

了解数据科学Python库
编程语言及工具
描述
Python 近几年在数据科学行业获得了人们的极大青睐,各种资源也层出不穷。数据科学解决方案公司 ActiveWizards 近日根据他们自己的应用开发经验,总结了数据科学家和工程师将在 2017 年最常使用的 Python 库。
核心库
1)NumPy
当使用 Python 开始处理科学任务时,不可避免地需要求助 Python 的 SciPy Stack,它是专门为 Python 中的科学计算而设计的软件的集合(不要与 SciPy 混淆,它只是这个 stack 的一部分,以及围绕这个 stack 的社区)。这个 stack 相当庞大,其中有十几个库,所以我们想聚焦在核心包上(特别是最重要的)。
NumPy(代表 Numerical Python)是构建科学计算 stack 的最基础的包。它为 Python 中的 n 维数组和矩阵的操作提供了大量有用的功能。该库还提供了 NumPy 数组类型的数学运算向量化,可以提升性能,从而加快执行速度。
2)SciPy
SciPy 是一个工程和科学软件库。除此以外,你还要了解 SciPy Stack 和 SciPy 库之间的区别。SciPy 包含线性代数、优化、集成和统计的模块。SciPy 库的主要功能建立在 NumPy 的基础之上,因此它的数组大量使用了 NumPy。它通过其特定的子模块提供高效的数值例程操作,比如数值积分、优化和许多其他例程。SciPy 的所有子模块中的函数都有详细的文档,这也是一个优势。
3)Pandas
Pandas 是一个 Python 包,旨在通过「标记(labeled)」和「关系(relational)」数据进行工作,简单直观。Pandas 是 data wrangling 的完美工具。它设计用于快速简单的数据操作、聚合和可视化。库中有两个主要的数据结构:
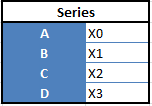
Series:一维
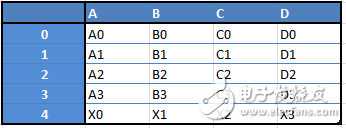
Data Frames:二维
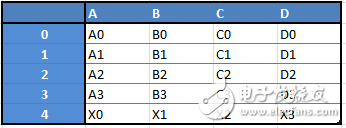
例如,当你要从这两种类型的结构中接收到一个新的「Dataframe」类型的数据时,你将通过传递一个「Series」来将一行添加到「Dataframe」中来接收这样的 Dataframe:
这里只是一小撮你可以用 Pandas 做的事情:
轻松删除并添加「Dataframe」中的列
将数据结构转换为「Dataframe」对象
处理丢失数据,表示为 NaN(Not a Number)
功能强大的分组
可视化
4)Matplotlib
Matplotlib 是另一个 SciPy Stack 核心软件包和另一个 Python 库,专为轻松生成简单而强大的可视化而量身定制。它是一个顶尖的软件,使得 Python(在 NumPy、SciPy 和 Pandas 的帮助下)成为 MatLab 或 Mathematica 等科学工具的显著竞争对手。然而,这个库比较底层,这意味着你需要编写更多的代码才能达到高级的可视化效果,通常会比使用更高级工具付出更多努力,但总的来说值得一试。花一点力气,你就可以做到任何可视化:
线图
散点图
条形图和直方图
饼状图
茎图
轮廓图
场图
频谱图
还有使用 Matplotlib 创建标签、网格、图例和许多其他格式化实体的功能。基本上,一切都是可定制的。
该库支持不同的平台,并可使用不同的 GUI 工具套件来描述所得到的可视化。许多不同的 IDE(如 IPython)都支持 Matplotlib 的功能。
还有一些额外的库可以使可视化变得更加容易。
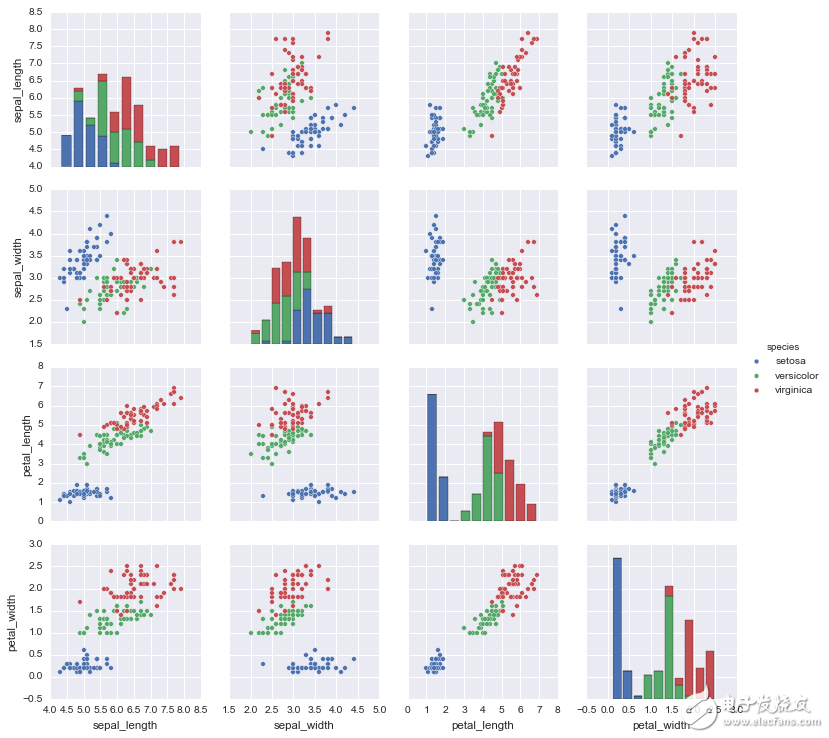
5)Seaborn
Seaborn 主要关注统计模型的可视化;这种可视化包括热度图(heat map),可以总结数据但也描绘总体分布。Seaborn 基于 Matplotlib,并高度依赖于它。
6)Bokeh
Bokeh 也是一个很好的可视化库,其目的是交互式可视化。与之前的库相反,这个库独立于 Matplotlib。正如我们已经提到的那样,Bokeh 的重点是交互性,它通过现代浏览器以数据驱动文档(d3.js)的风格呈现。
7)Plotly
最后谈谈 Plotly。它是一个基于 Web 的工具箱,用于构建可视化,将 API 呈现给某些编程语言(其中包括 Python)。在 plot.ly 网站上有一些强大的、开箱即用的图形。为了使用 Plotly,你需要设置你的 API 密钥。图形处理会放在服务器端,并在互联网上发布,但也有一种方法可以避免这么做。

机器学习
8)SciKit-Learn
Scikits 是 SciPy Stack 的附加软件包,专为特定功能(如图像处理和辅助机器学习)而设计。在后者方面,其中最突出的一个是 scikit-learn。该软件包构建于 SciPy 之上,并大量使用其数学操作。
scikit-learn 有一个简洁和一致的接口,可利用常见的机器学习算法,让我们可以简单地在生产中应用机器学习。该库结合了质量很好的代码和良好的文档,易于使用且有着非常高的性能,是使用 Python 进行机器学习的实际上的行业标准。
深度学习:Keras / TensorFlow / Theano
在深度学习方面,Python 中最突出和最方便的库之一是 Keras,它可以在 TensorFlow 或者 Theano 之上运行。让我们来看一下它们的一些细节。
9)Theano
首先,让我们谈谈 Theano。Theano 是一个 Python 包,它定义了与 NumPy 类似的多维数组,以及数学运算和表达式。该库是经过编译的,使其在所有架构上能够高效运行。这个库最初由蒙特利尔大学机器学习组开发,主要是为了满足机器学习的需求。
要注意的是,Theano 与 NumPy 在底层的操作上紧密集成。该库还优化了 GPU 和 CPU 的使用,使数据密集型计算的性能更快。
效率和稳定性调整允许更精确的结果,即使是非常小的值也可以,例如,即使 x 很小,log(1+x) 也能得到很好的结果。
10)TensorFlow
TensorFlow 来自 Google 的开发人员,它是用于数据流图计算的开源库,专门为机器学习设计。它是为满足 Google 对训练神经网络的高要求而设计的,是基于神经网络的机器学习系统 DistBelief 的继任者。然而,TensorFlow 并不是谷歌的科学专用的——它也足以支持许多真实世界的应用。
TensorFlow 的关键特征是其多层节点系统,可以在大型数据集上快速训练人工神经网络。这为 Google 的语音识别和图像识别提供了支持。
11)Keras
最后,我们来看看 Keras。它是一个使用高层接口构建神经网络的开源库,它是用 Python 编写的。它简单易懂,具有高级可扩展性。它使用 Theano 或 TensorFlow 作为后端,但 Microsoft 现在已将 CNTK(Microsoft 的认知工具包)集成为新的后端。
其简约的设计旨在通过建立紧凑型系统进行快速和容易的实验。
Keras 极其容易上手,而且可以进行快速的原型设计。它完全使用 Python 编写的,所以本质上很高层。它是高度模块化和可扩展的。尽管它简单易用且面向高层,但 Keras 也非常深度和强大,足以用于严肃的建模。
Keras 的一般思想是基于神经网络的层,然后围绕层构建一切。数据以张量的形式进行准备,第一层负责输入张量,最后一层用于输出。模型构建于两者之间。
自然语言处理
12)NLTK
这套库的名称是 Natural Language Toolkit(自然语言工具包),顾名思义,它可用于符号和统计自然语言处理的常见任务。NLTK 旨在促进 NLP 及相关领域(语言学、认知科学和人工智能等)的教学和研究,目前正被重点关注。
NLTK 允许许多操作,例如文本标记、分类和 tokenizing、命名实体识别、建立语语料库树(揭示句子间和句子内的依存性)、词干提取、语义推理。所有的构建块都可以为不同的任务构建复杂的研究系统,例如情绪分析、自动摘要。
13)Gensim
这是一个用于 Python 的开源库,实现了用于向量空间建模和主题建模的工具。这个库为大文本进行了有效的设计,而不仅仅可以处理内存中内容。其通过广泛使用 NumPy 数据结构和 SciPy 操作而实现了效率。它既高效又易于使用。
Gensim 的目标是可以应用原始的和非结构化的数字文本。Gensim 实现了诸如分层 Dirichlet 进程(HDP)、潜在语义分析(LSA)和潜在 Dirichlet 分配(LDA)等算法,还有 tf-idf、随机投影、word2vec 和 document2vec,以便于检查一组文档(通常称为语料库)中文本的重复模式。所有这些算法是无监督的——不需要任何参数,唯一的输入是语料库。
数据挖掘与统计
14)Scrapy
Scrapy 是用于从网络检索结构化数据(如联系人信息或 URL)的爬虫程序(也称为 spider bots)的库。它是开源的,用 Python 编写。它最初是为 scraping 设计的,正如其名字所示的那样,但它现在已经发展成了一个完整的框架,可以从 API 收集数据,也可以用作通用的爬虫。
该库在接口设计上遵循著名的 Don』t Repeat Yourself 原则——提醒用户编写通用的可复用的代码,因此可以用来开发和扩展大型爬虫。
Scrapy 的架构围绕 Spider 类构建,该类包含了一套爬虫所遵循的指令。
15)Statsmodels
statsmodels 是一个用于 Python 的库,正如你可能从名称中猜出的那样,其让用户能够通过使用各种统计模型估计方法以及执行统计断言和分析来进行数据探索。
许多有用的特征是描述性的,并可通过使用线性回归模型、广义线性模型、离散选择模型、稳健的线性模型、时序分析模型、各种估计器进行统计。
该库还提供了广泛的绘图函数,专门用于统计分析和调整使用大数据统计数据的良好性能。
结论
这个列表中的库被很多数据科学家和工程师认为是最顶级的,了解和熟悉它们是很有价值的。这里有这些库在 GitHub 上活动的详细统计:

当然,这并不是一份完全详尽的列表,还有其它很多值得关注的库、工具包和框架。比如说用于特定任务的 SciKit 包,其中包括用于图像的 SciKit-Image。
- 相关推荐
- 热点推荐
- python
-
SQLite数据库与python的区别2023-08-28 1851
-
你了解数据是如何存储在内存中的吗?2022-12-12 434
-
详解Python中的Pandas和Numpy库2022-05-25 4312
-
Python科学计算利器Anaconda2021-09-18 893
-
Python科学计算与数据分析2021-06-01 1046
-
Python数据科学手册的PDF电子书免费下载2020-11-27 1643
-
大数据:数据科学家需要知道十个好用的Python库2020-08-08 2430
-
理解数据库的事务:ACID,CAP和一致性2020-05-04 1542
-
为什么在数据科学领域Python比R更好2020-04-18 4124
-
Python数据科学速查表2019-11-25 2796
-
python数据分析的类库2018-05-10 2785
-
学python有哪些方向?2018-03-09 4813
-
数据库系统概述2015-12-03 436
全部0条评论

快来发表一下你的评论吧 !
