

百度云服务器FPGA标准开发环境的逻辑开发与编译示例
FPGA/ASIC技术
描述
镜像是云服务器实例运行环境的模板,包括操作系统和预装软件等配置。百度云为每个FPGA实例默认提供了专属公共镜像,用户可以按需选择适合的镜像类型。
概述
基于百度云自研的FPGA加速卡,提供了一套FPGA标准开发环境。您可以使用百度云提供的镜像工具包,在FPGA上开发与调试自己的业务功能,或者将已有的功能模块移植到FPGA加速卡上。
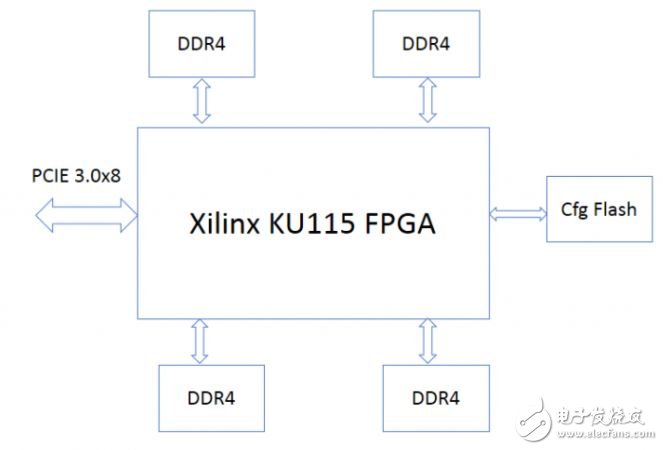
百度自研FPGA加速卡使用Xilinx 20nm KU115 FPGA。FPGA板卡带有4通道DDR4,每个通道72bit,带ECC,容量2GB,速率2400Mhz。FPGA通过PCIE 3.0x8和CPU相连。板卡的结构框图如下所示:
基于上面的FPGA板卡,百度还提供的FPGA标准开发环境,其系统结构如下图:
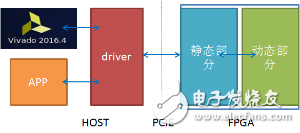
FPGA标准开发环境具有极大的灵活性:
您可以自行研发FPGA中动态部分的逻辑,包括KU115芯片的绝大部分资源,以及4个DDR4通道,让FPGA电路完成定制化的功能,
百度云提供驱动和应用参考设计,您只需修改软件侧的驱动和应用程序,调用FPGA完成特定的功能。
直接使用百度提供的工具包更换FPGA中动态部分的逻辑。
FPGA标准开发环境提供虚拟jtag工具,您可以使用vivado工具对FPGA进行调试。
FPGA 标准开发环境操作包括两部分:
FPGA软件驱动开发
以运行支持PE进行简单浮点向量加功能的示例程序为例:
1. 编译驱动,提供编译示例程序。
2. 运行示例程序。
FPGA逻辑开发
使用工具包开发和调试用户逻辑:
1. 使用Baidu_HW_design_toolkit编译实现您的动态逻辑。
2. 使用bin_pr_tools更换您的动态逻辑。
3. 使用Vivado对您的动态逻辑进行调试。
FPGA软件驱动开发
编译驱动
修改driver/Makefile中的KERNELDIR变量,使之指向当前内核的编译目录,一般为/lib/modules/$(uname -r)/build目录或/usr/src/kernels/$(uname -r)。
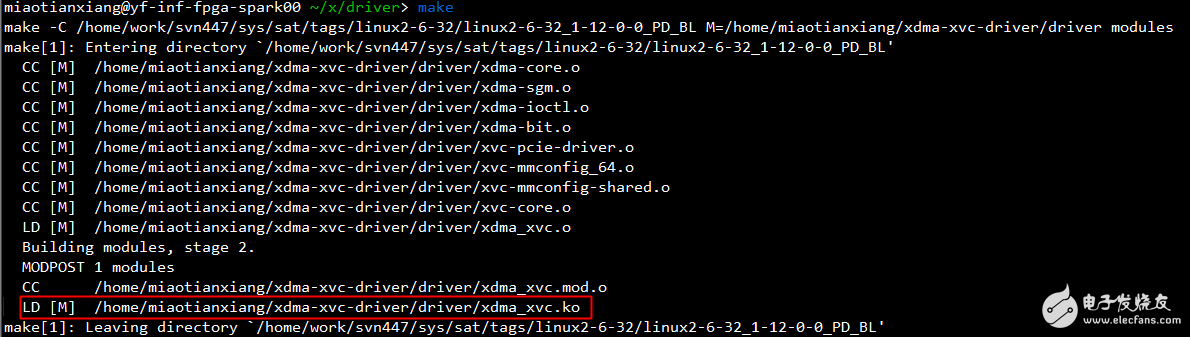
执行make,如果编译成功,当前目录下会生成xdma_xvc.ko驱动文件,如下图所示:
执行insmod xdma_xvc.ko,装载上一步生成的驱动文件,在/dev目录下会出现如下设备文件/dev/xil_xvc/cfg_ioc0。
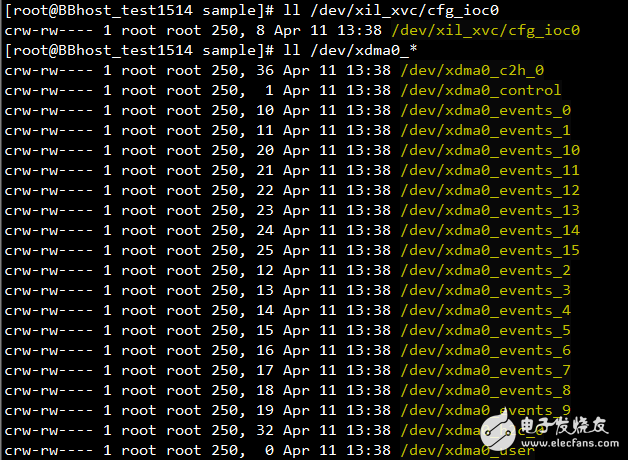
编译示例程序
进入sample目录,执行make。如果编译成功,当前目录下生成sample、sample_user_irq等可执行文件,参见下图:

运行示例程序
执行./sample,输出如下结果,PE正确地执行了浮点向量加功能。sample使用轮询寄存器方式检查命令结果是否完成。
执行./sample_user_irq,输出如下结果,PE正确地执行了浮点向量加功能。sample_user_irq使用中断方式检查命令结果是否完成。
关键代码示例
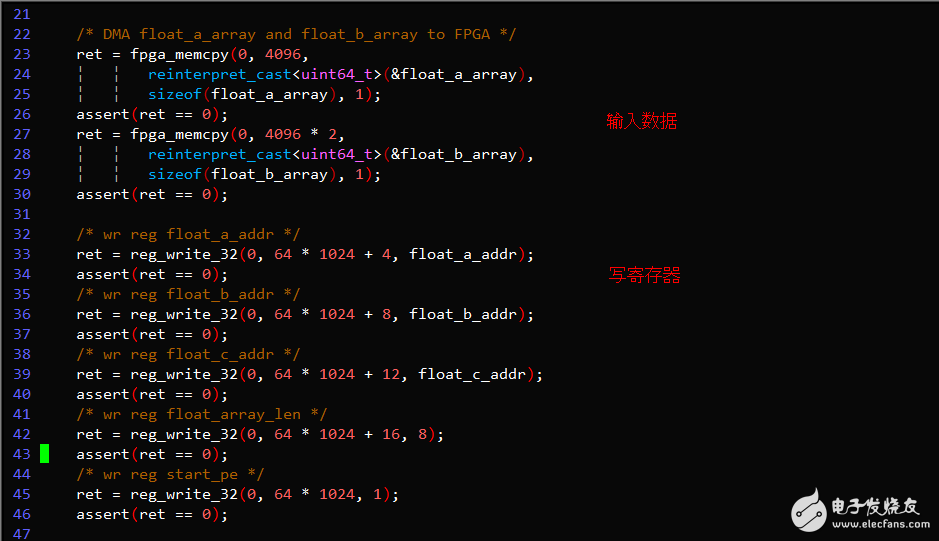
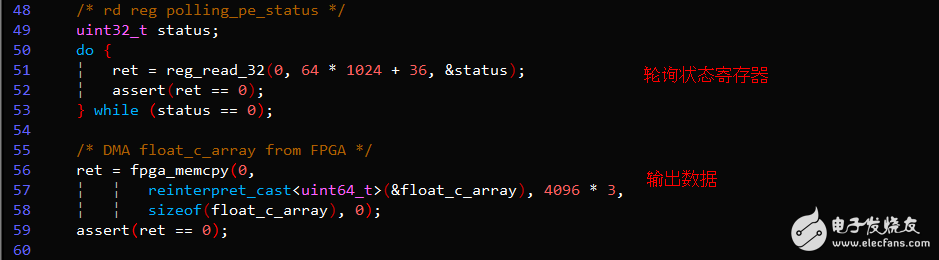
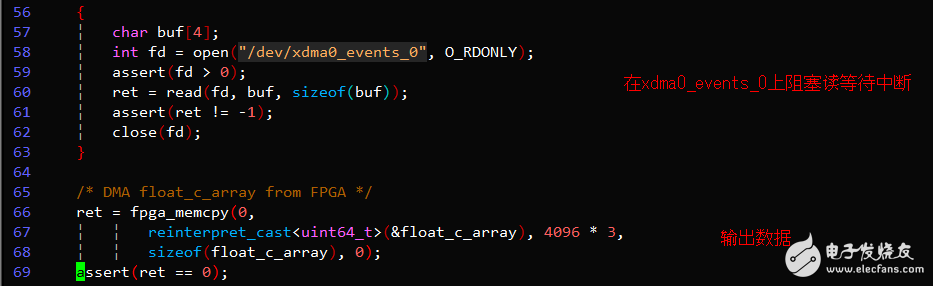
FPGA逻辑开发
使用Baidu_HW_design_toolkit编译实现您的动态逻辑
“Baidu_HW_design_toolkit”工具包,帮助将您开发的动态逻辑实现在FPGA中。
“Baidu_HW_design_toolkit”提供FPGA硬件逻辑所需的环境,只需将自己逻辑所需的相关的文件(如rtl代码,ip核,xdc约束等)放入指定的路径,然后执行脚本,即可生成用于烧写FPGA云服务器的逻辑镜像文件。
“Baidu_HW_design_toolkit”包含了三个子文件夹,build,common_files和usr_files.
usr_files存放用户的工程设计文件。
common_files存放FPGA云服务镜像工程的一些通用设计。如静态逻辑的dcp,ddr约束等。通常情况下,不建议您修改common_files目录中的内容。
build存放制作FPGA云服务器逻辑镜像所要执行的脚本,如果您具备丰富的FPGA开发经验,可以根据自己的需要修改脚本。例如,用更加适合的布局布线策略管理您的工程实现。
“Baidu_HW_design_toolkit”提供了两种流程制作FPGA云服务逻辑镜像,需要准备不同的设计文件:
Non_IPI流程
这种方式比较类似传统的FPGA工程实现方式,您需要准备好动态部分逻辑(也就是rp_bd_wrapper.rp_bd_i)的设计文件放入usr_files指定的目录,然后执行build目录下的run_nonIPI.tcl脚本。
IPI流程
这种方式采用vivado IP Integrator制作云服务逻辑镜像的动态部分逻辑(也就是rp_bd_wrapper.rp_bd_i)。你需要准备好IPI的设计文件放入usr_files和build下指定的目录,然后执行build目录下的run_IPI.tcl脚本。
使用bin_pr_tools更换您的动态逻辑
“bin_pr_tools”工具包,是更换FPGA动态部分逻辑的必要工具。在使用该工具包前,您需要确保FPGA的驱动程序已经加载。然后运行bin_pr_tools目录下的”load_pr_bin.sh”脚本即可更换您的动态部分逻辑。
$sudo sh load_pr_bin.sh base ./ver2/ver2_pr_region_partial.bin
OK set decouple! ...
OK loading clear bin! ...
OK loading pr region bin! ...
OK unset decouple! ...
OK soft reset rp_bd ...
successfully load custom bitstream!
partial clear bin: ./base/base_pr_region_partial_clear.bin
partial bin: ./ver2/ver2_pr_region_partial.bin
found clear bin base_pr_region_partial_clear.bin in the current partial bin file’s directory
copy bin base_pr_region_partial_clear.bin into ‘last_clear_bin’ directory
注意:由于更换动态部分逻辑时,需要写入当前动态逻辑对应的clear bin,您务必保存好clear bin文件,以便下次更新动态逻辑时使用。同时bin_pr_tools工具包也会保存新动态逻辑对应的clear bin文件。
使用Vivado对您的动态逻辑进行调试
百度云提供工具包类似日常使用vivado操作,对您的动态逻辑进行调试。
在使用该工具包前,您需要确保FPGA的驱动程序已经加载。
1. 打开xvc_server工具包,运行xvc_pcie服务。
2. 使用vivado工具,仅需几步就可以通过虚拟jtag识别FPGA设备。
3. 选择动态逻辑对应的probe文件,类似使用Vivado工具,对工程中的ila和vio进行功能调试和信号查看。
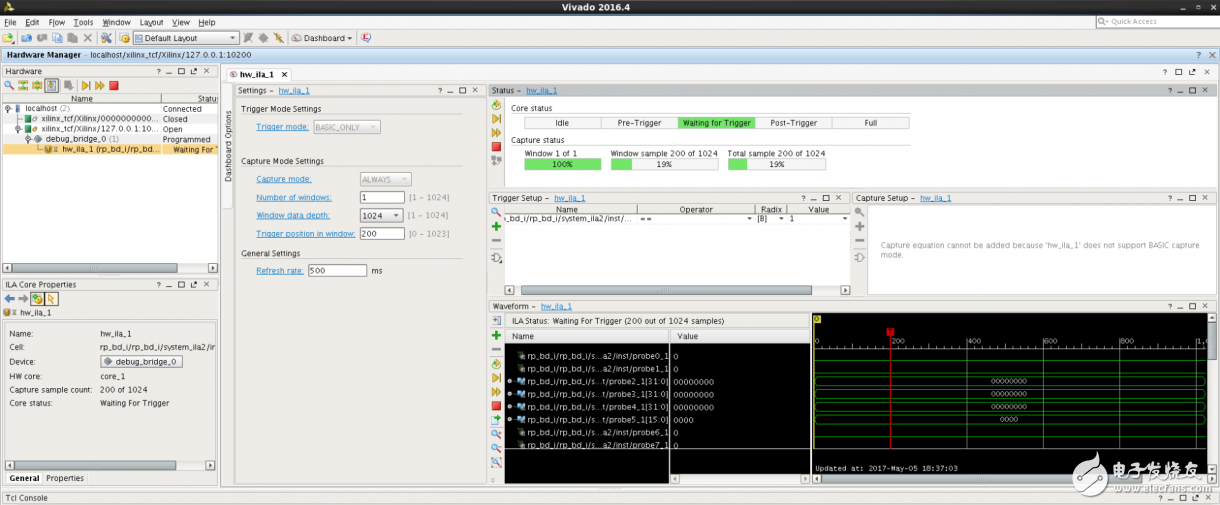
FPGA示例工程说明
概述
为方便您掌握FPGA云服务器的使用流程,快速创建自己定制的加速卡逻辑,百度云提供一个demo工程作为示例。
该demo工程支持了基于FPGA云服务器开发的几个基础功能,主要包括:
工程分成静态和动态两部分逻辑,支持基于pcie总线的partial reconfiguration开发及配置流程。
静态逻辑支持pcie-3.0-8x xdma,并提供了配套的driver。用户不能修改也无需关注静态部分的逻辑。
动态逻辑为用户自定制部分,用户需基于当前提供的接口实现所需功能逻辑。demo工程中的动态逻辑是一个element-wise向量加法模块,基于HLS开发。接口包括:
1. 一个axi slave(256bit)和一个axi lite slave(32bit)接口,可分别用于传输逻辑所需的数据和控制命令。
2. 4个axi master(512bit),用于连接DDR MIG控制器(可选)。
3. 中断、时钟。
支持基于pcie总线的ila debug,可在云服务器上的vivado中抓取信号波形进行调试。
您可根据此demo工程的结构及提供的配套脚本了解fpga云服务器的开发流程,并以该工程为基础,修改其中的动态逻辑,实现所需的其他功能。
工程结构
demo工程主要包含了两个部分,分别是static_bd_wrapper和rp_bd_wrapper。
其中static_bd_wrapper属于工程的静态部分,提供了pcie xdma,基于pcie的debug模块,flash控制器等。静态部分的逻辑不暴露给用户,用户不能修改也不用关心静态部分的逻辑。
rp_bd_wrapper则是动态逻辑,这部分逻辑中有rp_bd和其他一些组件。其中只有rp_bd是用户可以修改的内容。其他组件主要用于支持用户利用虚拟jtag进行调试或其他功能,这些组件不需要用户关心,用户不能修改。
rp_bd通过两组AXI总线与static_bd_wrapper传输数据,可以此为基础实现您所需的功能。
demo工程的rp_bd结构框图如下:
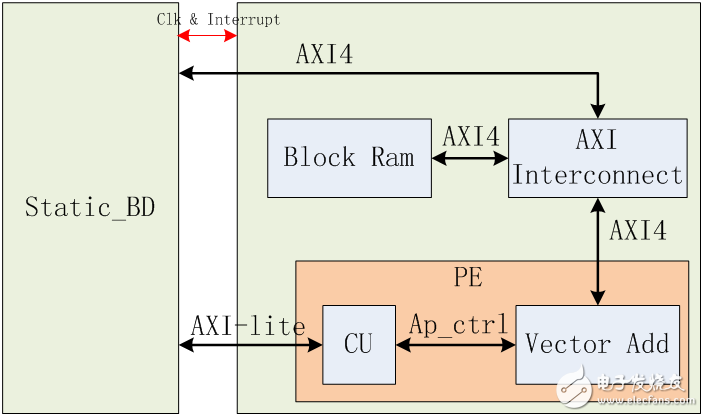
模块 说明
Block Ram rp_bd内部有一个64KB的block ram用来存储计算所用的数据和计算结果,这个block ram可同时被host和卡上的用户逻辑访问,这是通过rp_bd中的一个AXI Interconnect实现的。
AXI Interconnect AXI Interconnect用于协调两个AXI master访问rp_bd中的Block Ram;static_bd内的xdma输出的AXI4连接到AXI Interconnect的一个slave端口,demo工程提供的drive支持host通过dma访问这个block ram;PE内的Vector Add模块输出的AXI4连接到AXI Interconnect的另一个端口,使得用户逻辑也可以访问这个block ram。
CU 命令处理单元,static_bd输出的AXI-lite接口连接到PE中的CU模块,CU模块解析从AXI lite收到的命令,并产生符合ap_ctrl总线的请求信号与Vector Add模块相连。ap_ctrl是通过HLS综合出的逻辑模块采用的一种标准状态控制总线。有关其详细介绍可以参考Xilinx ug902文档。
Vector Add 计算处理单元,Vector Add模块完成向量加法运算,他是使用HLS高级综合工具开发的,它的控制输入为一组HLS模块使用的ap_ctrl信号;他使用AXI总线协议将Block Ram中的数据读出,进行加法运算后,将数据写回Block Ram中。
PE工作流程
1. 软件发起dma_to_dev将输入向量A,B拷贝至dev;A,B的长度必须8个float数据对齐。(单精度浮点数)
2. 软件通过配置寄存器发起PE计算指令,然后等待PE计算完成。
3. PE计算完成后,通过中断通知CPU上的软件驱动程序。
4. 软件发起dma_from_dev将输出向量C拷贝至host。(单精度浮点数)
-
Flexus 云服务器 X 实例:在 Docker 环境下搭建 java 开发环境2024-12-30 1218
-
不想续费百度云,这款轻量应用服务器完美替代2023-10-19 1064
-
百度CreateAI开发者大会2023-01-10 1893
-
百度AI开发者大会有什么内容2021-12-29 2661
-
百度Create AI开发者大会:百度大脑位居中国市场第一2021-12-28 3119
-
云服务器搭建嵌入式Linux开发环境的步骤2021-11-08 2477
-
Linux学习之云服务器搭建嵌入式Linux开发环境2021-11-03 1035
-
百度智能云获云计算服务能力评估一级认证2021-03-11 3105
-
百度云服务器怎么使用nfs ,tftp2020-04-24 2816
-
百度自研昆仑云服务器上线 加速AI技术与各行各业深度融合的步伐2019-12-16 2423
-
赛灵思公司宣布,百度已部署了基于赛灵思 FPGA 的应用加速服务2019-07-29 3035
-
百度在其全新公有云加速服务器中部署了赛灵思的FPGA2018-09-02 1379
-
百度云FPGA云服务器发布内测版本_助力人工智能和大数据应用2018-06-29 3037
-
百度云服务器怎么查端口号?2018-01-15 6891
全部0条评论

快来发表一下你的评论吧 !
