean id=”transactionManager“ class=”org.springframework.transaction.jta.JtaTransactionManager“/》
从上面的配置文件可以看出,当使用Spring事务管理事务策略时,应用程序无需与具体的事务策略耦合,,Spring提供了两种事务管理方式:
编程式管理方式:即使使用Spring编程式事务时,程序也可直接获取容器中的TransactionManager Bean,该Bean总是PlatformTransactionManager的实例,可以通过该接口提供的3个方法来开始事务,提交事务和回滚事务。
声明式管理方式:无需在Java程序中书写任何的事务操作代码,而是通过在XML文件中为业务组件配置事务代理(AOP代理的一种),AOP事务代理所织入的增强处理也是由Spring提供:在目标方法前,织入开始事务;在目标方法后执行,织入结束事务。
注意:
Spring编程事务还可以通过TransactionTemplate类来完成,该类提供了一个execute方法,可以更简洁的方式来进行事务操作。
当使用声明式事务时,开发者无需书写任何事务管理代码,不依赖Spring或或任何事务API,Spring的声明式事务编程无需任何额外的容器支持,Spring容器本身管理声明式事务,使用声明式事务策略,可以让开发者更好的专注于业务逻辑的实现。
————使用TransactionProxyFactoryBean创建事务代理————
在Spring1.X,声明事务使用TransactionProxyFactoryBean来配置事务代理Bean,正如他的名字所暗示的,它是一个工厂Bean,该工程Bean专为目标Bean生成事务代理Bean,既然TransactionProxyFactoryBean产生的是事务代理Bean,可见Spring的声明式事务策略是基于Spring AOP的。
例如:
《?xml version=”1.0“ encoding=”GBK“?》
《!-- 指定Spring配置文件的DTD信息 --》
《!DOCTYPE beans PUBLIC ”-//SPRING//DTD BEAN 2.0//EN“
”http://www.springframework.org/dtd/spring-beans-2.0.dtd“》
《!-- Spring配置文件的根元素 --》
《beans》
《!-- 定义数据源Bean,使用C3P0数据源实现 --》
《bean id=”dataSource“ class=”com.mchange.v2.c3p0.ComboPooledDataSource“
destroy-method=”close“》
《!-- 指定连接数据库的驱动 --》
《property name=”driverClass“ value=”com.mysql.jdbc.Driver“/》
《!-- 指定连接数据库的URL --》
《property name=”jdbcUrl“ value=”jdbc:mysql://localhost/javaee“/》
《!-- 指定连接数据库的用户名 --》
《property name=”user“ value=”root“/》
《!-- 指定连接数据库的密码 --》
《property name=”password“ value=”32147“/》
《!-- 指定连接数据库连接池的最大连接数 --》
《property name=”maxPoolSize“ value=”40“/》
《!-- 指定连接数据库连接池的最小连接数 --》
《property name=”minPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的初始化连接数 --》
《property name=”initialPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的连接的最大空闲时间 --》
《property name=”maxIdleTime“ value=”20“/》
《/bean》
《!-- 配置JDBC数据源的局部事务管理器,使用DataSourceTransactionManager 类 --》
《!-- 该类实现PlatformTransactionManager接口,是针对采用数据源连接的特定实现--》
《bean id=”transactionManager“
class=”org.springframework.jdbc.datasource.DataSourceTransactionManager“》
《!-- 配置DataSourceTransactionManager时需要依注入DataSource的引用 --》
《property name=”dataSource“ ref=”dataSource“/》
《/bean》
《!-- 配置一个业务逻辑Bean --》
《bean id=”test“ class=”lee.TestImpl“》
《property name=”ds“ ref=”dataSource“/》
《/bean》
《!-- 为业务逻辑Bean配置事务代理 --》
《bean id=”testTrans“ class=
”org.springframework.transaction.interceptor.TransactionProxyFactoryBean“》
《!-- 为事务代理工厂Bean注入事务管理器 --》
《property name=”transactionManager“ ref=”transactionManager“/》
《property name=”target“ ref=”test“/》
《!-- 指定事务属性 --》
《property name=”transactionAttributes“》
《props》
《prop key=”*“》PROPAGATION_REQUIRED《/prop》
《/props》
《/property》
《/bean》
《/beans》
public class TestImpl implements Test
{
private DataSource ds;
public void setDs(DataSource ds)
{
this.ds = ds;
}
public void insert(String u)
{
JdbcTemplate jt = new JdbcTemplate(ds);
jt.execute(”insert into mytable values(‘“ + u + ”’)“);
//两次插入相同的数据,将违反主键约束
jt.execute(”insert into mytable values(‘“ + u + ”’)“);
//如果增加事务控制,我们发现第一条记录也插不进去。
//如果没有事务控制,则第一条记录可以被插入
}
}
配置事务代理的时。需要传入一个事务管理器,一个目标Bena,并指定该事务的事务属性,事务实行由transactionAttribute指定,上面只有一条事务传播规则,该规则指定对于所有方法都使用PROPAGATION_REQUIRED的传播属性,Spring支持的事务传播规则:
PROPAGATION_MANDATORY:要求调用该方法的线程已处于事务环境中,否则抛出异常;
PROPAGATION_NESTED:如果执行该方法的线程已处于事务的环境下,依然启动新的事务,方法在嵌套的事务里执行,如果执行该方法的线程并未处于事务的环境下,也启动新的事务,此时与PROPAGATION_REQUIRED;
PROPAGATION_NOT_SUPPORTED:如果调用该方法的线程处于事务中,则暂停事务,再执行方法。
PROPAGATION_NEVER:不允许执行该方法的线程处于事务的环境下,如果执行该方法的线程处于事务的环境下,则会抛出异常;
PROPAGATION_REQUIRED:要求在事务环境中执行该方法,如果当前执行线程已处于事务中,则直接调用;否则,则启动新的事务后执行该方法。
PROPAGATION_REQUIREDS_NEW:该方法要求在新的事务中执行,如果当前执行线程已处于事务环境下,则暂停当前事务,启动新事务后执行方法;否则,启动新的事务后执行方法。
PROPAGATION_SUPPORTS:如果当前线程处于事务中,则使用当前事务,否则不使用事务。
主程序代码:
public class MainTest
{
public static void main(String[] args)
{
//创建Spring容器
ApplicationContext ctx = new
ClassPathXmlApplicationContext(”bean.xml“);
//获取事务代理Bean
Test t = (Test)ctx.getBean(”testTrans“);----------①
//执行插入操作
t.insert(”bbb“);
}
}
上面①处代码获取testTrans Bean,该Bean已不再是TestImpl的实例了,它只是Spring容器创建的事务代理,该事务代理以TestImpl实例为目标对象,且该目标对象也实现了Test接口,故代理对象也可当作Test实例使用。
实际上,Spring不仅支持对接口的代理,整合GBLIB后,Spring甚至可以对具体类生成代理,只要设置proxyTargetClass属性为true就可以了,如果目标Bean没有实现任何接口,proxyTargetClass默认为true,此时Spring会对具体的类生成代理。当然通常建议面向接口编程,而不面向具体的实现类编程。
————Spring2.X的事务配置策略————
上面介绍的TransactionProxyFactoryBean配置策略简单易懂,但是配置起来极为繁琐:每个目标Bean都需要额外配置一个TransactionProxyFactoryBean代理,这种方法将导致配置文件的急剧增加。
Spring2.X的XML Schema方式提供了更简洁事务配置策略,Spring提供了tx命名空间来配置事务管理,tx命名空间下提供了《tx:advice.。/》元素来配置事务切面,一旦使用了该元素配置了切面,就可以直接使用《aop:advisor.。。/》元素启动自动代理。
如:
《?xml version=”1.0“ encoding=”GBK“?》
《!-- 指定Spring配置文件的Schema信息 --》
《beans xmlns=”http://www.springframework.org/schema/beans“
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance“
xmlns:aop=”http://www.springframework.org/schema/aop“
xmlns:tx=”http://www.springframework.org/schema/tx“
xsi:schemaLocation=”http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-2.5.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-2.5.xsd“》
《!-- 定义数据源Bean,使用C3P0数据源实现 --》
《bean id=”dataSource“ class=”com.mchange.v2.c3p0.ComboPooledDataSource“
destroy-method=”close“》
《!-- 指定连接数据库的驱动 --》
《property name=”driverClass“ value=”com.mysql.jdbc.Driver“/》
《!-- 指定连接数据库的URL --》
《property name=”jdbcUrl“ value=”jdbc:mysql://localhost/javaee“/》
《!-- 指定连接数据库的用户名 --》
《property name=”user“ value=”root“/》
《!-- 指定连接数据库的密码 --》
《property name=”password“ value=”32147“/》
《!-- 指定连接数据库连接池的最大连接数 --》
《property name=”maxPoolSize“ value=”40“/》
《!-- 指定连接数据库连接池的最小连接数 --》
《property name=”minPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的初始化连接数 --》
《property name=”initialPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的连接的最大空闲时间 --》
《property name=”maxIdleTime“ value=”20“/》
《/bean》
《!-- 配置JDBC数据源的局部事务管理器,使用DataSourceTransactionManager 类 --》
《!-- 该类实现PlatformTransactionManager接口,是针对采用数据源连接的特定实现--》
《bean id=”transactionManager“
class=”org.springframework.jdbc.datasource.DataSourceTransactionManager“》
《!-- 配置DataSourceTransactionManager时需要依注入DataSource的引用 --》
《property name=”dataSource“ ref=”dataSource“/》
《/bean》
《!-- 配置一个业务逻辑Bean --》
《bean id=”test“ class=”lee.TestImpl“》
《property name=”ds“ ref=”dataSource“/》
《/bean》
《!-- 配置事务切面Bean,指定事务管理器 --》
《tx:advice id=”txAdvice“ transaction-manager=”transactionManager“》
《!-- 用于配置详细的事务语义 --》
《tx:attributes》
《!-- 所有以‘get’开头的方法是read-only的 --》
《tx:method name=”get*“ read-only=”true“/》
《!-- 其他方法使用默认的事务设置 --》
《tx:method name=”*“/》
《/tx:attributes》
《/tx:advice》
《aop:config》
《!-- 配置一个切入点,匹配lee包下所有以Impl结尾的类
执行的所有方法 --》
《aop:pointcut id=”leeService“
expression=”execution(* lee.*Impl.*(。。))“/》
《!-- 指定在txAdvice切入点应用txAdvice事务切面 --》
《aop:advisor advice-ref=”txAdvice“
pointcut-ref=”leeService“/》
《/aop:config》
《/beans》
提示:
Advisor的作用:将Advice和切入点绑在一起,保证Advice所包含的增强处理在对应的切入点被织入。
主程序:
public class MainTest
{
public static void main(String[] args)
{
//创建Spring容器
ApplicationContext ctx = new
ClassPathXmlApplicationContext(”bean.xml“);
//获取事务代理Bean
Test t = (Test)ctx.getBean(”test“);
//执行插入操作
t.insert(”bbb“);
}
}
上面的配置文件直接获取容器中的test Bean,因为Spring AOP会为该Bean自动织入事务增强处理的方式,所以test Bean的所有方法都具有事务性。
配置《tx:advice.。/》元素时除了需要一个transaction-Manager之外,重要的就是需要配置一个《attributes.。。/》子元素,该元素又可以包含多个《method.。/》子元素。
可以看出配置《tx:advice.。/》元素重点就是配置《method.。。/》子元素,每个《method.。/》子元素为一批方法指定所需的事务语义。
配置《method.。/》元素时可以指定如下属性:
name:必选属性,与该事务语义关联的方法名,该属性支持通配符。
propagation:指定事务传播行为,该属性可以为Propagation枚举类的任意一个枚举值,该属性 的默认值是Propagation.REQUIRED;
isolation:指定事务隔离级别,该属性值可为Isolation枚举类的任意枚举值。
timeout:指定事务超时时间(以秒为单位),指定-1意味不超时,默认值是-1;
read-only:指定事务是否只读,该属性默认为false;
rollback-for:指定触发事务回滚的异常类(全名),该属性可以指定多个异常类,用英文逗号隔开;
no-rollback-for:指定不触发事务回滚的类,该属性可以指定多个异常类,并且用英文的逗号隔开。
因此我们可以为不同的业务逻辑方法指定不同的事务策略,如:
《tx:advice id=”aaa“》
《tx:attributes》
《tx:method name=”get*“ read--only=”true“/》
《tx:method name=”*“/》
《/tx:attributes》
《/tx:advice》
《tx:advice id=”bbb“》
《tx:attributes》
《tx:method name=”*“ propagation=”NEVER“/》
《/tx:attributes》
《/tx:advice》
6,Spring整合Struts2
①启动Spring容器:
1,直接在web.xml文件中配置Spring容器;
2,利用第三方MVC框架扩张点,创建Spring容器。
第一种创建Spring容器的方式更加常见,为了让Spring容器随web应用启动而启动,有如下两种方式:
利用ServletContextListener实现;
采用load-on-startup Servlet实现。
Spring提供ServletContextListener的一个实现类ContextLoadListener,该类可以作为Listener使用,它会在创建时自动查找WEB-INF目录下的ApplicationContext.xml,
如果只有一个配置文件,并且名字为ApplicationContext.xml,则只需要在web.xml文件添加如下代码:
《listener》
《listener-class》org.springframework.web.context.ContextLoadListener《/listener-class》
《/listener》
如果需要加载多个配置文件,则考虑使用《context-param.。/》元素来确定配置文件的文件名。ContextLoadListener加载时,会查找名为contextConfigLocation的初始化参数:
《context-param》
《param-name》contextConfigLocation《/param-name》
《param-value》可以配置多个文件,用逗号隔开《/param-value》
《/context-param》
除此之外,Spring提供一个特殊的Servlet类:ContextLoadServlet。该Servlet启动时,也会自动查找WEB-INF路径下的ApplicationContext.xml文件。为了让ContextLoadServlet随应用启动而启动,应该将此Servlet配置成
load-on-startup的值小一点比较合适,这样可以保证ApplicationContext更快的初始化。
《servlet》
《servlet-name》context《/servlet-name》
《servlet-class》org.springframework.web.context.ContextLoadServlet《/servlet-class》
《load-on-startup》1《/load-on-startup》
《/servlet》
该Servlet用于提供后台服务的,主要用于创建Spring容器的,无需响应客户端请求,因此无需为它配《servlet-mapping.。/》,如果有多个配置文件,或者文件名不是applicationContext,则 一样使用《context-param.。。/》元素来确定多个配置文件。
ContextLoadListener和ContextLoadServlet底层都是依赖于ContextLoad。因此二者效果没有什么区别,他们之间的区别不是它们本身 引起的,而是Servlet规范:Listener比Servlet优先加载,因此采用ContextLoadListener创建ApplicationContext的时机更早。
②MVC框架与Spring整合的思考:
对于一个基于B/S架构的JavaEE而言,用户请求总是向MVC框架的控制器请求,而当控制器拦截到用户请求后,必须调用业务组件来处理用户的请求,那么控制器如何获取业务组件呢?
最容易想到的是,直接通过new 关键字创建业务逻辑,然后调用该业务逻辑组件的方法。
在实际应用中很少采用上面的访问策略,至少有一下几个原因:
1:控制器直接创建业务组件,导致控制器和业务组件的耦合降低到代码层次,不利于高层次的解耦;
2:控制器不应该负责业务逻辑组件的创建,控制器只是业务逻辑的使用者,,无需关系业务逻辑组件的实现;
3:每次创建新的业务组件导致性能降低。
答案是采用工厂模式或者服务定位器模式,对于采用服务定位模式,是远程访问的场景,在这种情形下,业务组件已经在某个容器中运行,并对外提供某种服务,控制器无需理会该业务组件的创建,直接调用该服务即可,但在调用该服务前,必须先找到该服务。这就是服务定位模式的概念,经典JavaEE应用就是这种结构的应用。
对于轻量级的JavaEE 应用,工厂模式则是更实际的策略,因为在轻量级JavaEE应用中,业务组件不是EJB,通常就是一个POJO,业务组件的生成通常应由工厂负责,而且工厂可以保证组件的实例只需要一个就够了,可以避免重复实例化造成的系统开销。
如果系统采用Spring框架,则Spring成为最大的工厂,那么控制器如何访问到Spring容器中的业务组件呢?有两种策略:
1,Spring容器负责管理控制器Action,并利用依赖注入为容器注入业务组件;
2,利用Spring的自动装配,Action将会自动从Spring容器中获取所需的业务逻辑组件。如:
Action类:
publicclass LoginActionimplements Action {
private Stringusername;
private Stringpassword;
private Stringtip;
private MyServicems;
publicString execute()throws Exception {
if(ms.valid(username,password)){
setTip(”哈哈哈。整合成功!“);
returnSUCCESS;
}
}
returnERROR;
}
业务组件:
publicclass MyServiceImplimplements MyService {
publicboolean valid(String username,String password) {
if(username.equals(”johnny“)&&password.equals(”123“)){
returntrue;
}
returnfalse;
}
}
Spring配置文件:
《?xmlversion=”1.0“encoding=”UTF-8“?》
《beansxmlns=”http://www.springframework.org/schema/beans“
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance“xmlns:aop=”http://www.springframework.org/schema/aop“
xmlns:tx=”http://www.springframework.org/schema/tx“
xsi:schemaLocation=”
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd“》
《beanid=”myService“class=”cn.huaxia.user.service.impl.MyServiceImpl“/》
《beanid=”loginAction“class=”cn.huaxia.web.struts.action.LoginAction“
scope=”prototype“》
《propertyname=”ms“ref=”myService“/》
《/bean》
《/beans》
Struts2配置文件:
《?xmlversion=”1.0“encoding=”GBK“?》
《!-- 指定Struts2配置文件的DTD信息--》
《!DOCTYPEstrutsPUBLIC
”-//Apache Software Foundation//DTD Struts Configuration 2.0//EN“
”http://struts.apache.org/dtds/struts-2.0.dtd“》
《!-- Struts2配置文件的根元素--》
《struts》
《!-- 配置了系列常量--》
《constantname=”struts.custom.i18n.resources“value=”messageResource“/》
《constantname=”struts.i18n.encoding“value=”GBK“/》
《packagename=”lee“extends=”struts-default“》
《!-- 定义处理用户请求的Action,该Action的class属性不是实际处理类
, 而是Spring容器中的Bean实例--》
《actionname=”login“class=”loginAction“》
《!-- 为两个逻辑视图配置视图页面--》
《resultname=”error“》/error.jsp《/result》
《resultname=”success“》/success.jsp《/result》
《/action》
《!-- 让用户直接访问该应用时列出所有视图页面--》
《actionname=”“》
《result》。《/result》
《/action》
《/package》
《/struts》
7,Spring整合Hibernate
1,Spring提供的dao支持:
DAO模式是标准的java EE设计模式,DAO模式的核心思想是所有的数据库访问,都通过DAO组件完成,DAO组件封装了数据库的增删改查等原子操作,业务逻辑组件依赖DAO组件提供的原子操作,
对于javaEE的应用架构,有非常多的,不管细节如何变化,javaEE大致 可以分为如下三层:
表现层;
业务逻辑层;
数据持久层;
Spring提供了一系列的抽象类,这些抽象类将被作为应用中DAO组件可以通过这些抽象类,Spring简化了DAO的开发步骤,能够以一致的访问方式使用数据库访问技术,不管底层采用JDBC、JDO还是个Hibernate,应用中都采用一致的编程模型。
Spring提供的多种数据库访问技术的DAO支持,包括Hibernate、JDO、TopLink、iBatis、OJB、JPA等,就Hibernate的持久层访问技术而言,Spring提供如下3个工具类来支持DAO组件的实现:HibernateDaoSupport、HibernateTemplate、HibernateCallback。
2,管理Hibernate的SessionFactory
前面介绍的Hibernate的时候知道:通过Hibernate进行持久层访问的时候,Hibernate的SessionFactory是非常重要的对象,它是单个数据库映射关系编译后的内存镜像,大部分情况下,一个java EE应用对应一个数据库,即对应一个SessionFactory对象。
配置SessionFactory的示范代码:
《!-- 定义数据源Bean,使用C3P0数据源实现 --》
《bean id=”dataSource“ class=”com.mchange.v2.c3p0.ComboPooledDataSource“
destroy-method=”close“》
《!-- 指定连接数据库的驱动 --》
《property name=”driverClass“ value=”com.mysql.jdbc.Driver“/》
《!-- 指定连接数据库的URL --》
《property name=”jdbcUrl“ value=”jdbc:mysql://localhost/javaee“/》
《!-- 指定连接数据库的用户名 --》
《property name=”user“ value=”root“/》
《!-- 指定连接数据库的密码 --》
《property name=”password“ value=”32147“/》
《!-- 指定连接数据库连接池的最大连接数 --》
《property name=”maxPoolSize“ value=”40“/》
《!-- 指定连接数据库连接池的最小连接数 --》
《property name=”minPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的初始化连接数 --》
《property name=”initialPoolSize“ value=”1“/》
《!-- 指定连接数据库连接池的连接的最大空闲时间 --》
《property name=”maxIdleTime“ value=”20“/》
《/bean》
《!-- 定义Hibernate的SessionFactory --》
《bean id=”sessionFactory“
class=”org.springframework.orm.hibernate3.LocalSessionFactoryBean“》
《!-- 依赖注入数据源,注入正是上面定义的dataSource --》
《property name=”dataSource“ ref=”dataSource“/》
《!-- mappingResouces属性用来列出全部映射文件 --》
《property name=”mappingResources“》
《list》
《!-- 以下用来列出Hibernate映射文件 --》
《value》Person.hbm.xml《/value》
《/list》
《/property》
《!-- 定义Hibernate的SessionFactory的属性 --》
《property name=”hibernateProperties“》
《props》
《!-- 指定数据库方言 --》
《prop key=”hibernate.dialect“》
org.hibernate.dialect.MySQLInnoDBDialect《/prop》
《!-- 是否根据需要每次自动创建数据库 --》
《prop key=”hibernate.hbm2ddl.auto“》update《/prop》
《!-- 显示Hibernate持久化操作所生成的SQL --》
《prop key=”hibernate.show_sql“》true《/prop》
《!-- 将SQL脚本进行格式化后再输出 --》
《prop key=”hibernate.format_sql“》true《/prop》
《/props》
《/property》
《/bean》
3,使用HibernateTemplate:
HibernateTemplate提供持久层访问模版化,它只需要提供一个SessionFactory的引用,SessionFactory可以通过构造方法参数传入,也可以通过设值方式传入。
示例:
public class PersonDaoImpl implements PersonDao
{
//定义一个HibernateTemplate对象,用于执行持久化操作
private HibernateTemplate ht = null;
//Hibernate持久化操作所需的SessionFactory
private SessionFactory sessionFactory;
//依赖注入SessionFactory的setter方法
public void setSessionFactory(SessionFactory sessionFactory)
{
this.sessionFactory = sessionFactory;
}
//初始化HibernateTemplate的方法
private HibernateTemplate getHibernateTemplate()
{
if (ht == null)
{
ht = new HibernateTemplate(sessionFactory);
}
return ht;
}
/**
* 加载Person实例
* @param id 需要加载的Person实例的标识属性值
* @return 指定id对应的Person实例
*/
public Person get(Integer id)
{
return (Person)getHibernateTemplate()
.get(Person.class, id);
}
/**
* 保存Person实例
* @param person 需要保存的Person实例
* @return 刚刚保存的Person实例的标识属性值
*/
public Integer save(Person person)
{
return (Integer)getHibernateTemplate()
.save(person);
}
/**
* 修改Person实例
* @param person 需要修改的Person实例
*/
public void update(Person person)
{
getHibernateTemplate().update(person);
}
/**
* 删除Person实例
* @param id 需要删除的Person实例的标识属性值
*/
public void delete(Integer id)
{
getHibernateTemplate().delete(get(id));
}
/**
* 删除Person实例
* @param person 需要删除的Person实例
*/
public void delete(Person person)
{
getHibernateTemplate().delete(person);
}
/**
* 根据用户名查找Person
* @param name 查询的人名
* @return 指定用户名对应的全部Person
*/
public List《Person》 findByName(String name)
{
return (List《Person》)getHibernateTemplate()
.find(”from Person p where p.name like ?“ , name);
}
/**
* 查询全部Person实例
* @return 全部Person实例
*/
public List findAllPerson()
{
return (List《Person》)getHibernateTemplate()
.find(”from Person“);
}
/**
* 查询数据表中Person实例的总数
* @return 数据表中Person实例的总数
*/
public long getPersonNumber()
{
return (Long)getHibernateTemplate().find
(”select count(*) from Person as p“)
.get(0);
}
}
4,使用HibernateCallback:
HibernateTemplate还提供一种更加灵活的方式来操作数据库,,通过这种方式可以完全使用Hibernate的操作方式,HibernateTemplate的灵活方式是通过如下两个方法来完成的。
Object execute(HibernateCallback action);
List executeFind(HibernateCallback action);
这两个方法都需要一个HibernateCallback实例,HibernateCallback是一个接口,该接口包含一个方法doInHibernate(org.hibernate Session session),该方法是有一个Session参数,当我们在开发中提供HibernateCallback实现类时,必须实现接口里的doInHibernate方法,该方法体内即可获得 Hibernate Session的引用。一旦获取到Session的引用我们就可以完全以Hibernate的方式进行数据库的访问。
示例:
public class YeekuHibernateDaoSupport extends HibernateDaoSupport
{
/**
* 使用hql语句进行分页查询
* @param hql 需要查询的hql语句
* @param offset 第一条记录索引
* @param pageSize 每页需要显示的记录数
* @return 当前页的所有记录
*/
public List findByPage(final String hql,
final int offset, final int pageSize)
{
//通过一个HibernateCallback对象来执行查询
List list = getHibernateTemplate()
.executeFind(new HibernateCallback()
{
//实现HibernateCallback接口必须实现的方法
public Object doInHibernate(Session session)
throws HibernateException, SQLException
{
//执行Hibernate分页查询
List result = session.createQuery(hql)
.setFirstResult(offset)
.setMaxResults(pageSize)
.list();
return result;
}
});
return list;
}
/**
* 使用hql语句进行分页查询
* @param hql 需要查询的hql语句
* @param value 如果hql有一个参数需要传入,value就是传入hql语句的参数
* @param offset 第一条记录索引
* @param pageSize 每页需要显示的记录数
* @return 当前页的所有记录
*/
public List findByPage(final String hql , final Object value ,
final int offset, final int pageSize)
{
//通过一个HibernateCallback对象来执行查询
List list = getHibernateTemplate()
.executeFind(new HibernateCallback()
{
//实现HibernateCallback接口必须实现的方法
public Object doInHibernate(Session session)
throws HibernateException, SQLException
{
//执行Hibernate分页查询
List result = session.createQuery(hql)
//为hql语句传入参数
.setParameter(0, value)
.setFirstResult(offset)
.setMaxResults(pageSize)
.list();
return result;
}
});
return list;
}
/**
* 使用hql语句进行分页查询
* @param hql 需要查询的hql语句
* @param values 如果hql有多个个参数需要传入,values就是传入hql的参数数组
* @param offset 第一条记录索引
* @param pageSize 每页需要显示的记录数
* @return 当前页的所有记录
*/
public List findByPage(final String hql, final Object[] values,
final int offset, final int pageSize)
{
//通过一个HibernateCallback对象来执行查询
List list = getHibernateTemplate()
.executeFind(new HibernateCallback()
{
//实现HibernateCallback接口必须实现的方法
public Object doInHibernate(Session session)
throws HibernateException, SQLException
{
//执行Hibernate分页查询
Query query = session.createQuery(hql);
//为hql语句传入参数
for (int i = 0 ; i 《 values.length ; i++)
{
query.setParameter( i, values[i]);
}
List result = query.setFirstResult(offset)
.setMaxResults(pageSize)
.list();
return result;
}
});
return list;
}
}
Spring提供了XxxTemplate和XxxCallback互为补充,XxxTemplate对操作进行封装,XxxCallback解决了封装后灵活性不足的缺陷。
5,实现DAO组件:
为了实现DAO组件,Spring提供了大量的XxxDaoSupport类,这些dao支持类已经完成了大量基础性的工作。
Spring为Hibernate的DAO提供工具类:HibernateDaoSupport,该类主要提供如下几个方法来简化DAO的实现:
public final HibernateTemplate getHibernateTemplate ();
public final void setSessionFactory(SessionFactory sessionFactory);
setSessionFactory方法可用于接收Spring的依赖注入,允许使用依赖注入Spring 管理的SessionFactory实例。
public class PersonDaoHibernate
extends HibernateDaoSupport implements PersonDao
{
/**
* 加载Person实例
* @param id 需要加载的Person实例的标识属性值
* @return 指定id对应的Person实例
*/
public Person get(Integer id)
{
return (Person)getHibernateTemplate()
.get(Person.class, id);
}
/**
* 保存Person实例
* @param person 需要保存的Person实例
* @return 刚刚保存的Person实例的标识属性值
*/
public Integer save(Person person)
{
return (Integer)getHibernateTemplate()
.save(person);
}
/**
* 修改Person实例
* @param person 需要修改的Person实例
*/
public void update(Person person)
{
getHibernateTemplate().update(person);
}
/**
* 删除Person实例
* @param id 需要删除的Person实例的标识属性值
*/
public void delete(Integer id)
{
getHibernateTemplate().delete(get(id));
}
/**
* 删除Person实例
* @param person 需要删除的Person实例
*/
public void delete(Person person)
{
getHibernateTemplate().delete(person);
}
/**
* 根据用户名查找Person
* @param name 查询的人名
* @return 指定用户名对应的全部Person
*/
public List《Person》 findByName(String name)
{
return (List《Person》)getHibernateTemplate()
.find(”from Person p where p.name like ?“ , name);
}
/**
* 查询全部Person实例
* @return 全部Person实例
*/
public List findAllPerson()
{
return (List《Person》)getHibernateTemplate()
.find(”from Person“);
}
}
实际上,DAO的实现依然借助于HibernateTemplate的模板访问方式,只是HibernateDaoSupport提供了两个工具方法。
至此Java EE应用所需的各种组件都已经出现了。
从用户的角度上看,用户发出HTTP请求,当MVC框架的控制器组件拦截到用户的请求,将调用系统的业务逻辑组件,业务逻辑组件则调用 系统的DAO组件,,而DAO组件则依赖于SessionFactory和DataSOurce等底层的实现数据库访问。
从系统的实现角度上看,IoC容器先创建SessionFactory和DataSource等底层组件,然后将这些组件注入DAO组件,提供一个完整的Dao组件,并将DAO组件注入给业务逻辑组件,从而提供一个完整的业务逻辑组件,而业务逻辑组件又被注入给控制器组件,控制器组件负责拦截用户请求,并将处理结果呈现给用户。
-
Spring MVC的工作原理2023-12-03 1828
-
springmvc的工作原理2023-11-22 1205
-
Java、Spring、Dubbo三者SPI机制的原理和区别2023-06-05 1975
-
基于spring的SPI扩展机制是如何实现的?2023-03-07 1845
-
「Spring认证」Spring IoC 容器2022-06-28 1410
-
Spring Boot嵌入式Web容器原理是什么2021-12-16 1462
-
「Spring认证」什么是Spring GraphQL?2021-08-10 1490
-
Spring认证_什么是Spring GraphQL2021-08-06 1364
-
Spring工作原理2019-07-10 2730
-
分享点胶机制造与工作原理2012-06-25 2282
-
dde与opc技术的工作机制2012-02-02 3235
-
java spring教程2008-09-11 4842
全部0条评论

快来发表一下你的评论吧 !
